Как устроен запуск экспериментов в ИТ-продукте на примере Joom
Привет, Хабр! Меня зовут Леонид Огрель, я работаю аналитиком в Джум Лабс. В этой статье я расскажу, зачем нужен эксперимент в ИТ-продукте, и на что нужно обратить внимание при его запуске.
Как понять, понравится ли пользователям изменение, которое мы хотим внести? Принесет ли оно пользу компании? Работает ли новый алгоритм ранжирования товаров лучше по сравнению с используемым? Снизится ли конверсия, если мы добавим дополнительный баннер на карточку товара?
Чтобы ответить на подобные вопросы, мы проводим большое число онлайн экспериментов, по итогам которыx ожидаем получить чёткий ответ: улучшает ли изменение метрики компании или нет.
Процесс подготовки эксперимента к запуску можно разделить на три этапа. Ниже остановимся подробнее на каждом из них.

Этап 1. Подготовка
Самый первый вопрос, на который нужно дать ответ:»а нужен ли вообще эксперимент?».
Не каждое изменение нужно тестировать. Стратегические планы развития компании на ближайшие годы нельзя проверить краткосрочным экспериментом. Также бывают ситуации, когда нужно внести изменения в любом случае. Например, из-за требований законодательства, или когда эффект от изменения очевиден.
Таким образом, у онлайн эксперимента есть некоторая область применимости. Её можно обозначить так:
Эффект от изменения можно быстро ощутить ― в период от нескольких дней до нескольких недель.
Нет абсолютной уверенности в пользе изменения. Либо польза очевидна, но её необходимо измерить количественно.
Реализация тестируемой фичи не занимает много времени.
Итак, вы поняли, что можете протестировать вашу фичу с помощью эксперимента. Вот о чем ещё нужно задуматься перед запуском.
Посмотрите на предыдущие запуски экспериментов, связанные с этой фичей, если они были. Станет понятнее, как пользователи с ней взаимодействуют, какими метриками её можно оценить, и какова величина эффекта, хотя бы на уровне порядка изменений: 1%, 10% или 50%.
Возможно, стоит реализовать не всю фичу, а только её часть, если это сильно сэкономит ваши ресурсы.
Например:
Вы думаете добавить поле для введения купона на скидку на страницу checkout«а. Но вы опасаетесь, что увидев это поле, пользователь может начать искать купон онлайн, не найдёт и не закончит checkout. Вы хотите протестировать гипотезу о том, оказывает ли добавление этого поля негативное влияние на конверсию.
Для этого вам не нужно реализовывать всю функциональность выдачи скидки. Достаточно сделать поле и показывать сообщение о том, что купон недействителен при введении туда любого набора символов.
Этап 2. Дизайн
Окей, мы реализовали фичу. Теперь подумаем, как протестировать пользу изменения, которое мы собираемся запустить.
Перед запуском эксперимента нужно ответить на следующие вопросы:
Кто ваша целевая аудитория — люди, на кого окажет влияние ваше изменение.
Это могут быть все пользователи или специфическая группа с определенными характеристиками, например:
Пользователи, которые живут в определенной стране или городе.
Пользователи, которые покупают товары через каталог.
Пользователи, которые оставляют отзывы на товары и используют смартфон с Android и т.д.
Как должно измениться поведение аудитории, которая использует новую фичу.
Когда вы ответите на этот вопрос, вам будет намного легче выбрать метрики для оценки эффекта от изменения.
Например:
Вы упростили процесс написания отзывов ⟶ пользователь будет чаще их оставлять.
Вы улучшили алгоритм ранжирования товаров в каталоге ⟶ более качественные товары будут показываться чаще ⟶ будет меньше возвратов.
Какие долгосрочные и побочные эффекты вы ожидаете после запуска фичи.
Не факт, что получится увидеть долгосрочные эффекты, но всегда полезно их описать. Возможно, вам придётся вернуться к эксперименту спустя какое-то время, чтобы детально его проанализировать. От предполагаемых побочных эффектов зависит выбор метрик, на которые вы будете смотреть в ходе эксперимента.
Например, вы значительно изменили дизайн checkout страницы и ожидаете, что пользователи станут чаще покупать. При этом большое количество элементов на странице может замедлить скорость отрисовки, что будет иметь обратный эффект.
Какую гипотезу (или набор гипотез) вы собираетесь протестировать.
После того, как вы продумаете ответы на эти вопросы, вы легко сформулируете гипотезу:
На основании [инсайта] мы ожидаем, что [тестируемое изменение X] приведет к [улучшению|неухудшению|ухудшению] в [выдаче поиска|ценообразовании|времени доставки|оптимизации рекламы|…], которое мы количественно измерим с помощью изменения [метрики Y] на [N%] при отсутствии ухудшения по [метрикам Z1 Z2 …]
Это нужно сделать, чтобы оградить себя от возможных ошибок при принятии решения по итогам эксперимента. Так, не получив ожидаемых результатов по одним заранее отобранным метрикам, но получив рост по каким-то другим, велик соблазн сказать: «Отлично! Мы не улучшили то, во что целились, но смогли добиться роста вот там-то и там-то». Бывает так, что эти неожиданные положительные результаты были получены случайно (так называемый «ложный прокрас», подробнее о нём будет дальше). В этом случае мы рекомендуем на основе инсайта из текущего эксперимента сформулировать новую гипотезу и проверить её отдельным экспериментом.
Этап 3. Запуск
1. Описание эксперимента.
При проведении А/Б эксперимента составьте подробное и понятное описание изменения и предполагаемого эффекта, чтобы сторонний человек мог прочитать и сразу понять, о чём идет речь. Изменения в UI можно проиллюстрировать с помощью скриншотов. Обязательно добавьте формулировку тестируемой гипотезы из предыдущего пункта.
Такое описание будет полезно и вам в будущем. При запуске нового эксперимента вы сможете обратиться к опыту уже завершенного.
2. Настройка аудитории.
Введем два понятия: exposed users и unexposed users.
Exposed users — пользователи, которых затронет изменение.
Unexposed users —пользователи, которых изменение не затронет.
Пользователь тестовой группы эксперимента может не ощутить воздействия фичи, потому что он не добрался до той части приложения, где она реализована.
Например, новый дизайн checkout страницы могут увидеть только те, кто дошел до этапа оплаты покупки. Такие unexposed users будут, в среднем, одинаковыми в контрольной и тестовой группах, и у них не должно быть разницы в поведении.
Вывод: по возможности включайте в эксперимент только тех, кто может увидеть это изменение.
Чем больше unexposed users окажется в эксперименте, тем меньше будут различаться значения метрик, даже если ваша фича растит метрики для exposed users.
Вы можете выделить пользователей, которых должно затронуть изменение, несколькими способами. В разработанной нами платформе экспериментов их три:
Отфильтровать по пользовательским характеристикам: страна, язык, тип устройства, версия приложения, время регистрации и т.д.
Пользователь попадает в эксперимент только после совершения определенного действия, например, перехода на экран оплаты.
Запустить эксперимент на заранее выбранную аудиторию.
 Настройка аудитории в платформе экспериментов Joom
Настройка аудитории в платформе экспериментов Joom
3. Группы и срезы.
Не создавайте лишние тестовые группы и срезы, оставьте только те, которые вам нужны. Иначе, вы увеличиваете вероятность ошибки первого рода ― случайного прокраса хотя бы в одном срезе одной из групп.
Неформально:
Ошибка первого рода — когда на самом деле эффекта нет, но данные показывают, что он есть.
Ошибка второго рода — когда на самом деле эффект есть, но в данных мы его не видим.
Например:
Вы хотите проверить, оказывает ли цвет кнопки эффект на нашу любимую метрику ― конверсию.
Для каждого из четырех оттенков цвета кнопки вы создали отдельную тестовую группу. Внутри каждой из них ― пять срезов пользователей, которые отличаются по возрасту, полу и другим характеристикам. В этом случае при уровне значимости 0.05 вероятность ошибки первого рода составит около 0.64. Вы можете применить коррекцию на множественное тестирование гипотез, но это уменьшит чувствительность эксперимента, повысив вероятность ошибки второго рода.
Мы в команде рекомендуем коллегам принимать решения по заранее выбранным срезам, остальные использовать только для информации. Чем больше срезов, тем больше вероятность ошибки первого рода.
4. Метрики.
Не тестируйте много метрик одновременно, иначе увеличится вероятность ошибки первого рода, как в случае со срезами. Чтобы этого избежать, мы разделили метрики на типы, которые помогают нам принять решения по итогам эксперимента.
Метрики делятся на три типа: success, guardrail и informative.
Success — это метрики, по которым будет приниматься решение. У нас есть ограничение — не более пяти таких метрик. На основе их изменений рассчитывается рекомендованный размер группы.
Guardrail — это метрики, которые не должны ухудшиться в результате эксперимента. Это нужно, чтобы отсечь ситуации, когда мы получим улучшение по одной метрике за счёт ухудшения другой.
Informative — это остальные метрики, изменение которых может представлять интерес.Наша платформа не ограничивает их количество в эксперименте, но принимать решение на их основе нельзя.
Размер группы и длительность эксперимента.
Это последний и самый технически сложный этап эксперимента.
А) Определите список метрик и проставьте тип для каждой из них.
Для success-метрик подберите величину изменения метрики в %, на которую вы рассчитываете в эксперименте.
Для guardrail-метрик укажите величину изменения в %, которую вы не хотите превысить.
Б) Подберите размер группы и длительность эксперимента.
Minimal Detectable Effect (MDE) — это минимальный эффект, который может быть обнаружен с заданной вероятностью.
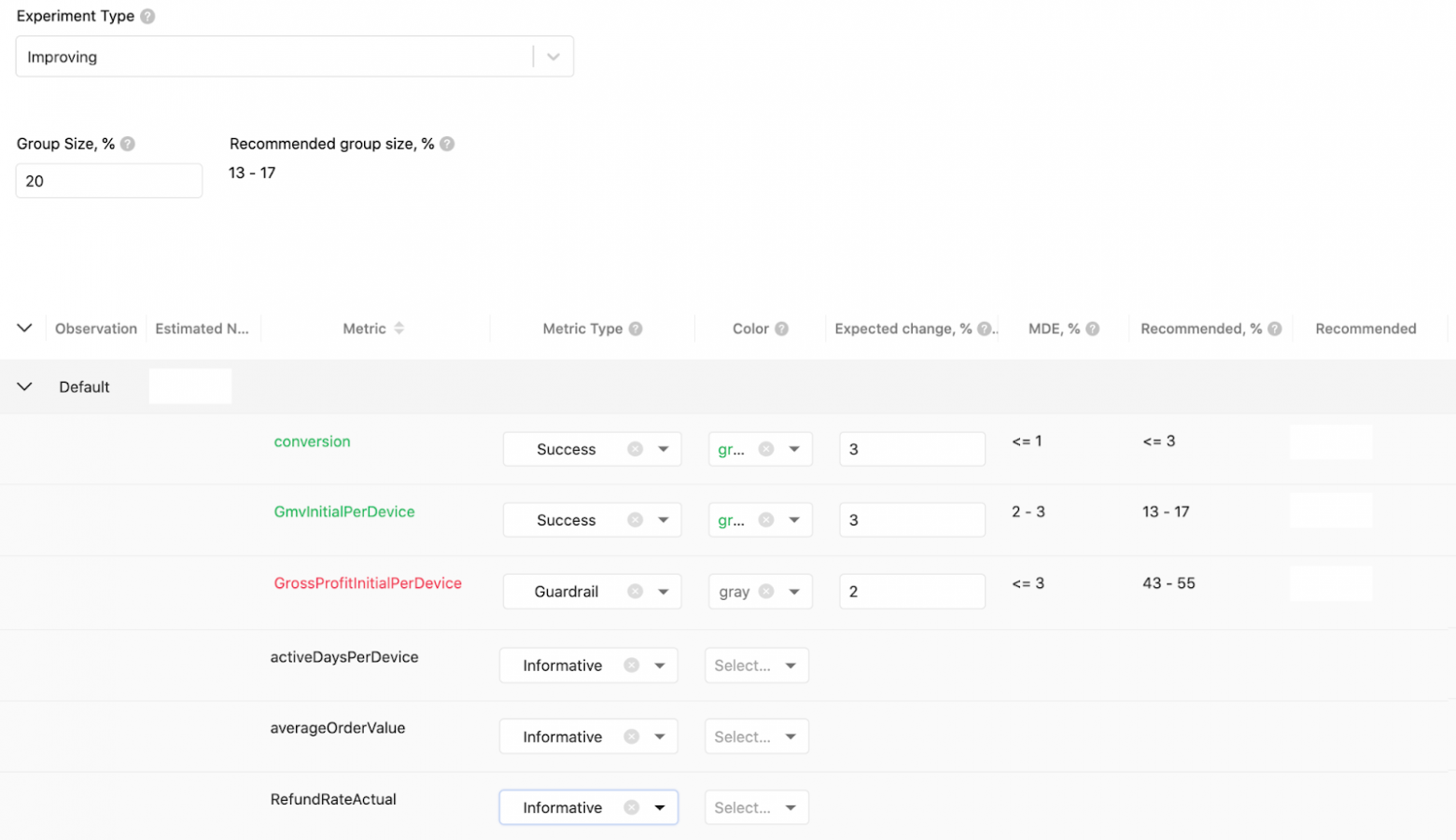 Типы метрик, величина ожидаемого эффекта и рекомендуемый размер группы в платформе экспериментов Joom
Типы метрик, величина ожидаемого эффекта и рекомендуемый размер группы в платформе экспериментов Joom
Чтобы понять, какое число пользователей включать в эксперимент, для каждой метрики нужно оценить:
текущее среднее значение.
текущее значение дисперсии ― есть типы метрик, где отдельно рассчитывать дисперсию не нужно, но для большинства метрик всё-таки нужно.
минимальное изменение метрики, которое вы хотите обнаружить в эксперименте, если оно там есть (эту величину часто называют MDE ― minimum detectable effect).
Последний пункт стоит понимать так: эксперимент, наподобие микроскопа, позволяет разглядеть изменения метрик, которые не обнаружить невооруженным глазом (например, просто разглядывая дашборды). Так, резкость микроскопа может быть недостаточна, чтобы рассмотреть мелкие детали, но вполне приемлема для более крупных объектов.
Минимальное изменение метрики ― это то, насколько мелкие детали вы хотите иметь возможность обнаружить. Конечно, вы можете захотеть увидеть даже самые маленькие изменения, например рост метрики на 0.1%. Но для этого у вас может быть недостаточный объём данных. Либо вам придется тестировать изменение на очень большом проценте вашей аудитории. Это может увеличить количество недовольств и отток пользователей, если фича по каким-то причинам им не понравится. Выбор MDE ― это всегда компромисс между вашими желаниями и возможностями в рамках отдельно взятого эксперимента.
Зная эти показатели, вы можете рассчитать необходимый размер группы с помощью специального калькулятора. Вот хороший пример такого калькулятора.
Например:
Конверсия в покупку составляет 10%. Вы ожидаете, что ваше изменение должно увеличить эту метрику минимум на 5%. Подставив эти значения в калькулятор, мы поймем, что для корректной оценки нам нужно набрать не меньше 56885 пользователей в одну группу.
Совет: Не завышайте MDE, чтобы запустить эксперимент на меньшем числе пользователей. Сильные фичи — это большая редкость, а из-за недостаточного количества пользователей не будет прокраса там, где он мог быть, если бы пользователей было больше.
При выборе длительности эксперимента имейте в виду следующее:
Пользователи, которые приходят на выходных и в рабочие дни, обычно отличаются по своему поведению. Поэтому запускайте эксперимент на целое количество недель, чтобы сгладить эффект сезонности.
Не запускайте эксперименты во время специальных событий, например, больших распродаж, если ваш эксперимент не связан с этим событием.
Пользователям может понадобиться какое-то время, чтобы понять, как работает экспериментальная фича. Поэтому заложите дополнительное время, если есть вероятность такого эффекта.
Чек-лист запуска эксперимента
«No matter how expert you may be, well-designed checklists can improve outcomes».
Steven Levitt, «The Checklist Manifesto» review in NYT.
Спасибо всем, кто дочитал до конца. Вот чек-лист, который поможет вам проверить себя.
☑ Оцените потенциал фичи и предыдущие эксперименты.
☑ Не проводите эксперименты в периоды важных событий, повышенного спроса и распродаж.
☑ Создайте базовую реализацию фичи (MVP), которую хотите протестировать.
☑ Убедитесь, что в MVP нет багов.
☑ Продумайте дизайн эксперимента: целевая аудитория, изменение поведения, ожидаемый эффект.
☑ Четко сформулируйте гипотезу, которую хотите проверить.
☑ Настройте параметры эксперимента в соответствии с гипотезой и дизайном.
☑ Подберите размер групп на основе MDE и среднего значения метрики.
Эксперимент — это инструмент, который позволяет получить ответ на интересующий нас вопрос. Но он работает с погрешностями, поэтому помните, что часто идеал недостижим. Продумайте наилучший из доступных вариантов, обратите внимание на недостатки и на то, как они могут повлиять на результаты.
Спасибо за помощь в редактуре этого поста Марине Соколовой и Антонине Татчук.
