Как правильно внедрить Self-service-аналитику и для чего вам это. Кейс «Пятёрочки»
Делимся лайфхаком, который упростил жизнь продакт-менеджерам и сделал продукт удобнее для пользователей.

Мы работаем с приложением «Пятёрочки» на протяжении нескольких лет: в 2017 году разработали его, дальше развивали. В 2021 году запустили процесс доработок.
«Пятёрочка» — одна из крупнейших сетей продуктовых магазинов «у дома» в России. Основанная в 1998 году, сейчас объединяет 18 000 магазинов по стране. Входит в компанию X5 Group.
В плотной связке с командами «Пятёрочки» мы вели работы по двум направлениям —финансовые сервисы (Х5 Банк и Экспресс-Скан) и продуктовая аналитика. Как мы интегрировали финсервисы в приложение «Пятёрочки», можно почитать в кейсе. Отметим лишь, что под брендом Х5 Банка выпускаются цифровые Х5 Карты «Пятёрочки» и «Перекрёстка», объединяющие в себе карту лояльности и банковские услуги (оплата, перевод денег, возврат денег за покупки и др.). Данный функционал уже оценили более 200 000 пользователей.
В этой статье мы подробно остановимся на том, как развернуть необходимую инфраструктуру для внедрения Self-service-аналитики на стороне клиента, систематизировать и упростить работу с большими данными. И какие методики стоит взять на вооружение, чтобы сделать работу с данными проще и удобнее для всех сотрудников вашей компании.
Если и у вашего бизнеса есть массивная Backend-часть со складами, логистикой, доставкой, товарооборотом, офлайн-заказами, мы рекомендуем внимательно изучить опыт «Пятёрочки». Также сетап Self-service-аналитики а-ля «Пятёрочка» подходит в том случае, если:
вам нужна сквозная карта пользователя по всей системе;
у вас много продуктовых команд, которым нужно работать с данными;
вам нравится, что продакт-менеджеры могут работать с данными самостоятельно.
Задача
Первоначально задачей клиента было усиление инхаус-экспертизы по работе с аналитикой данных. Для этого «Пятёрочка» искала команды, которые имеют нужных специалистов и могут оперативно подключиться к работе.
AGIMA с такими задачами успешно работает уже много лет, мы умеем подбирать команды под конкретную задачу, быстро интегрироваться в процессы заказчика и сразу приступать к решению задач.
Менее чем за одну неделю мы погрузились в специфику проекта, разобрались в продукте, вместе с продуктовыми командами «Пятёрочки» приоритизировали задачи и приступили к работе.
Проект вели по гибкой методологии Scrum: работа короткими циклами (спринтами), постоянное присутствие заказчика в проекте, совместное формирование бэклога — всё это помогает минимизировать ошибки в итоговом продукте и добиваться результатов в четко обозначенные сроки.
Как мы внедряли Self-service-аналитику
Команда продуктовой аналитики AGIMA на разных этапах включала от 2 до 9 человек: аналитики, тестировщик, тимлид аналитиков, менеджер. В начале сотрудничества мы подключили одного аналитика и менеджера: собирали данные (приложение + веб) и оборачивали их в отчеты для заказчиков внутри компании.
На этом этапе стала понятна специфика проекта, которая помогла определить потенциальные точки роста. После согласования с заказчиком развитие продуктовой аналитики решили вести по направлению Self-service.
Self-service-аналитика или аналитика самообслуживания — это форма бизнес-аналитики, где специалисты могут самостоятельно выполнять запросы к нужным данным и генерировать необходимые отчеты без привлечения аналитиков.
У «Пятёрочки» большой объем данных, они регулярно требуются самым разным бизнес-пользователям для принятия решений, поэтому Self-service-аналитика поможет клиенту ускорить рутинные процессы с данными и высвободить аналитиков для решения более сложных стратегических задач.
В рамках задачи по внедрению Self-service-аналитики мы:
Выстроили иерархию метрик.
Развернули ELT-слой и внедрили BI-инструмент для визуализации данных.
Разработали дата-каталог.
Иерархия метрик
С мобильным приложением «Пятёрочки» работают 5–6 инхаус-команд, каждая отвечает за свой раздел. Такие продуктовые команды самостоятельно управляют фичами, трекингом, следят за аналитикой по своим разделам.
С каждой командой мы провели интервью. Узнали, какие у них КПИ, метрики, какие данные собирают. В результате обнаружили следующие пробелы:
командам не хватает некоторых данных, поэтому часть решений принимается наугад;
нет сквозного понимания, как действия каждой из команд влияют на соседей.
На основании собранной информации приняли решение выстроитьиерархию метрик.
Иерархия метрик — одна из методик работы с метриками, представляет собой древовидную структуру, во главе которой находится ключевая метрика продукта (North Star или метрика «полярной звезды»).
У «Пятёрочки» получилось две North Star-метрики — это оборот и MAU, за которые отвечает каждая из команд. Для подготовки иерархии мы:
определили, какие данные командам нужно отслеживать, чтобы принимать решения;
упорядочили показатели по важности и определили зависимости между ними;
расписали все эти метрики — от более общих к детализированным.
В нашем случае внутри продукта — приложения «Пятёрочка» — иерархия метрик делится по подпродуктам: финсервисы, ОС, лояльность, доставка и т. д. Это позволяет оценить, как метрики каждого из процессов влияют на конечную цель.
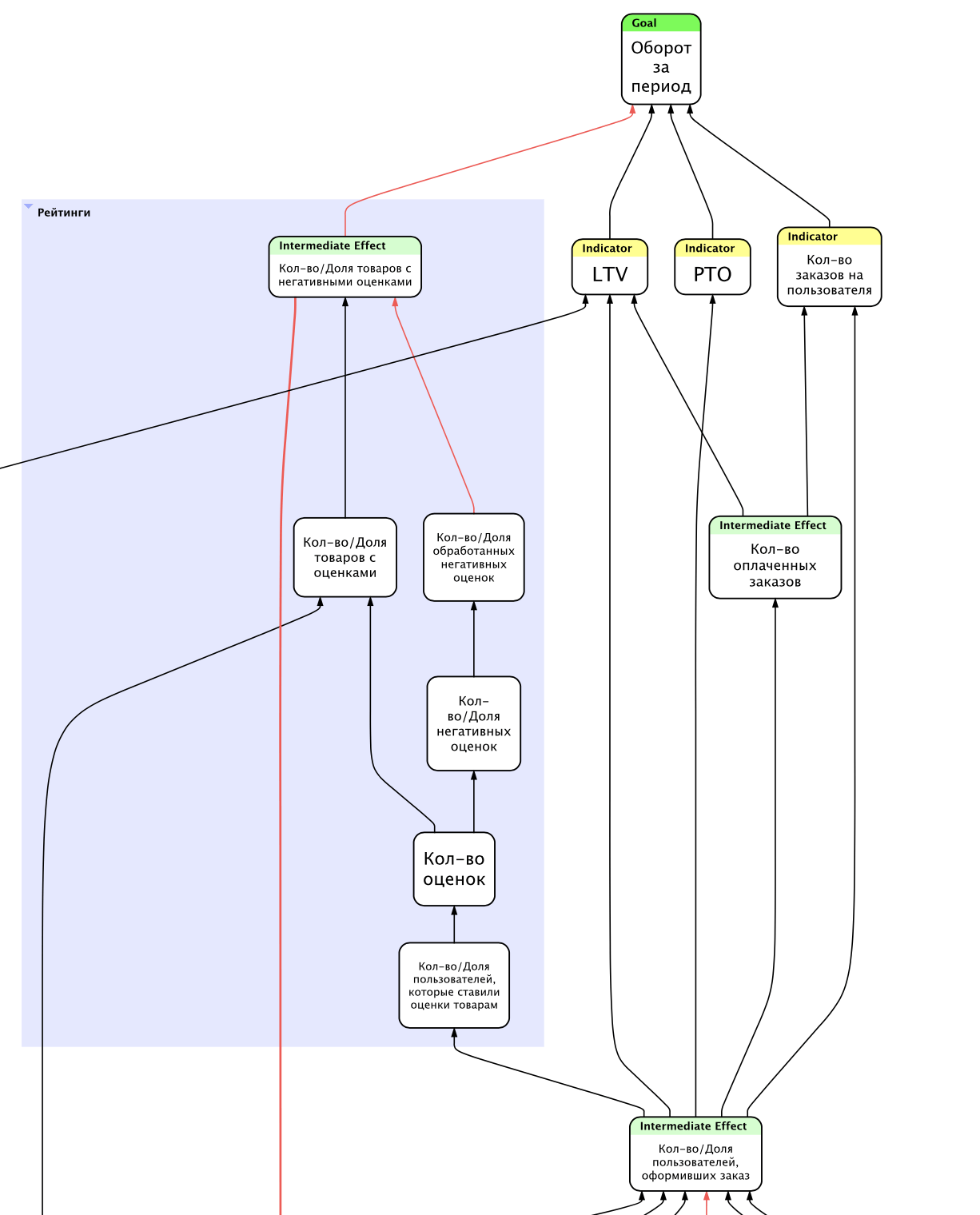 Фрагмент иерархии метрик для «Пятёрочки», на котором видно, как метрики одной из продуктовых команд влияют на North Star-метрику — оборот.
Фрагмент иерархии метрик для «Пятёрочки», на котором видно, как метрики одной из продуктовых команд влияют на North Star-метрику — оборот.
Тут вы можете спросить: зачем это всё? Ведь можно и без иерархии собирать данные и готовить нужные бизнесу отчеты. Да, конечно, можно! Но на наш взгляд, иерархия метрик — это более основательный подход, который помогает выстроить работу с данными в стратегическом разрезе, а не операционном. Бизнесу, особенно такому крупному, как «Пятёрочка», очень важно видеть, как метрики с низких уровней влияют на верхнеуровневые, самые важные.
Параллельно с работой над иерархией мы провели аудит всей разметки, которая была у заказчика. Оценили, что сделано качественно, что нет. Подготовили ТЗ на переразметку. Критичные моменты сразу исправили, чтобы лишние события не засоряли данные.
ELT-слой и Metabase
В основе Self-service-аналитики лежит простой в использовании BI-инструмент с базовыми аналитическими возможностями и удобной визуализацией данных. В нашем случае был выбран Metabase — бесплатный Open Source-инструмент, который имеет низкий порог входа для пользователя и закрывает следующие задачи клиента:
Таким образом, у продакт-менеджеров будет возможность изучить датасеты и самостоятельно вывести нужные метрики на свои дашборды, без участия аналитиков.
Чтобы запустить работу с BI-инструментом, мы развернули всю инфраструктуру ELT.
ELT (от англ. Extract — извлечение, Load — загрузка, Transform — преобразование) — это совокупность инструментов аналитики, которые позволяют получать данные из разных источников и сразу их визуализировать в BI-инструменте.
Отметим, что изначально все продуктовые команды работали напрямую с Google Analytics, из-за этого многие данные были неточны, потому что был семплинг. Для решения этой проблемы мы создаем единое хранилище данных (DWH). Оно позволит бизнес-пользователям работать со сквозной аналитикой — связать действия от клика на сайте до покупок в том числе в офлайне. С помощью Meltano преобразовываем данные из Google Analytics в аналитическую форму. И на основании этих данных делаем аналитический слой с подготовленными очищенными данными, которые реализуют те метрики, которые нужны продуктовым командам.
Технологический стек ELT-слоя выглядит так:
Экстракторы выгружают данные из Google Analytics UA (Web), AppsFlyer и API Firebase.
Загрузчики передают данные из вышеперечисленных источников в BigQuery.
Трансформеры настроены посредством BigQuery и SQL-запросов. Данные организованы по трем слоям:
Сырые данные.
BI-данные, где сырые данные были очищены и приведены в аналитический вид.
Данные из BI-слоя, в который смотрит визуализатор Metabase.

Все собранные данные Metabase оборачивает в наглядные графики, диаграммы, дашборды. В общей сложности отслеживаем почти 140 разных метрик, таких как:
Общее MAU (Monthly Active Users)/DAU (Daily Active Users) по всему приложению.
MAU/DAU различных разделов.
Количество активированных пластиковых карт в месяц.
Android/iOS-установки за месяц.
Пятёрочка — один из самых больших по объему данных проект, только уникальных событий 100 000, это очень много. С помощью Self-service-аналитики мы упростили работу с таким объемом данными, постарались снять нагрузку с аналитиков и ускорить получение необходимой информации для заказчиков данных.
Например, благодаря дашбордам мы максимально снизили количество Adhoc-ов (обращений за выгрузками, отчетами). В начале 2021 года их было до 5 в месяц, сейчас 1 раз в две-три недели.
Татьяна Гайнутдинова, Delivery Manager AGIMA
Теперь, когда аналитики реже готовят отчеты, у нас появились ресурсы на развитие стратегических задач:
Работаем над качеством данных, которые попадают в инструмент.
Работаем над RnD-задачами, связанными с развитием аналитики. Например, поиск данных, которые мы еще не получаем, но можем.
После запуска мы продолжаем поддерживать и развивать ELT-слой: подключаем больше данных и источников, больше дашбордов переводим в Metabase.
Дата-каталог
Как мы рассказали выше, у «Пятёрочки» очень много событий. Часть этих событий устаревала, и отчеты, в которые тянулись эти данные, уже не отражали истинной картины. Протестировать 100 000 событий вручную невозможно, поэтому мы реализовали дата-каталог, который для каждого события умеет рассчитывать его статус актуальности.
Например, если событие продолжает логироваться, то объем этого события в мобильном приложении остается неизменным — значит, у данного события статус «Актуальное», с ним всё хорошо. Когда мы понимаем, что паттерн логирования события изменился, событие перестало приходить — его статус «Устаревшее». Дальше по устаревшим событиям запускается процесс проверки, находим дашборды, в которых они используются, и разбираемся, что с ними делать: отключить, обновить, либо поменять устаревшее событие на актуальное.
Дата-каталог — это метаинформация на русском языке, которую можно совместить с данными бэкенда. Мы собрали метаинформацию обо всех событиях, для каждого сделали описание. Далее эта информация попадает в визуализатор и становится наглядной.

В качестве инструмента для дата-каталога мы использовали NocoDB — Nocode-платформу с открытым исходным кодом, которая позволяет превратить любую базу данных в электронную таблицу. С ее помощью мы актуализировали ручные данные, которые нам нужно было видеть в Metabase. Также на события можно добавлять метаразметку, указать, что часть событий относится к определенному бизнес-процессу и построить отчеты в разрезе по данному бизнес-процессу.
Например, в бизнес-процессе «Регистрация пользователя» могут быть сотни событий, для подготовки отчета нужно эту сотню событий вспомнить и перечислить. Когда же у вас есть дата-каталог и информация, что эти события относятся к такому-то бизнес-процессу, вы сможете запросить всё, что относится к этому бизнес-процессу.
Теперь пользователям не нужно тратить время и силы на поиск актуальных данных и «перевод» названий событий (особенно в больших отчетах), нужную информацию легко получить, прочитать и понять.
Документация
После того как выстроили иерархию метрик и запустили работу с данными на ее основе, мы задокументировали все основные моменты:
описали дашборды;
рассказали, как работает ELT-слой;
разработали регламенты постановки задач и взаимодействия команд.
Для всех используемых метрик составили таблицу, в которой указали, есть ли данные для конкретной метрики, где они, как ее считать. По тем метрикам, где был нужен вводный трекинг, реализовали его.
Все это позволило сотрудникам «Пятёрочки» быстро познакомиться с новыми правилами и четко организовать рабочий процесс.
Заключение
Это был интересный опыт для AGIMA. Мы постарались сделать счастливее еще одну компанию — выстроили для бизнеса «Пятёрочки» удобную Self-service-аналитику. Оптимизировали и упростили процесс сбора и анализа данных, сделав их более точными (иерархия метрик), наглядными (Metabase) и понятными (дата-каталог).
Таким образом сократили нагрузку на аналитиков по некоторым задачам более чем в 2 раза и помогли продакт-менеджерам повысить эффективность работы за счет более глубокого изучения данных.
