Как студенты из Перми попали в финал международного чемпионата по анализу данных Data Mining Cup 2019
Всем привет. В этой статье я расскажу о нашем опыте участия в соревновании по анализу данных Data Mining Cup 2019 (DMC) и о том, как нам удалось войти в ТОП-10 команд и принять участие в очном финале чемпионата в Берлине.

Повествовать я буду от лица нашей команды, в которую вхожу я (Александр Перевалов), а также мой коллега — Сергей Бобков. Мы — магистранты Пермского Политеха, в свободное время от работы и учебы занимаемся решением Data Science контестов.
Что такое DMC и как мы о нём узнали
Data Mining Cup — это всемирный чемпионат по анализу данных среди студентов, который проводится раз в год. Его история началась 20 лет назад, задолго до Kaggle, можно сказать, что DMC проводил соревнования по анализу данных до того, как это стало мейнстримом.
Организатором DMC является немецкая компания PrudSys, занимающаяся Retail Intelligence. Ранее, в чемпионате разрешалось участие только «в одиночку», затем участникам разрешили объединятся в команды от университета, к слову, максимальное количество команд от универа — всего 2. Принадлежность участников к университету также жестко контролируется, для участия необходимо иметь почту с доменом вашего учебного заведения, а также выслать копию студенческого билета.
На сегодняшний момент, если сравнивать уровень участников DMC и Kaggle, конечно, уровень Kaggle на порядок выше. Это связано и с ограничением на студентов в DMC и с популярностью Kaggle. Отличительной особенностью DMC является отсутствие лидерборда, что позволяет избавиться от проблем с подгонкой под него.
Я узнал про Data Mining Cup в тот момент, когда мы поехали с группой от нашего университета на стажировку в Германию, по прибытию на родину мой друг и товарищ по команде предложил мне поучаствовать, дело было в середине апреля. Честно говоря, я отнесся скептически к этой идее, однако узнав, что в этом году данные и задача достаточно простые — мы все таки приступили к решению.
Как мы решали поставленную задачу
В 2019 году задача лежала в области self-checkout fraud detection. Наверняка вы уже сталкивались с кассами самообслуживания в супермаркетах. Данные аппараты работают как под надзором сотрудника магазина, так и полностью автоматически. Кассы самообслуживания позволяют оптимизировать расходы на персонал и минимизировать очереди в супермаркетах. Однако есть одна проблема, человеческая натура такова, что так или иначе возникает желание «не пробивать» товар, который мы хотим видеть в своём холодильнике. Чтобы этого избежать — необходим контроль, но такой, чтобы он не смущал и не надоедал покупателям.
Таким образом, на основе размеченных данных о self-checkout транзакциях, необходимо разработать математическую модель, которая бы автоматически относила ту или иную транзакцию к мошеннической или не-мошеннической. Итак, мы решаем задачу бинарной классификации.
Данные выглядели следующим образом:

Размер тренировочной выборки был всего ~1800 примеров, тогда как тестовой — 499000 примеров. Также, тренировочная выборка была не сбалансирована: всего 4% от транзакций являлись мошенническими, очевидно, что accuracy (доля верных ответов) тут применять бесполезно. Удивительно, но в данных не было пропущенных значений, а часть признаков была равномерно распределена. Исходя из этого, можно сделать вывод, что данные сгенерированы искусственно.
Также, организаторы предложили свою метрику в виде Confusion Matrix, которая измеряется в денежных единицах:
Проанализировав её, нам стало понятно, что Precision в данном случае важнее, т.к. мы несем максимальный убыток, если по ошибке назовем честного покупателя — мошенником.
Ход нашего решения состоял из классических этапов:
- Базовый анализ данных
- Анализ признаков, их описательных статистик и распределений
- Удаление выбросов
- Генерация признаков
- Построение модели и настройка параметров
- Валидация и финальный прогноз
Слайды с содержанием нашего решения можно найти по ссылке: www.docdroid.net/2XEDfYg/dmc-2019–1.pdf
Репозиторий на GitHub тут: github.com/Perevalov/dmc2019 (все разбросано по разным веткам, пока не было времени всё привести в порядок)
Организационные моменты подготовки к финалу
После того, как мы отправили финальное решение в начале мая, мы стали ожидать результатов. Условия организаторов таковы, что Топ-10 команд приглашаются на очный финал в Берлин, который проводиться в рамках конференции Retail intelligence summit 2019: Smart Decisions for Smart Retail.
Для справки, в 2019 году в DMC участвовало 149 команд из 114 университетов, расположенных в 28 странах.
Если честно, мы даже не надеялись пройти в финал, но вот, в конце мая приходит то заветное письмо с приглашением. Более того, всем финалистам предлагалось оплатить расходы до 500 Евро, а также предлагалось размещение в отеле на одну ночь, где и проводилось мероприятие.
Долго не раздумывая, мы купили билеты до Берлина и поехали оформлять визы. Являясь бедными студентами, сумма расходов на 2-х дневное путешествие получилась для нас немаленькой. Затраты на билеты Пермь-Берлин-Пермь и оформление визы встали примерно в 40000 руб. на одного человека, это чуть больше 500 евро.
Так как на мероприятии мы представляем свой университет, мы решили получить от него материальную поддержку. Тем более, Пермский Политех реализует программу развития Российско-Германских отношений и всячески поддерживает инициативных студентов (нам так казалось). Заручившись одобрением и подписью заведующего кафедрой, на которой мы учимся, мы отправились в отдел науки и инноваций. Там началась бюрократическая эпопея длиною в месяц, которая закончилась примерно следующим: «Денег нет, но вы держитесь». Мы конечно немного расстроились, но падать духом не стали. Теперь смешно читать различные заявления высшего руководства нашего ВУЗа о «необходимости поддержки молодых ученых» и другой ерунде. Ну это так, лирическое отступление.
Получили визы мы всего за 2 недели. За это же время мы подготовили доклад для выступления и уже 2-го июля вечером отправились в аэропорт.
Выступление на финале Data Mining Cup и награждение
Прибыв в Берлин 3-го июля с утра, мы отправились в nHow Hotel, где проводилась конференция. Уровень организации, конечно, высокий. Ещё бы, ведь стоимость участия в ней составляла 1000 евро на человека (для нас бесплатно). А вот так выглядит тот самый отель:

Наше выступление было назначено на 16:30. Проходило оно в основном конференц зале, естественно на английском языке. Кстати, само выступление никак не учитывалось в финальном рейтинге, он рассчитывался только на основании итогового скора, данные о котором были только у организаторов.
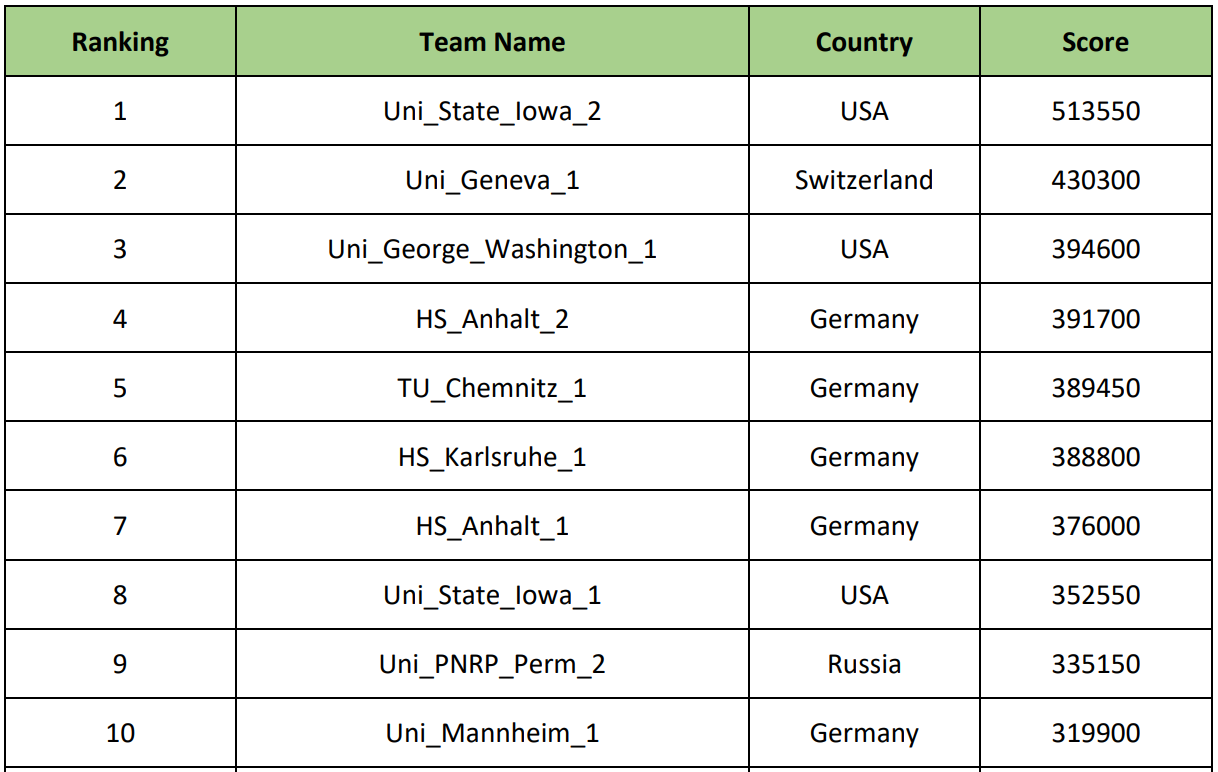
В числе первых 10 команд были такие университеты как: Университет Джорджа Вашингтона (США), Университет Женевы (Швейцария), Технологический университет г. Кемниц (Германия), Университет Айовы (США) и др. Ну и конечно наш Пермский национальный исследовательский политехнический университет.
Так выглядел конференц зал:

Небольшим конфузом был тот факт, что выступать пришлось не со слайдами, а с одним постером, выведенным на экран. Поэтому, выступления участников получились недостаточно информативными. Однако, была возможность подойти и рассмотреть бумажный постер каждого из участников в конференц зале. В основном, большинство людей применяли stacking, blending и ensembling (мы в их числе), также, некоторые участники использовали увеличенный threshold к моделям классификации, пара команд умудрилась вообще не заниматься генерацией признаков и строила модель на исходных.
Кстати, мы были самой малочисленной командой — всего 2 человека.
После выступлений начался праздничный ужин и награждение. Мы надеялись на призы, но понимали, что это маловероятно, поэтому нашим приземленным желанием было «хотя-бы не быть 10-ми». Получилось именно так, как мы и хотели — мы заняли почетное 9-е место. Естественно, было немного досадно, однако сам факт того, что мы оказались в финале среди таких серьезных университетов уже о многом говорит. Победителями стали участники из университета Айовы (США), хотя по ним не скажешь, что они приехали из штатов (см. фото):

Призы за 1-е, 2-е и 3-е места составили 2000, 1000 и 500 евро соответственно. Финальный рейтинг выстроился следующим образом:
Выводы
Мы ни сколько не пожалели об участии в данном соревновании. Как минимум, это +1 ачивка в портфолио, как максимум полезные контакты с людьми и возможность представить наш город и страну на международном мероприятии.
Всем дата сайентистам советую принимать участие в таких мероприятиях, это круто!
