Как сделать свою рекомендательную систему: история одной дипломной работы

Каждая дипломная работа на курсе «Мидл Python-разработчик» в Практикуме — самостоятельный проект. Здесь нет подробных вводных или подсказок — студенты сами ищут решения и пробуют разные подходы. И здесь нужны все знания, которые накопились за время прохождения курса, а может, даже чуть больше. Звучит серьёзно, но студентов трудности не останавливают. В этой статье расскажем, как команда выпускников курса создала рекомендательную систему для онлайн-кинотеатра с нуля.
Немного об устройстве курса
«Мидл Python-разработчик» — это полугодовой курс для тех, у кого уже есть опыт в разработке на Python. Во время обучения студенты создают собственный онлайн-кинотеатр на основе микросервисов. В качестве дипломного задания студенты должны выполнить командный проект — тему можно предложить самостоятельно или выбрать одну из предложенных авторами.
На выполнение задания отводится месяц. Наставники курса поддерживают студентов и помогают в сложных ситуациях. Если всё успешно, то команду допускают до защиты проекта.
Состав команды: Максим Колодников, Максим Черников, Кирилл Чебыкин, Артур Бурлака.
Выбор темы и организация процессов
Каждый выбирал тему дипломного проекта, исходя из своих интересов: кому-то было интересно машинное обучение, кому-то наскучило работать с API, а кому-то захотелось углубиться в data science. У всех нас были разные причины заняться созданием рекомендательной системы, но так или иначе мы оказались в одной команде.
Времени на работу было не так много, поэтому мы сразу распределили задачи между собой. Условно, у нас было два направления: data science, который непосредственно связан с рекомендательной системой, и обвязка, к которой относятся различные API, хранилища и другие технологии. Другими словами, кто-то собирал приложение из разных сервисов, кто-то читал статьи и изучал подходы, а кто-то занимался непосредственно проработкой ETL-процессов в приложении.
Весь проект так и протекал — у каждого была своя роль в команде. Максим Колодников был нашим лидом: он нас курировал, собирал информацию по тому, как продвигается процесс. А мы занимались своими задачами, синхронизировались на общих созвонах, обсуждали подходы и подводные камни.
Исследование систем
Мы провели исследования, для чего вообще нужны рекомендательные системы, что они в себя включают, каких бизнес-метрик позволяют добиться. Персонализированные товарные и контент-рекомендации используются для повышения конверсии и среднего чека, а также для улучшения опыта пользователей. Самые известные примеры использования этого подхода — компании Amazon и Netflix.
В итоге мы определили два типа рекомендательных систем, которые хотели бы реализовать: рекомендация фильмов, которые похожи на просматриваемые в онлайн-кинотеатре, и рекомендация фильмов конкретному пользователю в соответствии с его предпочтениями и оценками.

У этих двух подходов разные инструменты. В первом случае мы использовали косинусное сходство (cosine similarity) как некую меру дистанции между фильмами, которая зависела от актеров, режиссеров, сценаристов и жанров. Чем меньше значение, тем сильнее фильмы похожи друг на друга. В итоге у нас получалась матрица дистанций между всеми фильмами, по которой довольно легко определить ближайшие. В нашем случае мы отсекали 10 ближайших фильмов к целевому.
Это была упрощенная рекомендательная система, которая позволяла решить проблему холодного старта, когда у нас нет данных о пользователях, но мы хотим всё-таки посоветовать им фильмы для просмотра.

Второй подход связан с рекомендациями для конкретных пользователей. Здесь предполагалось, что у нас есть определённая информация по фильмам: условная табличка, где каждый юзер поставил фильму оценку. Мы хотели бы предсказать, как пользователь оценит фильм, который он ещё не смотрел, на основании других оценок пользователей.
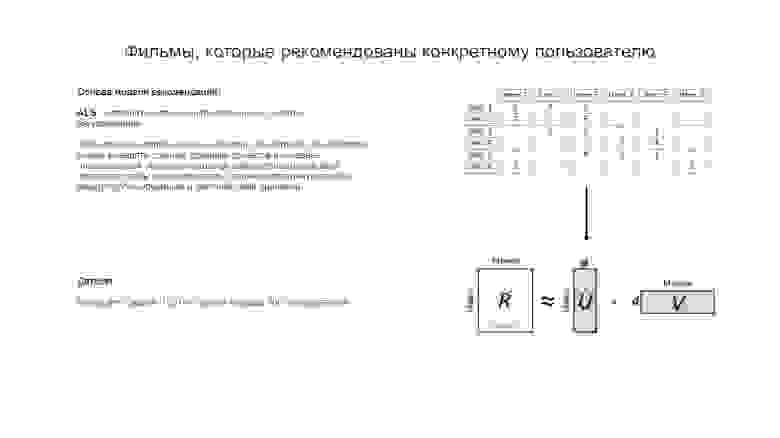
На этот случай тоже есть различные алгоритмы, основанные на факторизации матриц. Мы остановились на ALS, реализация которого есть на Spark. Суть алгоритма заключается в том, что мы раскладываем исходную матрицу оценок пользователей на две матрицы с факторами. Далее итеративно подбираем такие значения, чтобы при произведении этих матриц получалась матрица, наиболее близкая к исходной, но с заполненными пропусками. Заполненные пропуски в дальнейшем можно интерпретировать так: какую оценку поставил бы фильму пользователь, если бы посмотрел его. Эти новые оценки в дальнейшем станут основой для наших будущих рекомендаций.
Вот несколько статей на эту тему, которые помогли нам:
И ещё один момент. В нашем проекте мы рассматриваем так называемые явные оценки (explicit). Но в реальном мире пользователь часто не оценивает просмотренные фильмы, поэтому данных получается недостаточно. В этом случае мы можем использовать неявные оценки (implicit): покупки, лайки, репосты, просмотры. Подробнее про работу с подобными оценками на примере ALS можно почитать тут:
Создание архитектуры
По сути у нас должна была получиться одна система рекомендаций, которая по-разному выдаёт значения для разных сценариев использования. Мы придумали такую архитектуру.
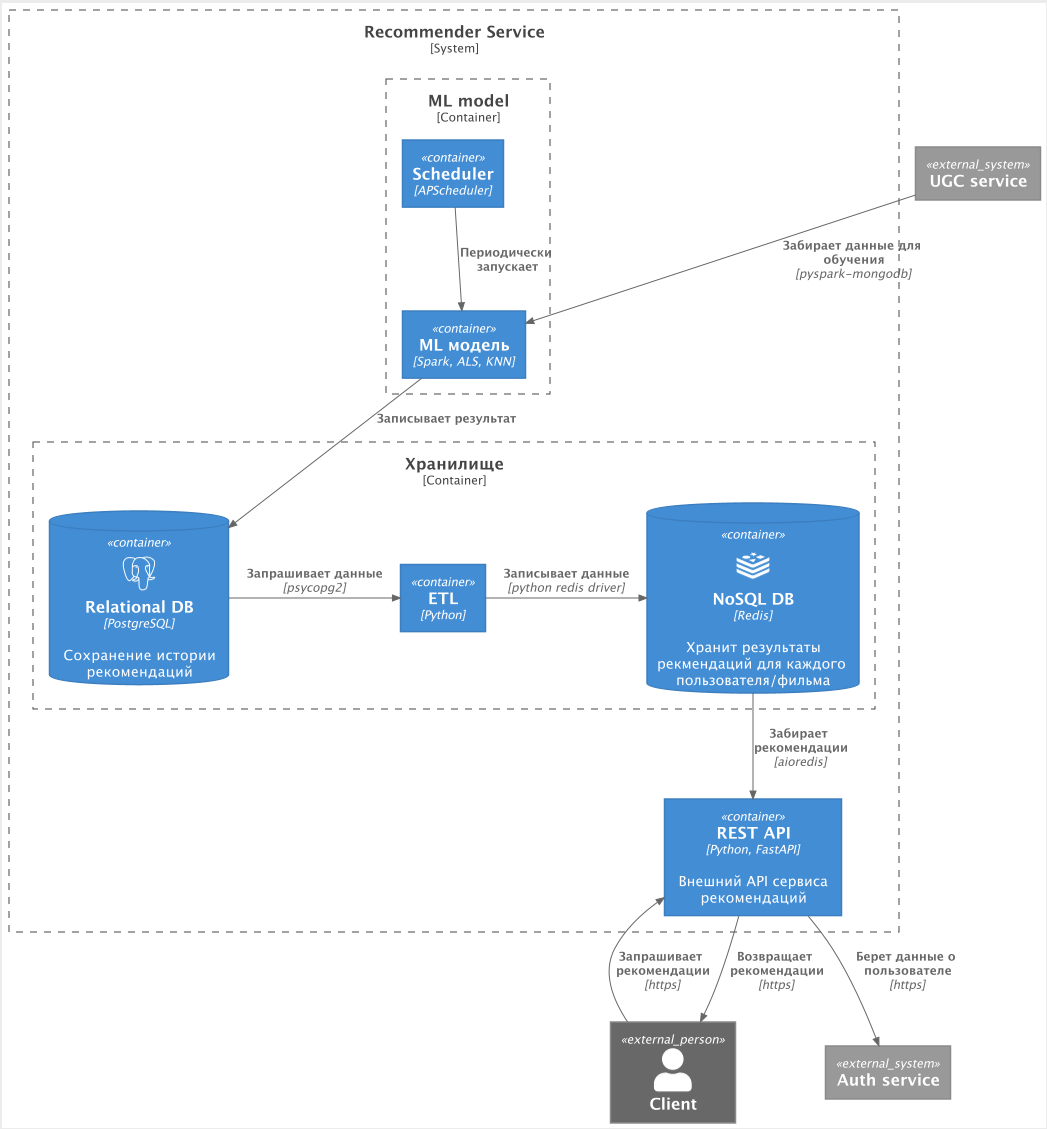
В одном из учебных спринтов мы создавали UGC-сервис, который должен собирать данные для ML-модели. Запуск системы происходил с помощью Scheduler. Сами модели мы забирали в Spark, обрабатывали данные, и результат отправлялся в PostgreSQL — во внутреннюю базу, где хранилась вся история рекомендаций. Это нужно для дальнейшего анализа или для отката в случае сбоев.
Данные из PostgreSQL копировались в Redis — в кэш, который непосредственно обращался к пользовательскому API. То есть клиентские запросы уходили в кэш, чтобы разгрузить базу, и поэтому в Redis хранились только самые свежие рекомендации — то есть результат последней работы модели.
Соответственно, первая рекомендательная система просто строила расстояния между фильмами на основании их схожести и сохраняла по 10 ближайших фильмов в базу PostgreSQL. А затем копировала её в Redis, чтобы к ней был быстрый доступ из API.
Такая же история со второй рекомендательной системой, но она уже использовала Spark для факторизации матриц, то есть строила рекомендацию для конкретного пользователя, а информация для каждого пользователя тоже заносилась в Redis и PostgreSQL.
Предполагалось, что ML-модель будет запускаться раз в сутки, стягивать все необходимые данные, генерировать список для каждого пользователя из 10–20 фильмов и по 10 для каждого фильма.
Когда пользователь заходил на сайт или на страницу конкретного фильма, он триггерил API-сервис, который обращался уже к кэшированным данным в Redis и выдавал рекомендации либо по конкретному фильму, либо персонализированные рекомендации.
Все технологии — Spark, PostgreSQL, Redis, Rabbit, Fast API — связаны кодом на Python. Вот схема взаимодействия всех этих сервисов: данные про фильмы, актёров и режиссёров лежали в PostgreSQL, а данные о лайках пользователя — в UGC-сервисе.
Эту архитектуру мы обсудили с наставником. По итогам разговора мы добавили базу для сохранения историчности. Если представить продакшн использования этой системы, то наличие постоянной базы с историей всех предсказаний очень полезно для будущих аналитиков. Либо есть опция забрать данные в непредвиденной ситуации: например, если в рекомендациях начал появляться какой-то бред, то можно достать предыдущие рекомендации для пользователя и откатиться к ним.
О результатах
Рекомендательная система получилась неидеальной, но всё равно показала хороший результат. Ниже представлены итоги работы той части, которая ищет ближайшие фильмы к просматриваемому. Например, по общей теме «война машин и людей» получилась хорошая выборка: «Я, робот», «Призрак в доспехах», «Матрица», «Терминатор». Но есть и минус: в подборку попали сиквелы. По остальным темам рекомендации тоже более-менее совпадают.

К сожалению, вторую часть рекомендательной системы мы не смогли проверить на реальных пользователях, потому что использовали уже готовые данные для обучения и тестирования ML-моделей.
Например, у пользователя с ID 100 паттерн жанров фильмов повторяется: везде romance, drama, action. Так у него вырисовываются предпочтения, на основе которых система и будет предлагать фильмы к просмотру. В третьем столбце стоят оценки, которые, как мы считаем, пользователь поставил бы указанным фильмам.

В итоге мы получили ошибку по метрике RMSE, равную 0,86. Другими словами, предполагаемая оценка фильма отклоняется в среднем на 0,86 от той, которая стоит на самом деле. Этот показатель можно снизить, но уже не в рамках дипломной работы.
Были и штуки, которые не удалось доработать. Мы так и не внедрили систему отката. А ещё не прописали что-то вроде «холодного старта» для тех случаев, когда у нового пользователя нет рекомендаций.
Ещё была идея сохранить историю рекомендаций в отдельное аналитическое хранилище. И сделать фильтрацию, чтобы не рекомендовать человеку то, что он уже смотрел. Да и в целом можно было реализовать другие типы рекомендаций, например выделить группы пользователей и рекомендовать им фильмы. Но всё упиралось во время и другие ресурсы.
Оценка проекта
 Руслан Юлдашев
Руслан Юлдашевнаставник курса «Мидл Python-разработчик», кофаундер и технический директор MODME — CRM/LMS edtech startup, кофаундер в Academy Department Head, MARS IT SCHOOL
Ценность командных работ на курсе строится из двух ключевых составляющих.
Приобретение командного опыта. Имею в виду опыт совместной коммуникации, принятия решений, декомпозиции и распределения задач. Часто именно в этих навыках скрывается дальнейший рост мидл-разработчиков.
Есть такое понятие — закон Конвея. Он гласит: «Организации проектируют системы, которые копируют структуру коммуникаций в этой организации». Множество раз видел подтверждение этих слов на практике. То есть способности и методы коммуникации разработчика с другими коллегами напрямую влияют на архитектуру его ПО.
«Обстукивание» идей, мыслей, решений друг об друга — то, что даёт решениям дополнительную валидацию, сверку с тем, как это воспринимают другие люди. В итоге работающие в командах студенты, которые активно взаимодействуют между собой и с участниками курса, эффективнее и полнее выполняют дипломную работу.
Взаимоподдержка и мотивация. Учиться непросто. Если двигаешься один, легче дать себе поблажку или просто застрять на непонятном моменте или сложном решении. При работе в команде гораздо легче решаются обе эти проблемы: вы поддерживаете друг друга и несёте личную ответственность, а ещё становится проще соблюдать внутренние дедлайны.
Чем хороша эта дипломная работа: ребята грамотно разделили зоны ответственности по своим сильным сторонам, что позволило им глубоко проработать тему. Они подготовили промежуточные диаграммы по архитектуре своего решения, к которым они обращались и обновляли по ходу разработки. Они продумали две модели для рекомендации — на основе сходства и на основе оценки пользователей. А главное, что они понимали пределы своей работы — что ещё не доделано и куда дальше развивать их продукт.
Немаловажный фактор: они хорошо оформили итоговую презентацию, которая позволяет внешнему эксперту понять, что они сделали. Ребята начали с общей задачи и бизнес-требований, рассказали про архитектуру всего решения, детали отдельных моделей и продемонстрировали на практике работу своей системы рекомендаций.
