Как работают text2image модели?
Вы, наверное, слышали про dalle-2, midjourney, stable diffusion? Слышали о моделях, которые по тексту генерируют картинку. Совсем недавно они продвинулись настолько, что художники протестуют, закидывая в стоки картинки с призывом запретить AI, а недавно, вообще, в суд подали! В этой статье будем разбираться, как такие модели работают. Начнем с азов и потихоньку накидаем деталей и техник генерации. Но будем избегать сложной математики — если хотите в нее погрузиться, то рекомендую эту статью (ссылка).
 https://imagen.research.google
https://imagen.research.google
Диффузии
Все нашумевшие text2image модели — диффузии. Поэтому мы и начнем с разбора, что такое диффузия. Диффузии в нейронных сетях — метод генерации изображений. И начнем мы разбирать этот метод в контексте генерации без всяких условий. Без текста.
Диффузионный процесс в контексте генераций изображений — это два процесса. Прямой и обратный. Прямой процесс портит изображение, обратный восстанавливает. Начнем с прямого. Он портит изображение в белый шум. И это важная деталь. В результате зашумления мы хотим не просто испортить изображение, сделать его неинтерпертируемым, а хотим получить именно нормальное независимое распределение на пикселях. Зачем нам это? Чтобы затем семплировать из этого нормального распределения. Иными словами, наш прямой процесс упрощает распределение картинок, и в конце оно становится настолько простым, что мы можем легко генерировать эти «испорченные» картинки.
 https://drive.google.com/file/d/1DYHDbt1tSl9oqm3O333biRYzSCOtdtmn/view
Тут прям хорошая преза про диффузии.
https://drive.google.com/file/d/1DYHDbt1tSl9oqm3O333biRYzSCOtdtmn/view
Тут прям хорошая преза про диффузии.
Портить изображение мы будем по следующей формуле:
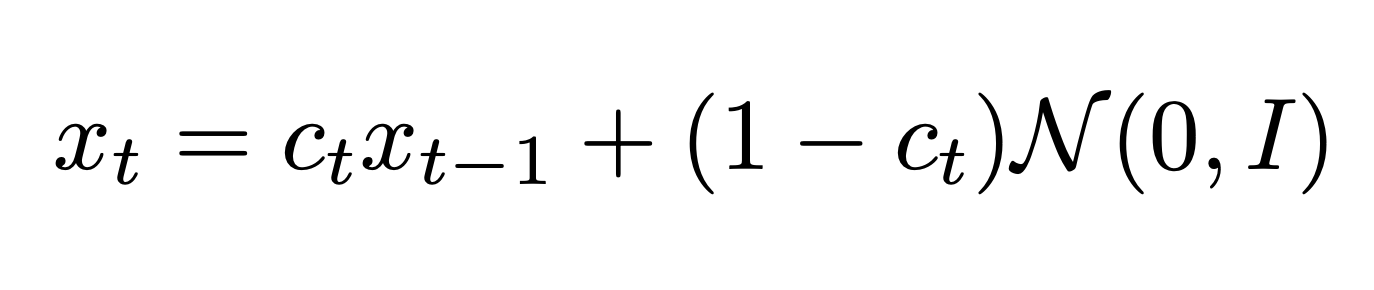
Что тут написано? Что на каждом шаге мы будем домножать изображение на число, меньшее 1, и прибавлять шум. Таким образом, за много шагов сведем изображение просто к белому шуму.
Для понимания процесса мне нравится картинка ниже. Она хорошо показывает, как на каждом шаге процесса мы упрощаем распределение картинок до чего-то очень понятного.
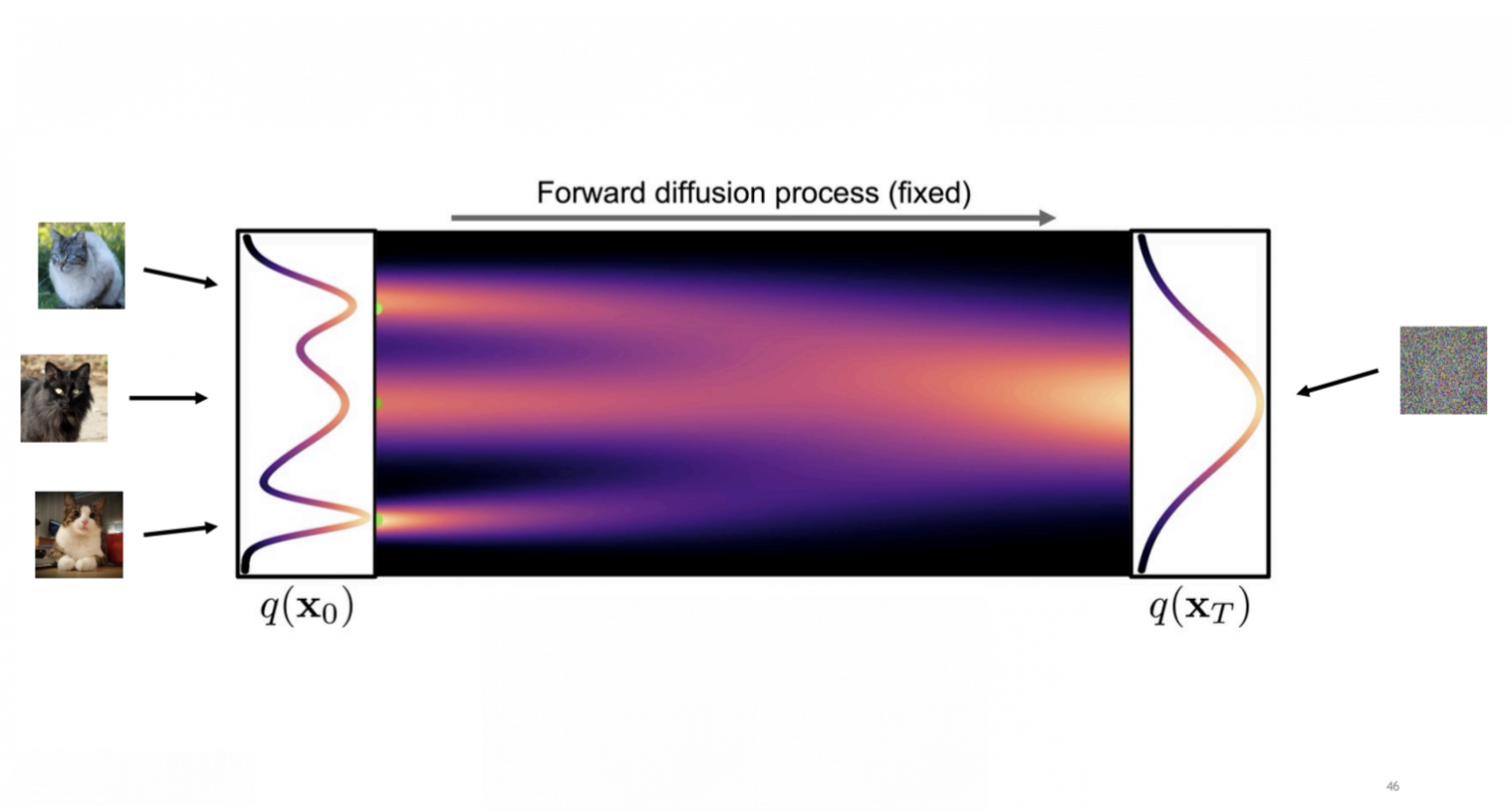 https://drive.google.com/file/d/1DYHDbt1tSl9oqm3O333biRYzSCOtdtmn/view
https://drive.google.com/file/d/1DYHDbt1tSl9oqm3O333biRYzSCOtdtmn/view
А теперь самое интересное. Вот мы сгенерировали зашумленное изображение. Его надо расшумить. Расшумлять будет обучаемая нейронная сеть. Тут надо вспомнить, как мы зашумляли: домножали изображение на константу и прибавляли шум. Константы мы знаем, результат мы знаем. А значит, чтобы восстановить изображение, нам нужен шум. Собственно, шум мы и будем предсказывать нейронкой.
Осталось разобраться с нейронкой. Предсказывать мы будем шум размером с картинку. Для таких задач часто используется Unet. Его же мы и будем использовать. Unet это симметричная сетка. Изображение на вход, изображение на выход. В нашем же случае на вход будет подаваться не только изображение, но и время. Чтобы его добавить, используют либо небольшую полносвязную подсетку, либо тригонометрические преобразования, либо и то и то. Получившиеся фичи подсовывают через домножение или конкатенацию в фичемапы Unet-а
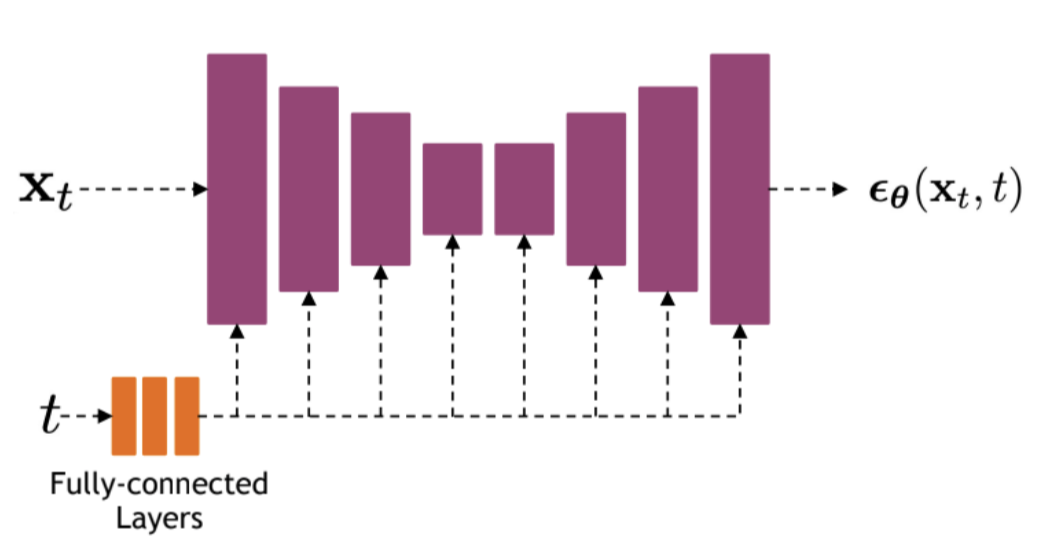 https://drive.google.com/file/d/1DYHDbt1tSl9oqm3O333biRYzSCOtdtmn/view
https://drive.google.com/file/d/1DYHDbt1tSl9oqm3O333biRYzSCOtdtmn/view
В результате получаются такие вот алгоритмы. Тут  — номер шага (время),
— номер шага (время),  — изображения,
— изображения,  шумы, а
шумы, а  — наша сетка.
— наша сетка.
 https://arxiv.org/pdf/2006.11239.pdf
https://arxiv.org/pdf/2006.11239.pdf
Обратите внимание на семплирование. Описанное выше семплирование базовое, очень понятное. Буквально делаем весь процесс назад. Однако алгоритмы семплирования могут быть другими. И запускаться они могут поверх обученной модели без дополнительной тренировки. Идея в том, что мы можем немного «срезать углы» во время обратного процесса. Сделать не все шаги, а только часть, и перевзвесить константы в формулах. Но раз уж мы договорились без математики, то как это сделать пусть будет очевидным.
 Handi#2783 @ discord
Лучше источника чем дискорд я не нашел.
Handi#2783 @ discord
Лучше источника чем дискорд я не нашел.
Stable Diffusion
С общими принципами диффузий мы разобрались, так что пришло время разбирать конкретные методы. Разбирать мы будем Stable Diffusion. Это одна из нашумевших text2image моделей, но ее отличает открытость. Для нее есть и статья, и исходный код, и веса. Самое важное, наверное, — это веса, ибо их доступность породила множество интересных методик поверх уже обученной модели.
Первая надстройка — диффузия гоняется в латентном пространстве. Дело в том, что Unet — это тяжелая архитектура. Возможно, не по количеству весов, но по количеству вычислений. Она много работает на исходном разрешении входной картинки, и это долго. Особенно если учесть, что диффузию надо прогнать много раз. Отсюда идея — диффузионный процесс надо гонять не на изображениях, а на их представлениях меньшего разрешения. Иными словами, не в пространстве изображений, а в скрытом, латентном пространстве. Чтобы перевести изображение в такое пространство, обучается автоэнкордер. Это нейронная сеть из двух подсеток. Энкодер, который сжимает изображение, и декодер, который разжимает его назад. Собственно сжатое таким образом изображение и будет нашим латентным представлением.
Вторая пристройка — это метод передачи условия. Собственно то, как мы будем давать диффузии информацию о тексте. Особенность Stable Diffuision в том, что механизм модульный, и информацию можно передавать не только о тексте, но и о чем угодно.
Как это работает? В два этапа. На первом этапе из условия извлекаются признаки предобученной сеткой. В случае текста используется CLIP ViT-L/14. На выходе он дает вектора-признаки для каждого слова токена.
Второй этап — пропихивание этих признаков в процесс диффузии. Для этого используется механизм cross-attention. С его помощью мы прокинем информацию о тексте в промежуточные слои Unet-а.
 https://prompt-to-prompt.github.io
https://prompt-to-prompt.github.io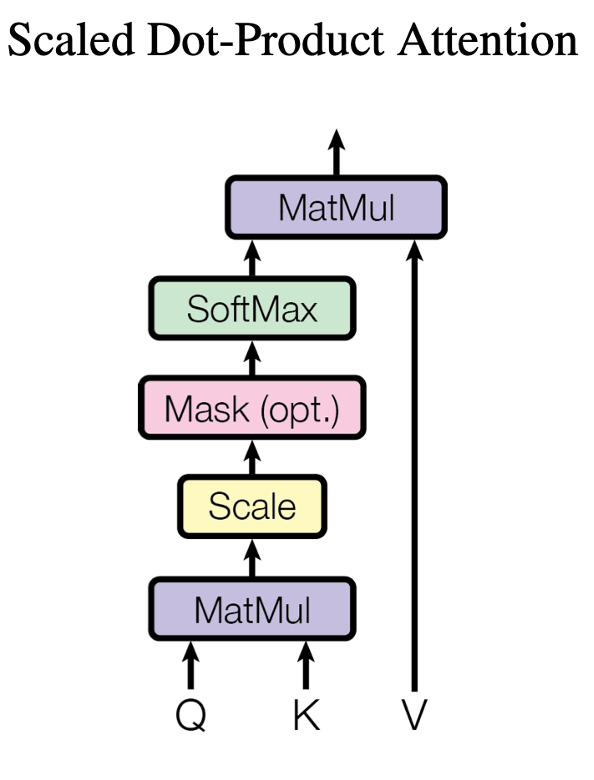 https://arxiv.org/pdf/1706.03762.pdf
https://arxiv.org/pdf/1706.03762.pdf
Cross-attention придумали для нейронок, занимающихся обработкой текста. Кратко напомню, в чем идея. На вход в cross-attention подаются Q, K, V. В нашем случае Q, V — это эмбединги слов из текста, домноженные на обучаемые проецирующие матрицы. K — это тоже спроецированные признаки, но на этот раз из Unet-а. Что формально происходит дальше, отлично видно на картинке. Но если говорить об интерпретации, то attention занимается тем, что по K и Q вычисляет маску внимания (тензор из чисел между 0 и 1), и домножает V на эту маску.
Собственно, вот это и есть самые яркие детали Stable Diffusion. Если хочется больше деталей, то уже лучше идти в статью, а мы тут остановимся. В результате получился алгоритм, который умеет генерировать во многих смыслах высококачественные изображения. Но мы пойдем чуть дальше и посмотрим, что еще можно с ним сделать. А сделать можно много всего, и в первую очередь из-за модульности. Так как stable diffusion состоит из множества частей, модулей, выдающих промежуточные результаты, то, подменяя эти результаты, можно контролировать генерацию.
Prompt-to-Prompt Image Editing
 https://prompt-to-prompt.github.io
https://prompt-to-prompt.github.io
Начнем с задачи редактирования входного текста. Если просто отредактировать текст и отдать на генерацию, никогда не знаешь, что получится на выходе. Скорее всего что-то абсолютно новое. А что делать, если мы хотим получить то же самое изображение, но чуть измененное? Измененное ровно там, где изменился текст? Для этого вспомним, как работает cross-attention. Cross-attention создает маски между фичами Unet-а и эмбедингами слов токенов в запросе. Если посмотреть на эти маски, то неожиданно окажется, что они осмыслены и отображают генерируемый для соответствующего слова объект. Да и меняются со временем тоже осмысленно. От размазанной по всей картинке каши до узнаваемого образа.
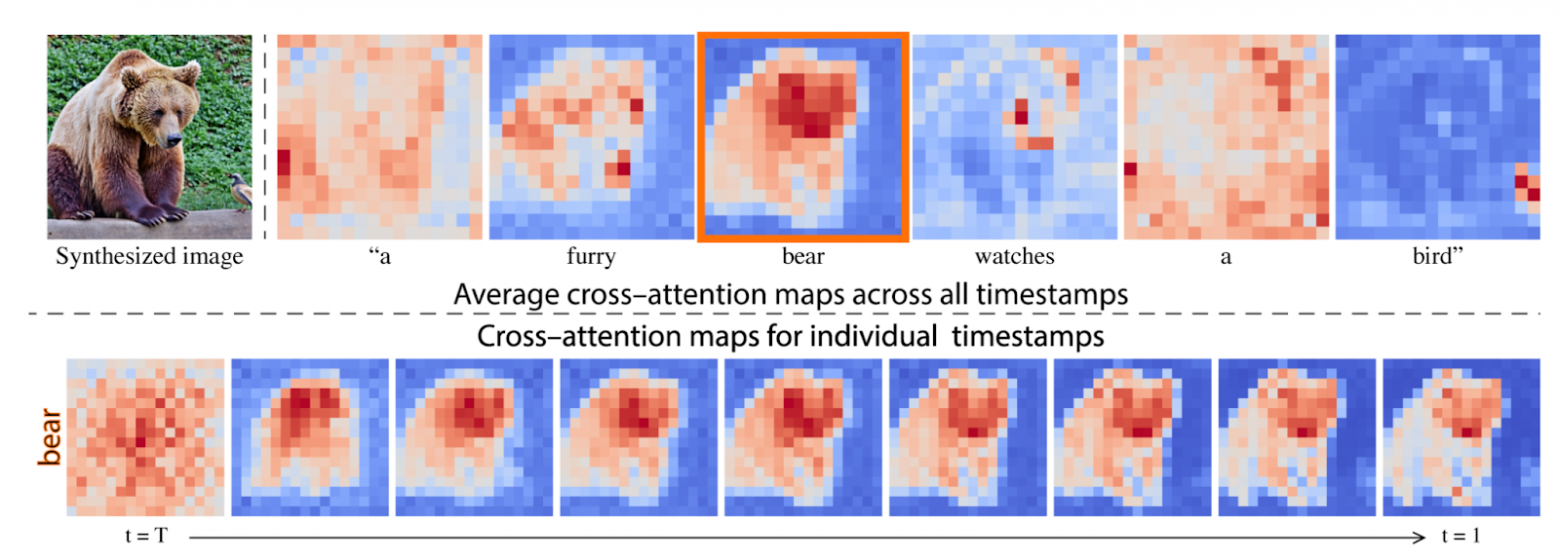 https://prompt-to-prompt.github.io
https://prompt-to-prompt.github.io
Отсюда идея. Давайте при редактировании текста по началу использовать маски оригинального запроса, а потом измененного. И эта идея работает. Причем чем позже начать менять маски оригинальных слов, тем лучше сохранится оригинальное изображение.
 https://prompt-to-prompt.github.io
https://prompt-to-prompt.github.io
Dreambooth
А теперь давайте представим, что мы хотим сгенерировать изображение с человеком. Да не с простым, а с самими собой. Да еще и в разных образах. К сожалению, ни одна сетка не знает, кто ты такой, не было тебя размеченного в датасетах. Значит будем доучивать. Придумаем новое слово «w», наберем фотографий с собой и будем дообучать сетку по запросу «w человек» восстанавливать себя.
 https://dreambooth.github.io
https://dreambooth.github.io
А потом генерировать себя в разных стилях. Или свою собачку. Или табуретку.
Vision Decoding
И напоследок научимся читать мысли. А точнее, восстанавливать, что видит испытуемый по снимку фМРТ. фМРТ — это почти тоже самое, что МРТ. Огромная штука, в которую ты ложишься и ждешь, пока твой мозг отсканируют. Как и МРТ, она меряет кислород, но делает это быстрее и в меньшем разрешении. На выходе получается 3х мерный тензор, где в каждом вокселе записано количество кислорода.
Этот тензор мы сожмем автоэнкодером, засунем в StableDifusion вместо текста и обучим. Будет работать с точностью 22%, то есть в 22% случаев сетка сгенерирует тот же объект, что видел пациент. И это очень много для такой задачи!
 https://mind-vis.github.io
https://mind-vis.github.io
На этом все. Рассказывать можно еще много. Про то, как генерировать этой же технологией музыку, как делать видосы. Но мне надоело.
P.S. Хабр, ****, хранит черновики локально, в кеше браузера.
