Как создать свою СУБД с нуля и не сойти с ума. Практическое пособие начинающему некроманту. Часть первая

Наступил Апокалипсис.
Нет, не стоит бежать запасаться банками с консервами и крышками отечественной бай-колы! Апокалипсис произошёл только в нашей фантазии и с определённой целью — чтобы проверить, а может ли человек, обладающий только книгами по теме и стандартной библиотекой языка, воссоздать инструмент, который будет служить ему верой и правдой?
Так родился учебный проект SicQL, реляционная СУБД, чей символ — сова — это олицетворение силы знаний и мудрости. Олицетворение тех знаний и той мудрости, которые мы получим, создав с нуля то, чем мы пользуемся каждый день, может, не осознавая всей сложности таких инструментов.
Приглашаю присоединиться к увлекательному путешествию!
Содержание
Как создать свою СУБД с нуля и не сойти с ума. Практическое пособие некроманту. Часть первая (данная статья)
Предисловие
То, что я не могу создать, я не понимаю.
Ричард Фейнман, 1988 г.
Иногда мы слишком просто принимаем за должное то, что было создано кровью и потом прошлых поколений. Используем в качестве вызываемых библиотек в нашем скриптовом коде, используем в качестве хранилища бесчисленного множества заказов… И это нельзя считать за грех ровно до того момента, пока мы знаем, что мы делаем.
Но современная парадигма обучения программированию не всегда предполагает знание основополагающих принципов инструментов, с которыми мы работаем каждый день. И не было бы это проблемой, если бы не то последствие, которое вытекает из такого отношения — что бы вы думали о спортсмене-бегуне, который не знает, как работает его организм? «Ну бегаю и бегаю, что пристали-то?» —, а в решающий момент, за день до соревнования, потянет ногу каким-нибудь глупым упражнением. «Кто же знал, что так получится…» —, а вот мы постараемся такого не допустить.
Глава 0. Новое начало истории
Итак — мы немного отвлеклись — грянул Судный день. Его часы оттикали полночь и снова пошли по кругу. В новом мире постапокалипсиса не существует ни того количества дистрибутивов Линукса, ни новых версий Айфона каждый год — в общем, всего того разнообразия любимых (или не очень) плодов существовавшей ранее цивилизации.
Но давайте заранее условимся — мы всё-таки создаём учебный проект, а не по-настоящему симулируем (как бы это странно не звучало) новый, отчасти пугающий, мир. Поэтому, думаю, простительно, если мы всё же воспользуемся некоторыми библиотеками в тех местах, в которых мы не хотим излишне повышать сложность. У учёбы есть задача — научиться, научиться чему-то конкретному, и мы подробно разберём эти задачи в следующей главе про архитектуру базы данных. Если по пути воплощения в жизнь нашей СУБД возникнут задачи, которые не попадают в изначально установленные критерии, то будет разумно воспользоваться уже готовыми решениями.
Для начала хочу донести пару важных принципов, по которым была написана данная статья:
Структура статьи составлена таким образом, чтобы даже в мире постапокалипсиса по её тексту можно было воссоздать без особых других знаний эту СУБД. Пусть даже не с помощью языка Rust, а с помощью какого-нибудь новоизобретённого Rusty или C**.
Процесс создания SicQL продолжается и по сей день — сначала создавалась статья, а затем уже начались работы по воплощению СУБД, притом она, как и сама статья, неоднократно переписывалась в виду особенностей как меня, автора, так и Rust — прототипы за две недельки не напишешь. Так что советую заглянуть через пару месяцев в исходный код и увидеть если не бета-релиз, то хотя бы альфу, которую можно будет полноценно потыкать. И где-то там будет вторая часть статьи с ревизией положений, изложенных ниже, хе-хе.
Так как исследуемая тема настолько обширна, что даже отдельных статей на каждую часть архитектуры не хватит, то, во-первых, иные подходы к решению поставленных задач затрагиваются только мельком, во-вторых, многие полезные с точки зрения оптимизации вещи не реализованы даже в теории, а в-третьих, раздел используемых источников сконструирован таким образом, чтобы после прочтения данной статьи можно было бы более основательно углубиться в затронутые темы, что я и советую. В том числе, я ожидаю, что знающие люди в комментариях дополнительно расскажут про вышеперечисленные первый и второй пункты, что ещё более повысит ценность данного текста с точки зрения простора для размышлений и развития себя как разностороннего специалиста.
Ну что ж, мы зашли уже слишком далеко, чтобы останавливаться! В путь!
 Через час те из вас, кто останется в живых, будут завидовать мёртвым!
Через час те из вас, кто останется в живых, будут завидовать мёртвым!
Глава 1. Архитектура. Noctua ex machina
Что-что делаем?
Начнём с определения абстрактного класса BasedTable… Эй, погоди! А что делаем-то?
Базы данных — это круто, системы управления базами данных — ещё круче, реляционные системы… Ну вы поняли. Нельзя сказать «а давайте сделаем projectName», а затем начать усердно писать код — с таким оголтелым подходом к разработке мы не то что наткнёмся на неведомые подводные камни, но и вообще не закончим проект. Поэтому немного угомоним свои высокие порывы инженерной души и взглянем на ситуацию со стороны.
Всякий инженерный проект — это решение конкретной задачи. В частности, поэтому так желанная серебряная пуля невозможна — не существует универсального решения. В конце концов, мы учим железку действовать определённым образом в определённом контексте. Осуществляется ли это условными конструкциями if … else или определённым датасетом, который мы скармливаем нейронке, — не так важно. Важно то, что учителя, в итоге, — это мы. Поэтому от того, насколько мы сможем увидеть решение задачи заранее, и зависит успешность проекта.
Взгляните только на простого столяра, которому требуется смастерить табуретку — явно она не получается случайно в процессе изготовления — табуретка уже существует в голове мастера как законченный проект. Вот, в голове мы её крутим-вертим, разбиваем на составные части, прикидываем необходимые инструменты… И как-то в конце концов переносим нашу воображаемую табуретку в реальный мир. Магия!
Чем же отличается наш случай от столяра с табуреткой? Высокой степенью абстракций. Мы не ощущаем прямого контакта с данным произведением человеческого труда. Из этого и растут дальнейшие проблемы — непонятно даже за что ухватиться. Так что перед тем, как обучать машину решать задачу, давайте научимся решать её сами.
Перепридумываем перепридуманное
В сущности, задача стоит так — предоставить человеку относительно ясный и понятный интерфейс для работы с долгосрочным хранилищем данных. Во как — мысль наша пошла-поехала, начинаем разбивать задачу на подзадачи!
Какой самый удобный для человека, так скажем, визуальный интерфейс? Текст. Есть предположение, что человеку удобнее всего получать информацию из пиктограмм — но, во-первых, я такое даже и представить не могу (отсылаю к предыдущему параграфу), а во-вторых, нам нужно не только информацию извлекать, но и вносить. А как уж эти пиктограммы в компьютер заносить да обучить машину их считывать — это, извините, не ко мне, а к специалистам по машинному обучению. Остались они в постапокалиптическом мире или нет — ещё один хороший вопрос.
Отлично! Значит, взаимодействовать будем с помощью текста — тем самым нужен какой-то определённый язык… И тут в игру вступают ограничения, заданные изначально, то есть вроде наступивший постапокалипсис. Давайте условимся о том, что переизобретать SQL (к его сущности мы перейдём немного позже) мы не будем. Свою NoSQL базу данных сделаем как-нибудь в следующий раз.
Но так просто мы не отделаемся. Потому что под словами «переизобретение» в абзаце выше могут скрываться две вещи: переизобретение спецификации языка и переизобретение самого языка. Что это за странная игра слов? Смотрим ниже:
Допустим, в гипотетическом языке программирования под фирменным названием Language™ существуют две конструкции:
выражение + выражение?
выражение - выражение? …где выражение — число или одна из этих синтаксических конструкций, обособленных круглыми скобками (). Тут мы вступаем на одно очень интересное поле лингвистики, но не будем торопить события, всё успеем разобрать.
Замечательно — у нас на руках правила, которые задают синтаксис этого языка. Но синтаксис на то и синтаксис, что задаёт лишь правильное расположение лексем. Но как бы мы не ставили, хоть и правильно, слова в языке, он не может являться языком, пока он не будет что-то значить. Это называется семантикой языка.
Можно написать хоть сотни стандартов, описывающих синтаксис языка, но кто-то на этом языке должен говорить — собственно сама СУБД. Точнее сказать, вталдычивать программе о нужных нам записях в базе данных будем мы, но только таким образом, чтобы это понимала программа. Следовательно мы, авторы этой программы, должны каким-то магическим образом научить её понимать некоторое подмножество языка SQL. Именно это, я считаю, тоже можно считать за изобретение языка — хоть уже и по имеющимся стандартам, и всему прочему.
Дружим запрос с процессором
«Но кто-то на этом языке должен говорить…» Интересное заявление — мы начали одушевлять миллионы транзисторов на камне с работающей операционной системой на борту. Пока что он нам не отвечает — то, что мы ему пытаемся сказать, выходит за рамки его понимания. Для него всё бренное есть наличие или отсутствие напряжения на контактах.
Довольно пессимистично для начала, особо учитывая окружающую нас реальность. Но у нас давний друг, выручавший не одно поколение человечества — разум. И у этого разума есть занимательное свойство — способность к абстракции. Не важно, что мы имеем сейчас на руках — мы всегда можем придумать что-то лучше. Что-то, чем легче оперировать. А дальше дело будет за малым — пару миллионов электронных (где-то мы это уже видели) и химических сигналов, и абстрактное видение буквально осуществится с помощью наших ручек.
Но долой эту лирику — давайте строить мост между процессором и человеком с двух концов:
За какой конец взяться?
Конкретно разберём замеченную нами проблему: первое, мы не имеем представления, да и, желательно, не должны, о том, как процессор взаимодействует с данными, второе, мы не знаем, во что стоит переводить строку запроса.
Ответ кроется в разборе проблемы выше — чтобы знать, во что стоит перевести запрос, мы должны знать, как процессор работает с данными. Поэтому первый компонент нашей архитектуры должен быть тем, кто будет заботиться о правильном расположении данных в хранилище, то есть первым делом будем браться за бэкэнд нашей СУБД.
Что из имеющегося под рукой мы можем использовать под хранилище? Компьютер предоставляет нам две опции: храни данные либо в оперативной памяти, но до завершения своего процесса, либо в файловой системе, но надолго. Многие проблемы встанут перед нами только в случае хранения базы в файловой системе, поэтому условимся, что база будет представлять из себя одну большую последовательность записей в одном файле, который можно представить как массив в оперативной памяти, ведь мы хотим сохранить для пользователей такую возможность.
Далее — вот мы храним данные, но в каком формате? Записать белиберду — просто, а как её считать и преобразить обратно?
Сделать простое иногда во много раз сложнее, чем сложное, поэтому не будем изобретать велосипед, пока это нам напрямую не понадобится. «В лоб» задача решается следующим образом:

То есть в данный момент база представляет из себя один текстовый файл с последовательностью записей, предварённых заголовком с метаданными: какие поля есть в записях, какого они типа.
Из-за данного формата данных перед нами встали следующие проблемы:
Перед тем, как начинать операции с данными на диске, мы должны выгрузить их в оперативную память — иначе скорость работы будет неимоверно низкой. Но, допустим, нам нужна запись под номером 100500 — нам что, придётся загрузить все записи с 1-ой по 100500-ую? А если там хранятся гигабайты данных?
А как мы будем доставать 100500-ую запись? Как видно выше, каждая новая запись начинается на новой строке, то есть они разделяются символом переноса строки (в зависимости от платформы — CRLF/LF/…). Нам придётся считывать символ за символом, строку за строкой — звучит так же плохо, как и в предыдущим примере.
Текстовый формат данных — ну слишком жирно! Каждый символ (в том числе и пробелы, и переносы строк, и запятые) занимает 1 байт при кодировке UTF-8 или 2 байта при UTF-16. Звучит не так страшно? Представим 100000 записей всего лишь с одним знаковым целочисленным полем, хранящем максимальное число, которое можно уместить в 32 битах —
2147483647. В UTF-8 это поле занимает 10 байт, а бинарный формат, то есть запись, как есть — 4 байта,0x7f 0xff 0xff 0xffпри шестнадцатеричном формате записи. 6 байтов разницы, плёвое дело? Ну-ну — в итоге вместо ~390 килобайт данная таблица будем занимать весь мегабайт! В два с половиной раза больше!
Как мы можем решить эти проблемы?
Мысль первая: почему бы не разделить этот файл —, но не на отдельные файлы, а на сегменты, чей размер будет известен заранее?
Размер должен быть определён заранее и желательно не должен меняться. Если размер сегментов будет зависеть от количества строк (например, 100 записей в одном сегменте), то нам так же придётся считывать строку за строкой, пока не насчитываем достаточное количество для перевода страницы. Непорядок…Мысль вторая:, а если мы отойдём от текстового формата данных и перейдём к бинарному?
Если принять оба этих решения, то мы получим следующий формат файла:
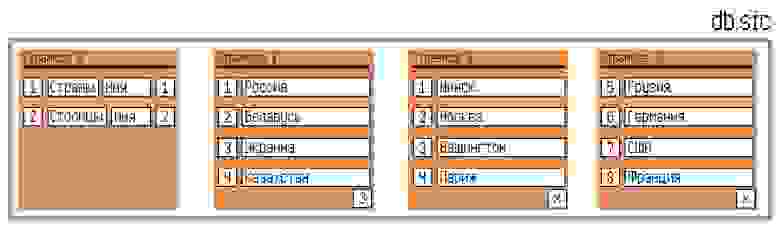 Foreign keys тут нет, простые списки названий стран и столицПримечание
Foreign keys тут нет, простые списки названий стран и столицПримечание
Так как теперь у нас нет знаков CRLF/LF, которые бы указывали на начало новой записи, то нам нужно либо располагать записи на странице особым образом, либо перед началом поля данных хранить тип, некоторый байт, чьё значение бы указывало на то, сколько байтов, за ним следующих, считать, и что они значат (строка, номер записи, целое число, число с плавающей запятой…).
Здесь и далее будем рассматривать это всё достаточно концептуально — записи располагаются последовательно на странице. О том, как это на самом деле будет происходить, будем смотреть уже во второй части статьи по реализации всех наших задумок.
В СУБД такие сегменты обычно именуются страницами, но могут встречаться и другие названия. Поэтому будем называть их именно страницами.
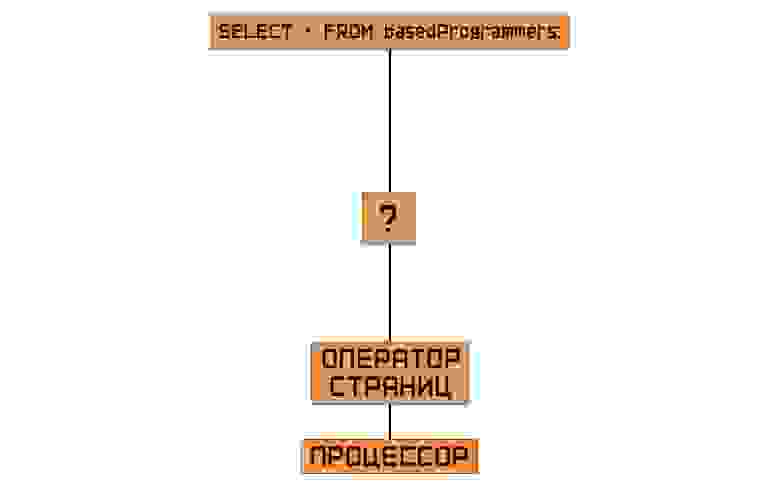
Теперь у нас есть файл базы данных, разделённый на страницы одного размера. В нашей архитектуре должен появиться герой, который сможет разобраться в этом, который сможет предоставлять вверх по цепочке структуры СУБД эти страницы.
В английской литературе его зовут просто — pager. Пейджер, то есть страничник. Диспетчер, оператор страниц. Звучит во всех случаях глупо, но ради сохранения консистентности текста будем называть его оператором страниц.
Этот оператор запрашивает данные у файла ровно по странице — и это сделано не просто ради решения тех проблем, которые мы выявили ранее, а ещё ради облегчения дискового процесса ввода-вывода. Диск, в отличие от оперативной памяти (и то оперативная память ведёт себя лучше, когда запрашиваемые данные расположены рядом друг с другом в виду внутреннего строения), считывает данные не по байтам, а по огромным сегментам — и операционная система так же хранит эти данные в страницах. Зачастую размер такой страницы равняется 4096 байтам, то есть 4 килобайтам. Так что такую особенность нужно оседлать и использовать в своих нуждах.
Вообще современные СУБД усиленно следят за количеством операций ввода-вывода, так как это повышает как скорость работы, так и время жизни накопителя, особенно, если он твердотельный. В этом участвуют многоуровневые кэши внутри структуры, строение хранящихся данных… Но современные СУБД сгинули в пучине ядерного огня, так что времени философствовать у нас не так уж и много!
Как вы заметили в примере с упрощённым бинарным представлением файла, в странице под номером 0 расположены названия таблицы вместе с номером той страницы, на которой таблица начинается;, а в самой странице, в конце, указывается номер следующей страницы, на которой следуют данные, которые не поместились в странице предыдущей.
Следите за руками — если одной страницы не хватает для расположения всех данных таблицы, то мы берём любую попавшуюся под руку свободную страницу (пусть она даже не будет последующей!), вписываем указатель в последнюю страницу таблицы, продолжаем записывать данные в новую страницу.
Немного отойдём от темы. Мне трудно было уместить в голову понятие указателей в бинарном файле — поэтому объясню в том числе и для читателей: указатель на страницу — это её индекс, смещение от начала файла. В том числе и указатель на байт в бинарном файле — это его смещение от начала файла.
Если вы уже знакомы с понятием указателей в оперативной памяти, то там адрес всегда указывает на одно и то же место в этой памяти. Если представить оперативную память как один большой файл, то указатель в ней практически то же самое, что и указатель в файле. Простое смещение от начала структуры…
«Берём любую попавшуюся под руку» — хе-хе, а руки-то вот они, не уследили! Такие вещи кто-то должен делать —, но точно не оператор страниц. У него цель одна — паковать данные в страницы. Что там дальше — это, извините, не его ответственность. Пусть мир перевернётся уже во второй раз —, но внутрь страницы не заглянет!
Значит нам нужен ещё один оператор… Если страницы соединить в продиктованном указателями порядке, то мы получим таблицу. Значит это… оператор таблиц! Как всё легко, оказывается!
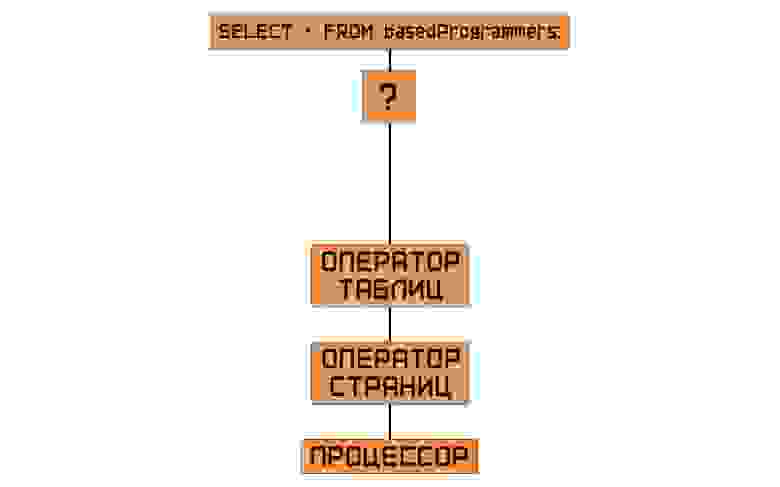
Оператор таблиц уже может заглядывать внутрь страницы — он может увидеть указатели, может увидеть, наконец, уже данные наших записей. Иными словами, оператор таблиц предоставляет вверх по структуре СУБД атомарные, то есть минимально возможные, инструкции над этими данными. Конечно, нам придётся поработать с тем, как эффективно хранить эти указатели, но, если особо не всматриваться, архитектура бэкэнда завершена. Внимательные читатели могли заметить, что мы упустили несколько важных вещей —, но мы к ним вернёмся, не переживайте.
Значит, приступим к созданию нашего фронтэнда — того, что будет понимать повеления пользователя и трансформировать их во внятные для бэкэнда инструкции.
На данном уровне абстракции запрос от пользователя представляет из себя строку. Как одну целую строку переделать в набор инструкций, да так, чтобы ещё и пользователь понял, что он сделал не так?
Если вы чутка знакомы с тем, как работают компиляторы и интерпретаторы языков программирования, то вы уже знаете ответ. В общем, подход такой: создать из строки промежуточные представления, на каждом из этих представлений производить как валидацию данного уровня анализа, так и подготавливать данное представление для следующего уровня.
Какие уровни анализа текста мы знаем из школьного курса русского языка?
Лексический анализ: на данном уровне предложение представляет из себя набор лексем, то есть характеристик слова на основе его происхождения, назначения, употребления в речи… Также могут включаться и отношения данного слова с другими в предложении, но для нас это уже перебор. Строка после проведения этого анализа переводится в массив лексем, которые точно присутствуют в языке SQL. Если пользователь ввёл SELECT …, то такая лексема существует, и мы передаём её дальше. Если же, по чистой случайности, в строке находится SLECT …, то ни о каком правильном запросе не может идти и речи, мы всё-таки просматриваем всю строку, и отдаём массив ошибок обратно пользователю. Почему не остановиться на первой ошибке? Да вы только представьте адские муки того, кто допустил множество ошибок в запросе на несколько строк! Переделывать запрос и опять скармливать СУБД… User experience first, как говорится.
Синтаксический анализ: предложение есть взаимосвязанный набор слов, представляющий из себя определённую структуру. Анализ данного уровня должен выявить эту структуру, и найти ошибки, если структура не удовлетворяет языку. Чаще всего эта структура называется абстрактным синтаксическим деревом, о чём мы поговорим в отдельной главе. Мы получаем набор лексем, не заботимся о том, правильные ли это слова (практически, так как всю такую грязную работу совершили на прошлом этапе), и выстраиваем отражающую взаимоотношения слов структуру.
Семантический анализ: слова, структуры слов, это понятно —, но предложение ведь должно нести какой-то смысл. Так как SQL это своего рода приказы — «возьми, обнови, вставь, создай», то и осмысливать это нужно как приказы — перед тем, как исполнить, стоит подумать о том, возможно ли вообще их исполнение. Если пользователь пытается получить несуществующее поле из таблицы, то он должен быть об этом предупреждён, а дальнейшая обработка запроса должна быть остановлена.
Дальше логика начинает расходиться, поэтому продолжим мыслить только в понятиях SQL. Этот язык в своей логике опирается на реляционную алгебру. Операции в этой алгебре представляют собой, если говорить упрощённо, навороченные логические операции. Множества, связи, перемножения, различные проекции… Что если семантически верное синтаксическое дерево (простите!) перевести в операции реляционной алгебры, раз уж в конце концов всё к ней и сводится? Таким образом мы облегчим сложность строения бэкэнда нашей СУБД, обеспечим будущую расширяемость функциональности — реляционная алгебра проще по строению, чем ветвистые и глубокие синтаксические деревья.
Произведя перевод всего запроса в реляционную алгебру, мы получили определённый план выполнения. Но кто сказал, что пользователь знает, как правильно составить план? Вдруг он не знает о существовании чего-то, что облегчило бы выполнение этого плана?
Данный этап называется оптимизацией запроса. В СУБД канувшей в лету цивилизации такая информация являлась, в большинстве своём, коммерческой тайной. Хранилась под строжайшим запретом, под семью замками и за пятиметровым забором из колючей проволоки. Возможно где-то тут кроется причина падения той цивилизации, но я, честно говоря, уже и не помню, что тогда было.
Но, в любом случае, делать оптимизацию мы не будем. Мы подготовили для себя фундамент, на котором можно будет легко, хе-хе, эту оптимизацию прикрутить. Но не сегодня — и так много чего весёлого впереди!
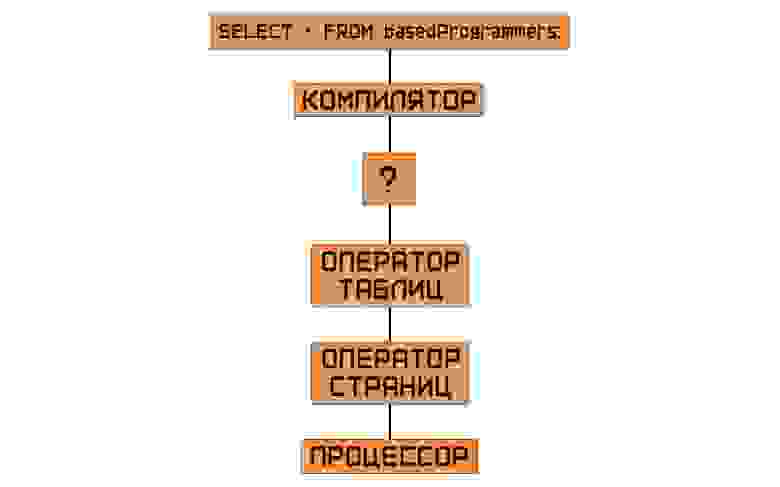
Мы оформили фронтэнд и бэкэнд. Компилятор предоставляет в бэкэнд план, записанный в формате реляционной алгебры, а оператор таблиц предоставляет, собственно, таблицы с записями в них, скрывая все страшные подробности хранения данных.
Но что-то не сходится… С одной стороны расположен план, а с другой — атомарные инструкции. Как будто здесь не хватает ещё одного компонента системы (если вы ещё не заметили это из картинки выше), который бы мог бы отработать по сгенерированному плану…
То, что мы упустили из анализа ранее, — и есть ключевой компонент СУБД, её сердце. Движок. Он-то и будет по высокоуровневым инструкциям (плану) производить вычисления над записями, которые предоставляет оператор таблиц.
Но здесь кроется ещё одна проблема — операции реляционной алгебры не так-то просты, они не всегда могут располагаться последовательно по смыслу, а, значит, движку придётся проводить предварительный анализ плана, что тоже увеличивает сложность компонента системы. Что же делать?
Решение этой проблемы кроется в ещё одном (боже мой!) анализе запроса. Теперь точно последнем. План, представляющий собой реляционную алгебру, можно перевести в последовательную цепочку инструкций, которую движок прочитает и выполнит так же последовательно.
Такой компонент уже можно называть не просто движком, а целой виртуальной машиной, со своим набором инструкций, регистрами и другими страшными вещами. Итого в строение компилятора (не просто так же он называется компилятором!) мы добавляем генератор кода для виртуальной машины, и этот код будет тем минимальным уровнем инструкций, которые может произвести ввод пользователя.
Мы смогли сохранить простоту каждого компонента нашей системы, не усложняя при этом общую цепочку взаимодействий — step by step, шаг за шагом запрос преодолевает проверки и преобразования, в конце концов добираясь до тех самых данных, ради которых и была затеяна вся эта история.
Скрываем реализацию — кто, что и кому должен?
Мы проделали долгий путь по общему анализу «подкапотной» нашей СУБД, с целью сохранения как простоты, так и концептуального содержания, чтобы не отбросить учебные (и немножко покрупнее — у нас всё-таки постапокалипсис за бортом) цели в угоду создания собственных велосипедов!
Но это не конец пути, а только начало. Поэтому сделаем привал, и посмотрим на то, что мы в итоге придумали — со всеми подробностями о том, какой компонент кому и что должен передавать по цепочке вызовов.
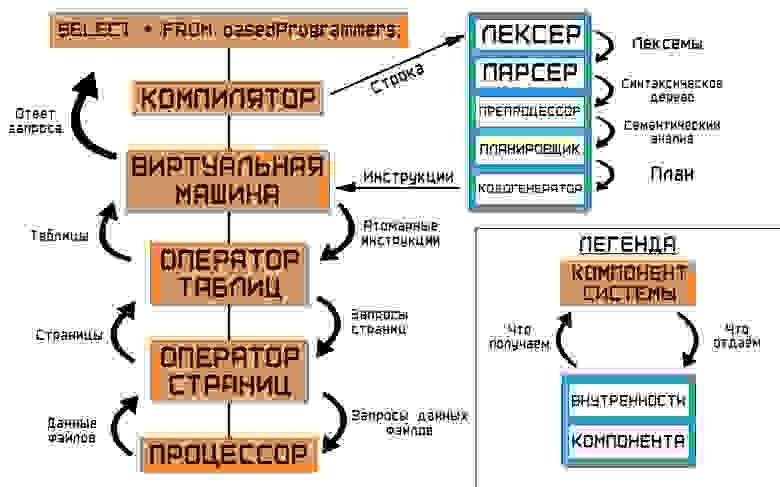
Каждый из компонентов скрывает свою часть реализации СУБД: компилятору не очень важно то, как данные хранятся на диске, как организованы соединения. У него есть своя часть работы — и он её должен выполнять, чтобы об этом не заботились нижележащие части нашей системы.
После общего анализа, разумеется, мы приступим к рассмотрению каждого компонента отдельно, рассмотрим подводные камни, которые мы не видели сверху, погрузимся в контекст — и, наконец-то, наломаем дров!
Глава 2. Транзакции, или как остаться без копейки в кармане
 Читаем странички базы конкурентно
Читаем странички базы конкурентно
Кислотный ACID
СУБД должна поддерживать несколько подключений к одной и той же базе данных. Несколько процессов, приложений, или несколько потоков в одном процессе должны иметь возможность взаимодействовать с одним файлом базы данных.
И тут начинает происходить какой-то неведомый ужас. Мы еле-еле сообразили, что делать с одним подключением, а тут уже появляются несколько. Наши мозги начинают потихоньку плавиться — возможно это влияние той радиоактивной кислоты с потолка. Хм, кислота…
Нам пришла ещё одна помощь из прошлого мира — это ACID. Странная аббревиатура, с моей точки зрения, так как переводится как «кислотный». Возможно, что она так называется потому, что СУБД должна работать, даже если случится кислотный дождь — что я имею в виду под этой аналогией? Рассмотрим, собственно, сами принципы, скрывающиеся за этими словами, правда, не очень последовательно:
I, Isolation — несколько транзакций могут происходить одновременно, и должны это делать без вмешательства одна в другую.
Когда-нибудь это закончится, и страшные новые слова перестанут появляться — но, видимо, даже ядерная война этому не поспособствует. Транзакции — это что такое?
Вот одно соединение может выполнить один запрос. И точно понятно, что никто иной в этот запрос не должен вмешиваться. Ну, по крайней мере, желательно. Тогда данный запрос можно рассматривать как отдельную транзакцию —, но что, если мы несколько расширим границы невмешательства с одного запроса на несколько? Мы предварительно скажем СУБД: «Вот слушай, сейчас я начну транзакцию, и я хочу, чтобы запросы внутри неё представляли нечто единое и неразделимое». Сделаем все наши грязные дела с данными, а потом завершим транзакцию. И нас вообще не беспокоит, что во время выполнения этой транзакции делают другие приложения — дай мне, наконец, уже мои данные, база!
 Где мои данные, база?!
Где мои данные, база?!
Вот и транзакция — это несколько запросов, которые должны с точки зрения СУБД представлять нечто единое. Это понятие поможет нам в будущем.
A, Atomicity — либо да, либо нет: транзакция или произошла, или была отменена, и все изменения, которые были произведены этой транзакцией, не произошли. Довольно простое понятие с точки зрения пользователя, так как «ну, а как что-то может произойти наполовину?», но разработчики СУБД уже не одно поколение ломают головы о том, как это можно поддерживать. Но кто думает о разработчиках?… Разберутся!
На то транзакция — это набор единых запросов и команд, которые не могут произойти только на половину. Если СУБД сказала, что транзакция исполнена — значит должна быть исполнена! Ну, или отменена, об этом тоже стоит помнить.
Вот, кстати, почему СУБД называется SicQL — от латинского слова sic! — что сказано, то сказано — и сделано! А то, что оно там связано с совами да сычами, — это вы надумали, ничего такого, хе-хе.
C, Consistency — база данных должна остаться согласованной, или хотя бы целостной (и это два разных понятия, разберём чуть ниже), до и после заверения транзакции. Здесь мы вводим понятия «заверения» транзакции, от английского commit (в контексте СУБД получается именно заверение, хотя перевести можно и иначе). Мы просим базу данных заверить выполнение транзакции — и или принять её, или отклонить. Но это разговор про Atomicity, здесь же вводится требование, что база данных не только должна поддерживать атомарность, но и согласованность данных.
Примечание
По слову commit кстати есть интересная история про наименования commit messages в системе контроля версий Git. Идут споры о том, в каком времени писать сообщения — в прошедшем, допустим, Added smth, или в настоящем, Add smth. Традиционным считается второй подход, хотя более логичным звучит первый. Бытует мнение, что вот, создатель Git, Linux и просто хороший человек Линус Торвальдс плохо владел английским, и поэтому сообщения к коммитам писал с ошибкой. Но это не так. Commit есть глагол «заверь», «подтверди», и сообщение должно правильно расшифровываться как «добавь что-то», а не «добавил…».
D, Durability — устойчивость. СУБД заверила транзакцию, но, вот те на, сервер потух. И устойчивая СУБД должна гарантировать то, что заверенная транзакция не будет потеряна даже в том случае, если случится апокалипсис, или, в локальном случае, если операционная система отдаст концы.
Но всё это чистая теория. Разрыв между практикой и теорией на практике в стократ больше, чем в теории. Посмотрим же на чистую практику.
Первая встреча с монстром конкуренции
Представим следующую ситуацию: процессы A и B имеют открытое соединение с одной и той же базой данных, в которой записан баланс кошелька определённого человека.
Процесс A хочет перевести на другой кошелёк 100 рублей. Он считывает данные из записи и получает 100 рублей — отлично, значит можно перевести — организовываем соединение с другим кошельком…
Как вдруг в эту ситуацию вмешивается процесс B. Он тоже хочет перевести на другой счёт 100 рублей. Считывает текущий баланс, получает 100 рублей — начинает производить бизнес-логику, в конце концов записав обратно баланс в 0 рублей.
Но вот процесс А организовал соединение, произвёл все вычисления и даёт задание СУБД записать баланс в те же 0 рублей. «Ну что, процесс — не дурак, делаем, как сказано», — и что же мы получаем в итоге?
Было 100 рублей. Перевели 200. Получили баланс в 0 рублей. Некрасиво получилось…
 А чё, так нельзя было что ли?
А чё, так нельзя было что ли?
Мы столкнулись с аномалией — то есть с таким поведением, при котором вроде бы верные с точки зрения одной транзакции изменения при выполнении вместе с другой транзакцией приводят к нарушению согласованности данных.
Что такое согласованные данные — вопрос хороший, так как в рамках СУБД мы определить это не можем. Целостность данных — можем (например, что данные в ячейке не должны равняться NULL), так как понятие целостности полностью лежит в поле управления СУБД. Согласованность данных же определяется приложением, пользующимся СУБД.
Оставлять это так, как сейчас, нельзя — мы переносим заботу о правильном порядке выполнения транзакций на пользователя —, а что это тогда за СУБД, которая не может (или не хочет) исполнять контракт по слежению за данными? Я даю СУБД данные, а она заставляет меня ещё и следить, чтобы они случайно не перемешались?
Нужно искать решение. И оно есть — в самом SQL.
Кладём болт на аномалии в реальном времени
Стандартом SQL (SQL92) определяются некоторые из известных аномалий, которые могут происходить в рамках одной транзакции:
