Как самому разработать систему обнаружения компьютерных атак на основе машинного обучения
На фото — Arthur Lee Samuel, пионер машинного обучения, демонстрирует возможности искусственного интеллекта и играет в шашки с собственной программой Checkers-Playing, одной из первых самообучающихся программ в мире. 1962 год.
Спустя почти 60 лет, я решил познакомиться с машинным обучением и научить свою собственную программу — систему обнаружения компьютерных атак — находить вредоносный трафик в сети.
Как разработчик средств защиты информации я в общих чертах представлял архитектуру такой системы. Но как ML инженер, который должен был научить ее, я мало что знал.
В этом длинном посте я расскажу о своем опыте разработки модели машинного обучения, по шагам: от поиска хороших данных и сокращения признакового пространства до настройки и апробации модели на реальном трафике. С примерами, графиками, открытым кодом.
Вступление. Машинное обучение и информационная безопасность
Да, сегодня все знают про машинное обучение. Умная колонка и онлайн-кинотеатр угадывают ваше настроение и близко к идеальному предлагают в рекомендациях следующий трек/фильм. Когда вы звоните на «горячую линию» банка, трудно понять, кто отвечает — робот или живой человек. Беспилотные автомобили уже на дорогах общего назначения.
Но как связаны машинное обучение и информационная безопасность?
Признаться, тяжело представить себе распространение технологий AI/ML в проекты и приложения информационной безопасности. Пока не пролистаешь отчет из Стэнфорда «AI Index 2019 Report», 220 страниц о современном состоянии дел в области искусственного интеллекта.
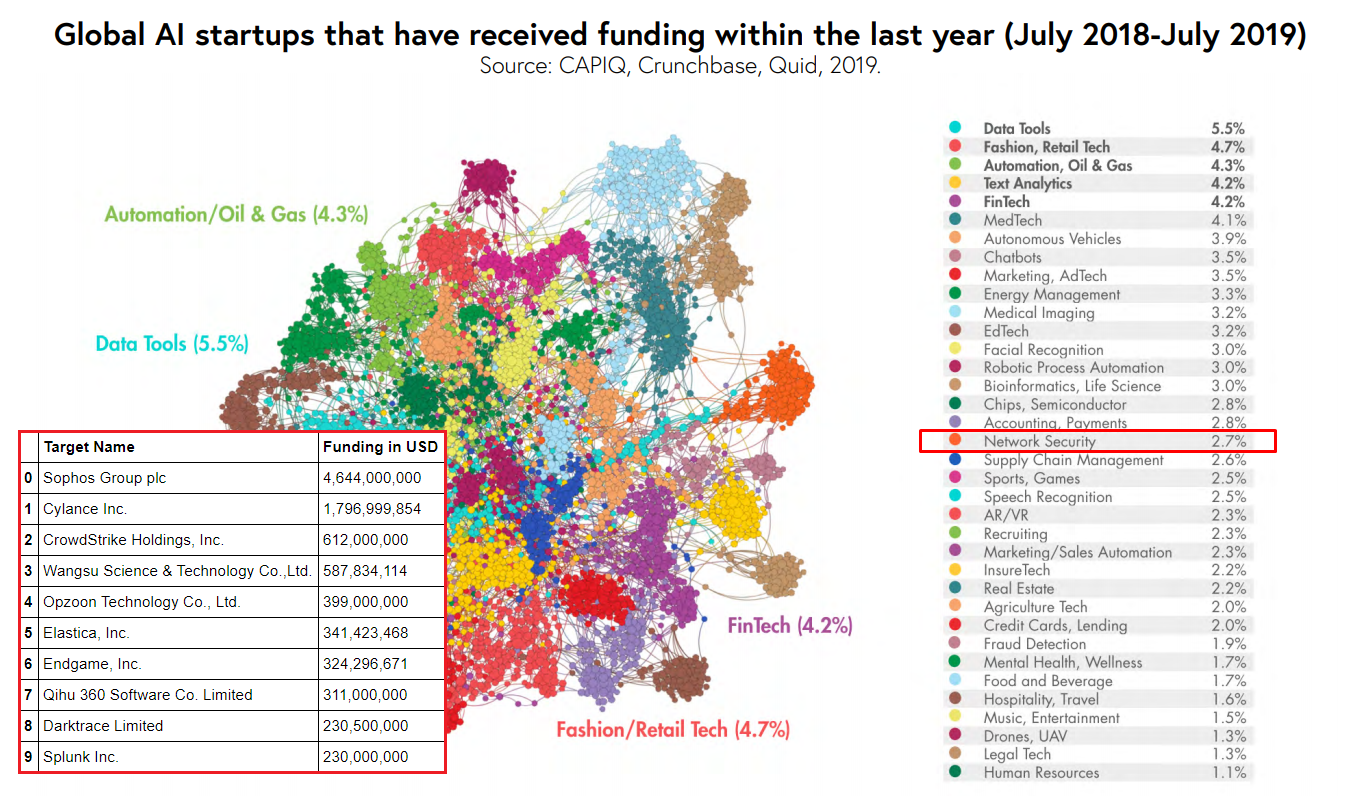 Привлечение инвестиций ведущими мировыми разработчиками средств защиты информации с применением технологий искусственного интеллекта
Привлечение инвестиций ведущими мировыми разработчиками средств защиты информации с применением технологий искусственного интеллектаВыводы после прочтения отчета:
Направление «Сybersecurity» («Network Security») — это около 3% мировых частных инвестиций в «стартапы», использующие технологии искусственного интеллекта. Впечатляюще.
В блокноте я подсчитал объемы привлеченных инвестиций ведущими мировыми разработчиками средств защиты информации с использованием AI (таблица на рисунке выше). В топ-10 из знакомых имён — только Splunk. А кто такие Sophos, Cylance, CrowdStrike, Wangsu, Opzoon? И с какими питчами они привлекают миллиарды долларов?
Среди продуктов лидеров построенного рейтинга — антивирусы, средства обнаружения атак, управления инцидентами, анализа защищенности, защиты от утечек, спам-фильтры, threat intelligence, почти вся номенклатура СЗИ. ML, как минимум, делает вид, что работает везде.
Итак, у меня есть желание разобраться в машинном обучении. Есть опыт в разработке средств защиты. Известны примеры успешных реализаций СЗИ c ML. Что мешает попробовать — самому, «с нуля» разработать систему обнаружения компьютерных атак на основе машинного обучения? Вперед!
Дисклеймер. Разрабатываемая система обнаружения атак призвана не заменить, а лишь дополнить сигнатурный анализатор с целью повышения общей эффективности системы, особенно в отношении ранее неизвестных атак.
Последовательность шагов
Уже после прохождения первых курсов обучения и первых набросков, пытаясь упорядочить последовательность шагов при построении модели ML, я обнаружил типовую схему и на ее основе разработал план действий:
Выбор набора данных для обучения системы обнаружения компьютерных атак.
Предварительная обработка данных.
Сэмплирование против дисбаланса классов.
Оценка значимости и отбор признаков.
Сокращение признакового пространства.
Выбор модели.
Настройка и обучение модели.
Тестирование и апробация.
Далее — по шагам.
Оригинальная схема обучения с учителем от Sebastian Raschka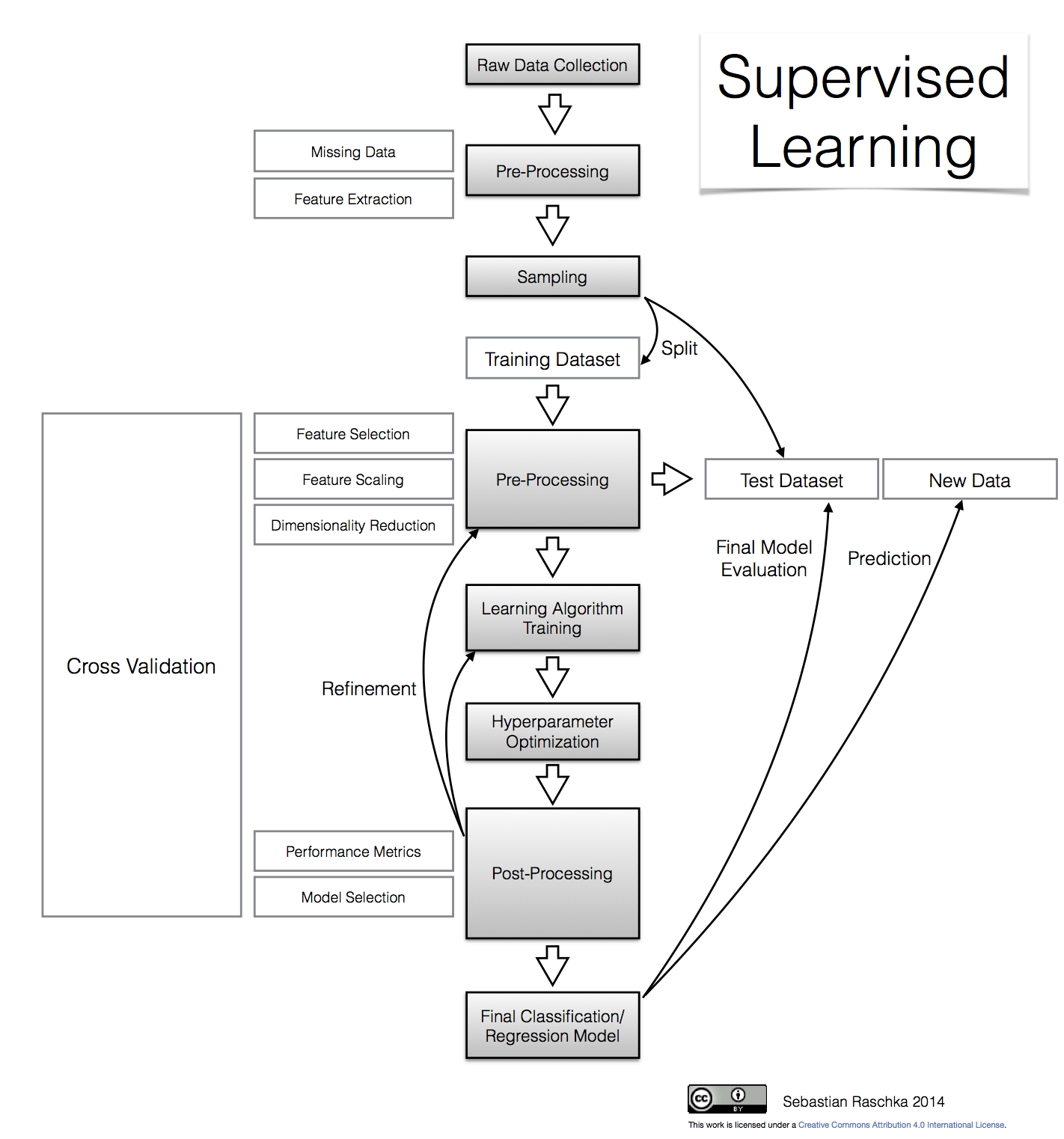 Типовая схема обучения с учителем
Типовая схема обучения с учителемШаг 1. Выбор набора данных для обучения
Для обучения системы обнаружения атак среди доступных публичных наборов данных (DARPA1998, KDD1999, ISCX2012, ADFA2013 и других) я выбрал один из наиболее актуальных (на момент начала исследования) — «Intrusion Detection Evaluation Dataset» CICIDS2017. Разработчик — Canadian Institute for Cybersecurity. Набор данных CICIDS2017 подготовлен по результатам анализа сетевого трафика в изолированной среде, в которой моделировались действия 25 легальных пользователей, а также вредоносные действия нарушителей.
Набор объединяет более 50 Гб «сырых» данных в формате PCAP и включает 8 предобработанных файлов в формате CSV, содержащих размеченные сессии с выделенными признаками в разные дни наблюдения. Краткое описание файлов и количественный состав набора данных представлены в таблицах ниже.
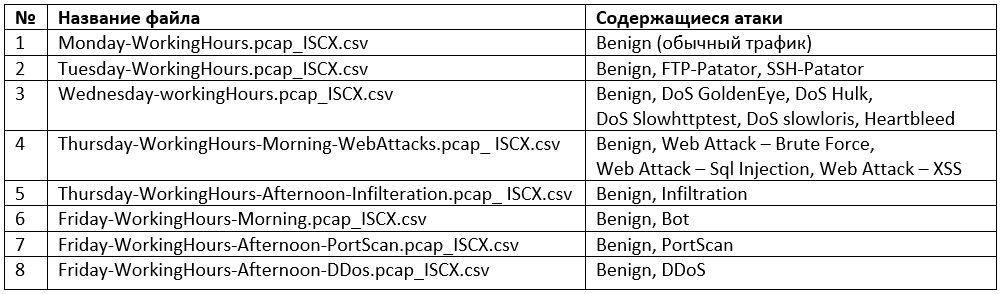 Описание файлов набора данных CICIDS2017
Описание файлов набора данных CICIDS2017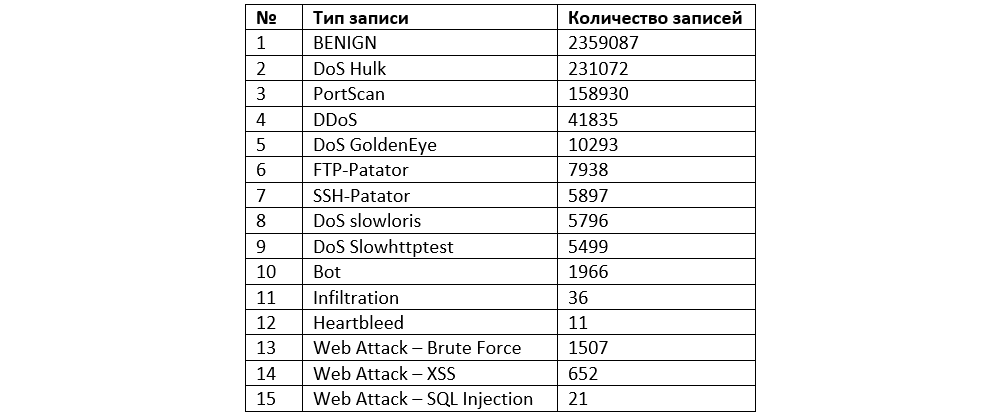 Количественный состав набора данных CICIDS2017Пример одной записи из набора данных CICIDS2017
Количественный состав набора данных CICIDS2017Пример одной записи из набора данных CICIDS2017Каждая запись соответствует сетевой сессии и характеризуется 85 признаками.
Flow ID, Source IP, Source Port, Destination IP, Destination Port, Protocol, Timestamp, Flow Duration, Total Fwd Packets, Total Backward Packets, Total Length of Fwd Packets, Total Length of Bwd Packets, Fwd Packet Length Max, Fwd Packet Length Min, Fwd Packet Length Mean, Fwd Packet Length Std, Bwd Packet Length Max, Bwd Packet Length Min, Bwd Packet Length Mean, Bwd Packet Length Std, Flow Bytes/s, Flow Packets/s, Flow IAT Mean, Flow IAT Std, Flow IAT Max, Flow IAT Min, Fwd IAT Total, Fwd IAT Mean, Fwd IAT Std, Fwd IAT Max, Fwd IAT Min, Bwd IAT Total, Bwd IAT Mean, Bwd IAT Std, Bwd IAT Max, Bwd IAT Min, Fwd PSH Flags, Bwd PSH Flags, Fwd URG Flags, Bwd URG Flags, Fwd Header Length, Bwd Header Length, Fwd Packets/s, Bwd Packets/s, Min Packet Length, Max Packet Length, Packet Length Mean, Packet Length Std, Packet Length Variance, FIN Flag Count, SYN Flag Count, RST Flag Count, PSH Flag Count, ACK Flag Count, URG Flag Count, CWE Flag Count, ECE Flag Count, Down/Up Ratio, Average Packet Size, Avg Fwd Segment Size, Avg Bwd Segment Size, Fwd Header Length, Fwd Avg Bytes/Bulk, Fwd Avg Packets/Bulk, Fwd Avg Bulk Rate, Bwd Avg Bytes/Bulk, Bwd Avg Packets/Bulk, Bwd Avg Bulk Rate, Subflow Fwd Packets, Subflow Fwd Bytes, Subflow Bwd Packets, Subflow Bwd Bytes, InitWinbytesforward, InitWinbytesbackward, actdatapktfwd, minsegsizeforward, Active Mean, Active Std, Active Max, Active Min, Idle Mean, Idle Std, Idle Max, Idle Min, Label
192.168.10.14–65.55.44.109–59135–443–6, 65.55.44.109, 443, 192.168.10.14, 59135, 6, 6/7/2017 9:00, 48, 1, 1, 6, 6, 6, 6, 6, 0, 6, 6, 6, 0, 250000, 41666.66667, 48, 0, 48, 48, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 20, 20, 20833.33333, 20833.33333, 6, 6, 6, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 9, 6, 6, 20, 0, 0, 0, 0, 0, 0, 1, 6, 1, 6, 513, 253, 0, 20, 0, 0, 0, 0, 0, 0, 0, 0, BENIGN
Хорошие данные — обязательное условие для построения хорошего классификатора.
В обзорах набора данных CICIDS2017 (Intrusion2017, Panigrahi2018, Sharafaldin2018) отмечались проблемы дисбаланса классов, сложной файловой структуры, пропуска значений. Эти замечания я принял как некритичные.
Сегодня у меня есть вопросы по аккуратности разметки набора данных CICIDS2017 (связаться с авторами набора данных и задать вопросы не удалось — ни по личным адресам электронной почты, ни через Canadian Institute for Cybersecurity), но именно по этой причине мне пришлось самому разработать весь pipeline — начиная от сниффера и предобработки сетевых сессий, заканчивая моделью машинного обучения и тестированием в реальной сети.
Получается, больше приобрел, чем потерял.
Шаг 2. Предварительная обработка данных
Отправной точкой для проведения собственных экспериментов с датасетом CICIDS2017 послужило исследование Kahraman Kostas «Anomaly Detection in Networks Using Machine Learning». При попытке воспроизведения этого исследования были обнаружены расхождения в результатах, а потом и ошибки в коде автора. Я связался в апреле 2020 года с Kahraman Kostas, мы обсудили варианты исправления ошибки, однако по состоянию на январь 2021 года код в репозитории по-прежнему некорректно оценивает значимость признаков.
Для сокращения времени вычислений в обучающей выборке был оставлен единственный класс атак — веб-атаки (Brute Force, XSS, SQL Injection). Для этого я подготовил подвыборку «WebAttacks» на основе обработки файла Thursday-WorkingHours-Morning-WebAttacks.pcap_ISCX.csv из набора данных CICIDS2017. Набор WebAttacks включает 458968 записей, из которых 2180 относятся к веб-атакам, остальные — к нормальному трафику.
Этапы предварительной обработки набора данных CICIDS2017 и подготовки подвыборки WebAttacksТакое решение упрощает задачу и снижает качество итоговых выводов: многоклассовая классификация свелась к бинарной классификации, значительно уменьшился размер обучающей выборки.
Исключение признака «Fwd Header Length.1» (признаки «Fwd Header Length» и «Fwd Header Length.1» являются идентичными).
Удаление записей с null значениями идентификатора сессии «Flow ID» (из 458968 записей после удаления осталось 170366 записей).
Замена нечисловых значений признаков «Flow Bytes/s», «Flow Packets/s» значениями -1.
Замена неопределенных значений (NaN) и бесконечных значений значениями -1.
Приведение строковых значений признаков «Flow ID», «Source IP», «Destination IP», «Timestamp» к числовым значениям методом label encoding.
Кодирование ответов в обучающей выборке в соответствии с правилом: 0 — «нет атаки», 1 — «есть атака».
После прочтения обсуждения «Should I normalize/standardize/rescale the data?» понимаю, что вопросы нормирования данных — это отдельное исследование.
Я храню Jupyter блокноты на Github в репозитории ml-cybersecurity, а ссылки даю на Google Colabоratory — тогда код готов к запуску прямо в браузере.
Исходный код в Google Colabоratory
Матч с канадцами. Поиск и исправление ошибок в датасете
На этапе предварительной обработки данных я обнаружил погрешности в признаковом пространстве (как минимум, подозрительным показалось наличие двух разных признаков с попарно одинаковыми значениями). И решил выполнить проверку: взять «сырой» трафик CICIDS2017, самому выделить в нём сетевые сессии и сформировать свой датасет. Мой датасет должен был совпасть с датасетом CICIDS2017.
Обрабатываю pcap файл с записанным траффиком своим сниффером, выделяю сессии и признаки, сравниваю с датасетом Thursday-WorkingHours-Morning-WebAttacks.pcap_ISCX.csv, пытаюсь понять и исправить расхождения. Да, расхождения есть.
Подробности поиска ошибок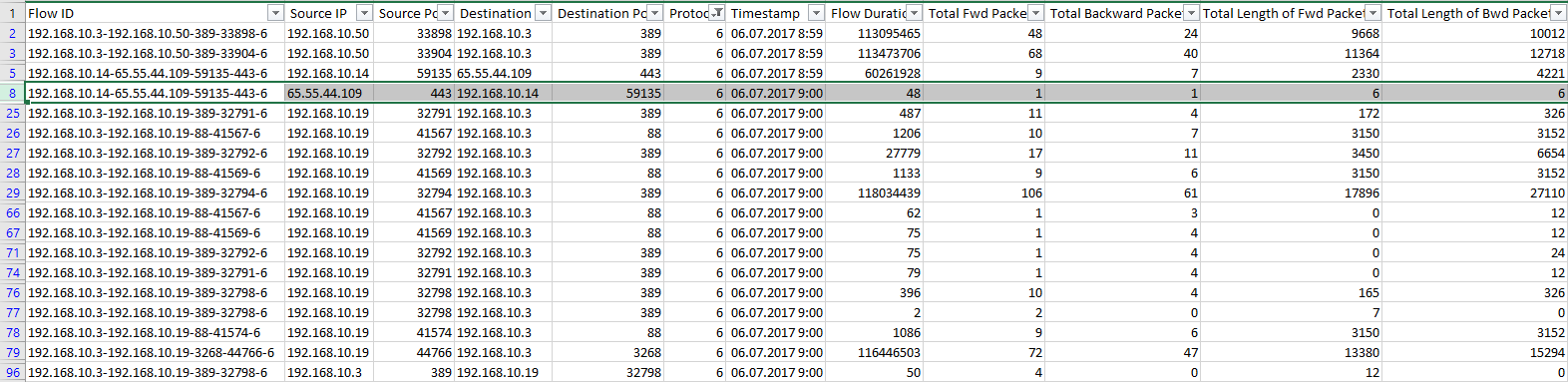 Выбранная сессия для анализа
Выбранная сессия для анализаАнализирую сессию Flow ID = »192.168.10.14–65.55.44.109–59135–443–6», Source IP = »65.55.44.109». У канадских исследователей два последних пакета выделены в отдельную сессию? Внимательно просматриваю исходники их сниффера и нахожу подтверждение в методе addPacket.
Что нужно учесть в моем сниффере:
При появлении пакета с флагом FIN в направлении forward для воспроизведения эксперимента нужно завершить текущую сессию и создать новую. Чтобы два последних пакета FIN ACK и ACK попали во вторую сессию вместе, условие прерывания сессии нужно дополнить: количество пакетов в сессии должно быть больше 1.
Завершение сессии по таймеру, 120 секунд (хотя в readme сказано про 600 секунд).
Иду дальше. Для той же сессии в прямом направлении зафиксирован один пакет («Total Fwd Packets» = 1), при этом общая длина переданных пакетов в прямом направлении «Total Length of Fwd Packets» = 6. По данным Wireshark, длина пакета = 0. Откуда разница в 6 байт? «Спускаюсь» от TCP до Ethernet и обнаруживаю «неучтенные» 6 байт в виде дополнения (padding) фрейма Ethernet. Спорная ситуация, нужно ли включать эти 6 байт в длину TCP пакета.
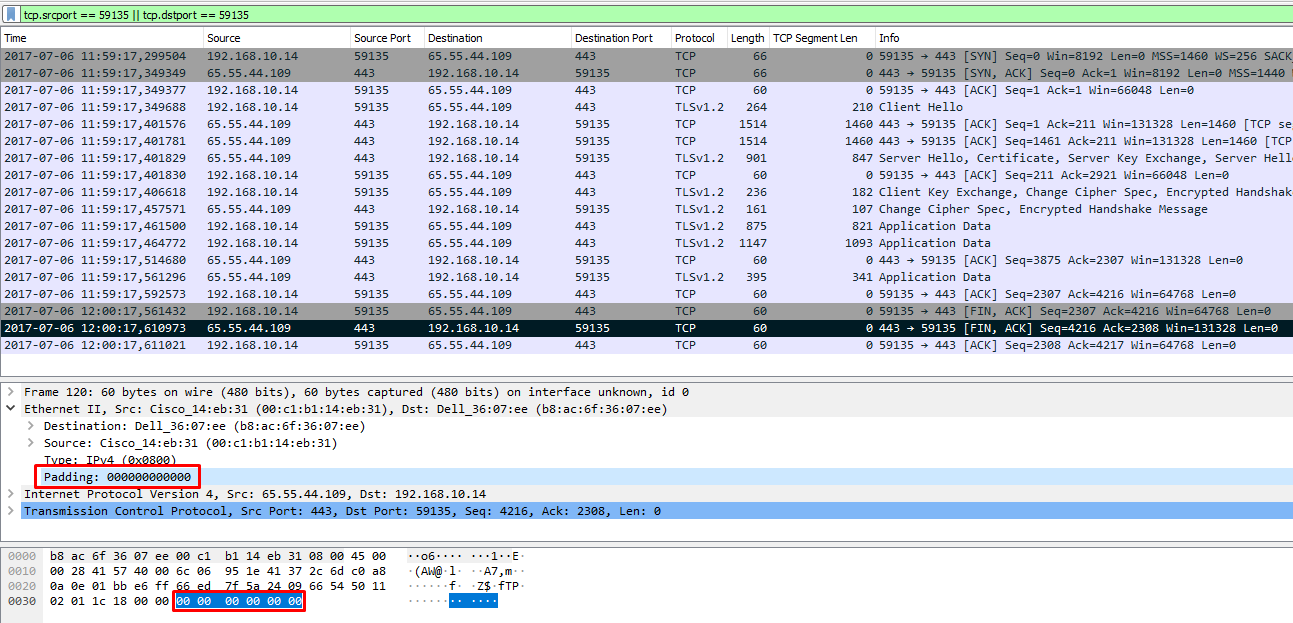 Проверка длины пакета в Wireshark
Проверка длины пакета в WiresharkПроверяю остальные признаки для этой сессии, совпадают все значения, кроме Average Packet Size = 9. Как при двух пакетах по 6 байт получить значение 9, не ясно. При этом Packet Length Mean = 6, совпадает.
Начинаю проверять другие сессии, и оказывается, что часто встречаются небольшие расхождения в признаках: Packet Length Mean, Packet Length Std, Packet Length Variance, Average Packet Size, Average Fwd Segment Size, Average Bwd Segment Size. Вскрытие (восстановление исходных слагаемых по значениям средних) показывает, что при срабатывании таймаута сессии длина отбрасываемого пакета ошибочно учитывается в статистике.
Как могу, обновляю свой код, добиваться полного соответствия датасетов (= вносить ошибки) не имеет смысла.
После устранения большинства расхождений в моем датасете и датасете CICIDS2017 можно двигаться дальше: теперь понятно, как вычисляются значения признаков по записанному трафику.
Шаг 3. Сэмплирование против дисбаланса классов
Подготовленная подвыборка «WebAttacks» является насбалансированной: при общем количестве записей 170366 класс «нет атаки» объединяет 168186 экземпляров, класс «есть атака» — 2180 экземпляров. Для устранения дисбаланса классов подойдет метод случайного сэмплирования (субдискретизация, undersampling), заключающийся в удалении случайно выбранных экземпляров класса «нет атаки». Целевое соотношение количества экземпляров классов «нет атаки» и «есть атака» я выбрал 70% / 30%.
Шаг 4. Оценка значимости и отбор признаков
Предварительно из признакового пространства были исключены признаки «Flow ID», «Source IP», «Source Port», «Destination IP», «Destination Port», «Protocol», «Timestamp» в предположении, что признаки «формы» (соответствующие статистикам сетевого трафика) являются более значимыми для общего случая. Кроме того, исключаемые признаки адресации могут быть относительно легко подделаны злоумышленником и не должны учитываться при обучении.
Анализ значимости признаков я выполнил с помощью встроенного механизма метода sklearn.ensemble.RandomForestClassifier (атрибут feature_importances_).
Первые результаты оценки значимости показали сильную взаимосвязь признаков «Init_Win_bytes_backward», «Init_Win_bytes_forward» с меткой класса в обучающей выборке, что может свидетельствовать о допущенных погрешностях при формировании набора данных. Дополнительные эксперименты показали, что можно построить достаточно точный классификатор, опираясь на один единственный признак — или «Init_Win_bytes_backward», или «Init_Win_bytes_forward». Указанные признаки были исключены из признакового пространства.
Итоговые результаты анализа значимости представлены на рисунке ниже, список ограничен первыми двадцатью признаками.
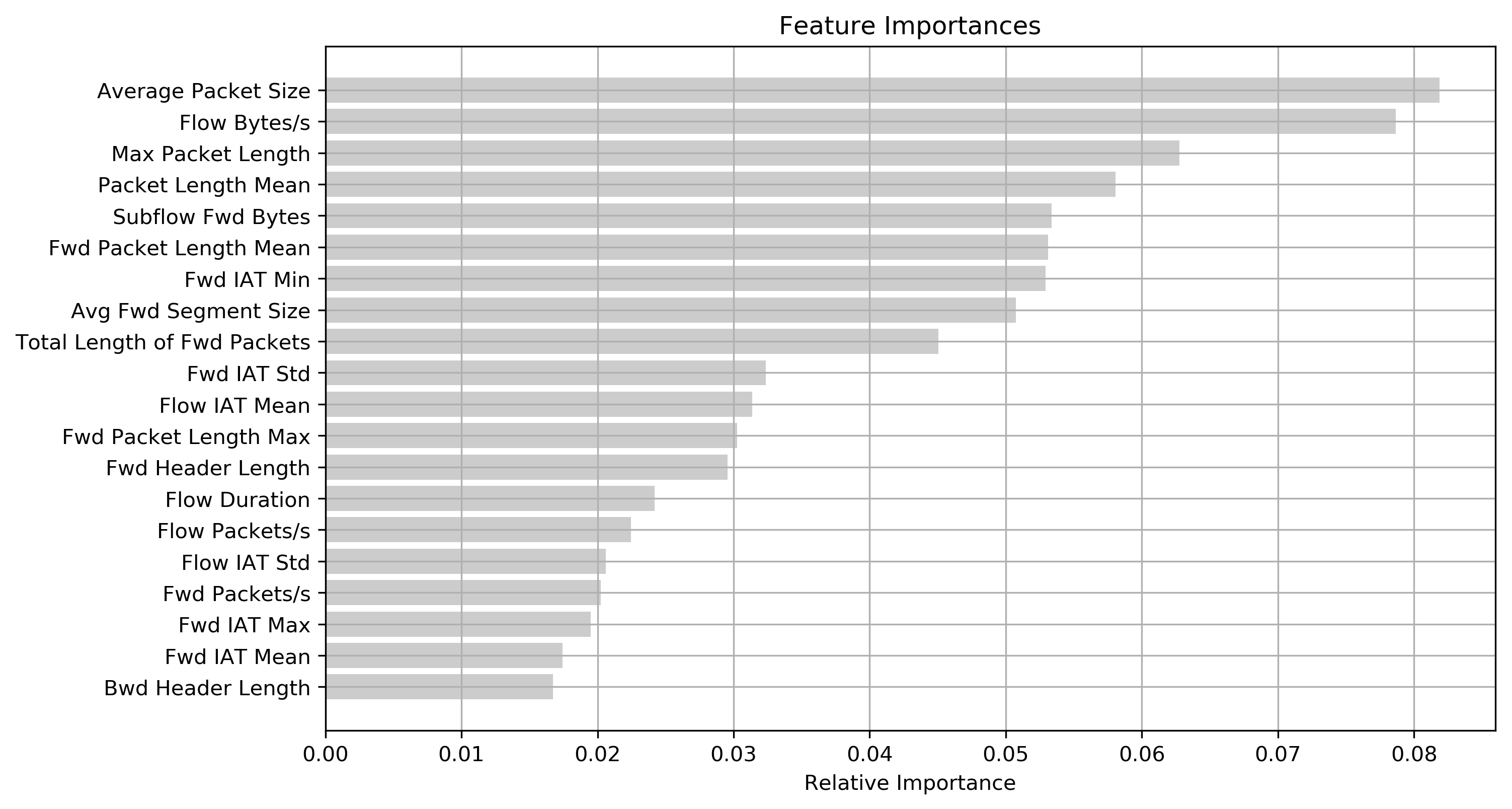 Результаты оценки значимости признаков
Результаты оценки значимости признаковШаг 5. Сокращение признакового пространства
На следующем рисунке представлена корреляционная матрица с линейными коэффициентами корреляции (коэффициентами корреляции Пирсона), рассчитанными для всех пар двадцати наиболее значимых признаков. Насыщенность цвета заливки пропорциональна значению коэффициента корреляции.
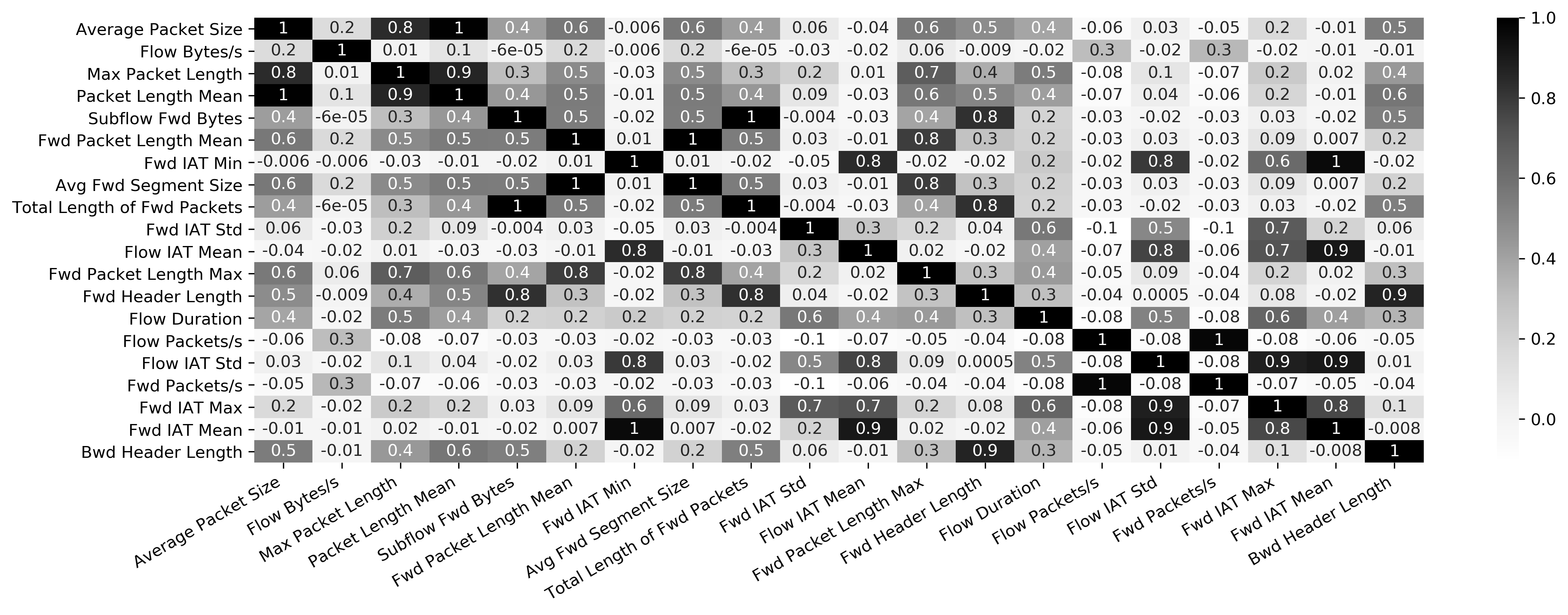 Результаты корреляционного анализа двадцати наиболее значимых признаков
Результаты корреляционного анализа двадцати наиболее значимых признаковКорреляционный анализ показал сильную зависимость между парами признаков:
«Average Packet Size» и «Packet Length Mean».
«Subflow Fwd Bytes» и «Total Length of Fwd Packets».
«Fwd Packet Length Mean» и «Avg Fwd Segment Size».
«Flow Duration» и «Fwd IAT Total».
«Flow Packets/s» и «Fwd Packets/s».
«Flow IAT Max» и «Fwd IAT Max».
По результатам корреляционного анализа из признакового пространства были исключены следующие признаки: «Packet Length Mean», «Subflow Fwd Bytes», «Avg Fwd Segment Size», «Fwd IAT Total», «Fwd Packets/s», «Fwd IAT Max».
После исключения признаков с наименьшей значимостью признаковое пространство было сокращено до объединения 10 признаков:
«Average Packet Size», средняя длина поля данных пакета TCP/IP (далее — длина пакета).
«Flow Bytes/s», скорость потока данных.
«Max Packet Length», максимальная длина пакета.
«Fwd Packet Length Mean», средняя длина переданных в прямом направлении пакетов.
«Fwd IAT Min», минимальное значение межпакетного интервала (IAT, inter-arrival time) в прямом направлении.
«Total Length of Fwd Packets», суммарная длина переданных в прямом направлении пакетов.
«Fwd IAT Std», среднеквадратическое отклонение значения межпакетного интервала в прямом направлении пакетов.
«Flow IAT Mean», среднее значение межпакетного интервала.
«Fwd Packet Length Max», максимальная длина переданного в прямом направлении пакета.
«Fwd Header Length», суммарная длина заголовков переданных в прямом направлении пакетов.
Шаг 6. Выбор модели
На этапе выбора модели я взял 10 наиболее распространенных моделей машинного обучения и оценил их качество на подвыборке WebAttacks.
Список из 10 моделейДля сравнения были выбраны следующие модели (алгоритмы) машинного обучения (в скобках указывается сокращенное обозначение и соответствующая реализация модели из состава пакета scikit-learn):
Метод k ближайших соседей (KNN, sklearn.neighbors.KNeighborsClassifier).
Метод опорных векторов (SVM, sklearn.svm.SVC).
Дерево решений (CART, алгоритм обучения CART, sklearn.tree.DecisionTreeClassifier).
Случайный лес (RF, sklearn.ensemble.RandomForestClassifier).
Модель адаптивного бустинга над решающим деревом (AdaBoost, sklearn.ensemble.AdaBoostClassifier).
Логистическая регрессия (LR, sklearn.linear_model.LogisticRegression).
Байесовский классификатор (NB, sklearn.naive_bayes.GaussianNB).
Линейный дискриминантный анализ (LDA, sklearn.discriminant_analysis.LinearDiscriminantAnalysis).
Квадратичный дискриминантный анализ (QDA, sklearn.discriminant_analysis.QuadraticDiscriminantAnalysis).
Многослойный персептрон (MLP, sklearn.neural_network.MLPClassifier).
Качество ответов классификаторов (моделей) сравнивалось с использованием следующих метрик:
доля правильных ответов (accuracy);
точность (precision, насколько можно доверять классификатору);
полнота (recall, как много объектов класса «есть атака» определяет классификатор);
F1-мера (F1-measure, гармоническое среднее между точностью и полнотой).
Оценка качества классификаторов производилась на сбалансированной и предобработанной подвыборке веб-атак WebAttacks набора данных CICIDS2017 (соотношение нормального и аномального трафика 70% / 30%, 20 наиболее значимых признаков). В таблице ниже приведены полученные значения метрик качества, усредненные по результатам 5 итераций кросс-валидации.
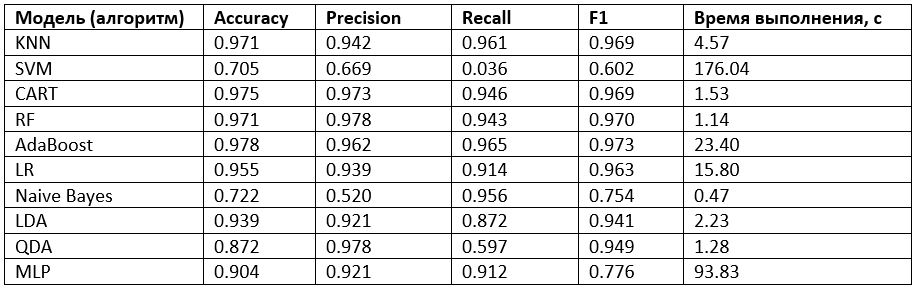 Результаты оценки качества десяти классификаторов
Результаты оценки качества десяти классификаторовНаилучшие результаты ожидаемо продемонстрировали модели (алгоритмы) KNN, CART, RF, AdaBoost, LR. Принимая во внимание минимальное время выполнения, применение модели «случайный лес» (RF) для решения поставленной задачи является обоснованным выбором.
Исходный код в Google Colaboratory
Шаг 7. Настройка и обучение модели
Итак, за основу я взял модель типа «случайный лес», реализация в scikit-learn — RandomForestClassifier.
Среди настраиваемых гиперпараметров модели были выбраны следующие: количество деревьев в лесу (n_estimators), минимальное число объектов в одном листе дерева (min_samples_leaf), максимальная глубина дерева (max_depth), максимальное количество признаков для одного дерева (max_features).
Степень квазиоптимальности параметров модели оценивалась значением F1-меры.
Проведенный экспертный анализ я дополнил результатами встроенного метода оптимизации параметров GridSearchCV библиотеки scikit-learn, итоговые значения параметров модели «случайный лес» получились следующие:
RandomForestClassifier(
bootstrap=True, class_weight=None, criterion='gini',
max_depth=17, max_features=10, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=3, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=50,
n_jobs=None, oob_score=False, random_state=1, verbose=0,
warm_start=False)Пример результатов подбора одного гиперпараметра (max_depth) при фиксированных значениях других гиперпараметров (n_estimators, min_samples_leaf, max_features) представлен на рисунке ниже в виде зависимости метрики качества (F1-меры) от значения настраиваемого параметра (max_depth).
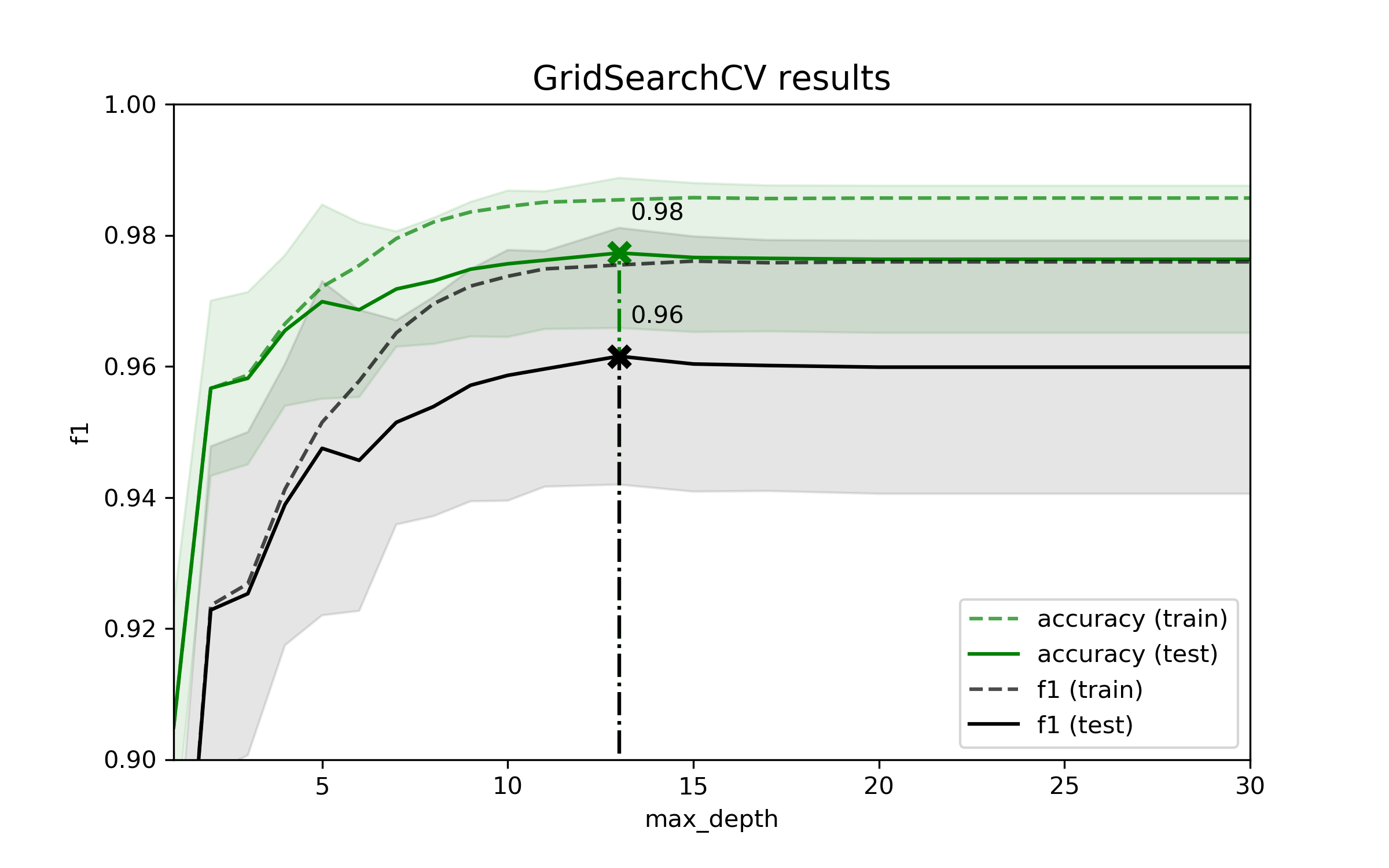 Зависимость F1-меры модели от параметра max_depth
Зависимость F1-меры модели от параметра max_depthШаг 8. Тестирование и апробация
Настроенная и обученная модель RandomForestClassifier на тестовой выборке позволила получить оценку полноты (recall) 0.961 и F1-меры 0.971 (запуск №1 в протоколе эксперимента, см. таблицу ниже). Достигнутый результат свидетельствует о возможности повышения точности модели за счет квазиоптимального подбора гиперпараметров (результаты исследования Kahraman Kostas — recall 0.94 и F1-мера 0.94, результаты авторов CICIDS2017 — recall 0.97 и F1-мера 0.97).
Для апробации модели на реальной сетевой инфраструктуре я разработал свой сетевой анализатор — сниффер (C#). Анализатор позволяет перехватить передаваемый сетевой трафик и с использованием алгоритмов реконструкции TCP сессий свободно распространяемых программных продуктов Wireshark и TCP Session Reconstruction Tool выделить отдельные сессии. Для каждой сохраненной сессии сниффер на основе алгоритма CICFlowMeter выделяет признаки и таким образом формирует набор данных.
В качестве атакуемого веб-приложения использовалась разработанная консоль администратора безопасности (PHP) с единственным включенным модулем авторизации, функционирующая под управлением веб-сервера Apache.
Нормальный трафик соответствовал запросам легальных пользователей на подключение к консоли администратора и авторизацию. Вредоносный (аномальный) трафик моделировался программным средством OWASP ZAP и включал три типа атак: Brute Force, XSS, SQL Injection. Соотношение нормального и аномального трафика в реальном тестовом наборе данных составило 70% / 30%.
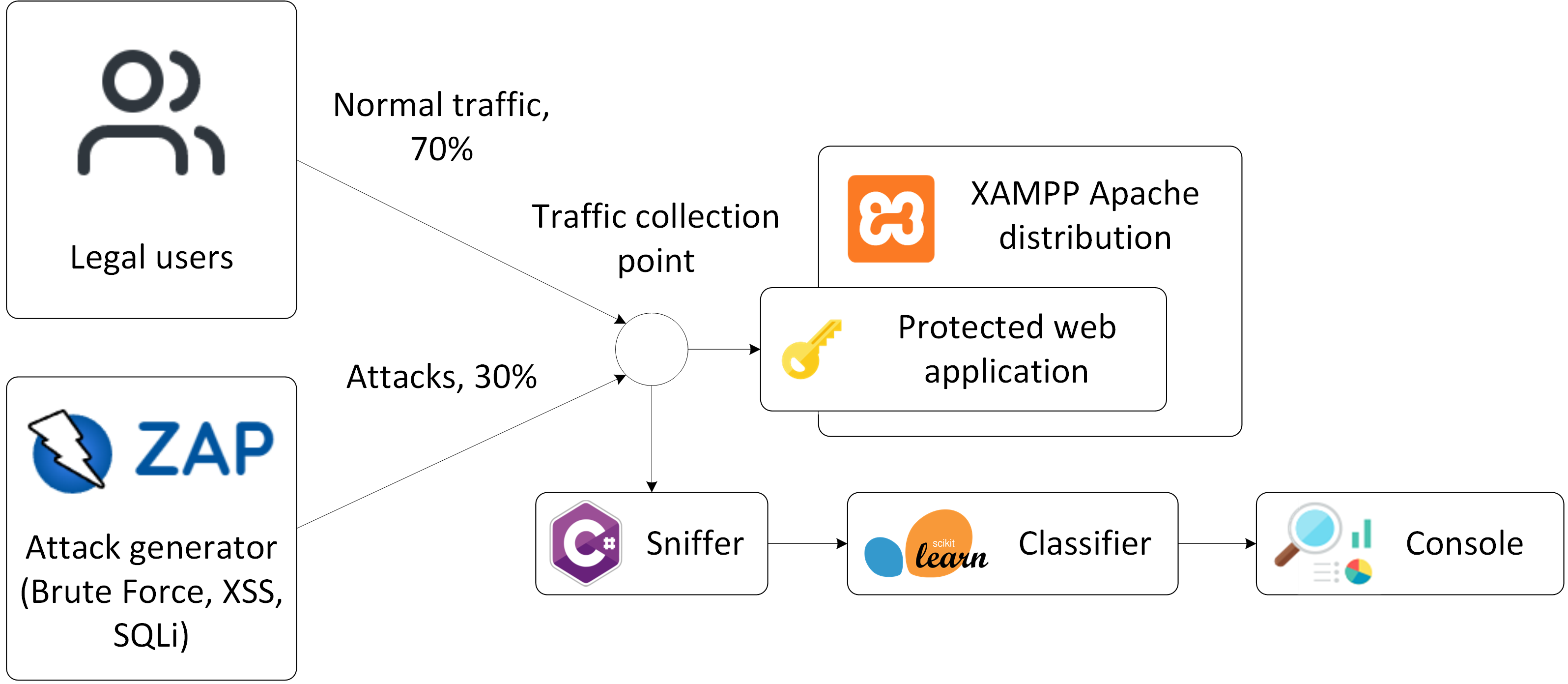 Схема стенда тестированияПодробно про запуск ZAP
Схема стенда тестированияПодробно про запуск ZAPПример защищаемого приложения (заимствован из поста: «Как за один день разработать SIEM»).
Пример URL, соответствующего попытке входа в защищаемое приложение: http://192.168.121.129/buggy/admin.php? password=12345&username=admin
ZAP запускается в режиме фаззинга, при котором будут перебираться различные значения параметра password. Важно: параметр username сразу устанавливается равным «admin». Будем считать, что злоумышленник знает имя администратора наверняка. В противном случае, можно для фаззера указать оба параметра, но и количество попыток возрастёт до N*N для двух параметров вместо N для одного (N — количество строк в словаре).
Нагрузки (payloads, словари) для проведения атак Brute Force, XSS и SQL Injection я взял из репозитория github.com/danielmiessler/SecLists.
Как узнать, подобрал ли фаззер пароль при реализации атаки Brute Force? Я знаю, что в защищаемом веб-приложении страница авторизованного пользователя отличается от приветственной. Поэтому достаточно отсортировать результаты работы фаззера по размеру ответа — столбец «Size Resp. Body». И в строке с размером ответа, отличающимся от всех остальных, обнаружить пароль «admin».
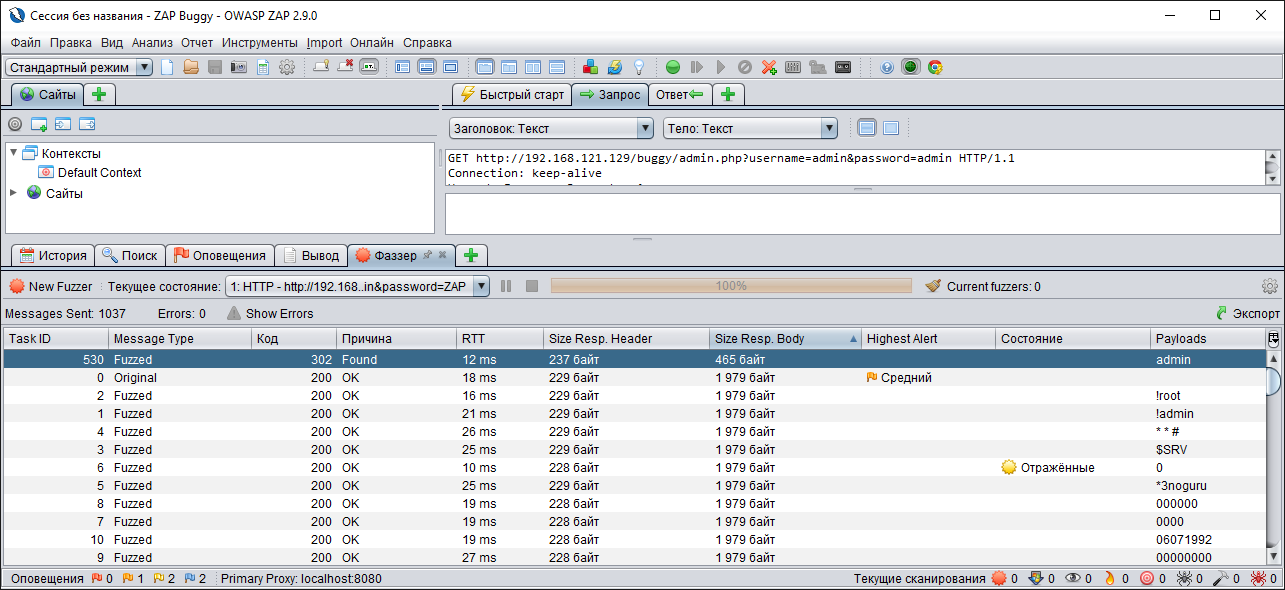 Успешный запуск фаззера
Успешный запуск фаззераПроведенные эксперименты на сформированном наборе данных (запуски №2, №3 в протоколе эксперимента) показали невозможность применения модели, обученной на наборе данных CICIDS2017, по следующим причинам:
Анализ обучающей выборки показывает, что характер моделируемых компьютерных атак в исследовании авторов набора данных CICIDS2017 отличается от реального. Так, атаки типа Brute Force присутствуют в сессиях с максимальными скоростями до 10 Кбит/c, что не соответствует случаям применения автоматизированных средств перебора паролей.
Среди десяти признаков с наибольшей значимостью четыре признака — «Flow Bytes/s» (скорость потока данных), «Fwd IAT Min» (минимальное значение межпакетного интервала в прямом направлении), «Flow IAT Std» (среднеквадратическое отклонение значения межпакетного интервала), «Flow IAT Mean» (среднее значение межпакетного интервала) — непосредственно зависят от физической структуры сети, в которой производится сбор сетевого трафика, а также настроек сетевого оборудования. В обучающем наборе данных сессии с признаками веб-атак записаны с низкими значениями скорости потока и высокими значениями межпакетных интервалов, что не соответствует характеристикам реальной сетевой инфраструктуры (сеть Ethernet 100 Мбит/c).
Хороший датасет должен удовлетворять определенным требованиям. У авторов CICIDS2017 есть работа, в которой перечислено 11 таких требований. Главное из этого: обеспечить разнообразие сетевого оборудования, компьютеров и операционных систем в тестовой инфраструктуре, разнообразие потоков сетевого трафика по разным направлениям, разнообразие протоколов и типов атак, разметить данные для атак и для чистого трафика.
Я сильно упрощаю задачу — уточнить возможность построения эвристического анализатора и грубо оценить его точность. Не претендуя на сбор сверхкачественного датасета, поскольку это задача целых институтов.
План сбора датасета:
1 этап. Запись pcap файлов, очистка. При сборе «грязного» трафика изменяем параметры фаззера и ставим паузы во время фаззинга, чтобы разорвать сессии и увеличить их количество в датасете. При сборе «чистого» трафика моделируем разные действия пользователя.
2 этап. Подача pcap файлов на вход сниффера и выделение признаков. Объединение всех размеченных записей в один датасет.
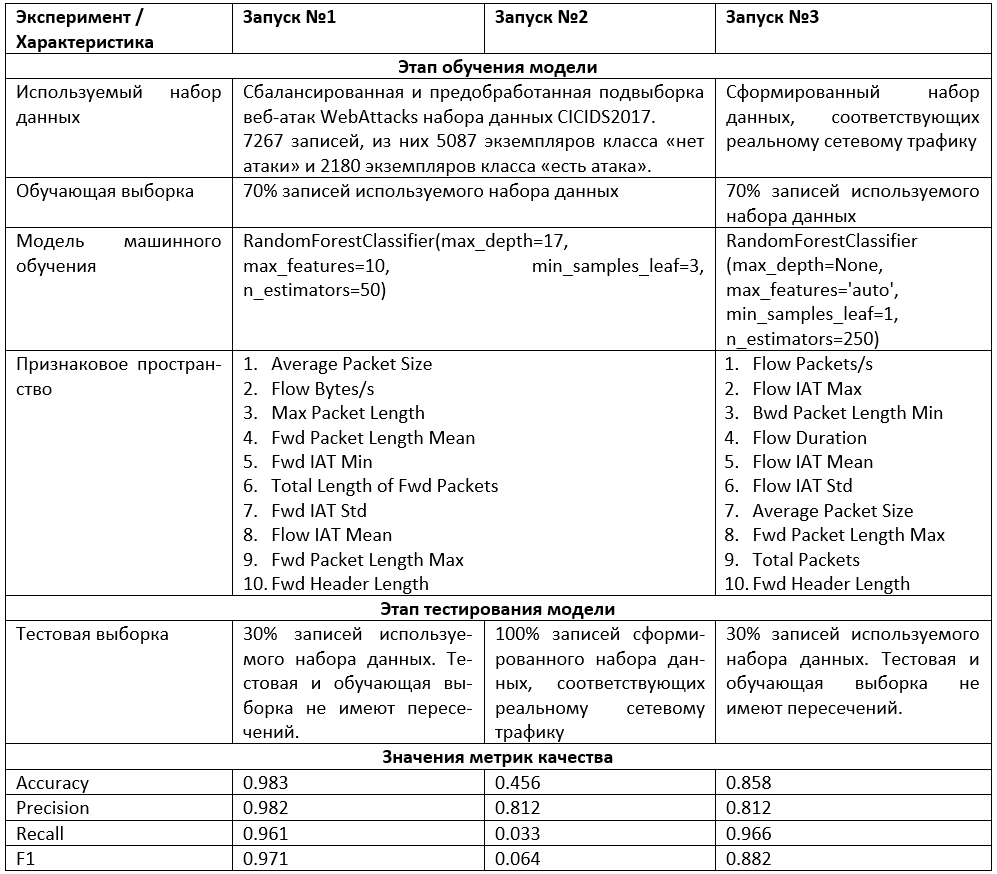 Протокол эксперимента
Протокол экспериментаВажно. Запуск №2. Модель была обучена на подвыборке WebAttacks набора данных CICIDS2017 (трафик собирался в одной сети). После этого я протестировал модель на реальном трафике в другой сети, отличающейся скоростью и другими характеристиками от первой. И получил неудовлетворительное качество — значение F1-меры 0.064.
Оценка вычислительной сложности производилась косвенным способом: разработанный в среде Jupyter Notebook макет системы обнаружения веб-атак запускался на персональном компьютере (процессор Intel Core i5–2300 CPU @ 2300 ГГц, ОЗУ 8 Гб) в режиме обнаружения. Тестовый набор данных содержал около 70000 записанных сессий, время обнаружения составило 0,74669 с. Таким образом, скорость обнаружения веб-атак оценивается величиной порядка 100000 сессий в секунду.
Подведение итогов
Итак, завершен эксперимент с разработкой модели «случайный лес» для решения задачи обнаружения компьютерных атак. Модель обучена на публичном наборе данных CICIDS2017 и протестирована в реальных условиях.
Настройка параметров выбранного классификатора RandomForestClassifier пакета scikit-learn позволила на тестовой выборке получить оценку полноты (recall) 0.961 и F1-меры 0.971 для набора данных CICIDS2017 и 0.966 и 0.882 соответственно для сформированного в исследовании набора данных.
Главный вывод эксперимента: методы машинного обучения на практике применимы для обнаружения компьютерных атак.
Из отрицательных результатов. Даже с учетом погрешности в оценках качества у меня не получилось применить предобученную модель обнаружения атак в реальной компьютерной сети. Основные причины:
Характер моделируемых компьютерных атак при сборе обучающего набора данных отличался от реального.
Часть значимых признаков непосредственно зависят от физической структуры сети, в которой производился сбор сетевого трафика, а также настроек сетевого оборудования.
Что исправить, чтобы получилось? Идеально — обучать модель на наборе данных, размеченном на основе анализа сетевого трафика в защищаемой сети. При использовании предобученной в другой сети модели (проблема transfer learning) обязательным является соответствие физической структуры защищаемой сети и сети, в которой обучалась модель, а также настроек сетевого оборудования.
Личные выводы. В начале освоения пути исследователя данных применение машинного обучения представлялось в виде 10 строчек кода из примера на scikit-learn.org. Сегодня, глядя на >500 строк кода в итоговом блокноте, я понимаю, сколько еще улучшений можно сделать и как развить решение.
Этот эксперимент занял больше двух лет, без спешки, в перерывах между чтением книг, статей, прохождением курсов, участием в соревнованиях по ML и выступлениями на конференциях. Я был нубом на старте, но смог разобраться и пройти этот увлекательный трек. Впереди — новые знания и эксперименты. Но уже сегодня я уверен: современный инженер должен знать, как работает машинное обучение. Чтобы быть ближе к будущему!
Полезные ссылки
Исходный код эксперимента (блокноты, сниффер, разное).
Книги, которые помогли в исследовании:
Talabis M. Information Security Analytics.
Sumeet D. Data Mining and Machine Learning in Cybersecurity.
Lee K.-F. AI Superpowers: China, Silicon Valley, and the New World Order.
McAfee A. Machine, Platform, Crowd. Harnessing Our Digital Future.
Chio С. Machine Learning and Security: Protecting Systems with Data and Algorithms.
История прохождения курсов обучения, все — бесплатные:
Цвет титульной фотографии восстановлен здесь
