Как приручить Polygon или обратная сторона олимпиад
Всем привет!
Меня зовут Кирилл Маглыш и сегодня я хотел бы описать процесс работы с системой polygon на примере создания предпоследней задачи финала олимпиады ВКОШП.Junior.
Введение
Polygon — самая популярная в российском олимпиадном сообществе система для создания задач по программированию, используемая в том числе для проблемсеттинга для codeforces. Однако существует очень мало туториалов по ее использованию (по крайней мере я смог найти только три и все на английском языке — ссылки в конце статьи), поэтому хочется дополнить этот список своим опытом.
Постановка задачи
Мы создадим с нуля задачу Снорк и порядок в кладовой, за тем маленьким исключением, что мы напишем лишь формальное условие, не заморачиваясь с длинной легендой. Итак, в чистом виде задача такова:
УсловиеВводВывод
Почему я выбрал именно эту задачу? Во-первых, она предполагает несколько возможных правильных ответов, что усложняет проверку решения (а коль уж мы программисты, то сложно == интересно) и позволяет показать многие возможности предоставляемые полигоном. Во-вторых, на вход здесь подается дерево, что сложнее обычной последовательности чисел, а это заставляет немного подумать в процессе создания тестов. Также она довольно несложная, но в то же время незаезженная и имеет довольно элегантное решение.
Инициализация
Если вы ещё этого не сделали, то самое время зарегистрироваться на polygon. Затем жмем на кнопку New Problem и вводим имя-идентификатор задачи. Свою я назову habr-task. Жмем Create и перед нами возникает список задач. Находим нашу, и в колонке Working Copy выбираем Start. Перед нами появилась страничка General Info которая выглядит примерно так:
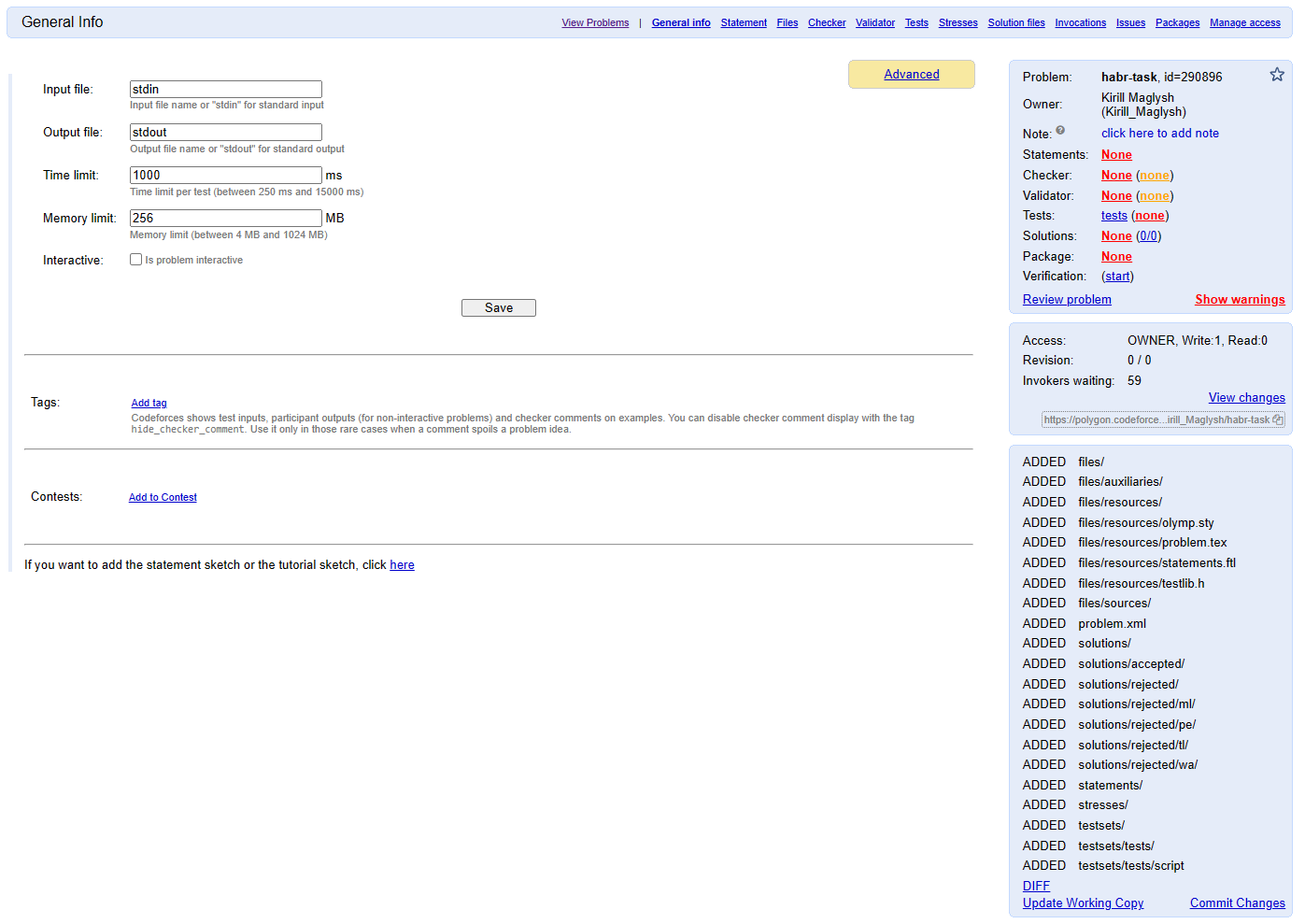
General info
Давайте по порядку разберемся, что тут есть.
Слева мы видим основные параметры задачи: входной и выходной потоки (оставляем stdin и stdout), TL и ML — ограничения мы изменим потом, когда напишем решение и поймем, чего мы хотим от участников. Далее идет чекбокс для интерактивных задач, но это, возможно, станет темой следующей статьи, поскольку процесс создания интерактивок довольно сильно отличается.
Правее есть кнопка Advanced — после нажатия на нее откроется окно, позволяющее скопировать/удалить задачу или добавить двойной запуск решений.
Слева можно (и довольно желательно для удобства поиска) проставить теги для задачи или добавить ее в контест. Контесты выходят за рамки этого туториала, а вот тэги мы добавим, в нашем случае это constructive и dfs and similar.
Далее справа у нас идет структура задачи:
Statements — условия
Checker — проверяет решение участника
Validator — проверяет корректность тестов
Tests — тесты, либо загружаемые вручную, либо созданные специальной программой — генератором
Solutions — решения (как правило корректные на нескольких языках, а также превышающие TL или дающие WA)
Package — собранная версия задачи
Verification — проверка всех компонентов задачи
Собственно, все эти пункты мы и должны реализовать в этом туториале.
Затем внизу есть секция с кучей строк формата «ADDED…». Одно из больших преимуществ полигона — встроенная система контроля версий. Как раз сейчас и пришло время сделать первый коммит. Нажимаем Commit Changes в окно комментария пишем Initial commit и ставим галочку, чтобы не сыпался спам на почту.
А теперь давайте пойдем по списку выше.
Пишем условие
Жмем на Statements, в появившемся окне выбираем язык, русский в нашем случае, и попадаем на страницу:
Пустая форма для условия задачи
Пустая форма для условия задачи
Здесь можно выбрать формат работы с условием: нажав на Edit with Preview вы разделите экран на две части и справа отобразится уже отформатированная собранная версия. Для того, чтобы посмотреть как будет выглядеть задача со стороны пользователя также можно кликнуть на InLaTeX, InHTML, InPDF — так вы можете посмотреть на внешний вид условия в разных вариантах. Обязательно учитывайте, что одно и то же условие может отображаться неодинаково, и фишки форматирования, которые работают на одном движке, совершенно не обязательно будут работать на другом.
Попробуем сначала просто написать текст (или скопировать выше, но без форматирования), сохранить и открыть In HTML.
Условие без форматирования

Получилось читаемо, но если присмотреться, то можно увидеть явные беды с оформлением: индексы в неправильном регистре, числа и переменные никак не выделены, некрасивое <= и т.д. И здесь мы плавно подходим к ещё одному удобному инструменту полигона - TeX, который легко исправляет все, что я написал выше и позволяет ещё много чего делать. Давайте посмотрим на отформатированную версию условия и посмотрим как TeX работает на примере. Итоговой текст у нас будет такой:
Готовое условие

Так куда лучше, не правда ли?
Условие в редакторе
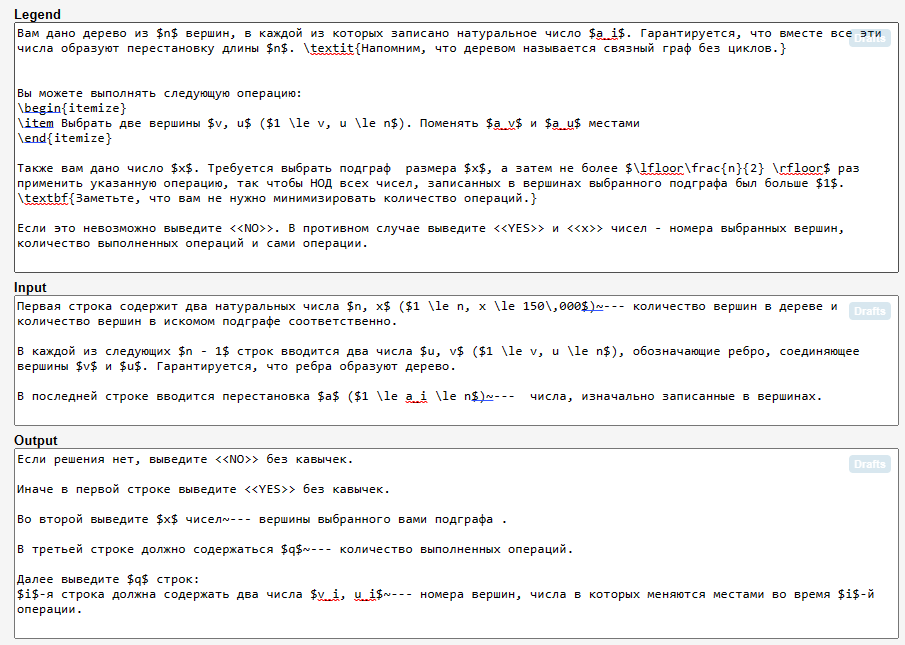
Теперь разберемся с тем, что есть что.
$математическое выражение$ — в долларах записывается формула/число. Полигон переводит текст внутри в читабельный вид с помощью MathJax. Сюда относятся дроби \fract{n}{2}, неравенства, индексация a_i и другой математический синтаксис. При этом $а$ — запись прямо внутри текста, а $$а$$ — вынесет выражение в отдельную строку.
\textCommand{text} — выделение текста (жирный, курсив).
\begin — \end — форматирование некоторого блока текста. Например itemize — маркированный список, а enumerate — нумерованный.
~--- — длинное тире, приклеенное к слову перед ним (тильда отвечает за неразрывность)
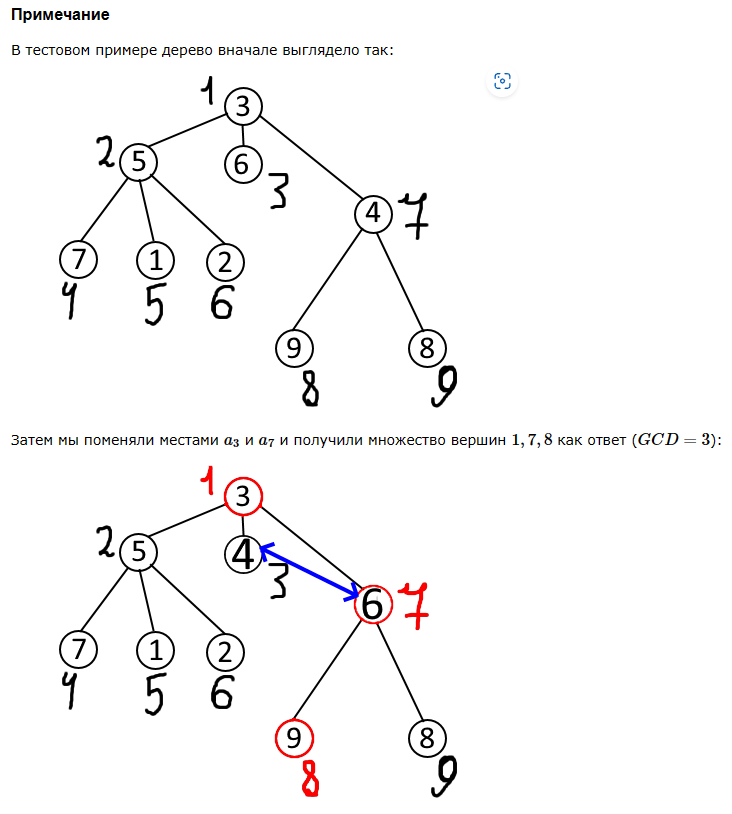
Но это ещё не все. Хотелось бы показать максимальный спектр возможностей полигона, поэтому мы, как ответственные авторы, добавим рисунок и пояснение к первому тестовому примеру (его пока можно смотреть оригинальной задаче).
Тест:
Input:
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
Output:
YES
1 7 8
1
3 7
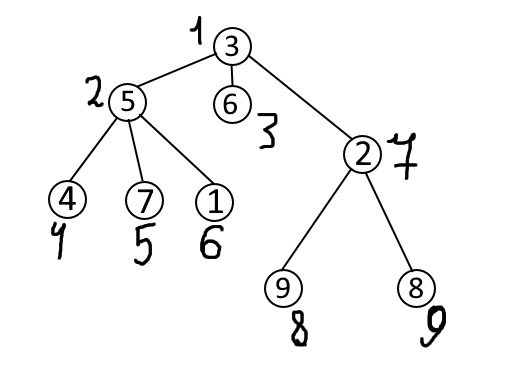
Дерево в начале
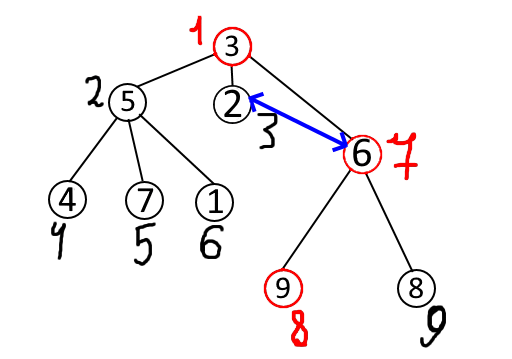
Дерево в итоге
Пояснение в редакторе:

Для того, чтобы вставить изображение, нужно сначала загрузить его в полигон (кнопка Add files внизу страницы), а затем вписать его название в \includegraphics{}
Собранная версия
Наконец, условие полностью готовы, можем коммитить и идти дальше.
Основное решение (C++)
Вообще, у всех своя последовательность действий, но я предпочитаю писать решение (хотя бы основное) как можно раньше. Как правило я делаю это даже прежде, чем пишу условие или по крайней мере раньше, чем его форматирую. Это связано с несколькими ситуациями, в которых я придумывал красивую идею для задачи, понимал какие разнообразные тесты под нее можно сделать, как ее красиво описать в условии, делал все это, а потом осознавал, что придумал что-то нерешаемое и идея на самом деле была красивой, но абсолютно нерабочей. Поэтому лучше сразу написать код решения, так вы гораздо лучше поймете саму задачу, столкнетесь с тонкими моментами, которые необходимо описать в условии, возможно, придумаете специальные тесты, но самое главное, будет ясно, что задача решается.
В нашей задаче все довольно просто: выделяем подграф размера  и «закидываем» в его вершины четные числа. Тогда, если
и «закидываем» в его вершины четные числа. Тогда, если  , то ответ существует, т.к.
, то ответ существует, т.к.  в подграфе будет кратен двум, а иначе решения просто нет, т.к. нам дана перестановка от 1 до n, а значит ни на один простой делитель не делится больше половины чисел.
в подграфе будет кратен двум, а иначе решения просто нет, т.к. нам дана перестановка от 1 до n, а значит ни на один простой делитель не делится больше половины чисел.
Код
/**
* Task: Отформатируй дерево (habr-task)
* C++ correct solution
*
* Complexity: O(N)
* Memory: O(N)
*
* @author Kirill_Maglysh
* @since 12.02.2023
*/
#include
#include
using namespace std;
int n, x;
vector> graph;
vector a;
vector white;
vector whiteOdd;
vector blackEven;
void dfs(int v, int p = -1) {
if (int(white.size()) < x) {
white.push_back(v);
if (a[v] & 1) {
whiteOdd.push_back(v);
}
} else {
if (!(a[v] & 1)) {
blackEven.push_back(v);
}
}
for (const auto& to : graph[v]) {
if (to != p) {
dfs(to, v);
}
}
}
void solve() {
cin >> n >> x;
if (n / 2 < x) {
cout << "NO\n";
return;
}
cout << "YES\n";
graph.resize(n);
for (int i = 0; i < n - 1; ++i) {
int v, u;
cin >> v >> u;
--v;
--u;
graph[v].push_back(u);
graph[u].push_back(v);
}
a.resize(n);
for (auto& item : a) {
cin >> item;
}
dfs(0);
for(int i = 0; i < int(white.size()); ++i) {
cout << white[i] + 1;
if (i < int(white.size()) - 1){
cout << ' ';
}
}
cout << '\n';
cout << whiteOdd.size() << '\n';
for (int i = 0; i < int(whiteOdd.size()); ++i) {
cout << whiteOdd[i] + 1 << ' ' << blackEven[i] + 1 << '\n';
}
}
int32_t main() {
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
solve();
return 0;
}
Здесь мы делаем простой дфс по двудольному графу.
По решению, пожалуй, обращу внимание только на шапку файла. Здесь опять же нет никакого единого подхода. Многие не пишут ничего, кто-то указывает только автора. Я стараюсь писать именно в таком формате, как в примере выше: название, описание (здесь оно короткое, но тот факт, что это корректное решение тоже важен, как мы увидим позднее, бывают не только такие), временная сложность и затраты памяти алгоритма, а также автора решения и дату написания. Такой подход помогает, когда у вас много задач, а для них много решений, особенно если среди них существуют разные по асимптотике — вы можете легко восстановить в памяти все необходимое перед прочтением кода.
А теперь загружаем наше решение во вкладке Solution.

Список решений
Здесь также можно скомпилировать фалы и проверить, что все хорошо.
Коммитим.
Validator
Теперь напишем валидатор — код, который будет проверять корректность наших тестов. Здесь можно задаться сразу несколькими вопросами.
Во-первых, а зачем вообще проверять тесты? Мы же сами их написали, мы ведь не идиоты, чтобы пихать в задачу некорректные тесты… Но на самом деле все не так просто. Тесты — важнейшая часть задачи, к тому же очень чувствительная. С одной стороны, если вы обнаружите, что решение работает слишком медленно, вы можете уменьшить ограничения на входные данные, и тесты станут некорректными. С другой, а почему мы вообще уверены, что все сделали правильно?
Простой пример: в условии указано, что числа вводятся в строку, а наши тесты сгенерированы так, что каждое число печатается на новой строке (по невнимательности всякое бывает). И решение на C++ отработает прекрасно, cout вообще без разницы, в каком формате считывать. Scanner на Java тоже отработает великолепно. А вот стандартный ввод в Python или BufferedReader в Java вдруг упадут. Да, решение на питоне у нас скорее всего будет, но где гарантии, что погрешности, с которыми с легкостью справится один язык, не станут фатальными для второго? Их просто нет. Поэтому тесты всегда должны строго соответствовать формату и всегда должны проверяться. В конце концов, мы как разработчики точно не хотим, чтобы по нашей вине кто-то из участников несправедливо не взял диплом.
Во-вторых, а почему, собственно, мы пишем штуку, которая будет проверять то, чего ещё нет в природе? Отдаленно, это напоминает TDD (именно отдаленно, но, по-моему, сходства есть). Пока мы пишем валидатор, мы четко обозначим все ограничения на тесты и переберем большинство вероятных ошибок, а значит, при написании самих тестов вероятность допустить эти самые ошибки будет гораздо меньше.
Это была философия, а теперь давайте к самому валидатор. Важнейшая вещь, с которой мы сталкиваемся при его написании — библиотека testlib. С ее помощью пишутся не только валидаторы, но и чекеры, и генераторы. Помимо прочего, testlib связывает их между собой и, чекер может, например, сразы читать потоку ввода, пользовательского вывода и вывода автора.
Чтобы использовать testlib у себя на компе, достаточно просто склонировать репозиторий, а потом в Make файле в вашем редакторе указать зависимость.
include_directories(path\\testlib)Все, что мы сегодня будем писать, я, естественно, буду комментировать, но если кто хочет, отдельно про testlib можно почитать тут.
Код валидатора
#include "testlib.h"
using namespace std;
const int maxN = 150'000;
int n;
vector used;
int dfs(int v, const vector> &graph) {
used[v] = true;
int sz = 1;
for (const auto &to: graph[v]) {
if (!used[to]) {
sz += dfs(to, graph);
}
}
return sz;
}
void checkGraphIsTree() {
vector> graph(n);
for (int i = 0; i < n - 1; ++i) {
int v = inf.readInt(1, n, "v") - 1;
inf.readSpace();
int u = inf.readInt(1, n, "u") - 1;
graph[v].push_back(u);
graph[u].push_back(v);
inf.readEoln();
}
used.resize(n);
ensuref(dfs(0, graph) == n, "Given graph is no a tree");
}
void checkPermutation() {
vector vals = inf.readInts(n, 1, n, "a");
inf.readEoln();
sort(vals.begin(), vals.end());
for (int i = 0; i < n; ++i) {
ensuref(vals[i] == i + 1, "A[] is not a permutation");
}
}
int main(int argc, char *argv[]) {
registerValidation(argc, argv);
n = inf.readInt(1, maxN, "n");
inf.readSpace();
inf.readInt(1, maxN, "x");
inf.readEoln();
checkGraphIsTree();
checkPermutation();
inf.readEof();
}
Попробуем по порядку разобраться, что тут происходит. Сначала в main мы регистрируем валидатор. Это просто служебная строчка, вам не нужно ее менять, можно просто запомнить и вставлять в начало валидатора для каждой задачи. Далее мы считываем  . inf — это поток ввода, и в данном случае, он содержит в себе наш тест. Важно помнить, что валидатор — максимально строгий предмет, то есть и ввод в нем максимально строгий. Метод
. inf — это поток ввода, и в данном случае, он содержит в себе наш тест. Важно помнить, что валидатор — максимально строгий предмет, то есть и ввод в нем максимально строгий. Метод readInt(int minv, int maxv, const std::string &variableName) не станет проматывать поток до следующего числа или игнорировать пробелы. Он считает ровно то, что идет во вводе следующим, попутно проверив, что число лежит в заданных границах. Это довольно удобно, т.к. нам не надо писать никакого технического кода, напротив библиотека сделает все за нас, и, если данные некорректны, сообщит об этом (для этого и нужно передавать имя считываемой переменной). Затем мы ожидаем пробел, число  и окончание строки.
и окончание строки.
Далее уже начинается какая-то логика. Метод checkGraphIsTree() начинается считыванием ребер, в котором ничего нового нет, а вот дальше идет ensuref(dfs(0, graph) == n, "Given graph is no a tree") — это своего рода assert (). Если мы хотим проверить, что условие истинно, мы передаем его первым параметром. В случае, когда проверка не выполнилась, будет выведено сообщение, которое мы даем функции вторым параметром.
Из нового в checkPermutation() вызывается метод readInts(int size, int minv, int maxv, const std::string &variablesName, int indexBase) без последнего парметра (он автоматически true). readInts позволяет нам считать нужное количество чисел, данных через пробел и находящихся в заданном диапазоне. Обратите внимание на то, что во все читающие методы передаются диапазон и название переменной. В testlib есть и аналогичные методы не требующие этих параметров, но хорошим тоном считается использовать именно подробный вариант, т.к. он делает ошибки максимально прозрачными. Если вы что-то пропустите, полигон начнет ругаться и кидать варнинги.
Осталось загрузить валидатор на соответствующей странице и… написать тесты. Но нет, пока тесты не к задаче, а к самому валидатору. Дело в том, что в процессе его написания часто можно забыть ввод какого-то пробела или переноса строки, поэтому мы напишем несколько простых примеров, которых валидатор должен распознать как VALID или INVALID. В такие тесты разумно записать все хоть сколько-то необходимые проверки: дать валидатору почти дерево, поставить где-то лишний пробел, ввести больше ребер, чем надо, ввести большие числа и т.д.
Тесты валидатора
Можно сразу указать несколько, главное не забыть разделитель === и полигон сам разнесет данные на разные тесты.
Ввод9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
===
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 9
===
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 6
3 5 6 4 7 1 2 9 8
===
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
7 9
3 5 6 4 7 1 2 9 8
===
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8 11
===
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
===
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
===
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
VALID
INVALID
INVALID
INVALID
INVALID
INVALID
INVALID
INVALID
Ура, валидатор готов!
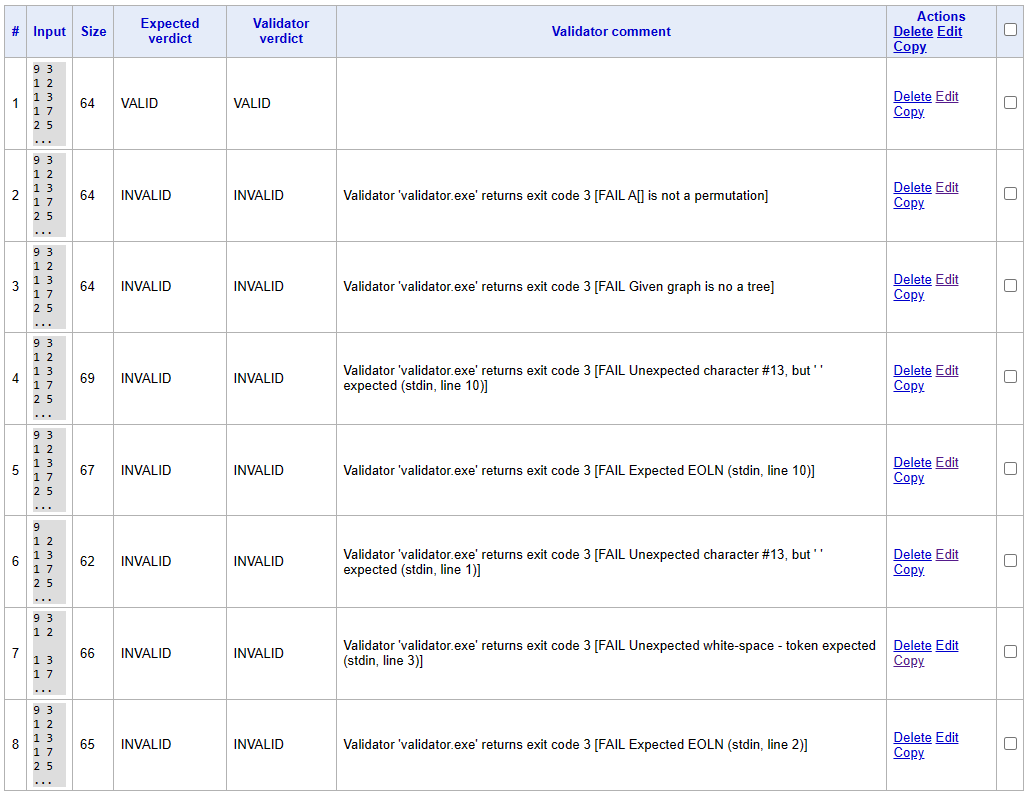
Результаты тестирования валидатора
Checker
Проверять тесты мы уже научились, теперь давайте проверим пользовательские решения, а именно напишем чекер. Здесь мы все также используем наш testlib.
Во-первых, нужно понять что мы вообще проверяем. Конкретно в этой задаче нам нужно:
Считать первое слово, если не совпадает, то WA, если совпадает и NO, то OK.
Если в предыдущем пункте YES, то сначала нужно проверить, что выведено правильное количество операций, затем проделать эти операции и проверить

Давайте это и сделаем. Сразу оговорюсь, что в чекере уже не нужно четко следовать формату ввода и читать пробелы и концы строк, это требование устанавливается только для валидатора строчкой registerValidation(argc, argv). Код чекера будет выглядеть так:
Чекер
#include "testlib.h"
using namespace std;
const int maxN = 150'000;
int n, x;
vector> graph;
void checkYesNo() {
string author = ans.readLine("YES|NO", "YES|NO");
string participant = ouf.readLine("YES|NO", "YES|NO");
if (author == "YES" && participant == "NO") {
quitf(_wa, "Jury found answer, but participant didn't");
} else if (author == "NO" && participant == "YES") {
quitf(_wa, "Wrong answer");
} else if (author == "NO" && participant == "NO") {
quitf(_ok, "Correct: NO solution");
}
}
void readGraph() {
graph.resize(n);
for (int i = 0; i < n - 1; ++i) {
int v = inf.readInt(1, n, "Vertex id in edge") - 1;
int u = inf.readInt(1, n, "Vertex id in edge") - 1;
graph[v].push_back(u);
graph[u].push_back(v);
}
}
void readOperations(vector &vals) {
int cnt = ouf.readInt(0, n / 2, "Operation number");
for (int i = 0; i < cnt; ++i) {
int v = ouf.readInt(1, n, "Swapping vertex, operation " + toString(i)) - 1;
int u = ouf.readInt(1, n, "Swapping vertex, operation " + toString(i)) - 1;
swap(vals[v], vals[u]);
}
}
int dfs(int v, const vector &white, int p = -1) {
int sz = 1;
for (const auto &to: graph[v]) {
if (to != p && white[to]) {
sz += dfs(to, white, v);
}
}
return sz;
}
vector readSubtree() {
vector subTree(x);
vector able(n);
for (int i = 0; i < x; ++i) {
subTree[i] = ouf.readInt(1, n, "Chosen vertex " + toString(i)) - 1;
able[subTree[i]] = true;
}
int visitedCnt = dfs(subTree[0], able);
if (visitedCnt != x) {
quitf(_wa, "vertex Set is not a tree");
}
return subTree;
}
void checkGCD(const vector &vals, const vector &subTree) {
int GCD = 0;
for (const auto &v: subTree) {
GCD = __gcd(GCD, vals[v]);
}
if (GCD > 1) {
quitf(_ok, "SubTree is correct");
} else {
quitf(_wa, "GCD in subtree is equal to 1");
}
}
int main(int argc, char *argv[]) {
setName("FormatTheTree checker");
registerTestlibCmd(argc, argv);
checkYesNo();
n = inf.readInt(1, maxN, "Vertex number");
x = inf.readInt(1, maxN, "Target size");
readGraph();
vector vals = inf.readInts(n, 1, n, "a");
vector subTree = readSubtree();
readOperations(vals);
checkGCD(vals, subTree);
}
Пройдемся по файлу и посмотрим, что здесь происходит.
Во-первых, мы используем три входных потока:
ans — ответ жюри, сгенерированный Main Correct Solution
inf — текст теста
ouf — вывод участника
Обращение к этим потокам устроено абсолютно также как и в валидаторе. Но, раньше мы не использовали метод readLine(const pattern &p, const std::string &variableName = ""). Это ещё одна мощная вещь из testlib. Мы можем передать в нее нужный нам шаблон, и библиотека сама проверит корректность данных (подробнее о шаблонах тут).
Также появился метод quitf(TResult result, const char *format, ...), который завершает работу чекера с нужным нам вердиктом и сообщением.
В остальном ничего необычного, просто реализация описанного выше алгоритма.
Тут также стоит отметить, что в нашем случае задача имеет несколько возможных ответов, что усложнило логику проверки и заставило нас писать сой чекер. Однако по возможности стоит использовать системные. Они уже протестированы на тысячах примеров и имеют много форматов, покрывающих довольно большую часть задач. Для этого нужно просто выбрать в списке нужный нам файл:

Системные чекеры
Как я уже сказал, системные чекеры хорошо протестированы, но что на счет нашего? Да, нам придется написать несколько тестов, чтобы быть уверенными в том, что наш код работает верно. Тут опять же нет больших отличий от тестирования валидатора. Нужно рассмотреть несколько крайних случае, продумать какие ошибки мог бы допустить участник и удостоверится, что чекер их найдет.
Тесты чекера
Чтобы добавить тест, заходим в Checker и жмем Add test. Ответ можно сразу генерировать автоматически, а вот ввод-вывод придется писать самим.
Ок, YES9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
YES
1 2 5
3
1 4
2 3
5 7
9 5
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
YES
1 2 3
5
1 2
2 3
3 4
4 5
5 6
1 2 3 4 5
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
YES
1 7 9
0
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
YES
1 7 8
1
3 7
1 9
Чекер написан, коммитим!
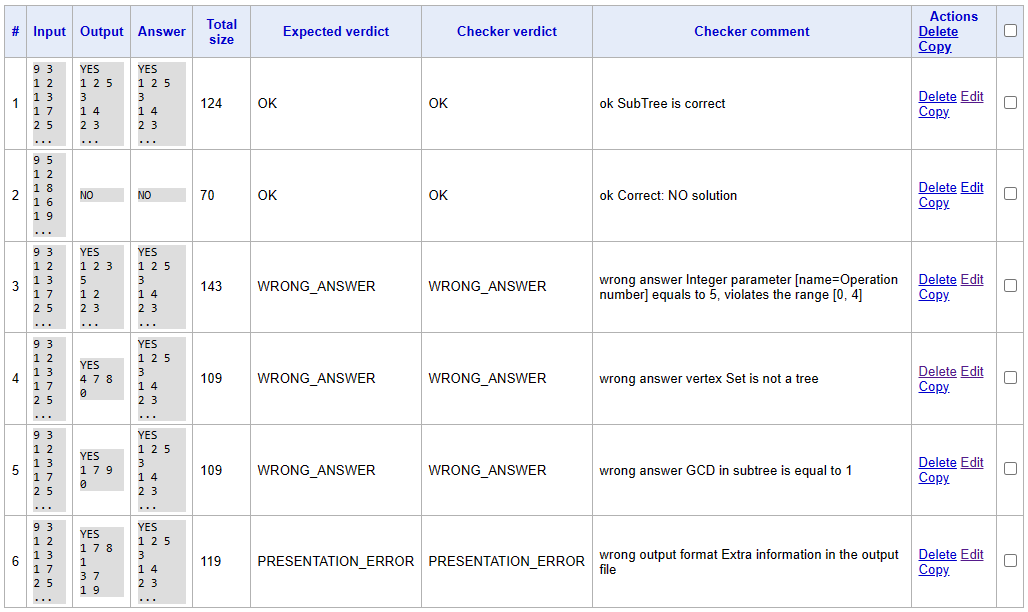
Generator и тесты
Ура, это свершилось! Мы наконец-то переходим к подготовке тестов. Сам процесс как правило занимает больше времени, нежели остальные, и этот раздел будет также больше других.
Тесты можно поделить на рукописные и сгенерированные автоматически. Начнем с первых, так как для генерации нам понадобится сразу несколько интсрументов.
Итак, сначала добавим тест, к которому мы уже написали примечания и который пойдет в условие. Для этого заходим в tests, жмем Add test, в поле Data вводим сам тест и ставим галочку Use in statements. После этого появится предложение сделать свой ввод-вывод, а не сгенерированный решением. Жмем click_here и вываливается ввод/вывод в условии. Зачем нам вообще что-то менять? Как и любые порядочные авторы, мы хотим, чтобы участник получил максимальное удовольствие, а это значит, что ему нельзя подсказывать, поэтому мы не будем давать ему ответ, полученный нашим алгоритмом, а просто напишем другое правильное решение.
Тест в условии
Input:
9 3
1 2
1 3
1 7
2 5
2 4
2 6
7 8
7 9
3 5 6 4 7 1 2 9 8
Output:
YES
1 7 8
1
3 7
Теперь можем зайти в условие и убедиться, что тест появился.
Что насчет автоматических тестов? Здесь мы будем использовать два инструмента. Первый — генератор. Он очень похож на валидатор и чекер, которые мы уже писали.
Часто тесты бывают принципиально разными (разные типы деревьев, или принципиально отличающиеся по свойствам массивы). Для таких случаев есть два решения. Первое — писать по генератору на каждый тип тестов. Этот подход хорош тем, что код генератора не разрастается и всегда остается понятным. Второе — сделать в одном генераторе несколько функций, которые будут генерировать разные типы тестов, а тип передавать в командной строке. Здесь также есть свои преимущества. Во-первых, если для генерации нужно много вспомогательного кода, нам придется его дублировать во всех файлах, а если найдем ошибку, то и менять во всех. Во-вторых, часто нужно указывать мин и макс значения переменных, которые будут созданы программой. Их, конечно, можно задавать из скрипта (про него чуть позже), но когда они всегда одинаковы, так заморачиваться не очень хочется. В общем, метод каждый выбирает сам для себя, я обычно пользуюсь вторым.
Когда мы на при подготовке олимпиады тестировали эту задачу, никакого решения кроме авторского так придумано и не было, а для авторского никаких специальных тестов в данном случае подобрать не получится, поэтому (и для экономии времени) мы напишем один генератор, который будет выдавать нам рандомное дерево и рандомную перестановку.
Код генератора
#include "testlib.h"
#include
using namespace std;
void genRandomPermutation(int n) {
println(rnd.perm(n, 1));
}
void genRandomTree(int n) {
vector vs = rnd.perm(n, 0);
int randCnt = rnd.next(1, 5);
for (int i = 0; i < randCnt; ++i) {
shuffle(vs.begin(), vs.end(), mt19937(random_device()()));
}
vector used;
used.push_back(vs.back());
vs.pop_back();
while (!vs.empty()) {
cout << rnd.any(used) + 1 << ' ' << vs.back() + 1 << '\n';
used.push_back(vs.back());
vs.pop_back();
}
}
int main(int argc, char *argv[]) {
registerGen(argc, argv, 1);
int n = opt("n");
int x = has_opt("x") ? opt("x") : (rnd.wnext(n - 1, -3) + 1);
cout << n << ' ' << x << '\n';
genRandomTree(n);
genRandomPermutation(n);
return 0;
}
Что у нас здесь происходит?
Во-первых, изменился способ получения данных. Теперь мы читаем аргументы командной строки (о том, откуда они берутся — чуть позже). Для этого есть несколько способов. В примерах, прикрепленных на полигоне можно увидеть запись вида atoi(argv[1]). Но минус этого варианта в том, что нужно помнить о том, какой параметр какому индексу соответствует, да и постоянно вызывать функцию преобразования не очень-то хочется. Поэтому в одни чудесные новогодние праздники MikeMirzayanov добавил удобный способ чтения — opts (почитать можно тут). Как видно из кода, чтобы получить нужный параметр нужно всего лишь написать opt<тип>(имя). Есть и другой способ, который я когда-то подсмотрел у Владимира Новикова — распарсить argv в map<имя, значение> и потом обращаться к этой мапе.
Во-вторых, много обращений к разным функциям, возвращающим случайный результат. В testlib вообще есть много полезных методов, которые позволяют генерировать случайные перестановки, распределения чисел в диапазоне, случайный элемент из контейнера и т.д. Например, метод wnext (int n, int type) генерирует случайное число из диапазона [0, n]  раз и берет мин/макс из них в зависимости от знака (мин — минус, макс — плюс).
раз и берет мин/макс из них в зависимости от знака (мин — минус, макс — плюс).
Вывод происходит как обычно, через cout или через функции от testlib, как например println(const T &x).
Код генератора у нас готов. Теперь осталось зайти во кладку Files, нажать Add file в разделе Source Files (именно там, важно не перепутать) и выбрать нужный нам файл.
Теперь нужно создать сами тесты. Тут опять есть два способа. В любом случае нам нужно перейти в tests и написать скрипт. Первый способ — перечисляем тесты, которые нужны в формате generator-name [params] > {test-indices} — то есть gen -n=5 -x=2 > $ в нашем случае. Так мы можем перечислить столько тестов, сколько нам нужно, а дальше полигон все сделает за нас.
Но есть и другой путь. Чтобы не писать кучу тестов вручную, можно написать полноценный скрипт с использованием Freemarker. Это очень удобная штука, которая позволяет нам сжать много однотипных строчек в один цикл. В нашем случае скрипт будет выглядеть так:
<#assign nBase = 15/>
<#assign nMinus = 1/>
<#list 1..5 as power>
gen -n=${nBase} -x=${(nBase - nBase % 2) / 2} > $
<#list 7..0 as testNumber>
gen -n=${nBase - nMinus * testNumber} > $
<#assign nBase = nBase * 10>
<#assign nMinus = nMinus * 10>
<#assign maxN = 150000/>
<#list 5..1 as testNumber>
gen -n=${maxN} -x=${maxN/2 - testNumber} > $
Вуаля! 50 тестов готово всего в 14-ти строках. Но что же здесь написано. По сути тут всего 2 команды: assign — задать значение переменной, list — цикл. А текст без тегов мы выводим в качестве тестов. То есть в данном случае будет сгенерировано 5 тестов по шаблону gen -n=${nBase} -x=${(nBase - nBase % 2) / 2} > $. 40 по шаблону gen -n=${nBase - nMinus * testNumber} > $ И 5 макстестов: gen -n=${nBase} -x=${nBase/2 — testNumber} > $
Коммит
Мы близки к цели (верификация)
На самом деле мы уже почти вышли на финишную прямую. Теперь можно проверить работоспособность всего, что бы написали, кликнув на start в пункте Verification.

Ура! Мы получили ok, а значит, решение, тесты, валидатор и чекер работают. Теперь осталось немного украсить скелет задачи.
Решения на других языках (Java, Python)
Мы уже поняли, что на плюсах все чудесно функционирует, но, к сожалению или к счастью, часто нужно, чтобы задача сдавалась ещё и на питоне. Я обычно пишу ещё на Java на всякий случай. Перевести, как правило, недолго, а подвериться, что все хорошо работает на трех самых популярных языках не помешает. Давайте зайдем в Solutions и добавим два новых решения с тегом Correct.
Python
n, x = map(int, input().split())
if x * 2 > n:
print("NO")
exit(0)
print("YES")
graph = [[] for i in range(n)]
vis = set()
def bfs():
q = [0]
ptr = 0
vis.add(0)
while ptr != len(q):
if len(vis) == x:
break
fst = q[ptr]
ptr += 1
for ch in graph[fst]:
if ch not in vis:
vis.add(ch)
if len(vis) == x:
break
q.append(ch)
for i in range(1, n):
u, v = map(int, input().split())
u, v = u - 1, v - 1
graph[u].append(v)
graph[v].append(u)
bfs()
a = [int(x) for x in input().split()]
free = []
operation_cnt = x
for i in range(n):
if a[i] % 2 == 0:
if i not in vis:
free.append(i)
else:
operation_cnt -= 1
for i in vis:
print(i + 1, end=' ')
print()
print(operation_cnt)
for u in vis:
if a[u] % 2 != 0:
print(u + 1, 1 + free.pop())
Java
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
/**
* Task: Format the tree
* Java correct solution
* Complexity: O(N)
* Memory: O(N)
*
* @author Kirill_Maglysh
* @since 12.02.2023
*/
public class FormatTheTree {
int maxN = 150000;
int n;
int x;
List> graph;
int[] vals = new int[maxN];
List white;
List whiteOdd;
List blackEven;
void dfs(int v, int p) {
if (white.size() < x) {
white.add(v);
if (((vals[v] & 1)) == 1) {
whiteOdd.add(v);
}
} else {
if ((vals[v] & 1) == 0) {
blackEven.add(v);
}
}
for (Integer to : graph.get(v)) {
if (to != p) {
dfs(to, v);
}
}
}
private void solve() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
String[] in = reader.readLine().split(" ");
n = Integer.parseInt(in[0]);
x = Integer.parseInt(in[1]);
if (n / 2 < x) {
System.out.println("NO");
return;
}
System.out.println("YES");
graph = new ArrayList<>(n);
white = new ArrayList<>(n);
whiteOdd = new ArrayList<>(n);
blackEven = new ArrayList<>(n);
for (int i = 0; i < n; i++) {
graph.add(new ArrayList<>());
}
for (int i = 0; i < n - 1; i++) {
in = reader.readLine().split(" ");
int v = Integer.parseInt(in[0]) - 1;
int u = Integer.parseInt(in[1]) - 1;
graph.get(v).add(u);
graph.get(u).add(v);
}
in = reader.readLine().split(" ");
for (int i = 0; i < n; i++) {
vals[i] = Integer.parseInt(in[i]);
}
dfs(0, -1);
StringBuilder output = new StringBuilder();
for (Integer v : white) {
output.append(v + 1).append(" ");
}
output.append("\n");
output.append(whiteOdd.size()).append("\n");
for (int i = 0; i < whiteOdd.size(); i++) {
output.append(whiteOdd.get(i) + 1).append(" ").append(blackEven.get(i) + 1).append("\n");
}
System.out.print(output);
}
public static void main(String[] args) throws IOException {
new FormatTheTree().solve();
}
}
Теперь хотелось бы удостовериться в работоспособности решений, но верификация занимает довольно много времени, а тесты уже проверять не нужно, поэтому мы запустим только сами решения. Для этого переходим во вкладку Invocations, жмем на Want to run solutions, выбираем все решения и все тесты и ждем, пока тестирование пройдет.
И все бы хорошо, но на последних тестах решения на питоне и на джаве попали в желтую зону.

Корректное авторское решение не должно превышать половину Tl.
По сути, ради этого мы отчасти и писали решения на других языках.
По правилам хорошего тона корректное авторское решение не должно сильно превышать половину от лимита времени. Мотивируется это довольно логично. У автора есть много времени, чтобы причесать код и довести его почти до максимального быстродействия. От участника же требуется скорее верный алгоритм, а не доскональные оптимизации. Поэтому мы поднимем TL до 2000 мс (это пункт в General Info). И пока мы здесь, можно также понизить ML. Это вообще менее принципиально. Но поскольку наше решение не затратило больше 50 Мб, я опущу границу до 128 Мб.
Итак, снова верификация.
ok!
Некорректные решения (WA, TL)
Также всегда в задачи добавляются решения, которые заведомо являются неправильными или превышают лимит времени исполнения. Делается это для того, чтобы удостовериться, что некорректное решение не пройдет тесты. Но для нашей задачи придумать решение, которое получит TL (и при этом будет достаточно адекватным), довольно непросто. А может я просто чего-то не замечаю, и вы предложите свой вариант в комментариях. Что же касается неправильных решений, то можно написать код, который будет всегда выводить NO или придумать что-нибудь ещё. Но это задание уже останется как упражнение читателю, т.к. ничего нового в плане работы с системой оно не несет.
Пара слов о стресс тестах
Сказав о TL-решении, неправильно было бы промолчать о Stress-тестах в полигоне. Любой, кто погружался в олимпиадное программирование немного глубже самых базовых алгоритмов почти наверняка когда-то писал свои стрессы на какую-то противную задачу, по которой неясно почему WA. И в полигоне все тоже самое. Можно зайти во кладку Stresses, добавить новый тест, ввести script pattern (как в генераторе), выбрать решение и TL и запустить. В итоге решения будут гоняться на тестах пока не найдется тот, после которого вывод будет отличаться, или пока не закончится время.
Собираем пакет и добавляем задачу в мэшап
Осталось только выложить задачу на codeforces. Для этого сначала соберем пакет. Заходим в Packages и видим два варианта: Full иStandart. Стандартный пакет содержит в себе чекеры, валидаторы, решения, генераторы и запускающий код. Полный же помимо этого включает в себя все тесты и несколько дополнительных файлов. Как можно догадаться, стандартный пакет легче и собирается быстрее, к тому же его достаточно для codeforces. Его мы и создадим.
Теперь предоставим системе доступ к нашей задаче. Для этого переходим в Manage Access и добавляем пользователя codeforces с правами на чтение.
Далее копируем ссылку, которая нам понадобится чуть позднее — она расположена внизу среднего справа окошка.

Ссылка на задачу для мэшапа
Идем по этой ссылке Новый мэшап — Codeforces (
