Как работать с данными киберразведки: учимся собирать и выявлять индикаторы компрометации систем
В течение всего прошедшего года в гонке кибервооружений между атакующими и защитниками все большую популярность набирала тема киберразведки или Threat Intelligence. Очевидно, что превентивное получение информации о киберугрозах — очень полезная штука, однако само по себе оно инфраструктуру не обезопасит. Необходимо выстроить процесс, который поможет грамотно распоряжаться как информацией о способе возможной атаки, так и имеющимся временем для подготовки к ней. И ключевым условием для формирования такого процесса является полнота информации о киберугрозе.

Первичные данные Threat Intelligence можно получать из самых разных источников. Это могут быть бесплатные подписки, информация от партнеров, группа технического расследования компании и пр.
Существует три основных этапа работы с информацией, полученной в рамках процесса Threat Intelligence (хотя у нас, как центра мониторинга и реагирования на кибератаки, есть и четвертый этап — оповещение заказчиков об угрозе):
- Получение информации, первичная обработка.
- Детектирование индикаторов компрометации (Indicator of Compromise, IOC).
- Ретроспективная проверка.
Получение информации, первичная обработка
Первый этап можно назвать наиболее творческим. Правильно понять описание новой угрозы, выделить релевантные индикаторы, определить их применимость к конкретной организации, отсеять лишнюю информацию об атаках (например, узконаправленных на определенные регионы) — все это зачастую непростая задача. В то же время есть источники, предоставляющие исключительно проверенные и релевантные данные, которые можно добавлять в базу автоматически.
Для системности подхода к обработке информации мы рекомендуем делить индикаторы, получаемые в рамках Threat Intelligence, на две крупных группы — хостовые и сетевые. Детектирование сетевых индикаторов еще не говорит об однозначной компрометации системы, а вот детектирование хостовых индикаторов, как правило, достоверно сигнализирует об успешности атаки.
К сетевым индикаторам относятся домены, URL, почтовые адреса, совокупность IP-адресов и портов. Хостовые индикаторы — это запущенные процессы, изменения веток реестра и файлов, хэш-суммы.
Индикаторы, полученные в рамках одного оповещения об угрозе, имеет смысл объединять в одну группу. В случае обнаружения индикаторов это сильно облегчает определение типа атаки, а также позволяет легко проверить потенциально скомпрометированную систему на все возможные индикаторы из конкретного отчета об угрозе.
Однако часто приходится иметь дело с индикаторами, обнаружение которых не позволяет однозначно говорить о компрометации системы. Это могут быть IP-адреса, принадлежащие к крупным сетям корпораций и хостингов, почтовые домены сервисов рекламных рассылок, имена и хэш-суммы легитимных исполняемых файлов. Самый простые примеры — IP-адреса Microsoft, Amazon, CloudFlare, которые часто оказываются в списках, или легитимные процессы, появляющиеся в системе после установки программных пакетов, например, pageant.exe — агента для хранения ключей. Во избежание большого количества ложноположительных срабатываний такие индикаторы лучше отсеивать, но, скажем так, не выбрасывать — большинство из них не совсем бесполезны. Если есть подозрения на компрометацию системы, производится полная проверка по всем индикаторам, и обнаружение даже косвенного индикатора эти подозрения может подтвердить.
Поскольку не все индикаторы одинаково полезны, мы в Solar JSOC используем так называемый вес индикатора. Условно, обнаружение запуска файла, хэш-сумма которого совпадает с хэш-суммой исполняемого файла вредоноса, имеет пороговый вес. Детектирование такого индикатора мгновенно приводит к возникновению события информационной безопасности. Однократное же обращение к IP-адресу потенциально опасного хоста по не специфичному порту не приведет к возникновению события ИБ, но попадет в специальный профиль, накапливающий статистику, а детектирование дальнейших обращений в итоге также приведет к расследованию.
В то же время, есть механизмы, казавшиеся нам разумными в момент создания, но в итоге признанные неэффективными. Например, изначально закладывалось, что определенные виды индикаторов будут иметь ограниченный срок жизни, по истечении которого будут деактивированы. Однако, как показала практика, при подключении новой инфраструктуры иногда обнаруживаются хосты, которые годами были заражены различными видами вредоносов. Например, однажды при подключении заказчика на машине руководителя службы ИБ был обнаружен вирус Corkow (на тот момент индикаторам было больше пяти лет), а дальнейшее расследование выявило на хосте эксплуатируемый бэкдор и кейлоггер.
Детектирование индикаторов компрометации
Мы работаем со множеством инсталляций различных SIEM-систем, тем не менее, общая структура записей, попадающих в базу индикаторов, стандартизована и выглядит следующим образом:
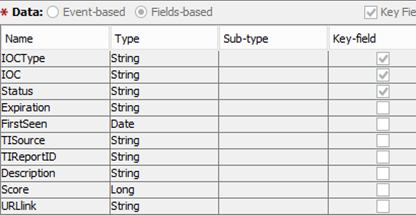
Например, отсортировав индикаторы по TIReportID, можно найти все индикаторы, фигурировавшие в описании конкретной угрозы, а перейдя по URLlink, можно получить ее развернутое описание.
При построении процесса Threat Intelligence очень важно проанализировать информационные системы, подключенные к SIEM, с точки зрения их пользы для выявления индикаторов компрометации.
Дело в том, что описание атаки обычно включает индикаторы компрометации различного типа — например, хэш-сумму вредоноса, IP-адрес СС-сервера, на который он стучится, и так далее. Но если IP-адреса, к которым обращается хост, отслеживаются многими средствами защиты, то информацию о хэш-суммах получить гораздо труднее. Поэтому все системы, которые могут служить источником каких-либо логов, мы рассматриваем с точки зрения того, какие индикаторы они способны отследить:
| Indicator Type |
SourceType |
| Domain |
Прокси серверы, NGFW, DNS серверы |
| URL |
|
| Socket |
Прокси серверы, NGFW, FW |
| Mail |
Почтовые серверы, Антиспам, DLP |
| Process |
Логи с хоста, БД АВПО, Sysmon |
| Registry |
Логи с хоста |
| Hash Sum |
Логи с хоста, БД АВПО, Sysmon, Песочницы CMDB |
Схематично процесс обнаружения индикаторов компрометации можно представить в следующем виде:

О первых двух пунктах я уже рассказал выше, теперь чуть подробнее про проверку по базе IOC. Для примера возьмем события, содержащие информацию об IP-адресах. Правило корреляции для каждого события осуществляет четыре возможных проверки по базе индикаторов:

Поиск ведется по релевантным индикаторам типа Socket, при этом на соответствие индикатору проверяется совокупная конструкция из IP-адреса и соответствующего порта. Т.к. в информации об угрозе далеко не всегда указан конкретный порт, конструкцией IP: any проверяется нахождение в базе адреса с неопределенным портом.
Похожая конструкция реализована в правиле, детектирующем индикаторы компрометации в событиях изменения реестра. В поступающей информации часто отсутствуют данные о конкретном ключе или значении, поэтому при занесении индикатора в базу неизвестные или не имеющие точного значения данные заменяются на 'any'. Итоговые варианты поиска выглядят следующим образом:

Обнаружив в логах индикатор компрометации, правило корреляции создает корреляционное событие, помеченное той категорией, которую обрабатывает инцидентное правило (об этом мы подробно рассказывали в статье «ПРАВИЛьная кухня»).
Кроме категории корреляционное событие будет дополнено информацией о том, в каком оповещении или отчете фигурировал этот индикатор, его весе, данными об угрозе и ссылкой на источник. Дальнейшую обработку событий обнаружения индикаторов всех типов производит инцидентное правило. Его работу схематично можно представить следующим образом:

Но, конечно, следует помнить об исключениях: практически в любой инфраструктуре есть устройства, действия которых легитимны, несмотря на то, что формально содержат признаки компрометации системы. К таким устройствам чаще всего относятся песочницы, различные сканеры и пр.
Необходимость корреляции событий обнаружения индикаторов разных типов также вызвана тем, что в информации об угрозах чаще всего присутствуют разнотипные индикаторы.
Соответственно группировка событий обнаружения индикаторов может позволить увидеть всю цепочку атаки от момента проникновения до эксплуатации.
Событием информационной безопасности мы предлагаем считать реализацию одного из следующих сценариев:
- Обнаружение высокорелевантного индикатора компрометации.
- Обнаружение двух различных индикаторов из одного отчета.
- Достижение порога срабатывания.
С первыми двумя вариантами все понятно, а третий необходим в том случае, когда у нас нет иных данных, кроме сетевой активности системы.
Ретроспективная проверка индикаторов компрометации
После получения информации об угрозе, выделении индикаторов и организации их выявления, возникает необходимость в ретроспективной проверке, которая позволяет обнаружить уже произошедшую компрометацию.
Если немного углубиться в то, как это устроено в SOC, могу сказать, что этот процесс требует по-настоящему колоссального количества времени и ресурсов. Поиск индикаторов компрометации в логах за полгода вынуждает хранить внушительный их объем доступным для онлайн проверок. При этом результатом проверки должна быть не просто информация о присутствии индикаторов, но и общие данные о развитии атаки. При подключении новых информационных систем заказчика данные с них также необходимо проверять на наличие индикаторов. Для этого надо постоянно дорабатывать так называемый «контент» SOC — правила корреляции и индикаторы компрометации.
Для SIEM-системы ArcSight выполнение такого поиска даже за пару прошедших недель может сильно затянуться. Поэтому было принято решение воспользоваться трендами.
«A trend is an ESM resource that defines how and over what time period data will be aggregated and evaluated for prevailing tendencies or currents. A trend executes a specified query on a defined schedule and time duration.»
ESM_101_Guide
После нескольких тестов на нагруженных системах был выработан следующий алгоритм использования трендов:

Профилирующие правила, заполняющие соответствующие активные листы полезными данными, позволяют распределить общую нагрузку на SIEM. После получения индикаторов создаются запросы в соответствующие листы и тренды, на базе которых будут сделаны отчеты, которые в свою очередь будут распространены по всем инсталляциям. Фактически остается лишь запустить отчеты и обработать результаты.
Стоит отметить, что процесс обработки можно непрерывно улучшать и автоматизировать. Например, у нас внедрена платформа для хранения и обработки индикаторов компрометации MISP, на текущий момент отвечающая нашим требованиям по гибкости и функционалу. Её аналоги широко представлены на рынке open source — YETI, зарубежные — Anomali ThreatStream, ThreatConnect, ThreatQuotinet, EclecticIQ, российские — TI.Platform, R-Vision Threat Intelligence Platform. Сейчас мы проводим финальные тесты автоматизированных выгрузок событий непосредственно из базы данных SIEM. Это значительно ускорит получение отчетов о наличии индикаторов компрометации.
Главный элемент киберразведки
Тем не менее, финальным звеном в обработке как самих индикаторов, так и отчетов являются инженеры и аналитики, а перечисленные инструменты только помогают в принятии решений. У нас за добавление индикаторов отвечает группа реагирования, а за корректность отчетов — группа мониторинга.
Без людей система не будет работать достаточно адекватно, нельзя заранее предусмотреть все мелочи и исключения. Например, мы отмечаем обращения к IP-адресам TOR-нод, но в отчетах для заказчика разделяем активность скомпрометированного хоста и хоста, на котором просто установили TOR Browser. Автоматизировать это можно, но вот заранее продумать все подобные моменты при настройке правил достаточно трудно. Так и получается, что группа реагирования по самым различным признакам отсеивает индикаторы, которые будут создавать большое число ложных срабатываний. И наоборот — может добавить специфичный индикатор, высокорелевантный для некоторых заказчиков (например, финансового сектора).
Группа мониторинга может убрать из финального отчета активность песочницы, проверку администраторов на успешную блокировку вредоносного ресурса, но добавить активность о неуспешном внешнем сканировании, показывая заказчику, что его инфраструктуру проверяют злоумышленники. Машина таких решений не примет.

Вместо вывода
Почему мы рекомендуем именно такой метод работы с Threat Intelligence? Прежде всего — он позволяет уйти от схемы, когда под каждую новую атаку надо создавать отдельное правило корреляции. Это отнимает непозволительно много времени и позволяет выявить разве что ведущуюся атаку.
Описанный метод максимально задействует возможности TI — надо просто добавить индикаторы, а это максимум 20 минут с момента их появления, и затем провести полную ретроспективную проверку логов. Так вы и сократите время реагирования, и получите более полные результаты проверки.
Если остались вопросы, добро пожаловать в комментарии.
