Как при помощи нейросети восстанавливали обугленные свитки из Помпеи (угадайте, с каким контентом внутри)

Результат одной из попыток физически развернуть один из обугленных Геркуланумских свитков. Вот попробуйте читать с такого.
С этими свитками из библиотеки в Геркулануме пошло не так абсолютно всё. Они на папирусе, который состоит из нескольких слоёв расплющенных и спрессованных тростниковых стеблей. Высушенный тростник легко воспламеняется. Температура пирокластических потоков, извергнутых Везувием, достигала 700 ᵒС, поэтому вот что вы видите на фото выше. Впрочем, манускриптам из Геркуланума ещё повезло: из-за высокой скорости движения и температуры газово-пепловых туч воздух из помещений, где они хранились, быстро вытеснился, и папирусы не сгорели, а обуглились.
Сверху у них — грязь селя. Дальше — выпавший из эруптивной колонны вулканический пепел. Получилась довольно прочная оболочка — это «запечатало» помещения, не дав воздуху и влаге окончательно добить бесценные рукописи, буквально законсервировав их почти на 2 000 лет.
Сами свитки очень хрупкие, и это затрудняет их изучение. Одно неловкое движение — и вместо папируса получится горстка пепла. Частично прочесть удалось только наиболее сохранившиеся, а это малая часть всей библиотеки.
Но сейчас удаётся восстановить часть контента с этих древних свитков. Кажется, нам достался самый популярный греческий контент — предметные инструкции, как радоваться жизни. Довольно прикладные.
Что это за свитки

Свиток, первые 2 000 знаков которого были расшифрованы в рамках конкурса Vesuvius Challenge
Конец I века до нашей эры, греческий философ-эпикуреец Филодем Гадарский (предположительно) перебирается из Рима в город Геркуланум, где и умирает, оставив после себя около 800 папирусов. В них он рассуждает о музыке, каперсах, фиолетовом цвете и прочих удовольствиях, а также о том, как правильно радоваться жизни, причём инструкции там довольно предметные. А ещё он критикует своих оппонентов, которые этого делать не умеют.
1 800 свитков Филодема и его коллег хранились в библиотеке на роскошной вилле, принадлежавшей (опять же предположительно) тестю Юлия Цезаря. Но настал 79 год нашей эры, и вулкан Везувий всё испортил. Пирокластические потоки из раскалённых газов, камней и пепла накрыли Геркуланум, в том числе и виллу-библиотеку, обуглив хранившиеся там папирусы. В 1740-х её случайно обнаружили рабочие, которые прокладывали тоннели в вулканическом туфе.
В 2024 году группа студентов-программистов из США, Германии и Швейцарии сумела прочесть целых две тысячи знаков на одном из свитков при помощи компьютерной томографии и технологий современных языковых моделей. Это событие практически единогласно признаётся специалистами в изучении древних текстов как революция. И на то есть все основания.
Так пирокластические потоки сначала обуглили, а потом законсервировали свитки из Геркуланума
Впрочем, это мало утешает археологов. Проблема в том, что папирусы хранились в виде плотно свёрнутых свитков, и первая же попытка развернуть обугленные манускрипты приводила к их распаду на мелкие нечитаемые фрагменты. Кроме того, даже в развёрнутом состоянии прочесть их очень сложно: из-за высокой температуры папирус потемнел, а органические чернила частично или полностью разрушились, сделав текст нечитаемым.
После первых безуспешных попыток раскрыть обугленные свитки из Геркуланума, которые привели к полному уничтожению или сильной фрагментации текстов, священник из Генуи Антонио Пьяджо изобрёл машину, позволявшую худо-бедно разворачивать свитки без значительных повреждений. Она работала так:
- На опору в нижней части установки кладётся свиток, в его передний край продеваются шёлковые нити, которые прикрепляются к винтам в верхней части машины.
- Вращением винта свиток медленно и непрерывно разворачивается от края к центру, а регулируемое натяжение нитей позволяет компенсировать провисание.
- По мере разворачивания свитка развёрнутая часть разделяется на отдельные куски, которые наклеиваются на плёночные полоски, покрытые клеем. Они предохраняют фрагмент от дальнейшего распада.
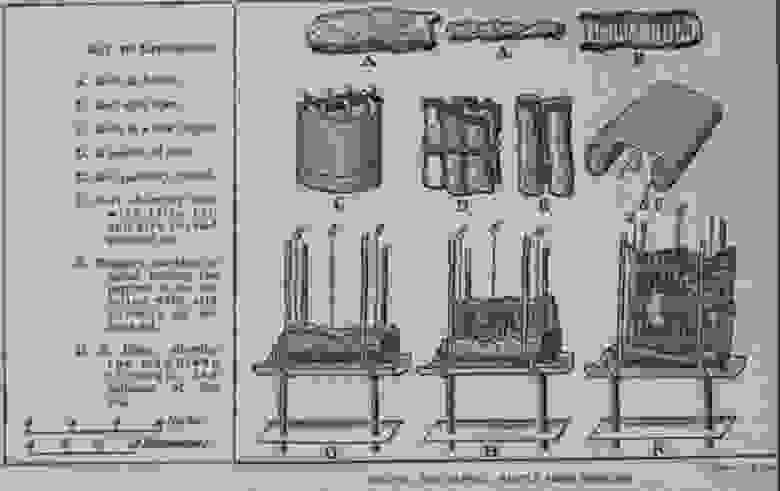
Принципиальная схема работы машины Антонио Пьяджо
Машина Пьяджо помогла относительно безболезненно развернуть некоторое количество свитков, но только тех, которым был нанесён меньший ущерб. Остальные отправили на хранение или выставили в музеях Лондона, Оксфорда, Парижа, Неаполя и других городов.
Первые попытки безопасно развернуть манускрипты из Геркуланума
Сотни обугленных, но сохранившихся свитков из Геркуланума столетиями не давали археологам спокойно спать. Однако до определённого времени всё, что им оставалось делать, — изучать сравнительно неплохо сохранившиеся образцы или по кусочкам собирать те, которые были разрушены в попытках их развернуть. Иногда исследователи осознанно шли на разрушение, например, срезали сильно обугленные внешние слои, чтобы добраться до лучше сохранившихся внутренних. Или разрезали свитки на фрагменты, которые потом кропотливо собирали, как пазлы. Но все эти методы работали плохо и требовали большого количества времени и сил.
Наконец первые подвижки в расшифровке были сделаны около 20 лет назад, когда Брент Силс, профессор компьютерных наук из университета Кентукки, разработал метод цифрового сканирования с помощью компьютерной томографии. Вместе со своей командой он создал специальное программное обеспечение, позволявшее сначала создать 3D-модель свитка, а потом послойно развернуть его. Для максимально точного виртуального отображения манускриптов два из них Брент Силс в 2019 году отсканировал в ускорителе частиц Diamond Light Source, расположенном недалеко от Оксфорда.

Томографирование одного из Геркуланумских свитков в Diamond Light Source
К слову, это не первый опыт команды в расшифровывании древних манускриптов. Ранее по такому же методу им удалось развернуть и прочесть Эн-Геди — один из знаменитых свитков Мёртвого моря. Тогда компьютерная томография в сочетании с машинным зрением позволила «разглядеть» даже написанные на древних пергаментах слова. Однако текст на этих манускриптах был написан минеральными чернилами, которые хорошо отображаются при просвечивании рентгеновскими лучами. К сожалению, свитки из Геркуланума были написаны органическими пигментами, которые томографу безразличны.
Силс и его команда понимали, что с помощью технологии машинного обучения можно прочесть и Геркуланумские манускрипты. Но в их распоряжении было слишком мало ресурсов для разработки соответствующих алгоритмов. И тогда учёные решили компенсировать эту нехватку, подключив ресурсы со стороны.
Vesuvius Challenge и прорыв в прочтении
К Силсу обратились предприниматели из Кремниевой долины Нэт Фридман и Дэниэл Гросс. Он предложил организовать конкурс, в котором на соревновательной основе отдельные энтузиасты и их команды из разных уголков мира предлагали бы свои методики прочтения Геркуланумских манускриптов.
Проект заработал в марте 2023 года. Для ускорения и максимальной эффективности исследований организаторы выбрали схему «конкуренция + сотрудничество»: исследователи-энтузиасты не только соревнуются друг с другом, но и обмениваются наработками, формируют команды. Для, так сказать, стимулирования поисков был предложен один главный приз в размере $700 000 и несколько промежуточных, которые выдавались за разработку программных инструментов и методов с открытым исходным кодом.
Чтобы участникам конкурса было с чем работать, организаторы создали необходимую базу:
- Силс выложил в открытый доступ код своей программы по томографическому сканированию и построению трёхмерных моделей свитков, а заодно и результаты обработки свитков из Геркуланума и района Мёртвого моря.
- Была создана физическая рабочая модель «свиток у костра», имитирующая манускрипт, подвергшийся карбонизации. Она позволила участникам понять, как тепловое воздействие на материал изменяет его структуру, цвет, форму и другие характеристики.
- Также Силс и его команда просканировали имеющиеся фрагменты свитков с выявленными остатками чернил, оставшиеся после предыдущих удачных и неудачных попыток физического развёртывания.
Первым серьёзным прорывом стало открытие «паттернов растрескивания» одним из участников конкурса — Кейси Хэндмейром. Он часами изучал оцифрованные фрагменты свитков и обнаружил повторяющиеся текстурные узоры, напоминающие буквы греческого алфавита. Это стало серьёзным открытием, так как теперь можно было прочесть текст на тех участках папирусов, в которых самого пигмента уже не осталось, зато остались его следы. За своё достижение Кейси получил премию за первые чернила в размере $10 000.

«Паттерн растрескивания» на месте разрушенных чернил, обнаруженный Кейси Хэндмейром
Этим открытием тут же воспользовался другой участник — 21-летний стажёр SpaceX Люк Фарритор. Он начал просматривать отсканированные и развёрнутые массивы папирусных фрагментов в поисках «паттернов растрескивания», используя технологии машинного обучения. В итоге ему удалось прочесть целое слово «порфирас» (в переводе с древнегреческого — «фиолетовый»). За это достижение он получил промежуточный приз в $40 000.

Первое слово, прочитанное Люком Фарритором на виртуальном сегменте свитка из Геркуланума
Спустя ещё несколько недель студент из Германии Юсеф Надер смог усовершенствовать технологию поиска остатков самих чернил, взяв за основу фрагменты свитков, разрушенных при попытках физического развёртывания. Он применил этот метод к плоским сегментам, полученным в процессе виртуального развёртывания сохранившихся манускриптов, и получил достаточно чёткое изображение, позволившее прочесть несколько строк текста. За это достижение ему вручили приз в размере $10 000.
И, наконец, Джулиан Шиллигер, студент-робототехник из швейцарского ETH Zürich, разработал эффективные инструменты для виртуальной 3D-картографии участков папирусов и поиска «паттернов растрескивания», за что получил целых три приза.
Объединив усилия, Джулиан, Люк и Юсеф смогли в итоге распознать целых 15 столбцов текста (в общей сложности — около 2 000 знаков) на виртуальных сегментах одного из неразвёрнутых свитков. Их данные были проверены командой из профессиональных папирологов — результаты были настолько впечатляющими, что команде однозначно присудили главный приз в размере $700 000.
Как это работает?
Разработанный организаторами и участниками Vesuvius Challenge метод прочтения древних свитков включает в себя три основных этапа.
Сканирование. По сути, это тот же процесс, который применяется в медицинской компьютерной томографии. Отличие в том, что для сканирования свитков используется не больничный томограф, а рентгеновская установка ускорителя частиц, которая даёт картинку в значительно более высоком разрешении. Свиток размещается на поворотной платформе, расположенной между излучателем и приёмником (камерой) рентгеновского излучения. Полученные сотни и тысячи снимков с разных ракурсов затем объединяются с помощью алгоритмов томографической реконструкции в 3D-модель, состоящую из вокселов. Значение каждого воксела отражает радиоплотность соответствующего фрагмента свитка. Полученные таким образом трёхмерные модели сохраняются в виде стека файлов .tif, каждый из которых представляет собой изображение одного поперечного среза.
Срез из стека изображений, полученных в процессе компьютерной томографии
Сегментация. Далее в цифровой трёхмерной модели свитка идентифицируются отдельные слои папируса, называемые «сегментами». Теоретически можно построить и единый сегмент для всего свитка, но точность при этом уменьшается, поэтому сегментацию проводят отдельными кусками. С помощью инструмента Volume Cartographer команда сегментации вручную выделяет один слой на срезе из стека, после чего программа экстраполирует эти данные на другие срезы. В результате получается трёхмерная сетка, показывающая структуру сегмента. Сегментацию проводят как для свитков, так и для уже физически развёрнутых фрагментов.
Ручное выделение сегмента на поперечном срезе для последующей автоматической экстраполяции
Поиск чернил. Полученная 3D-сетка сегмента (точнее, содержащиеся в ней вокселы) сама по себе не даёт достаточных данных о чернилах. Чтобы найти их, исследователи также обрабатывают вокселы, расположенные над и под сеткой. Они могут содержать информацию о чернилах, которые как просочились в сам папирус (исследование «вниз»), так и остались на его поверхности, создавая характерные узоры потрескивания (исследование «вверх»). Чтобы получить эти данные, исследователи при сегментации «захватывают» часть свитка, расположенную непосредственно около вокселов 3D-сетки. Полученный массив разворачивается и снова сохраняется в виде стека плоских «срезов», который называется «поверхностным объёмом».
Выделение «поверхностного объёма», который затем разрезается на отдельные слои
Для уже физически развёрнутых фрагментов используется выравнивание инфракрасной фотографии для выделения тёмных областей, где предположительно были чернила. По результатам этой работы создаётся бинарная «чёрно-белая» маска, максимально чётко показывающая такие участки папируса.
Далее фрагменты свитков с однозначно найденными чернилами используются как база для обучения нейросети. Затем с её помощью проводится сканирование срезов «поверхностного объёма», в ходе которого алгоритм ищет схожие участки, анализирует их плотность, степень проникновения «внутрь» свитка или расположение на его поверхности. В результате из полученных данных формируется бинарная маска исследуемых сегментов, отображающая расположение тёмных и светлых участков.
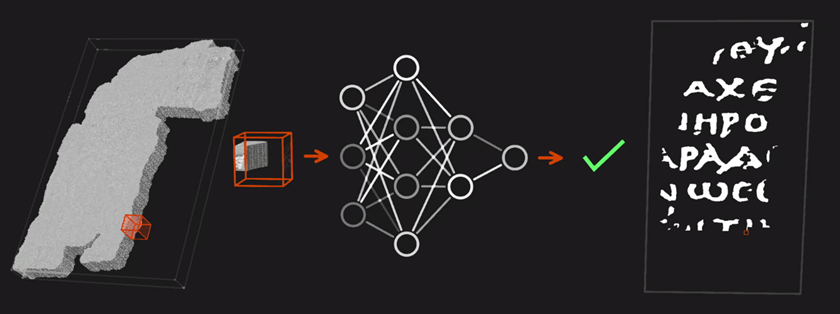
Так нейросеть ищет чернила в виртуальном сегменте папируса
На этом техническая часть исследования свитков заканчивается, и начинается, собственно, археологическая. Полученные изображения передаются команде папирологов, анализирующих их, вычленяя из совокупности тёмных участков те, которые можно интерпретировать как буквы греческого алфавита. Распознанный таким образом текст и составляет расшифровку свитков из Геркуланума.

Распознанное и улучшенное изображение расшифрованного фрагмента с 15 колонками текста
А что там с достоверностью?
С учётом ценности (точнее, бесценности) полученных расшифровок для науки и весомости вознаграждений, перед организаторами встал вопрос проверки полученных результатов.
Известно, что нейросети порой страдают «галлюцинациями»: если говорить упрощённо, это когда они «додумывают» то, чего нет на самом деле, основываясь на обучающих данных. Равно как и есть вероятность того, что кто-то из участников, позарившись на денежные призы, сознательно исказит результаты в свою пользу.
Чтобы исключить такие риски, организаторы используют следующие методы:
- Независимое воспроизведение результатов. Наработки участников, в том числе исходные коды алгоритмов, обучающие базы и т. д., хранятся в открытом доступе. Команда проверки с их помощью независимо запускает повторные исследования — если полученные результаты совпадают с результатами участников, то это говорит об их достоверности. Кроме того, организаторы специально дали всем участникам конкурса один и тот же отсканированный фрагмент свитка. Схожесть результатов от разных команд, использующих различные алгоритмы и методы поиска изображений, также свидетельствует в пользу достоверности.
- Малые окна ввода-вывода. Чем больше данных анализирует нейросеть, тем вероятнее, что она начнёт «галлюцинировать», особенно если она обучена распознавать символы и строить на их основе слова, фразы и предложения. Используемые в Vesuvius Challenge алгоритмы обучены лишь обнаруживать крошечные тёмные пятна на поверхности свитков. Они последовательно обрабатывают небольшие участки, анализируя их на предмет присутствия/отсутствия признаков чернил. Проще говоря, нейросети оперируют не символами и словами, а пятнами. А уже из этих пятен последовательно выстраиваются изображения.
Естественно, полученные с помощью нейросетей изображения в итоге анализируются профессиональными папирологами. Они интерпретируют найденные пятна как символы греческого алфавита, составляют из них текст, проверяют его на соответствие правилам семантики и синтактики древнегреческого языка, контексту эпохи, в культурном слое которой были обнаружены свитки, и т. д.
Что в итоге удалось прочесть?
Так как проект Vesuvius Challenge был основан только в 2023 году, у команды было достаточно мало времени для получения каких-либо обширных результатов. Пока исследовано всего около 2 000 знаков (15 столбиков) текста с одного из виртуально развёрнутых свитков. Это примерно 5% всей прокрутки документа. Но и организаторы конкурса, и специалисты в области изучения древних манускриптов единогласно говорят о прорыве: наконец-то разработана методология, позволяющая достоверно и быстро прочесть содержание без физического повреждения свитков.
Исследователи, принимающие участие в конкурсе, говорят, что каждый из этапов этого конвейера расшифровки можно усовершенствовать, и это приведёт к ещё более быстрым и точным результатам. Организаторы проекта рассчитывают, что уже в 2024 году будет расшифровано около 90% всей прокрутки свитка, который исследуется в данный момент.
Теперь — про содержание расшифрованного фрагмента. Оно представляет собой рассуждения о правильном понимании удовольствий. Это типичная тема для философов-эпикурейцев, к которым предположительно принадлежит автор свитка, работавший в погибшей библиотеке. В частности, в расшифрованном фрагменте он рассматривает вопрос, приносят ли блага, доступные в меньших количествах, больше удовольствия, чем те, которые представлены в изобилии. А ещё рассуждает о музыке, упоминает некоего Ксенофанта, критикует своих оппонентов за отрицание удовольствий или их неправильное понимание.
По содержанию и стилю расшифрованного фрагмента большинство исследователей склонно приписывать его авторство Филодему — философу-эпикурейцу, который в конце жизни как раз работал в Геркулануме. В пользу этого свидетельствуют и характерный «корявый» стиль повествования, и упоминание Ксенофанта, под которым, возможно, подразумевается флейтист, упоминаемый Филодемом в уже известной науке третьей части его трактата «О музыке».
Как ИИ ещё помогает в раскрытии тайн древности?
Расшифровка свитков из Геркуланума — не единственная попытка привлечь возможности машинного обучения к поиску древностей. С 2015 года в научных журналах наблюдается рост исследовательских работ, посвящённых применению ИИ в археологии.
Одна из наиболее популярных областей, где применяется искусственный интеллект, — поиск признаков древних архитектурных сооружений и других рукотворных артефактов (захоронений, курганов, ирригационных систем, транспортных сетей и т. д.) на спутниковых и аэроснимках земной поверхности. Например, в журнале Nature опубликована статья с результатами теста, проведённого в Месопотамии археологами из Болонского университета. Они обучили искусственный интеллект распознавать признаки искусственных объектов на базе уже зафиксированных археологических достопримечательностей. Затем они протестировали его в долине Масан в Ираке — результаты показали 80% совпадений с уже известными археологам сведениями об объектах в этом районе.
Аналогичным образом антропологу из Пенсильванского университета Дилану Дэвису нейросеть помогла идентифицировать возможные курганы коренного населения Северной Каролины и постройки на Мадагаскаре. С её помощью он со своей командой обработал тысячи трёхмерных изображений земной поверхности в этих регионах, сделанных дронами с LiDAR, на которых нейросеть нашла признаки рукотворных объектов. Точно так же исследователи из Каталонского института классической археологии реконструировали русла древних рек в Индии и Пакистане, где зародилась Индская цивилизация.
Другая область приложения ИИ в археологии — распознавание и восстановление изображений. С помощью нейросетей исследователи из университетов Гриффина и Дикина в Австралии смогли идентифицировать следы наскальных росписей в национальном парке Какаду. Они обучили искусственный интеллект на базе достоверно распознанных образцов древнего скального искусства, а затем дали ему проанализировать камни, на которых предполагается наличие подобных изображений в прошлом. Помимо непосредственного обнаружения таких рисунков, учёные планируют использовать ИИ для их классификации, извлечения мотивов и т. д.
Больших успехов ИИ помог достичь в расшифровке и восстановлении древних надписей. Например, разработанный командой DeepMind алгоритм Ithaca позволил не просто восстановить, но и определить происхождение и дату создания надписей на древнегреческом языке с разрозненных и повреждённых фрагментов керамики, папирусов и других материальных носителей. Этот инструмент в сочетании с трудом профессиональных эпиграфологов (исследователей надписей) позволил с точностью в 71% идентифицировать первоначальное местоположение текстов и сузить возможное время их создания до интервала менее 30 лет.
Из курьёзного: интернациональная группа исследователей использовала ИИ-инструмент CoproID для идентификации окаменевших экскрементов (копролитов) древних людей и собак. Зачем? Если у какого-нибудь исследователя возникнет вопрос, чем питались или болели наши предки, то ему нужно отделить найденные образцы человеческого и животного происхождения в местах совместного проживания.
Ещё ИИ помогает с датировкой и определением генетической принадлежности древних останков, определением химического состава артефактов (следовательно, происхождения и путей миграции), прогнозированием мест будущих раскопок, виртуальным моделированием экспедиций, воссозданием разрушенных архитектурных сооружений и т. д. Текущая тенденция использования систем машинного обучения и искусственного интеллекта показывает, что в будущем их применение в археологии будет только расти не только количественно, но и качественно.
