Как работают нейронные генераторы картинок (в формате ELI5)
Хочу очень кратко рассказать, на каких принципах построены современные нейронные генераторы картинок типа DALL-E, MidJourney, Make-a-Scene, чтобы немножко разбавить флёр волшебства и магии, который окружает публичное обсуждение результатов их работы. Для того, чтобы понимать перспективы собственных профессий в мире, где похожие генераторы производят вообще все виды электронных артефактов (видео, тексты, программы, 3D-модели и так далее), –, а этот мир нас, безусловно, ожидает в самом ближайшем будущем — надо понимать, что за генерацией стоит довольно простая математика на основе данных, которые ввели клавиатурой и мышкой и закачали в интернет люди.
(Должен сразу предупредить, что для специалистов текст окажется может оказаться смехотворным. Например, я полностью опускаю детали применения градиентного спуска при обучении, вообще не упоминаю слои в нейронках, уже не говоря о развёртках или там, рекурренции. Также я ловко обхожу вопрос довольно значительного различия между классической многослойной архитектурой и трансформерами. Мне кажется, что это детали реализации, хотя в них, конечно, и вложены мегалитры программистской крови. В общем, если вы работаете в этой области, то вам может быть не очень интересно, зато мне будет интересно прочитать ваши комментарии, чтобы улучшить статью и сделать её ещё более простой и понятной.)
Распознавание образов
Для разговора о генерации картинок лучше начать с обратной задачи, которая была решена существенно раньше. Это распознавание картинок (образов), то есть определение изображённых на них объектов. Самые простые реализации её решения хорошо работают в программах распознавания текстов. Какой-нибудь древний FineReader умел отсканировать текст из книги, вырезать из него буквы, потом превратить их в символы и составить текстовый документ.
Алгоритм распознавания букв представляет из себя длинную последовательность условий вида «Если пиксели складываются в два кружочка друг над другом, то это либо восьмёрка, либо кириллическая буква 'В — Ворона', либо латинская буква 'B — Basket'» или, например, «Если в слове есть много букв и одна восьмёрка, то скорее всего это всё-таки буква, а не восьмёрка». Эти условия применяются друг за другом по очереди много-много раз и в результате получается текст, возможно с ошибками, если бумага была грязная. В программе распознавания печатных текстов таких условий может быть несколько тысяч.
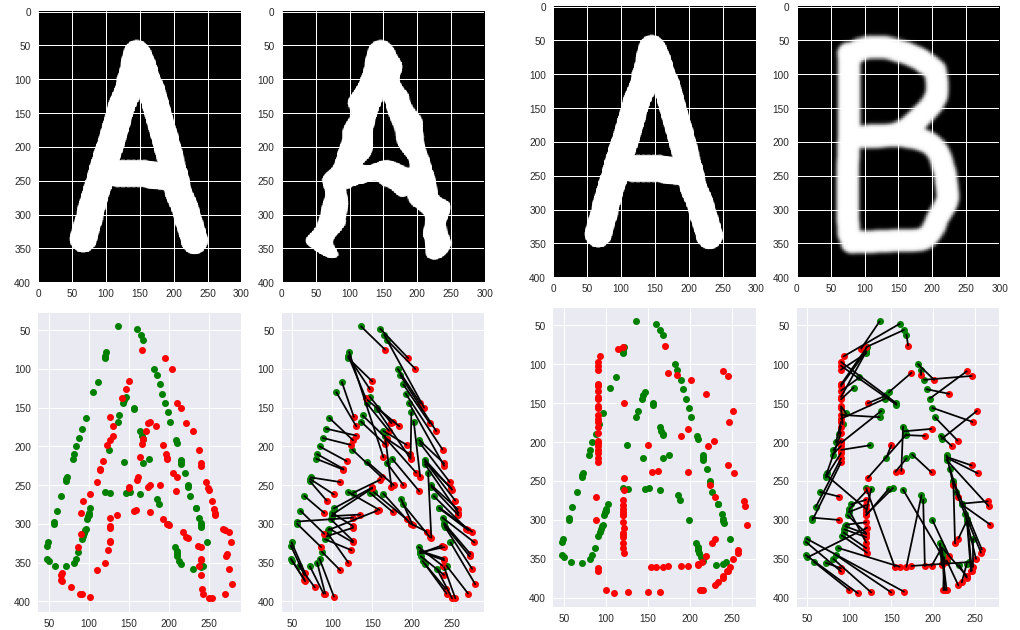
Такая же задача, но с гораздо большим числом условий может распознавать и более сложные объекты, скажем рукописные буквы или вообще фрагменты реальности на фотках. Например, ваш телефон скорее всего умеет находить лица, чтобы фокусироваться на них. Для этого он применяет точно такое же распознавание образов, только не с тысячью, а с несколькими миллионами условий вида «Если пиксель номер 765 тёмный, а вокруг него есть от 13 до 98 светлых пикселей, то это возможно чей-то глаз».
Нейронные сети
Программисты за последние 20 лет придумали много способов быстро применять такие списки условий. Одна из прорывных технологий в этой области — нейронные сети. Сама по себе идея искусственных нейрончиков, соединённых в сеть, очень старая, появилась в 1960-х, но в последние годы были найдены новые способы её использовать, что привело к очередному витку прогресса. Нейронная сеть представляет из себя огромную систему формул-многочленов (как уравнения, только без знака «равно») с большим числом переменных и описание, как в эти формулы подставить входные данные (например, цвет пикселей или коды букв), чтобы на выходе получился результат распознавания (например, тип предмета с картинки или строка букв на другом языке).
Одно из свойств нейронных сетей состоит в том, что их нужно «учить». Вручную составлять формулы, по которым принимается решение, нельзя. Для обучения берут пустую нейронную сеть, полную случайных чисел, применяют её к картинке «восьмёрки», видят на выходе какую-то букву, а затем по специальному алгоритму немножко подкручивают коэффициенты внутри формул так, чтобы для этой учебной картинки сеть выдавала именно цифру »8». Эту процедуру повторяют много миллионов раз на разных учебных картинках и постепенно формулы нейронной сети начинают всё чаще правильно угадывать картинки. Обученную нейронную сеть иногда называют «моделью».
Важно отметить, что нейронная сеть не является базой данных и не хранит внутри себя все примеры, которые ей показывали при обучении. Комбинация формул сети после многократной подстройки коэффициентов выдаёт значение, которое следует из входных данных согласно каким-то закономерностям, которые автоматически выделяются из примеров при обучении. Поэтому, например, очень редко встречающиеся примеры, выбивающиеся из закономерностей, вообще никак не повлияют на модель, они будут подавлены более частыми примерами.
Учёные и программисты примерно к середине 2010-х создали быстрые алгоритмы, подобрали хорошие наборы учебных картинок и поставили создание нейронных сетей, которые распознают образы, на поток. Например, уже тогда ко всем картинкам, которые постили в Фейсбуке, добавлялся alt-текст с описанием изображённых на картинке объектов. Этот alt-текст позволял слепым пользователям приблизительно понимать, о чём картинка.
Neural Style Transfer
В 2015 году группа товарищей из одного немецкого университета изобрела остроумный способ применения уже обученных нейронных сетей под названием Neural Style Transfer. Сначала выбиралась хорошая, большая обученная сеть-модель, которая умела распознавать много картинок. Они уже тогда были свободно доступны в интернете. На вход этой сети подавалась картинка №1, формулы сети вычислялись, но не до конца! Вычисления прерывались, например, на шаге 10 (из 12). Сырые, промежуточные значения всех формул сохранялись в отдельное место, затем сеть сбрасывалась к исходному состоянию и на её вход подавалась картинка №2. Действие повторялось. Вычисление снова прерывалось, но на ещё более раннем этапе, например на шаге 5.
А после этого запускался третий, совершенно новый, интересный алгоритм: программа начинала «выдумывать» картинку №3, которая бы в той же самой сети на шаге 5 выдавала максимально те же значения, что картинка №2, а на шаге 10 — те же, что и картинка №1. Этот алгоритм генерировал картинки, которые были в крупных деталях похожи на картинку №1, а в мелких — на картинку №2.
Так появился Neural Style Transfer и программа Prisma, которую весь Рунет скачивал в 2016 году. Помните, как все конвертировали свои селфи «в стиль Ван Гога»?
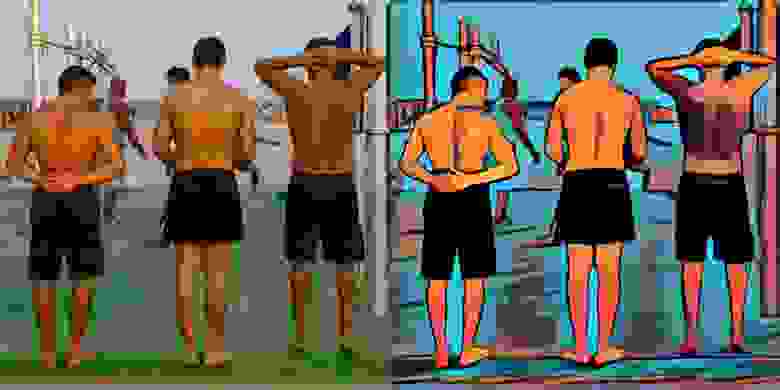
Deep Dream
Одновременно с этим Google опубликовал свой эксперимент под названием Deep Dream. Программа Deep Dream точно так же использовала уже обученную распознавать картинки нейронную сеть, но вместо двух картинок ей на вход подавалась одна. Другим параметром Deep Dream был номер шага вычислений, который требовалось «усилить», например шаг 12 из 15. Deep Dream проводила частичные вычисления до шага 12, затем полученные промежуточные значения умножала на константу и таким образом немножко увеличивала. После этого в точности как в Neural Style Transfer происходило «выдумывание» новой картинки, которая бы в той же самой распознающей сети на 12 шаге сразу давала те самые «усиленные» значения без всякого умножения.
Таким образом Deep Dream генерировала картинки, на которых были выделены и усилены некоторые детали оригинальной картинки. Например, кусок облака с двумя точками мог превратиться в морду собаки, потому что он, действительно, если прищуриться, немножко напоминал эту морду и сеть даже находила её, но соответствующая формула давала весьма малое значение, которое сильно перебивалось формулами «облака», «неба», «дыма» и так далее. Зато после усиления этого самого 12 шага собачья морда внезапно проявлялась значительно более явно.

Полезным результатом этих двух забавных, но довольно бесполезных игрушек, оказались 1) алгоритм, который по промежуточным значениям формул внутри нейронной сети рассчитывал входные значения, то есть генерировал картинки вместо их анализа, 2) наблюдение, что промежуточные шаги вычисления формул соответствуют уровням детализации входных картинок.
Для решения задачи генерации картинок по тексту в том виде, в котором её реализовал Midjourney, потребовалось ещё 5 лет исследований. Сеть DALL-E была анонсирована в начале 2021 года.
Большие текстовые модели на трансформерах
За эти годы учёные десятка лабораторий мира придумали много новых алгоритмов работы с нейронными сетями, в том числе так называемые «большие текстовые модели на трансформерной архитектуре». Буду называть их дальше БТМ. Ярким представителем этого семейства является модель GPT 2018 года, которая умеет генерировать тексты. Принцип применения БТМ очень прост, если смотреть с большой высоты, — это точно такая же система формул-уравнений, но вместо пикселей картинки на вход подаются коды символов входного текста, а с выходов снимаются коды символов текста, который наилучшим образом продолжает входной. Что значит «продолжает»? При обучении GPT, например, ей на вход подавали тексты из интернета (не все, но многие), «откусывая» от них «хвосты» разной длины. Сеть генерировала продолжение, а затем алгоритм подстраивал формулы так, чтобы это продолжение было равно откушенному «хвосту». Таким образом через миллиарды итераций эта модель прочитала весь интернет и научилась по любому началу текста приблизительно догадываться до продолжения.
Скажем, если попросить такую сеть продолжить текст «yesterday all my troubles seemed», она быстро предложит «so far away», потому что видела в интернете тексты всех песен Beatles (и не один раз). Интересно, что если при обучении выкусывать не только хвостики разной длины, но и любые другие произвольные фрагменты, то наша сеть без каких-либо изменений алгоритма сможет вписывать пропущенные слова, дополнять тексты предисловиями или даже генерировать перевод на иностранный язык (ведь в интернете полным-полно словарей и уже переведённых текстов)! Изобретение БТМ (первую статью про них опубликовали учёные из Google в 2017 году) по праву считается огромным прорывом в области искусственного интеллекта.
Вспомним, что нейронные сети не хранят все примеры, на которых их обучали. Они хранят закономерности. По этой причине самое интересное происходит, когда на вход БТМ подают тексты, которых вообще не было в интернете. В этом случае модель генерирует текст, который следует из всех выученных моделью языковых закономерностей, таких как грамматика, морфология и даже смысловые связи между словами. Такой текст наилучшим образом дополняет входной текст, если бы тот был-таки написан реальным человеком и выложен в интернет.
Генерация картинок
Теперь, наконец, можно перейти к основной задаче, про которую написан этот пост, — генерации картинок по описанию. В её решении к началу 2021 года учёные и программисты совместили идеи, описанные выше — применение БТМ и использование промежуточных значений формул нейронных сетей.
Какая-то светлая голова заметила, что в интернетах вслед за текстом (или сразу перед текстом, или просто рядом с текстом) часто расположены картинки. Что, если мы попробуем соорудить такую нейронную сеть, которая будет «продолжать» заданный нами кусочек текста картинкой? Получится как бы БТМ, только вместо Т (текста) там будет «текст или картинка». Для этого нужно было придумать, как в формулах нейронной сети использовать коды символов текста и пиксели картинок одновременно, чтобы они не мешали, не забивали друг друга, но при этом кодировались примерно похожими форматами чисел и могли участвовать вместе в одних и тех же формулах.
Удобно подходят промежуточные результаты применения заранее обученных сетей. И для текста, и для картинок это будут одинаково выглядящие числа, кодирующие некие детали содержимого оригинальных входных данных. К результату такой сети нужно применить дополнительную операцию, которая из чисел восстановит нормальное, человеко-понятное изображение.
Сказано-сделано. Так получился DALL-E, а потом Midjourney и ещё десяток больших «мультимодальных» трансформерных моделей. Словом «мультимодальный» здесь обозначен тот факт, что они работают со входными данными нескольких разных форматов или «модов». Сами модели представляют из себя огромные многотерабайтные файлы коэффициентов формул, о которых я говорил в начале. Для быстрого одновременного вычисления миллионов формул используются мощные дорогие видеокарты (которые, кстати, оказались подходящими для этой задачи совершенно случайно). Большую ценность и коммерческую тайну владельцев этих моделей составляет обучающая выборка — тот самый набор учебных картинок, текстов и, в случае DALL-E и Midjourney, пар-соответствий между текстами и картинками, который и позволяет модели выделить и закодировать в себе закономерности связей между образами и смыслом, так заботливо выложенные в интернет миллиардами его пользователей :)
Чтобы подвести итог, хочу попробовать ответить на частый вопрос, возникающий сразу после того, как проходит первая волна восхищения и удивления результатами работы этих моделей. Может ли Midjourney сгенерировать что-то абсолютно новое и гениальное? Абсолютно новое — конечно, ведь в алгоритмах используются датчики случайных чисел. Модель вывела и закрепила в себе три типа закономерностей:
человеческого языка (за каким словом или фразой, или буквой обычно следует какое, в какой форме и с какими дополнительными словами рядом);
внешнего вида мира так, как его видит человек (пятна каких цветов обычно соседствуют с какими формами, линии каких форм обрамляют какие градиенты);
связей между языком и образами (какие комбинации пиксельных закономерностей соответствуют слову «anime», какие — фразе «tbilisi photo», а какие — одновременному упоминанию названия эмоции и мелкого пушистого животного).
Этих закономерностей миллионы, а их комбинаций — факториал от этих миллионов (очень-очень-очень большое число). Модель вывела их из данных, доступных в интернете, так как нигде кроме как в интернете взять столько данных нельзя. А кто их туда положил? Правильно, авторы Википедии мы сами и положили, применяя собственные биологические нейронные сети в наших мозгах. Midjourney компонует закономерности о нашем мире, которые он почерпнул из наших текстов и картинок, добавляет туда немножко случайности из датчика случайных чисел, и генерирует картинку, которая наилучшим образом «по мнению человечества» соответствует введённой фразе с учётом всех дополнительных настроек. Midjourney — это зеркало, в котором каждый из нас видит сразу всех нас остальных :) (Поразительный факт с точки зрения программирования: в вычислении цвета каждого пикселя картинки-результата используются данные, производные от вообще всех пикселей и вообще всех букв в картинках и текстах значительной доли интернета.) Гениальна ли такая картинка? Ну ровно настолько, насколько гениальным себя считает коллективное человечество, смотрящееся в зеркало. То есть видимо да, очень гениальна.

