Как СберБанк Онлайн на микросервисную архитектуру мигрировал и от legacy старался избавиться

Привет, Хабр! Сейчас мы, команда СберБанка Онлайн, проводим очень масштабную работу по миграции на микросервисную архитектуру. Проект стартовал много месяцев назад, и сейчас уже можно поделиться некоторыми результатами и соображениями. Так мы и решили поступить — делимся нюансами этой работы в статье, которая написана по мотивам выступления Артёма Арюткина, исполнительного директора и руководителя проектного офиса. Подробности нашей трансформации — под катом.
Что такое СберБанк Онлайн
Чтобы понять масштабы трансформации, сначала приведём важнейшие характеристики СБОЛ как продукта:
У него 75 млн MAU.
Развитием продукта занимается больше 200 команд.
120 тысяч входов в минуту мы наблюдаем в обычный день.
Ежегодный рост нагрузки — около 15%.
Высокая надёжность сервисов — 99,99 (допустимый простой до 52 минут в год).
Почему такая высокая надёжность? Мы просто не можем позволить себе быть недоступными. Скажем, если в магазине ребёнок просит вас купить что-то либо, или потребуется отправить платёж продавцу, партнёру или коллеге, то СБОЛ должен быть доступен. Для бизнеса и обычных пользователей это очень важно.
Чтобы чуть лучше погрузиться в проект, посмотрим на архитектуру.
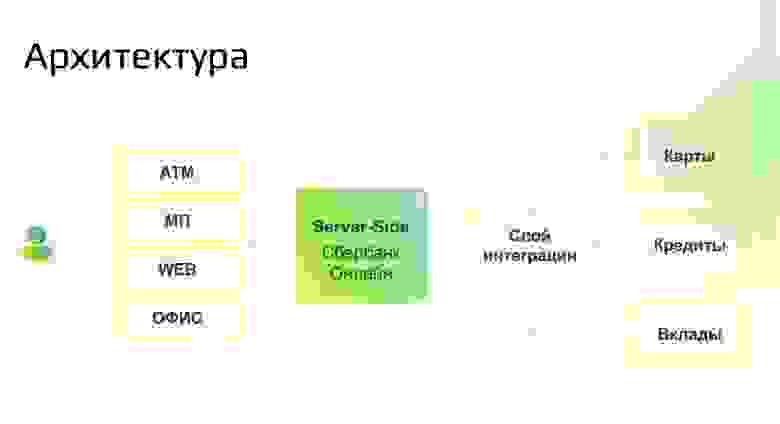
Каналы, через которые работает клиент — банкоматы, веб-сервисы, приложения для iPad сотрудников в офисе и другие элементы. Server-side Сбербанк Онлайн — именно тот монолит, который мы планируем распилить с вашим участием на микросервисы. Важно понимать, что сам СБОЛ не открывает вклад, не проводит платёж, а представляет собой интерфейс для взаимодействия с теми самыми системами, которые отвечают за:
проведение клиентских транзакций — процессинг;
решение о процентной ставке кредита — кредитная фабрика;
решение о выдаче кредита и т. п.
И ещё один важный элемент — организационная структура. Она важна для понимания контекста и тех вызовов, с которыми мы столкнёмся.

Наша организационная структура условно представлена на картинке выше. Есть трайб — организационная единица, бизнес-подразделение: объединение бизнеса и ИТ в единую структуру для повышения управляемости и скорости вывода продуктов на рынок. На картинке выше это «Платформа Сбербанк Онлайн», «Платежи и переводы» и так далее.
В каждом трайбе есть кластеры: «Клиентская сессия», «Интеграция» и другие А внутри кластера несколько разных команд. Команда — это владелец продукта (product owner) и инженеры разработки, отвечающие за свой продукт e2e. При этом, мы, как лидеры трансформации находимся в одном из трайбов.
Почему это важно? Дело в том, что у нас около 200 команд, и каждая из них должна выполнить определённую работу для перехода с монолита на микросервисы. Этим процессом крайне сложно управлять, если вообще возможно. Решения принимаются каждым трайбом отдельно.

В самом начале работы мы решили выяснить, где могут возникнуть проблемы. А их виделось немало.
Первое и ключевое — матричная структура. Она накладывает серьёзные ограничения. К примеру, ты не можешь напрямую влиять на решения, принимаемые продуктовыми командами, на их мотивацию. Если вы когда-то видели седого менеджера с дергающимся глазом, скорее всего, это продукт-менеджер, работающий в матричной структуре и ведущий проект с большим количеством заинтересованных сторон.
Вторая причина в том, что, в зависимости от трайба и беклога команды в нём. К примеру, для одной из команд, задача перехода на микросервисы может иметь высокий приоритет, так как это совпадает с их интересами по ускорению вывода на рынок, желанием трансформации и смены технологического стека, и, в целом, команда готова сейчас инвестировать в это. У другой команды может стоять серьёзный выбор между трансформацией и улучшением сервиса для клиента. Тут менеджеру проекта и менеджеру команды приходится серьёзно подумать над тем, как «сплести» задачи бизнеса и ИТ.
Высокие требования к надёжности. Трансформация любого legacy — это вызов. Нужно продумать, что и как поменять, определиться с возвратом инвестиций и ожидаемыми эффектами. К тому же, нужно минимизировать влияние на клиентов. В системах, которыми клиенты пользуются с 9 до 18, продумать внедрение и оценить риски чуть легче, чем в продуктах, где 75 млн активных пользователей и мы не можем позволить себе недоступность. Так что это отдельная задача, как всё это бесшовно внедрить.
Как с этим можно бороться
Общие KPI для бизнеса и ИТ на уровне топ-менеджмента. Несмотря на то, что подобная трансформация — это явно ИТ-проект, нам следует вплести бизнес-эффекты в инженерную трансформацию.
Мы должны «продавать» концепцию командам и рассказывать им о том, как и куда они двигаются. Не стоит пытаться написать чёткую инструкцию или ТЗ, или нанять армию архитекторов, так как пытаться решить таким образом задачу в подобных масштабах будет безумием.
Ответственность на уровне команд. KPI у топ-менеджмента — это важно и удобно, но у них их много. Хорошим решением будет сфокусировать команды на решении этой задачи, добавив KPI и на их уровень.
Для чего мы это затеяли
Чтобы ускорить вывод на рынок отдельных новых продуктов и сервисов. И здесь есть затруднение: текущая архитектура не позволяет использовать механику независимой разработки. То есть вся эта история трансформации началась ради клиента и ускорения доставки новых продуктов до него. А позволит нам это сделать независимая продуктовая разработка.
Кроме того, трансформация позволяет снизить стоимость legacy с помощью снижения количества «железа» в нём, а также количества доработок, так как те ресурсы, что были вовлечены в работу с legacy, мы переключаем на работу на новой платформе.
И напоследок, мы не занимаемся трансформацией ради трансформацией, мы переплетаем задачи бизнеса и инженерные задачи, что позволяет повысить нашу эффективность.
С чего начать
Всё бы хорошо, но на входе — огромное количество команд, которые работают сами по себе, и непонятно, как заставить их двигаться в едином ритме. Дело в том, что нельзя, например, нанять армию архитекторов, которые всё сделают в сжатые сроки, это дорого и очень ресурсозатратно. Вместо этого можно использовать другой вариант: ввести ответственность на уровне команд. Они должны понимать её, а также выгоду от трансформации.
Исходя из тех целей и общих вводных, которые у нас есть, мы приняли крайне важное решение: начать с самых популярных сервисов с максимальным количеством уникальных пользователей в месяц. Это сделано для ускорения вывода на рынок. Ведь компании нужно снизить количество изменений, которые вносятся в legacy, и направить усилия на микросервисы. Пример самых популярных действий с максимальным количеством пользователей и операций:
Кроме всего прочего, эти операции ещё и самые высоконагруженные.
Почему так? Основные ресурсы разработки нацелены на постоянное улучшение клиентского опыта в самых важных для клиента сервисах. Это означает, что чем скорее мы перестанем дорабатывать монолит и переключим инженеров на новую платформу, тем скорее мы снизим стоимость владения legacy, ускорим вывод на рынок и улучшим клиентский опыт.
Как оценивать успех трансформации?
Менеджер — не тот, кто напоминает вам каждый день про задачу, а тот, кто правильно объясняет всем цели. Любой проект нужно начинать только после того, как мы договоримся, а как же будем оценивать свою эффективность. То есть мы должны договориться о метриках. Чтобы было понятно, насколько успешно движется вперёд процесс миграции на микросервисную архитектуру, мы ввели несколько метрик.
Количество мигрировавших бизнес-сервисов. Казалось бы, самая простая метрика из возможных. Но есть нюанс, о котором менеджер не должен забывать: далеко не все операции, которые переводятся на новую архитектуру, равноценны. Есть такие, что выполняются у десятков миллионов пользователей, а есть те, что получают лишь сотни тысяч уникальных пользователей в месяц.
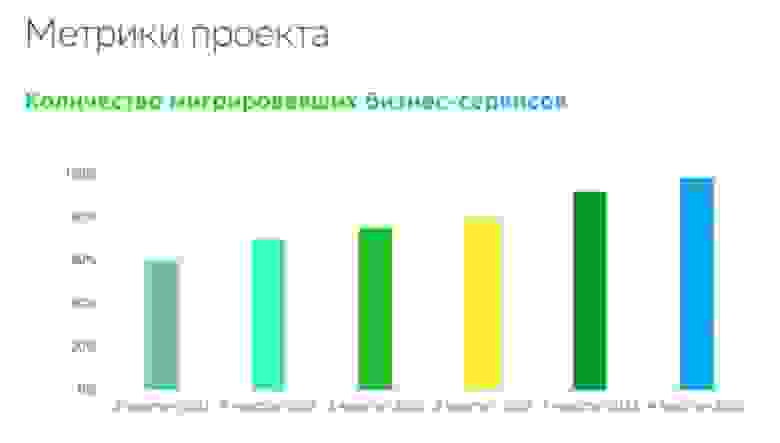
Поскольку равнозначными их считать нельзя, можно ввести дополнительные критерии оценки. Например, веса каждой из операций, либо, что ещё лучше, количество клиентских операций в legacy. Эта метрика очень хорошо себя зарекомендовала.
Количество операций в legacy. Оно должно у нас падать, радовать глаз и подтверждать, что мы движемся в верном направлении.

Эта метрика, к слову, исторически коррелируется с загруженностью «железа». Участвуя в проекте по надёжности СБОЛ, я годами начинал свое утро с того, что смотрел этот график.
Но вот в один прекрасный день что-то пошло не так.

Смотрим сюда и понимаем, что загруженность железа не падает, несмотря на то, что количество клиентских операций значительно снизилось. И тут нам стоит начать нервничать!

Количество изменений в legacy. На графике видно, что количество изменений в legacy интенсивно падает, так как в начале мы сделали правильный выбор, начав с самых популярных операций. Всплески стоимости связаны с тем, что иногда legacy дорабатывалось для интеграции с микросервисами.
Ещё в рамках этой метрики стоит поговорить о людях. Это самое дорогое, что есть в нашей системе. И одна из главных задач трансформации — как можно быстрее перевести разработчиков с работы с legacy на развитие новой платформы.
Метрики помогли выяснить несколько важных факторов, включая как приятные, так и не очень:
Нагрузка на инфраструктуру не падает с той скоростью, на которую рассчитывали; «о, боже, всё пропало!»
Мы очень эффективно сократили стоимость владения legacy.
Количество изменений в legacy падает, но кто-то всё ещё продолжает его дорабатывать!
Сейчас проект по трансформации завершён примерно на 75%. Нагрузка на инфраструктуру снижается очень медленно. И в этот момент хочется задуматься над профессионализмом продукт-менеджера.
Давайте попробуем вместе понять, а в чём же, собственно, причина.
Есть гипотеза, что проблема в постоянном росте нагрузки, которая, как упоминалось выше, увеличивается на 15% каждый год. А это означает, что для снижения нагрузки на «железо» в legacy нужно делать так, чтобы нагрузка падала на эти 15% плюс ещё на сколько-то, иначе это будет рост, а не падение. Верна ли гипотеза, посмотрим дальше. Разберём несколько других проектных метрик.

Нагрузка на БД. Возьмём метрику elapsed time. На графике видно, что есть запрос 1, который явно вырывается вперёд и потребляет больше всего ресурсов. В целом, все те запросы, что изображены на графике, потребляют 80% ресурсов (из использованных). Оставшиеся 20% потребляют около 45 других запросов.
Здесь стоит сказать, что микросервисы обращаются к legacy, что, в целом, нормально. К тому же, ранее я упоминал, что мы работаем в матричной структуре в продуктовой организации и команда А, отвечающая за миграцию конкретного сервиса, сейчас может иметь иной приоритет, и мы, как организация, с этим приоритетом согласны. Команда Б может иметь зависимость от А, но нам лучше пустить её вперед, оставив технический долг по интеграции с А на следующий этап. Это позволит нам правильно освободить команду Б и позволить ей двигаться дальше.
Ещё из любопытного отмечу, что у нас не было плана мигрировать сервисы 1–5 как можно скорее. Да, они сильно нагружают инфраструктуру, но частота их доработок и изменений значительно ниже, чем у тех, что мы выбрали в качестве приоритетных.
А ещё новые продукты могут использовать старые сервисы. Это нормально, поскольку иногда на legacy скорость вывода нового продукта или фичи может быть сильно выше. Как пример, приходит бизнес со срочным запросом и высоким ожидаемым результатом от реализации. Тогда вполне можно принять решение о реализации сервиса на legacy или с использованием его сервисов.
Нагрузка на серверы приложений. Ниже приведена диаграмма с интересными результатами. Почему первый столбец такой высокий? Всё объясняется достаточно просто: за время существования системы произошло очень много организационных изменений, к тому же за разработку в legacy отвечала выделенная команда. Как итог, здесь «потерялся» владелец сервиса. Да, такое бывает. И да, далее встает вопрос ресурсов и готовности команды взять ответственность на себя. Напомню, что у нас нет выделенной под проект команды, а значит пришлось потратить несколько месяцев, прежде чем владелец «нашёлся» и начал работу.
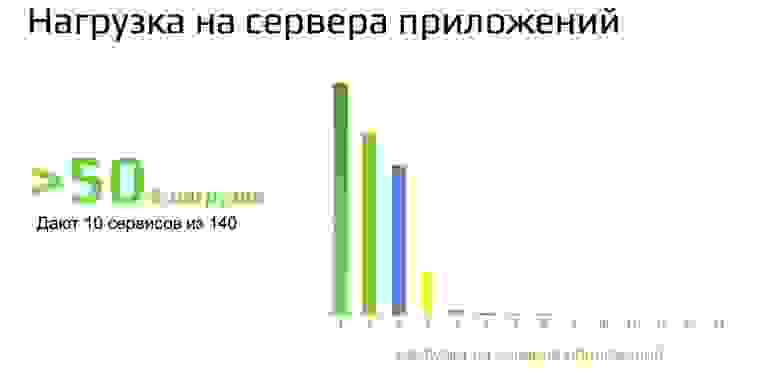
Кстати, половину нагрузки на инфраструктуру дают 10 основных сервисов из 140.
Если оценивать метрики, отражающие нагрузку на инфраструктуру, то проект находится не в лучшей стадии.
Что можно было улучшить в ходе трансформации?
Давайте вместе пофантазируем, могли бы мы что-то поменять. Стоит сказать, что, несмотря на все сложности, миграцию мы провели и сейчас всё работает отлично. Но можно было сделать ещё лучше. Как?
Взять за ключевую метрику загруженность железа. Это привело бы к тому, что мы перенесли те сервисы, которые больше всего загружают инфраструктуру. Так как они реже всего меняются, количество доработок на legacy продолжало бы расти. А значит, у нас росла бы стоимость владения системы, и при этом скорость изменений для важных клиентских сервисов оставалась бы низкой.
Использовать строгий архитектурный контроль доработок и используемых сервисов. Это нужно для оптимизации миграции на микросервисы: правильная расстановка последовательности, запрет на доработки legacy. Недостаток в том, что растёт стоимость разработки и замедляется скорость изменений. Причина проста: увеличение количества архитекторов и проект-менеджеров, рост расходов на согласование. К тому же, у нас всегда будут исключения, так как срочность ещё никто не отменял.
Что в итоге?
Оглядываясь назад, мы видим, что сделали правильно и в чём ошиблись:
Мы начали с сервисов с самым большим количеством пользователей. Это позволило разрабатывать и развивать новые продукты с ускоренным выводом на рынок, масштабировать инфраструктуру и снизить стоимость владения legacy.
Не нужно было гнаться за сокращением инфраструктуры. Именно в нашей ситуации этого не требовалось;, но легко представить себе сценарий, в котором эта задача стала бы приоритетной.
Введение общих KPI для бизнеса и IT позволило ускорить трансформацию за счёт вовлечения бизнеса и переплетения бизнес-задач и трансформации.
Введение ответственности на уровне команд для усиления их вовлечения в трансформацию.
Что же, на сегодня всё. Уверены, мы далеко не единственные в РФ, кто проводит сейчас подобную трансформацию с переходом на микросервисы. Если вы реализуете схожие проекты, расскажите о результатах в комментариях, пожалуйста. Кроме того, если есть вопросы, то задавайте, постараемся ответить!
