Как ускорить работу PostgreSQL с помощью конфигурации базы и оптимизации запросов
Когда работаешь с данными, скорость запросов — один из главных показателей эффективности. Чтобы повысить эту скорость, нужно знать не только как оптимизировать сами запросы, но и как конфигурация самой базы влияет на скорость выполнения запроса.
Администратор баз данных в Southbridge и ведущий инженер компании Data Driven Lab Иван Чувашов занимается базами данных 15 лет и сегодня хочет поговорить про оптимизацию запросов. Разбирать все будет на примере PostgreSQL, так как именно с этой базой он сейчас работает плотнее всего.
Эта статья — конспект бесплатного вебинара об оптимизации PostgreSQL от «Слёрма». Если вам удобнее смотреть, а не читать, переходите на YouTube.

Немного об оптимизации
SQL — весьма сложная тема для погружения и понимания. Условно у нас есть 30 команд — и сотни способов и подходов, как их использовать. Мысля множествами, можем выбирать разные интерпретации SQL-языка, чтобы помочь базе данных выполнить наш запрос. Поэтому какой-то серебряной пули, то есть универсального способа ускорения SQL-запросов нет. Ну либо я не нашел этот философский камень). Нельзя сформировать пошаговую инструкцию, потому что для каждой базы, ситуации и запроса будет своя схема — нужно в общем понимать и чувствовать, что следует сделать.
Но чтобы сформировать это понимание, нужно на практике увидеть, как изменение отдельных параметров приводит к ускорению в конкретных ситуациях. Это мы и рассмотрим на практике.
Оптимизировать работу с данными можно четырьмя способами:
«Правильно» настроив конфигурацию БД, в нашем случае PostgreSQL.
Оптимизировав конкретные запросы.
Переработав архитектуру данных.
Изменив работу приложения.
Архитектуру данных и работу приложения мы затрагивать не будем, так как это напрямую не связано с SQL. А вот о конфигурации БД и оптимизации конкретных запросов поговорим на практических примерах.
Конфигурация PostgreSQL
В PostgreSQL много параметров, которые позволяют ускорить выполнение запросов. С помощью этих параметров мы сообщаем PostgreSQL, например, на каком железе он находится и как должен с ним работать.Также мы можем настроить логику работы приложения с PostgreSQL: установить лимиты или изменить параметры выбора плана запросов, указав максимальное количество JOIN в запросе.
Параметров много, но я разберу самые полезные и интересные, с моей точки зрения.
Maintenance_work_mem и autovacuum_work_mem. По сути они мало связаны с оптимизацией, но по факту очень важны. PostgreSQL — это MVCС-модель, а значит есть процессы, которые занимаются очисткой неактуальных данных и поддерживают консистентность обслуживающих процессов.
maintenance_work_mem больше работает с create-индексами, обновлениями альта-тейбл, системными параметрами. autovacuum_work_mem, работает с autovacuum. И эти два параметра часто используют так: ставят autovacuum_work_mem -1, чтобы он заимствовал значение параметра от maintenance_work_mem.
max_parallel_maintenance_workers и autovacuum_мах_workers. Если мы изменим вышеперечисленные параметры, и не учтем это, мы можем сломать наш сервер. Ну либо сильно его замедлим.
work_mem. Он отвечает за выделение памяти под запрос, который мы хотим выполнить на PostgreSQL. Главная его фишка в том, что он может выделять память довольно специфически. Например, возьмем несколько утрированный запрос:
select * from (select * from table1) t1 a join (select * from table2) t2 on t1.id = t2.idКак думаете, сколько памяти он будет потреблять?
Кажется, что раз work_mem выделяет память на запрос, то потребление будет один work_mem. Но по факту один выделится на главный запрос, и по одному на каждый вложенный. То есть всего на запрос потратится 3*work_mem. Кажется, что это не много, но если у нас 100 таких запросов, это уже существенно.
Поэтому не стоит безгранично увеличивать work_mem — память на сервере конечна. Может быть, стоит сделать его меньше, а побольше отдать, например, внутренней памяти PostgreSQL.
Этот параметр нельзя настроить один раз и потом про него забыть. Разные запросы, изменение логики приложения — все это отражается на памяти, поэтому work_mem регулярно нужно корректировать. Есть даже схемы, в которых параметр настраивается с помощью приложения, передавая в сессии значения этого параметра, так как оно лучше понимает, какой запрос будет выполняться и сколько памяти ему для этого нужно.
У этого параметра всегда нужно искать точку равновесия. Если выставить его маленьким, то для операций вроде агрегации и сортировки БД будет использовать диск —, а это очень медленно. Если же work_mem сделать слишком большим, он съест память, которая не расходуется.
from_collapse_limit. Этот параметр отвечает за то, сколько джойнов может быть в вашем запросе прежде, чем будет выбран алгоритм генетический вероятного поиска плана запросов. Он важен, если у вас есть серьезные большие отчеты. По умолчанию его значение. 10. Если уменьшить — планы могут выбираться неоптимально. А если сильно увеличить — планирование запроса может занять недопустимое количество времени. Поэтому его тоже можно варьировать и смотреть, как это отражается на степени производительности ваших запросов.
Подробнее о разных параметрах PostgreSQL можно прочитать в документации. Там есть информация об их настройках, параметрах и влиянии на производительность. Как уже сказано выше, универсальных советов здесь нет, так что нужно экспериментировать и применять на практике.
Оптимизация запросов
Поиск запросов для оптимизации
Прежде чем приступать к оптимизации нужно понять — как вообще найти эти самые медленные, «неоптимизированные» запросы. Можно делать это несколькими способами:
Вручную искать в логах PostgreSQL.
Использовать системы мониторинга, которые парсят эти же логи и отображают их на графике. Например, pgbadger, который выдает логи в виде html-странички с удобным интерфейсом.
Кроме медленных можно поискать запросы, которые выполняются чаще других, иногда по непонятным причинам. В этом поиске поможет расширение pg_stat_statements. Например, у меня была ситуация, когда 5 или 6 запросов выполнялись на сервере больше 300 раз в секунду. То есть на ровном месте создавалось две тысячи запросов —, а учитывая секционированные таблицы, внутри это давало еще большую нагрузку. Как только мы снизили частоту выполнения запросу до раза в секунду, приложение и база стали работать быстрее — не пришлось оптимизировать сам запрос.
Теперь представим, что мы взяли запрос, оптимизировали его и посмотрели на время. Вроде бы оно уменьшилось в пять раз, но что это значит на самом деле? Разберем на примерах и посмотрим, почему время на самом деле не показатель быстродействия.
Первый пример
Давайте создадим табличку user, внесем в нее 10 миллионов записей:
create table users
(
id bigint primary key,
login varchar(200) not null,
first_name varchar(200) not null,
last_name varchar(200) not null,
create_date timestamp not null default now()
);
CREATE TABLE
insert into users
select id, random() * id, md5(sin(id)::text), md5(cos(id)::text)
from generate_series(1, 10000000) id;
INSERT 0 10000000
analyze users;
ANALYZEПотом выполним такой запрос:
\timing
Timing is on.
select count(distinct id) from users;
count
----------
10000000
(1 row)
Time: 4535.931 ms (00:04.536)Получилось 4,5 секунды — для нас это неоптимально. Но выполним его второй раз — и вот он уже занимает 3 секунды, хотя мы ничего не меняли. В чем дело?
На самом деле причин может быть много: загрузка данных с диска в оперативную память сервера, текущая нагрузка на сервер, другая работа приложения, какие-то изменения конфигурации. Поэтому время выполнения запроса может быть разным, и ориентироваться при оптимизации только на этот критерий нельзя.
Для расчетов некоторые используют explain. Пишут запрос и смотрят, какая у него стоимость, cost. В PostgreSQL cost — это среднее время доступа до случайной страницы в БД, поэтому по количеству костов можно посчитать время. Выглядит это так:
explain select count(distinct id) from users;
QUERY PLAN
---------------------------------------------------------------------
Aggregate (cost=176230.12..176230.14 rows=1 width=8)
-> Seq Scan on users (cost=0.00..173771.10 rows=983610 width=8)
(2 rows)
Time: 0.435 msНо эта величина тоже не стабильная и зависит от многих параметров. Например, если диск долгое время был загружен, средняя стоимость изменится, то есть показатель снова будет необъективным.
Слово explain показывает как будет работать запрос, но это не реальный план выполнения запроса. Чтобы это исправить, нужно добавить analyze:
explain analyze select count(distinct id) from users;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=284689.43..284689.45 rows=1 width=8) (actual time=4228.384..4228.386 rows=1 loops=1)
-> Index Only Scan using users_pkey on users (cost=0.43..259689.43 rows=10000000 width=8) (actual time=1.006..1224.245 rows=10000000 loops=1)
Heap Fetches: 61
Planning Time: 0.079 ms
Execution Time: 4229.148 ms
(5 rows)Здесь результат уже чуть более стабильный, по крайней мере в плане костов. И можно сравнивать по ним и говорить, что мы повысили производительность запросов в 5–6 раз. Но интереснее говорить не о костах и о времени выполнения —, а о буферах. То есть о том, какой объем данных нам потребовался для выполнения конкретного запроса.
Буферы не завязаны на архитектуру, диск и память — они напрямую связаны именно с данными, которые хранятся на текущем сервере. Так что можно составить запрос таким образом:
explain (analyze, buffers) select count(distinct id) from users;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=284689.43..284689.45 rows=1 width=8) (actual time=4408.248..4408.262 rows=1 loops=1)
Buffers: shared hit=13937, read=149998, dirtied=125912, temp read=30325 written=30382
-> Index Only Scan using users_pkey on users (cost=0.43..259689.43 rows=10000000 width=8) (actual time=0.084..1253.347 rows=10000000 loops=1)
Heap Fetches: 61
Buffers: shared read=27332
Planning Time: 0.081 ms
Execution Time: 4408.414 ms
(7 rows)Сложив все значения в строке buffers мы получим объем данных для выполнения этого запроса. В сумме может получиться 450–500 страниц — это совсем немало. Учитывая, что объем одной страницы данных — 8 килобайт.
Такая методика помогает узнать не только объем данных, но и то, чем PostgreSQL вообще занимался, пока выполнял запрос. Сначала разберем первые три параметра:
Shared hit. Найденные данные, которые уже находились в оперативной памяти.
Read. Это то, что пришлось считать не из памяти, а с диска.
Dirtied. Сколько «грязных» данных PostgreSQL нашел в процессе выполнения запроса.
Большие числа в этих показателях — сигнал того, что в конфигурационных настройках PostgreSQL что-то не так и нужно покопаться.
Еще есть интересный показатель temp_write. Он показывает, что оперативной памяти на запрос не хватило, и в какой-то момент БД создала файл на 30 страниц на диске, а потом оттуда их считывала. То есть можно увеличить work_mem, и тогда этот показатель исчезнет.
До этого мы с вами говорили про count (distinct id). Теперь давайте посмотрим на count(*) и план его выполнения:
explain (analyze, buffers) select count(*) from users;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=212772.98..212772.99 rows=1 width=8) (actual time=1093.250..1093.496 rows=1 loops=1)
Buffers: shared hit=12 read=27332
-> Gather (cost=212772.77..212772.98 rows=2 width=8) (actual time=1089.207..1093.486 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=12 read=27332
-> Partial Aggregate (cost=211772.77..211772.78 rows=1 width=8) (actual time=1061.481..1061.484 rows=1 loops=3)
Buffers: shared hit=12 read=27332
-> Parallel Index Only Scan using users_pkey on users (cost=0.43..201356.10 rows=4166667 width=0) (actual time=0.050..759.141 rows=3333333 loops=3)
Heap Fetches: 61
Buffers: shared hit=12 read=27332
Planning:
Buffers: shared read=3
Planning Time: 1.685 ms
Execution Time: 1093.589 ms
(15 rows)Раньше у нас было 300 тысяч буферов, а тут стало 27 тысяч — то есть запрос выполнился практически в 11 раз быстрее.
За счет чего достигается такое ускорение? Здесь видно, что запрос выполняется буквально за одну секунду, потому что одновременно три воркера начинают читать данные по индексу.
Еще существует альтернатива — вместо select count(*) from users можно прописать select count(1) from users. Такое решение часто можно встретить в SQL командах. Фактически эти запросы практически не отличаются, но давайте сравним их на синтетических тестах.
Воспользуемся утилитой pgbench и запустим оба запроса по 50 раз:
echo "select count(1) from users;" | sudo -iu postgres pgbench -d postgres -t 50 -P 1 -f –
latency average = 602.805 ms
latency stddev = 34.097 ms
tps = 1.658885 (without initial connection time)
echo "select count(*) from users;" | sudo -iu postgres pgbench -d postgres -t 50 -P 1 -f –
latency average = 593.256 ms
latency stddev = 30.989 ms
tps = 1.685587 (without initial connection time)Тут мы увидим, что count (*) хоть немного, но быстрее чем count (1). Тут все верно — ведь PostgreSQL »1» обрабатывает как функцию, что занимает больше времени и требует дополнительных проверок, а »*» он понимает как отдельный оператор и не выполняет дополнительных проверок.
Второй пример
Здесь у нас есть ранее созданная табличка users. Мы создаем аккаунт, делаем ссылку на таблицу и создаем account log, со ссылкой на таблицу account id.
create table account(id bigint primary key, user_id bigint not null references users, name varchar(200), create_date timestamp not null default now());
CREATE TABLE
create table account_log (id bigint primary key, account_id bigint not null references account, login_date timestamp not null default now());
CREATE TABLE
insert into account select id, (random()*10000000) :: bigint, md5(id::text), now() from generate_series(1,1000000) id;
INSERT 0 10000000
insert into account_log select id, (random()*10000000) :: bigint, '2022-01-01' :: timestamp + ((random() * 365)::int:: text || ' days') ::interval from generate_series(1,20000000) id;
INSERT 0 20000000
analyze account;
ANALYZE
analyze account_log;
ANALYZE
create index ix__account_log__account_id on account_log(account_id);
create index ix__account_log__login_date on account_log(login_date);
create index ix__account__user_id on account(user_id);То есть у нас есть пользователи, у каждого может быть, несколько аккаунтов и по каждому аккаунту мы создадим статистику, когда он последний раз заходил в систему.
И вот приходит бизнес-задача — посчитать, сколько людей залогинилось за определенный промежуток времени. И мы пишем запрос:
explain(buffers,analyze)
select count(*), min_login_date::date
from
(
select min(login_date) min_login_date
from users u
left join account a on u.id = a.user_id
left join account_log al on al.account_id = a.id
group by u.id
) t
where min_login_date between '2022-02-01' and '2022-02-28'
group by min_login_date::date
order by min_login_date::dateВыбираем минимальную дату логирования users, соединяемся с account_log, потом по этой дате наворачиваем фильтр. Допустим, смотрим на февраль. Дальше просто считаем count, делаем группировку и смотрим. Но что показывает план?
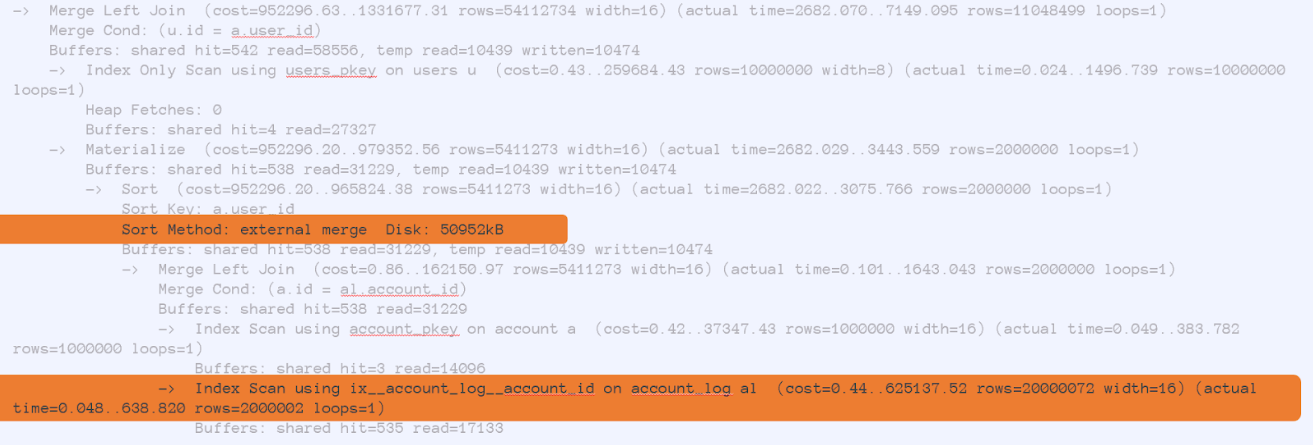
Ничего хорошего. Он говорит, что мы вычитываем много данных из таблички account_log, то есть обращаемся по индексу, по аккаунт ID. Здесь я для теста занес 20 миллионов строк. И для сортировки у нас не хватило места — пришлось 50 Мб данных записать на диск. А буферов потребовалось больше 500 тысяч.
Как это можно оптимизировать? На самом деле просто — достаточно выкинуть табличку users. В первом запросе по ней происходит группировка, но здесь у нас все нужное содержится в users ID. И отказ от users даст нам нужную оптимизацию:
explain(buffers,analyze)
select count(*), min_login_date::date
from
(
select min(login_date) min_login_date
from account a
join account_log al on al.account_id = a.id
group by a.user_id
) t
where min_login_date between '2022-02-01' and '2022-02-28'
group by min_login_date::date
GroupAggregate (cost=575697.89..575734.66 rows=200 width=12) (actual time=2755.648..2759.803 rows=28 loops=1)
Group Key: ((t.min_login_date)::date)
Buffers: shared hit=6 read=31761, temp read=8568 written=20136То есть получается, что у нас используется 60 тысяч буферов, а сам запрос занимает 3 секунды. Хотя учитывая, что это простой отчет, который может запрашиваться каждую минуту, это все равно долго.
Чтобы оптимизировать все еще больше, мы можем ограничить данные фильтром:
explain(buffers,analyze)
with cte
as
(
select min(login_date :: date) min_login_date
from account_log al
where al.login_date between '2022-02-01' and '2022-02-28'
group by al.account_id
)
select * from cte
Subquery Scan on cte (cost=1751.70..2527.46 rows=38788 width=4) (actual time=24.862..30.748 rows=19441 loops=1)
Buffers: shared hit=2 read=356Из 20 миллионов строк, который мы сканировали в прошлый раз, осталось 20 тысяч — с этим уже можно работать. Запрос уже оптимальный, и теперь на него нужно навесить логику.
Дальше давайте попробуем получить минимальную дату относительно не account, а users.
explain(buffers,analyze)
with cte
as
(
select min(login_date :: date) min_login_date, al.account_id
from account_log al
where al.login_date between '2022-02-01' and '2022-02-28'
group by al.account_id
)
select min(min_login_date) min_login_date, a.user_id
from cte
join account a on a. id = cte.account_id
group by a.user_id
Finalize HashAggregate (cost=24273.18..24661.06 rows=38788 width=12) (actual time=206.033..209.755 rows=19424 loops=1)
Group Key: a.user_id
Batches: 1 Memory Usage: 3089kB
Buffers: shared hit=6740 read=5706Стало хуже, чем в первом запросе, но зато больше подходит под наши бизнес-задачи. Добавим еще логики:
explain(buffers,analyze)
with cte
as
(
select min(login_date :: date) min_login_date, al.account_id
from account_log al
where al.login_date between '2022-02-01' and '2022-02-28'
group by al.account_id
),
cte_ac
as
(
select min_login_date, a.user_id,
exists(select * from account_log al
join account au on au.id = al.account_id where au.user_id = a.user_id and al.login_date < '2022-02-01' ) is_exists
from cte
join account a on a. id = cte.account_id
)
select count(*), min_login_date
from
(
select a.user_id, min(min_login_date) min_login_date
from cte_ac a
where a.user_id not in (select user_id from cte_ac where is_exists)
group by a.user_id
) t
group by min_login_date
order by min_login_dateВ итоге если посмотреть как было, и как стало, получается такой результат:
Было:
GroupAggregate (cost=1756768.39..1757145.89 rows=200 width=12) (actual time=9955.696..9960.064 rows=28 loops=1)
Group Key: ((t.min_login_date)::date)
Buffers: shared hit=545 read=58556, temp read=10439 written=10474Стало:
GroupAggregate (cost=685063.31..685066.81 rows=200 width=12) (actual time=535.396..540.163 rows=28 loops=1)
Group Key: t.min_login_date
Buffers: shared hit=5545 read=18164Пусть по буферам и по объему данных мы выиграли не так много, зато значительно оптимизировали работу запроса, что для нас как раз и было особенно важно.
Больше о конфигурации PostgreSQL и об оптимизации запросов я буду рассказывать на интенсиве «Оптимизация запросов SQL» в «Слёрме». Там мы разберем конкретные параметры, посмотрим популярные запросы и попрактикуемся на стендах.
