Как разработать микросхему, от идеи до результата. Часть 1. Теория
Пока наши соседи по цеху спорят о конкурентоспособности Эльбруса, мы не будем пустозвонить и начнём мало-помалу клепать Отечественный Процессор ™. Google выдал Skywater несколько миллионов для того, чтобы Skywater произвёл ваши микросхемы за бесплатно, а вы не знаете, как эту самую микросхему разработать? Этот материал точно для вас!

В этой серии статьей мы раскроем всё: от получения документации до layout-а. Но перед этим давайте разберёмся, как вообще разрабатывают микросхемы.
50 микросхем, бесплатно для всех проектов с открытым исходным кодом
Статья выходит очень вовремя, ведь в Декабре будет MPW-4 от SkyWater! У SkyWater было уже три производства микросхем по технологии Sky130, и очень даже успешных! Для желающих БЕСПЛАТНО есть возможность произвести вашу микросхему в количестве 50 штук. Для этого надо перейти на страницу MPW-4 от Efabless и зарегистрироваться, к сожалению, анонса на сайте пока нету, а регистрация на MPW-3 закончилась 15 ноября. Есть ещё несколько требований, например, ваша микросхема, должна быть с открытым исходным кодом, подробнее можно узнать, заглянув в анонс.
Вообще, мне удалось познакомиться с разработчиками и они очень классные люди! Спасибо комьюнити, и спасибо компаниям и странам, которые профинансировали просто отличный софт, с которым нам предстоит познакомиться в этой статье.
Но ведь Sky130 не новая, так почему же сейчас вдруг выходит эта статья? Дело в том, что Sky130 имеет полностью открытую PDK, и это первая в мире технология, документация которой доступна для всех. Также примечательно то, что данная технология заставила Open Source комьюнити попотеть, ибо вместе с выходом технологии стали доступны KLayout и Magic VLSI, а команде Efabless удалось на основе OpenRoad сделать OpenLane для синтеза цифровых микросхем. Наряду с уже существующими NGSPICE и XSCHEM это позволяет разрабатывать полностью открытые микросхемы от идеи до готового продукта просто огромные проекты, возможности реально неограниченны (если вы уместите всё в 10 квадратных миллиметров).
Микросхема изнутри
Все микросхемы состоят из подложки и корпуса. На корпусе находятся ножки, которые подключены к контактным площадкам подложки, используя специальные провода.
Иногда микросхемы делают по технологии Flip-Chip, которая не использует провода, вместо этого используются металлические контакты, которые напрямую подключены к верхним слоям металла внутри микросхемы.
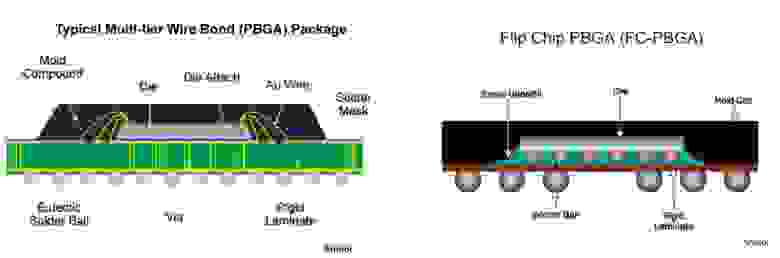
Источник
У sky130 есть возможность использовать корпус WCLSP 6×10:
Если вам захочется использовать другой корпус, для вас доступен ChipIgnite, всего за $9,999 вы можете получить 100 микросхем в корпусе QFN, либо 300 штук в корпусе WCSP. А за 1000 штук вы заплатите всего каких-то жалких двадцать киллобаксов.
Несмотря на корпус, который прямо-таки просится быть Flip-Chip, всё-таки нам доступен только WireBond. Вот оболочка, в которую нам предстоит интегрировать нашу схему։
▍ Подложки
Кроме корпуса, внутри микросхемы есть «сердце» микросхемы, подложка из кремния, в котором заточены наши транзисторы, слои металла и изоляции. Именно кремний определяет функциональность нашей микросхемы, и в мире существуют несколько компаний, производящих этот самый «кремний».
Для того чтобы эта компания могла произвести вашу микросхему, эту самую микросхему нужно сначала разработать, а затем только передать её в производство. Для этого используется стандарт файлов GDS-II, либо другие стандарты. GDS-II является многослойной векторной картинкой, которая соответствует требованиям этой самой компании. Но как нам узнать, какие файлы соответствуют этим требованиям или нет? Здесь на помощь приходит так называемый Process Design Kit или PDK.
Пример микросхемы по технологии sky130: ускоритель расчёта SHA3․
Process Design Kit
Process Design Kit содержит следующие компоненты:
- Технологическая документация. Этот файл содержит на удобно перевариваемом формате описание и требования к конечному файлу, кроме того, эта документация содержит примеры и описания транзисторов. Для sky130 документацию можно найти тут
- Модели для симуляции элементов схемы в формате SPICE. Эти модели используются для симуляции компонентов интегральной схемы. Перед тем как нарисовать структуру кремния, вам нужно сначала определиться со схемой, которую вы будете рисовать. Эти модели можно найти на гитхабе гугла.
- Технологические файлы, которые позволяют связать файл GDS-II и слои при производстве. Для Magic/Klayout эти файлы можно найти на гитхабе Open_PDKs
- Библиотека примитивов — Транзисторов, резисторов, конденсаторов и так далее для схематического представления, которые можно найти на гитхабе
- Правила Design Rule Check. Эти файлы привязаны к конкретному программному обеспеченью и содержат список правил, на которые в автоматическом режиме будут проверяться ваши интегральные схемы или её отдельные компоненты.
- Parasitic Extraction rules или правила описывающие паразитические свойства. Эти правила позволяют просчитать паразитные конденсаторы, индукторы и резисторы. После PEX
сгенерированный netlist содержит паразитные конденсаторы и резисторы, а сам netlist используется чтобы произвести симуляцию компонентов как можно более приближённой к реальной интегральной схеме. - Layout versus Schematic check или правила, которые позволяют получить из вашего GDS-II так называемый netlist. После чего его можно сравнить со схемой, которую вы нарисовали и уже просимулировали. DRC/PEX/LVS правила для Magic можно найти на гитхабе Open_PDKs
Skywater 130nm
Для этого давайте сначала разберём, что нам предоставил Skywater/Google для разработки микросхемы по технологии SKY130. Гуглим SKY130 и кроме кучки новостей, находим новость от efabless и офицальную документацию SKY130. Практически вся документации находится в виде ту-ду:
Тем не менее гуглим sky130 туториал и находим кучу всего, и все они неполные. К счастью, ваш покорный слуга не первый год в разработке интегральных схем, и поэтому я просто нашёл, как можно больше информации и решил всё расписать по частям в этой статье. Огромное количество информации найти нельзя, поскольку было получено лично от разработчиков в Slack канале sky130. Но перед тем как продолжить — немного теории.
Custom Design Flow
Custom Design Flow используется для того, чтобы разрабатывать аналоговые либо смешанные схемы. Custom Design Flow обладает наибольшей гибкостью, ибо позволяет разработать абсолютно любую схему, но её недостатком является долгий цикл разработки.
Custom Design Flow состоит из нескольких фаз, но при этом некоторые фазы повторяются, если результат не удовлетворяет требованиям. Вот эти фазы։
▍ Спецификация
Давайте разберём каждый шаг. Specification, который между разработчиками называется «спека», содержит в себе все необходимые требования к итоговой схеме. Иногда микросхема настолько большая, что её разделяют на более мелкие куски и распределяют по командам. Для того чтобы каждая команда знала, какую часть микросхемы нужно собрать, для этой команды составляется спецификация.
В спецификации часто содержится։ Рабочие напряжения, технология (например, sky130), требования к площади компонента, ограничения по слоям, функциональность и характеристики схемы. В этом материале мы будем разрабатывать простой NAND, но очевидно, что ячейки стандартной библиотеки содержат гораздо большее количество ячеек, чем простая NAND. Про это расскажу далее.
Пример спецификации к компоненту ввода вывода։
▍ Схемотехническое представление
Схемотехническое представление (schematic) это представление вашей микросхемы используя компоненты вашей технологии։ транзисторы, резисторы, конденсаторы, а также пины и их подключения. Схема составляется для двух целей։ проверить её работоспособность в идеальных условиях, когда сопротивление подключения и паразитные конденсаторы отсутствуют и понять, насколько мы близки к требованиям спецификации. Очевидно, что нам нужно оставить запас для паразитных ёмкостей и сопротивлений.
Пример схемотехнического представления։
▍ Testbench
Testbench это схема, в которой вашим компонентам предстоит работать. У вас может быть бесконечное количество testbench, и подкомпонентов, и testbench-ов для этих подкомпонентов. Testbench используется для того, чтобы измерить необходимые характеристики. Про это будет далее.
Пример testbench для NAND:
▍ Симуляция схематического представления.
Для того чтобы просимулировать схематическое представление и testbench конвертируется в netlist в формате SPICE. Для создания схематического представления я использовал XSCHEM и сгенерировал Netlist в формате SPICE на основе testbench, которое в свою очередь содержит определение нашей схемы.
Затем я скормил Netlist симулятору NGSPICE, который посчитал все параметры, которые, мы выставим. Также, NGSPICE сгенерировал результат симуляции, который содержит значения напряжения и тока в зависимости от времени. Затем мы просим NGSPICE нарисовать нам графики зависимости напряжения на выходе и входе в зависимости от времени. А еще мы можем попросить NGSPICE провести любые измерения:
▍ Разработка Layout
Layout это такое представление, в котором, содержатся полигоны, которые будут нанесены на маску. Затем эта маска будет использоваться для того, чтобы создать диффузии, слои металла, и всё остальное! Magic VLSI и Klayout могут использоваться для создания GDS-II файлов, которые содержат полигоны и прочие примитивные объекты по типу текста. Мы будем использовать Klayout, поскольку у него значительно проще интерфейс.
Пример, на картинке видны отдельные слои։ диффузий металла и межслойных соединений, а также всё в сборе:
▍ Design Rule Check (DRC)
Design Rule Check используется для того, чтобы проверить маски на возможность произвести физическую микросхему. Представьте, что вы сделали металл очень тонким и если попробовать произвести по вашей микросхеме, то полученный металл будет слишком тонким, и во время производства он просто исчезнет. Это если маску вообще удастся сделать.
Для sky130 используется программа Magic VLSI, и правила, написанные именно под эту программу. Если вам захочется использовать что-то другое, то вам придётся написать эти правила уже под вашу программу.
После того как вы установите Open_PDKs по пути $PDK_ROOT/sky130A/libs.tech/magic/sky130A.tech, вы найдёте правила DRC для Magic. Используя именно эти правила Magic VLSI будет проверять ваш Layout.
На картинке видно, слева направо: Layout, правила Magic VLSI для sky130, результат проверки DRC.
Кликабельно
▍ Layout Versus Schematic (LVS)
Layout Versus Schematic используется для того, чтобы удостовериться, что разработанный Layout соответствует схематическому представлению. Это проверка сначала использует Layout и правила Device Extraction для того, чтобы получить схематическое представление, которое получится в результате производства данной микросхемы или компонента.
Мы будем использовать Magic VLSI для того, чтобы сгенерировать Netlist из Layout-а, затем сгенерированный Netlist сравнивается с Netlist-ом соответствующего компонента. Сначала сравниваются компоненты и их параметры: Транзисторы, резисторы, конденсаторы, затем сравниваются все подключения между ними и пинами компонента. Про это будет далее.
Если вы попробуете сравнить сгенерированный Netlist и Netlist-ом соответствующий компонент, скорее всего у вас будет ошибка, дело в том, что netgen не знает, что у транзисторов симметричный drain и source. Также, netgen не будет знать, о том, что транзисторы, подключённые так, чтобы все ножки были подключены друг к другу, можно объединить, суммировав параметр W.
Аналогично с последовательным подключением drain, source, если gate и bulk подключены аналогичной ножке других транзисторов, то эти транзисторы можно объединить, суммировав параметр L. Не нашёл информации об этом, чтобы правильно всё расписать, тем не менее решил упомянуть.
▍ Parasitics EXtraction (PEX)
Parasitics EXtraction похож на Device Extraction, но кроме компонентов и их подключений так же извлекаются паразитные конденсаторы и резисторы. Таким образом, получается модель для симуляции, максимально приближённая к готовой микросхеме. Для этого мы будем использовать Magic VLSI. Очевидно, чтобы Magic VLSI знал, характеристики металлов и других проводников, нужен технологический файл.
Слева направо, layout, правила паразитных ёмкостей и сопротивлений, и зеленным отмечены компоненты нашей схемы, красным паразитные ёмкости, синим паразитные сопротивления.
Digital Design Flow
В современном мире микросхем, вручную разработать и проверить микросхему практически невозможно из-за количества её компонентов. В этом плане нам помогает «поток разработки цифровых компонентов».
«Поток разработки цифровых компонентов» позволяет разрабатывать цифровые части микросхем, используя высокоуровневый язык, называемый Register Transfer Level, который позволяет разрабатывать по-настоящему огромные микросхемы. Всё — начиная от процессоров, ускорителей, ПЛИС и видеопроцессоров разрабатываются с использованием Register Transfer Level и Digital Design Flow, хотя они содержат очень много аналоговых или смешанных компонентов, цифровые компоненты занимают значительно бОльшую площадь, чем аналоговые.
Следующие шаги используются для разработки цифровых микросхем:
▍ Register Transfer Level (RTL)
Для того чтобы разработать цифровую микросхему используется RTL Verilog, который описывает регистры и изменения в этих самых регистрах. Используя регистры для хранения, ваш конечный продукт может запоминать информацию, например, сетевые пакеты, значение внутри вашего процессора или даже промежуточные результаты расчётов. Если хотите подробнее узнать про RTL Verilog, рекомендую прочитать книгу Харриса и Харриса, либо её перевод на русский, либо её полную версию на русском.
Пример, найти полную версию можно тут:
▍ Design Contraints
Поскольку RTL не предусматривает механизма описания информации:
То для этих целей используется Design Constraints, который обычно сделан в формате Synopsys Design Constraints (.sdc).
Простой пример, в котором объявлен только сигнал тактования и частота.
▍ Синтез
Синтез берёт на вход Design Constraints, RTL код и превращает его в представление из элементов стандартной библиотеки. Для этого стандартная библиотека, должна быть предварительно разработана. Библиотека стандартных ячеек (Standard Cell Library) содержит в себе один ключевой файл: .lib. Этот файл содержит информацию о задержке каждой ячейки, а также другие важные временные параметры, информацию о размере ячейки и потребление ячейки в разных состояниях. Инструмент синтеза выбирает ячейки и генерирует gate level netlist:
Также именно в этом шаге единицы и ноли, подключённые к входам компонентам, заменяются на Tie-Hi и Tie-Lo компоненты, поскольку прямое подключение входов ячеек к соединениям питания запрещено.
Для синтеза используется Yosys, который я использовал много раз, и он мне он очень понравился. Конечно, были небольшие проблемы, но никаких багов, ломающих мои схемы.
▍ Design For Testability
После производства микросхемы, очень часто требуется проверить микросхему на работоспособность. Для этого в микросхеме все триггеры заменяются на специальные называемые «сканируемые триггеры», которые позволяют выбирать вместо логики, подключенной к входу триггера, выход предыдущего триггера.
Это позволяет выбирать режим «сканирования», в котором последовательно на все триггеры перемещаются входные данные, затем режим сканирования выключается, и на тактовый сигнал подаётся один такт, затем результаты снова перемещаются, используя цепочку триггеров на выход, и выход сравнивается с эталонным. Если одна из ячеек повреждена, то выходные данные не будут совпадать с эталонными значениями. Входные данные называются Test pattern.
На самом деле я очень упростил всё, и даже не рассказал про Observability, Testability, Stuck-At, At-speed-testing и огромную кучу всего, но нас это не касается, поскольку для sky130 нет готовых инструментов создания паттернов и замены ячеек на сканируемые. У Synopsys есть ПО, которое называется TetraMAX для создания DFT и их паттернов.
UPD: Есть Cloud-V/Fault.
Источник примера.
▍ Floorplan
Floorplan, один из достаточно ручных шагов. На этом этапе, бородатые дяденьки, сидят и анализируют RTL код и Design Constraints для того, чтобы определить идеальное расположение макрокомпонентов. Макрокомпоненты это Mixed/Analog или даже цифровые блоки, которые будут использоваться в вашем конечном компоненте/интегральной схеме.
В маленьких компонентах задержки между компонентами практически не влияют на частоту схему, но в больших компонентах и микросхемах, длительность одного такта становится сравнительной к длительности перемещения сигнала, между компонентами, либо даже имеет длину в несколько тактов. Из-за этого выбор местоположения компонентов может иметь критическое значение на производительность, задержки или даже на энергопотребление.
К сожалению OpenLane, хотя и имеет механизм установки компонентов в конкретных координатах, не обладает теми же инструментами, что Fusion Compiler, ICC II, Innovus и прочие, которые позволяют анализировать связи между макрокомпонентами. OpenLane, может сам выбирать местоположение компонентов, тем не менее этот выбор редко самый оптимальный.
После определения местоположения, также генерируется несколько групп ячейки.
▍ TAP ячейки
Далее в статье мы увидим ошибку о том, что наша стандартная ячейка, не имеет подключения PWELL/NWELL. Эти подключения называются Bulk-ом транзистора. В старых технологиях, подключения BULK были в каждой ячейке, но в новых технологиях длина затвора транзистора была настолько маленькой, что подключения к Bulk, используя контакты начали мешать, поскольку занимали значительную часть в слое контакта, ограничивая уменьшения высоты стандартной ячейки.
Для решения этой проблемы с определённой периодичностью, обычно каждые 30 микрометров, по всей площади вставляются TAP ячейки, который содержат подключения PWELL/NWELL. Каждой TAP ячейки в sky130, хватает, только на 15 микрометров.
Boundary ячейки используются для того, чтобы разделить макрокомпоненты и места размещения ячейки из стандартной библиотеки. В sky130, судя по всему необходимость в них отсутствует, но в более развитых технологиях, эти ячейки нужны для того, чтобы защитить полисиликоны стандартной ячейки. Если бы Boundary ячейки отсутствовали в этих технологиях во время производства полисиликона по сторонам активного транзистора, то полисиликон транзистора будет разъеден кислотой сильнее, чем соседних транзисторов, вызывая очень неприятные последствия.
Иногда после производства микросхемы, бывает необходимость внести изменения в микросхему. Если такая необходимость возникнет, добавление транзисторов является проблемой, поскольку для того, чтобы добавить транзисторы, нужно внести изменения в значительное количество слоёв, например: Полисиликон, N-имплант, P-имплант, Диффузии и другие.
Для решения этой проблемы предварительно расположены по площади всей микросхемы Spare ячейки. Это группы транзисторов, не подключённых ни к чему полезному, но контакты транзистора могут быть подключены для формирования разных ячеек, внося изменения только в металлические слои. В OpenLane эти ячейки не реализованы.
▍ Decap ячейкиDecap используются для того, чтобы загладить влияние высокочастотных компонентов на напряжение питания. Поскольку цифровые микросхемы имеют значительные частоты, и переходы между состояниями вызывают падения напряжения из-за сопротивления линий и огромных токов во время этих переходов.
Во время перехода из одного состояния в другую, цифровые компоненты потребляют наибольший ток и имеют крайне высокие частоты, поэтому влияние цифровых компонентов на напряжение аналоговых компонентов, что для аналоговых компонентов используются отдельные линии подачи питания VDDA/VSSA.
Влияние на друг друга, насколько высоко, что возникает необходимость в Decap ячейках, которые являются ничем иным, чем конденсаторами, который заглаживают изменения в напряжении. Decap конденсаторы заряжаются между переходами, и когда переход начинается, этот конденсатор заглаживает изменения напряжения.
Filler ячейки используются для того, чтобы закрыть ячейки для стандартной ячейки, который остались пустыми. Эта необходимость есть, поскольку многие слои не могут содержать прерываний (дырок), поскольку эти прерывания должны иметь размер в минимум 3 ячейки. Если какая-то стандартная ячейка осталась без соседа, то если расстояния между двумя стандартными ячейками получилась, например, в 2 ячейки, то у вас будет ошибка DRC.
Также Filler ячейки необходимы, поскольку пустые места для стандартной ячейки могут не содержать подключения металлов для линий VDD/VSS. В sky130 необходимость отсутствует, но в более продвинутых технологиях, без Filler ячейки не обойтись.
▍ Placement
В этом шаге мы имеем все ячейки, которые должны быть расположены по площади нашего макрокомпонента либо микросхемы, и их потенциальные расположения. Используя эту информацию инструмент Placement-а рассчитывает оптимальное расположение ячейки, и пытается сохранить плотность компонентов не выше, чем параметр Target Utilization. Не буду вдаваться в подробности, вкратце алгоритмы минимизируют задержку от входов макро ячейки, или выходных других ячеек до конкретной ячейки.
К сожалению, я не нашёл способа хорошо продемонстрировать это кроме как на примере этой картинки:
▍ Clock Tree Synthesis
В прошлом шаге мы предполагали, что сигналы тактования синхронных компонентов вроде триггеров, поступают единовременно. В реальности это невозможно, поэтому тактовые сигналы подключаются специальным методом, который вводит дополнительные задержки, чтобы гарантировать, что синхросигнал пребудет к триггеру почти единовременно. Я не буду дальше раскрывать эту тему, хотя она очень интересная и важная.
Рекомендую посмотреть данный плейлист на ютубе, именно на английском, если хотите подробнее узнать о Clock Tree Synthesis.
▍ Routing
После того как мы установили наши стандартные ячейки и подключили синхросигналы, переходим к ещё одному важному этапу, подключениям. На этом шаге инструмент Routing-а подключает все входы и выходы компонентов и ячейки, добавляя буферы и инверторы, для того чтобы компенсировать потери и паразитные ёмкости.
▍ Signoff
На этом шаге результаты приводятся результаты проверки DRC, LVS, которые полностью соответствуют тем же шагам из Custom Design Flow, но дополнительно добавляется шаг Static Timing Analysis, который проверяет время прибытия данных и синхросигналов для того, чтобы удостовериться, что не нарушаются требования триггера, по времени прибытия данных (Setup Timing) и по времени, когда входные данные меняются (Hold Timing). Для этого в OpenLane используется OpenSTA. Хотя это и важные вещи, которые стоит обсудить, я не буду об этом говорить в текущей статье. Для интересующихся, есть упомянутые видосики, либо огромное количество материала везде, начиная от учебников до статей.
Формальное сравнение используется для того, чтобы сравнить исходный RTL код и выходной netlist, который содержит все компоненты в том числе буферы. Несмотря на это, очень редко выходит ошибка сравнения, ибо один из шагов вносил ошибочные изменения из-за бага в инструменте, или из-за ошибки в файлах библиотеки.
▍ Библиотека Стандартной ячейки
Для того чтобы создать какую-либо схему нам нужны компоненты для этой схемы. Эти компоненты содержатся в Библиотеке Стандартной ячейки. Кроме layout файлов, также содержится lef файлы, .lib файлы и SPICE netlist файлы.
Lef файлы содержат лишь слои необходимые для подключения к ячейке или компоненту, этот файл крайне полезен, ибо позволяет не нагружать PnR инструменты лишними слоями, и это может быть крайне важно в случаях, когда количество компонентов превышает миллионы.
Пример LEF файла нашей NAND ячейки:
.lib используется для того, чтобы без симуляции дать необходимую информацию о выходных характеристиках сигнала в зависимости от нагрузочного конденсатора, информацию о характеристиках сигнала входных сигналов, входных конденсаторах, задержках и так далее.
SPICE netlist очень редко используется для симуляций Mixed-Signal компонентов, и изредка для более точной симуляции информации о задержках.
В этой части мы разберём разработку элементарной ячейки на примере элемента NAND.
Требование заказчика к нашей NAND
Требование заказчика, это такой кусок информации, который содержит список требований к характеристикам и функционалу нашего компонента. Вот, давайте разберём на примере:
▍ Нагрузочный конденсатор
Особенность CMOS логики в том, что входы имеют ёмкость, поэтому для того чтобы провести симуляцию нашей модели, нам нужно подключить конденсаторную ёмкость на выходе нашего компонента. Для этого мы взяли 20 фемтоФарад, поскольку именно такая указана ёмкость, которую наш компонент должен поддерживать.
Обычно в библиотеке у нас есть много вариантов одной логической ячейки. Например, у нас могут быть инверторы, которые могут нести 20 фемтоФарад, 40 фемтоФарад и так до, например, 320 фемтоФарад.
Чтобы не указывать конкретное значение, поскольку само значение ничего не значит, без информации о входной ёмкости каждой ячейки, был придуман параметр «размер» ячейки. Все стандартные ячейки используют стандарт де-факто, в котором размером 1 берут ёмкость четырёх инверторов размера 1.
А размер 1 инвертора берётся так, чтобы идеально иметь два транзистора PMOS/NMOS с конкретным размером диффузий. Если вы попробуйте увеличить размер транзистора, то у вас ничего не получится, поскольку ваша стандартная библиотека имеет заранее продуманные размеры NWELL/PWELL и диффузий, в которые просто физически невозможно поместить больше транзисторов.
Вот, например, инвертор 1 и инвертор 4 рядом, как видим, точки соприкосновения идеально совпадают:
▍ Corner cases, напряжение и температура
После производства чипа, транзисторы могут получиться как слабыми, так и более сильными чем типичный случай. Для того, чтобы произвести симуляцию PDK имеет три варианта моделей։ FF, TT и SS, они расшифровываются вот так։ Fast-Fast, Typical-Typical и Slow-Slow. Первый знак определяет характеристики NMOS, а второй PMOS. Бывают и другие вариации.
Также на характеристики транзистора влияет важный параметр температуры. Выше температура — больше сопротивление, транзисторы медленнее и имеют меньший ток в открытом состоянии.
Я не нашёл информацию о поддерживаемых значениях температуры, поэтому возьмём её от балды -40 до +125. Из документации мы узнаём, что модели некоторых ячеек работают между -50 до +150 градусов, но про остальные ячейки информации ноль. Предположим, что все ячейки будут адекватно работать под наши значения от балды.
В свою очередь, напряжение питания, так же влияет на время перехода выхода из одного состояния в другое. Выше напряжение — переход происходит быстрее, ниже напряжение — медленнее. Для этого проекта, мы возьмём центральное значение 1.8В, поскольку используем транзисторы, типичное рабочее напряжение которого 1.8В. Из документации мы увидим, что модели транзисторов, которые мы будем использовать, поддерживают напряжение до 1.95В. Давайте возьмём границу сверху 1.95В (1.8 + 0.15) и соответственно границу снизу 1.65В (1.8–0.15).
Зачем нам это знать? Чтобы измерить максимальную частоту, время Rise/Fall time и задержку нам нужно использовать самый медленный вариант нашей схемы։ SS, минимальное напряжение и высокую температуру. А чтобы измерить потребляемую мощность нужно использовать низкую температуру, высокое напряжение и вариант FF, поскольку быстрые транзисторы потребляют бОльшую мощность. В этой части мы не будем измерять потребляемую мощность.
▍ Rise time и Fall time
Чтобы понять эти два параметра давайте возьмём обычный инвертор и нарисуем графики его выхода. Мы увидим, что изменение из нуля в единицу и обратно происходит не сразу. Дело в том, что на выходе CMOS логики обычно подключена другая CMOS логика, которая имеет ёмкость, которую нужно зарядить, либо разрядить.
Чтобы подсказать инструменту, насколько быстро происходит переход из одного состояния в другое, используются эти два параметра. Rise time измеряется с момента пересечения выходного сигнала 10% от напряжения питания до момента пересечения 90%. Аналогично Fall Time измеряет обратный процесс.
Зелёным отмечен Fall Time и синим Rise time:
▍ Задержка
Кроме времени перехода, также у ячейки, есть очень важная характеристика: Задержка. Задержка описывает время, необходимое, чтобы изменение на входе вызвали изменения на выходе. Для её измерения мы берём момент, когда вход пересекает 50% от напряжения источника и момент, когда выход преодолевает те же 50%. 50% взято неспроста, это нужно для того, чтобы минимизировать влияние Rise/Fall Time. Для максимальной точности измеряются задержки всех комбинаций переходов.
Не буду вдаваться в подробности, если вас интересует: standard cell delay.
Также стоит отметить, что ячейки имеющие состояния, например, триггеры имеют другие временные параметры: Setup Time, Hold Time, Removal Time, Revoery Timer и другие. Я решил их не освещать в этой статье, хотя это очень часто и остается нераскрытой темой.
▍ Площадь компонента
Это важный параметр, поскольку иногда размер подложки имеет критическое значение. Чтобы измерить этот параметр просто берём рулетку, меряем высоту, меряем длину, умножаем.
Например, 2.72 мкм на 1.77 мкм = 4.8144 мкм^2.
▍ Как измерять мощность
У наших компонентов два важных параметра мощности. Активная и мощность утечки (Leakage Power). Но важно учесть, что наши компоненты потребляют наибольшую мощность в FF corner, с максимальным напряжением: 1.95В и при минимальной температуре.
Если наша потребляемая мощность соответствует спецификации при данных условиях, то в других состояниях, потребляемая мощность очевидно будет меньше, а значит тем более будет удовлетворять нашим требованиям.
Мощность утечки, эта та мощность, которую наш компонент потребляет в режиме простоя. Для его подсчёта, мы берём наш компонент и измеряем его мощность, с подачей на вход константных значений.
Вот, например график тока. Умножив его на наше напряжение, которое мы взяли 1.95В мы получаем мощность утечки:
Для измерения активной мощности компонента, на вход подают тестовый паттерн, который постоянно повторяется. Затем считают среднее значение мощности по длине всего паттерна.
Очевидно, что вручную никто эти параметры не считает, для этого есть .measure, который может в автоматическом режиме измерять абсолютно все требуемые параметры.
▍ Функция ячейки
Функция ячейки, это информация о том, как эта ячейка будет себя вести при определённых обстоятельствах. Например, при подаче на оба входа NAND сигнала 0, у нас на выходе будет единица. Обычно она даётся в форме таблицы, либо в виде типа ячейки.
Вот наш результат, сравним с таблицей и видим, что они полностью соответствуют друг другу:
Познакомились с теорией, теперь давайте установим необходимые инструменты, а затем приступим к практике в следующих частях.
Об авторе
Меня зовут Арман и я окончил институт Synopsys по профилю VLSI разработки микросхем. В основном я занимаюсь разработкой цифровых компонентов для микросхем и IP для ПЛИС. В прошлом я был программистом, писал бэкенд на Node.js и разрабатывал под микроконтроллеры, но решил пересесть на что-то сложнее, попробовать себя, так сказать.
Я открыт к найму, поэтому, если вас интересует найм разработчика цифровых микросхем с тремя годами опыта и очень интересными проектами (Радио-модемы, преобразователи интерфейсов, процессоры и очень многое) напишите мне в личку.

