Как правильно переходить границу: кроссплатформенность в мобильном приложении
 Сегодня все больше приложений создается сразу для нескольких мобильных платформ, а приложения, созданные изначально для одной платформы, активно портируются на другие. Теоретически можно полностью писать приложение «с нуля» для каждой платформы (т.е. фактически «кроссплатформенной» оказывается только идея приложения). Но это означает, что трудозатраты на его разработку и развитие будут расти пропорционально количеству поддерживаемых платформ. Если же многоплатформенность изначально заложить в архитектуру приложения, то эти затраты (плюс, в особенности, затраты на поддержку) могут существенно сократиться. Вы разрабатываете общий кроссплатформенный код один раз — значит используете его на текущих (и будущих) платформах. Но в этом случае сразу возникает несколько взаимосвязанных вопросов: Должна ли быть граница между общим (кроссплатформенным) и нативным (специфичным для данной платформы) кодом?
Если да, то где и как провести эту границу?
Как сделать так, чтобы кроссплатформенный код было удобно использовать на всех платформах, как на тех, что надо поддержать сейчас, так и на тех, чья поддержка, вероятно, может потребоваться в будущем?
Конечно, ответы на эти вопросы зависят от конкретного приложения, предъявляемых к нему требований и накладываемых ограничений, поэтому универсальный ответ найти, по всей видимости, невозможно. В этой статье мы расскажем, как мы искали свои ответы на эти вопросы в процессе разработки мобильного клиента Parallels Access для iOS и Android, какие архитектурные решения были приняты и что в итоге получилось.Хочу сразу предупредить, что букв в этом посте много, но дробить тему на куски не хотелось. Поэтому запаситесь терпением.
Сегодня все больше приложений создается сразу для нескольких мобильных платформ, а приложения, созданные изначально для одной платформы, активно портируются на другие. Теоретически можно полностью писать приложение «с нуля» для каждой платформы (т.е. фактически «кроссплатформенной» оказывается только идея приложения). Но это означает, что трудозатраты на его разработку и развитие будут расти пропорционально количеству поддерживаемых платформ. Если же многоплатформенность изначально заложить в архитектуру приложения, то эти затраты (плюс, в особенности, затраты на поддержку) могут существенно сократиться. Вы разрабатываете общий кроссплатформенный код один раз — значит используете его на текущих (и будущих) платформах. Но в этом случае сразу возникает несколько взаимосвязанных вопросов: Должна ли быть граница между общим (кроссплатформенным) и нативным (специфичным для данной платформы) кодом?
Если да, то где и как провести эту границу?
Как сделать так, чтобы кроссплатформенный код было удобно использовать на всех платформах, как на тех, что надо поддержать сейчас, так и на тех, чья поддержка, вероятно, может потребоваться в будущем?
Конечно, ответы на эти вопросы зависят от конкретного приложения, предъявляемых к нему требований и накладываемых ограничений, поэтому универсальный ответ найти, по всей видимости, невозможно. В этой статье мы расскажем, как мы искали свои ответы на эти вопросы в процессе разработки мобильного клиента Parallels Access для iOS и Android, какие архитектурные решения были приняты и что в итоге получилось.Хочу сразу предупредить, что букв в этом посте много, но дробить тему на куски не хотелось. Поэтому запаситесь терпением.
Должна ли быть граница у кроссплатформенности? Сегодня существует много фреймворков (например, Xamarin, Cordova/PhoneGap, Titaniun, Qt, и другие), которые, в принципе, позволяют написать код один раз, а затем собирать его под разные платформы и получать на выходе приложения с более (или, в зависимости от возможностей фреймворка, менее) нативным для данной платформы UI и его «look-n-feel».Но если вам важно, чтобы приложение воспринималось и вело себя привычным для пользователей на данной платформе образом, то оно должно «играть по правилам», установленным Human Interface Guidelines этой платформы. А для восприятия «нативности» приложения пользователям крайне важны «мелочи» — вид и поведение управляющих элементов UI, вид и тайминги анимации переходов между элементами UI, реакции на жесты, расположение стандартных для данной платформы элементов управления и т.д. и т.п. Если вы полностью пишете приложение на одном из кроссплатформенных фреймворков, то нативность поведения вашего приложения будет зависеть от того, насколько качественно она реализована в этом фреймворке. И здесь, как это часто бывает, «дьявол кроется в деталях».
Где в фреймворке скрывается «дьявол»?1. В багах. Сколь хорош ни был бы фреймворк, в нем, к сожалению, неизбежно будут баги, в той или иной степени влияющие на «look-n-feel» и поведение приложения.2. В скорости. Скорость, с которой развиваются и меняются мобильные платформы, напрямую влияет на нативный «look-n-feel» и на скорость появления новых «фишек» на той или иной платформе.
В любом из этих случаев вы либо попадаете в зависимость от скорости выхода и качества обновлений фреймворка, либо (если у вас есть доступ к его исходникам) вынуждены будете сами исправлять баги или добавлять недостающие, но срочно необходимые вам фичи. Мы в полной мере столкнулись с этими проблемами во время разработки другого нашего решения — Parallels Desktop для Mac, в котором широко используется библиотека Qt (в свое время Parallels Desktop для Mac развивался на общей кодовой базе с Parallels Workstation for Windows/Linux). В некоторый момент времени мы осознали, что время и силы, затрачиваемые на поиск проблем, связанных с багами или особенностями реализации в Qt платформо-зависимого кода, их исправлением или поиском путей для обхода, стали слишком велики.
При разработке Parallels Access мы решили не наступать на эти же грабли во второй раз, поэтому для разработки UI решили использовать нативные для каждой платформы фреймворки.
Где и как провести границу между кроссплатформенным и нативным кодом?
 Итак, мы решили, что UI будет писаться нативно, т.е. на Objective-C (позже добавился Swift) для iOS и Java для Android. Но кроме собственно UI в Parallels Access, как и, наверно, в абсолютном большинстве приложений, есть достаточно большой пласт «бизнес-логики». В Parallels Access он отвечает за такие вещи, как авторизация пользователей, обмен данными с облачной инфраструктурой Parallels Access, организация и, по мере необходимости, восстановление шифрованных соединений с удаленными компьютерами пользователя, получение разнообразных данных, а также видео- и аудиопотоков от удаленного компьютера, отправка команд на запуск и активация приложений, пересылка на удаленный компьютер клавиатурных и «мышиных» действий и многое другое. Очевидно, что эта логика не зависит от платформы, и является естественным кандидатом на вынесение в кроссплатформенное «ядро» приложения.Выбор, на чем писать кроссплатформенное «ядро», был для нас прост: С++ плюс подмножество модулей Qt (QtCore + QtNetwork + QtXml + QtConcurrent). Почему все-таки Qt? На самом деле эта библиотека давно стала много бОльшим, чем просто средством для написания кроссплатформенного UI. Мета-объектная система Qt обеспечивает множество крайне удобных вещей. Например, получить «из коробки» средства для потокобезопасной коммуникации между объектами с помощью сигналов и слотов, добавить к объектам динамические свойства, в пару строк кода организовать динамическую фабрику объектов по строке с наименованием класса. Кроме того, он предоставляет очень удобный кроссплатформенный API для организации и работы с событийным циклом, потоками, сетью и многим другим.
Итак, мы решили, что UI будет писаться нативно, т.е. на Objective-C (позже добавился Swift) для iOS и Java для Android. Но кроме собственно UI в Parallels Access, как и, наверно, в абсолютном большинстве приложений, есть достаточно большой пласт «бизнес-логики». В Parallels Access он отвечает за такие вещи, как авторизация пользователей, обмен данными с облачной инфраструктурой Parallels Access, организация и, по мере необходимости, восстановление шифрованных соединений с удаленными компьютерами пользователя, получение разнообразных данных, а также видео- и аудиопотоков от удаленного компьютера, отправка команд на запуск и активация приложений, пересылка на удаленный компьютер клавиатурных и «мышиных» действий и многое другое. Очевидно, что эта логика не зависит от платформы, и является естественным кандидатом на вынесение в кроссплатформенное «ядро» приложения.Выбор, на чем писать кроссплатформенное «ядро», был для нас прост: С++ плюс подмножество модулей Qt (QtCore + QtNetwork + QtXml + QtConcurrent). Почему все-таки Qt? На самом деле эта библиотека давно стала много бОльшим, чем просто средством для написания кроссплатформенного UI. Мета-объектная система Qt обеспечивает множество крайне удобных вещей. Например, получить «из коробки» средства для потокобезопасной коммуникации между объектами с помощью сигналов и слотов, добавить к объектам динамические свойства, в пару строк кода организовать динамическую фабрику объектов по строке с наименованием класса. Кроме того, он предоставляет очень удобный кроссплатформенный API для организации и работы с событийным циклом, потоками, сетью и многим другим.
Вторая причина — историческая. Мы не хотели отказываться от использования тщательно обкатанной и оттестированной С++/Qt библиотеки Parallels Mobile SDK, которая была создана в процессе разработки нескольких других наших продуктов и на которую ушло несколько человеко-лет работы.
Как сделать так, чтобы кроссплатформенное ядро было удобно использовать из Objective-C и Java? Как использовать С++ библиотеку из Objective-C и Java? Решение «в лоб» — сделать Objective-C++ обертки над C++ классами для их использования в Objective-C и JNI-обертки для использования в Java. Но с обертками есть очевидная проблема: если API С++ библиотеки активно развивается, то и обертки будут требовать постоянного обновления. Понятно, что поддержание оберток в актуальном состоянии вручную — это рутинный, малопродуктивный и неизбежно ведущий к ошибкам путь. Разумно было бы просто генерить обертки и необходимый «boiler plate» код для вызова методов в C++ классах и доступа к данным. Но генератор опять же либо надо написать, либо можно попробовать использовать готовый (например, для Java можно было бы использовать SWIG. И с генераторами остается вероятность, что оборачиваемый C++ API окажется им «не по зубам» и потребуются пляски с бубнами, чтобы сгенерить корректно работающую обертку.Как же устранить такую проблему на корню, «by design»? Для этого мы задались вопросом, а что, собственно, представляют собой коммуникации между «платформенным» кодом на Objective-C/Java и кроссплатформенным кодом на C++? Глобально, с «высоты птичьего полета» — это некоторый набор данных (модельные объекты, параметры команд, параметры нотификаций) и обмен этими данными между Objective-C/Java и C++ по определенному протоколу.
Как описать данные так, чтобы их представление на C++, Objective-C, Java было бы гарантировано возможно и взаимно-конвертируемо? В качестве решения напрашивается использовать еще более базовый язык для описания структур данных, и генерировать из этого описания типы данных, «родные» для каждого из трех языков (С++, Objective-C, Java). Кроме генерации типов данных, нам была важна возможность их эффективной сериализации и десериализации в байтовые массивы (ниже мы расскажем, для чего). Для решения подобных задач существует ряд готовых вариантов, например:
Google Protocol Buffers которые, фактически, стали «языком данных» в Google Apache Thrift, который был изначально разработан в Facebook, отдан в Open Source в 2007, и сейчас находится «под крылом» Apache MessagePack и т.д. Нами был выбран Google Protocol Buffers, т.к. на тот момент (2012 г.) он несколько превосходил конкурентов по производительности, компактнее сериализовал данные, кроме того, был прекрасно документирован и снабжен примерами.Пример, как описываются данные в .proto файле:
message MouseEvent { optional sint32 x = 1; optional sint32 y = 2; optional sint32 z = 3; optional sint32 w = 4; repeated Button buttons = 5;
enum Button { LEFT = 1; RIGHT = 2; MIDDLE = 4; } } Сгенерированный код, конечно, будет много сложнее, т.к. кроме обычных геттеров и сеттеров, он содержит методы для сериализации и десериализации данных, вспомогательные методы для определения наличия полей в протобуфере, методы для объединения данных из двух протобуферов одного типа и т.д. Эти методы нам пригодятся в дальнейшем, но сейчас нам важно то, как код, использующий кроссплатформенное «ядро», и код в самом «ядре» могут записывать и читать данные. А выглядит это очень просто. Ниже в качестве примера приведен код для записи (в Objective-C и Java) и чтения данных (в С++) о мышином событии — нажатие левой кнопки мыши в точке с координатами (100, 100):
а) Создание и запись данных в объект в Objective-C:
RCMouseEvent *mouseEvent = [[[[[RCMouseEvent builder] setX:100] setY:100] addButtons: RCMouseEvent_ButtonLeft] build]; int size = [mouseEvent serializedSize]; void *buffer = malloc (size); memcpy (buffer, [[mouseEvent data] bytes], size); б) Создание и запись данных в объект в Java:
final MouseEvent mouseEvent = MouseEvent.newBuilder ().setX (100).setY (100).addButtons (MouseEvent.Button.LEFT).build (); final byte[] buffer = mouseEvent.toByteArray (); в) чтение данных в C++:
MouseEvent* mouseEvent = new MouseEvent (); mouseEvent→ParseFromArray (buffer, size); int32_t x = mouseEvent→x (); int32_t y = mouseEvent→y (); MouseEvent_Button button = mouseEvent→buttons ().Get (0); Но как передавать данные, записанные в протобуферы, на сторону C++ библиотеки и обратно, учитывая, что код, отправляющий запросы (Objective-C/Java) в кроссплатформенное «ядро» и код, непосредственно их обрабатывающий (C++), живут в разных потоках? Использование для этого стандартных методов синхронизации требует постоянного внимания к тому, где и как используются примитивы синхронизации, иначе легко получить код с неоптимальным перформансом, dead lock–ами или race-ми, трудноотлавливаемыми падениями при несонхронизированном чтении/записи данных. Возможно ли построить схему коммуникаций между Objective-C/Java и C++ так, чтобы и эту проблему решить «by design»? Здесь мы снова задались вопросом, а какие, собственно, виды коммуникаций нам нужны:
• Во-первых, API нашего кроссплатформенного «ядра» должен предоставлять методы для запроса модельных объектов (например, получить список всех зарегистрированных в данном аккаунте удаленных компьютеров).• Во-вторых, API «ядра» должен предоставлять возможность подписываться на уведомления о добавлении, удалении и изменении свойств объектов (например, об изменении состояния соединения с удаленным компьютером или о появлении нового окна какого-либо приложения на удаленном компьютере.)• В-третьих, в API должны быть методы как для исполнения команд самим «ядром» (например, установить соединение с данным удаленным компьютером, используя заданные login credentials), так и для отправки команд на удаленный компьютер (например, проэмулировать нажатие клавиш на клавиатуре на удаленном компьютере, когда пользователь набирает текст на мобильном устройстве). Результатом команды может оказаться изменение свойств или удаление модельного объекта (например, если это была команда на закрытие последнего окна приложения на удаленном компьютере).
Т.е. у нас получается всего два характерных паттерна коммуникаций:1. Запрос-ответ из Objective-C/Java в С++ для запроса/получения данных и для отправки команд с опциональным обработчиком завершения2. События-нотификации из С++ в Objective-C/Java (NB: Обработка аудио- и видеопотоков реализована отдельно и не рассматривается в этой статье).
Реализация этих паттернов хорошо ложится на механизм асинхронных сообщений. Но, как и в случае с описанием данных, нам нужен механизм асинхроной очереди, позволяющий обмениваться сообщениями между тремя языками (Objective-C, Java и С++), и, кроме того, легко интегрирующийся с нативными для каждой платформы потоками и событийными циклами.
Велосипед мы и здесь не стали изобретать, а использовали библиотеку ZeroMQ. Она предоставляет эффективный транспорт для обмена сообщениями между так называемыми «нодами», которыми могут выступать потоки в пределах одного процесса, процессы на одном компьютере, процессы на нескольких компьютерах, объединенных в сеть.
Использование в этой библиотеке zero-copy алгоритмов и lock-free модели для обмена сообщения делает ее удобным, эффективным и масштабируемым средством для передачи блоков данных между «нодами». При этом, в зависимости от взаимного расположения «нод», передача сообщений может осуществляться через shared memory (для потоков в пределах одного процесса), IPC-механизмы, TCP-сокеты и т.д., причем для использующего библиотеку кода это происходит прозрачно: достаточно при создании «сокетов», через которые коммуницируют «ноды», одной строкой задать «среду обмена», и все. Помимо «низкоуровневой» C++ библиотеки libzmq, для ZeroMQ cуществует ряд высокоуровневых binding-ов для большого количества языков, включая С (czmq), Java (jeromq), C# и т.д., позволяющих более компактно и эффективно использовать предоставляемые ZeroMQ паттерны для организации коммуникаций между «нодами». Сконфигурировав среду обмена, мы можем, например, создавать и передавать ZeroMQ-сообщения из Java (c помощью jeromq) и нативным же образом получать и читать их на стороне C++ (с помощью czmq).
ZeroMQ — это транспорт, который реализует диспетчеризацию сообщений между «нодами» согласно сконфигурированному паттерну коммуникации, но не накладывает ограничений на «полезную нагрузку». Именно здесь нам пригодится упомнинавшийся выше факт, что протобуферы — это не только средство для обобщенного описания структур данных, но и механизм для эффективной (как по времени, так и по требуемому объему памяти) сериализации и десериализации данных.
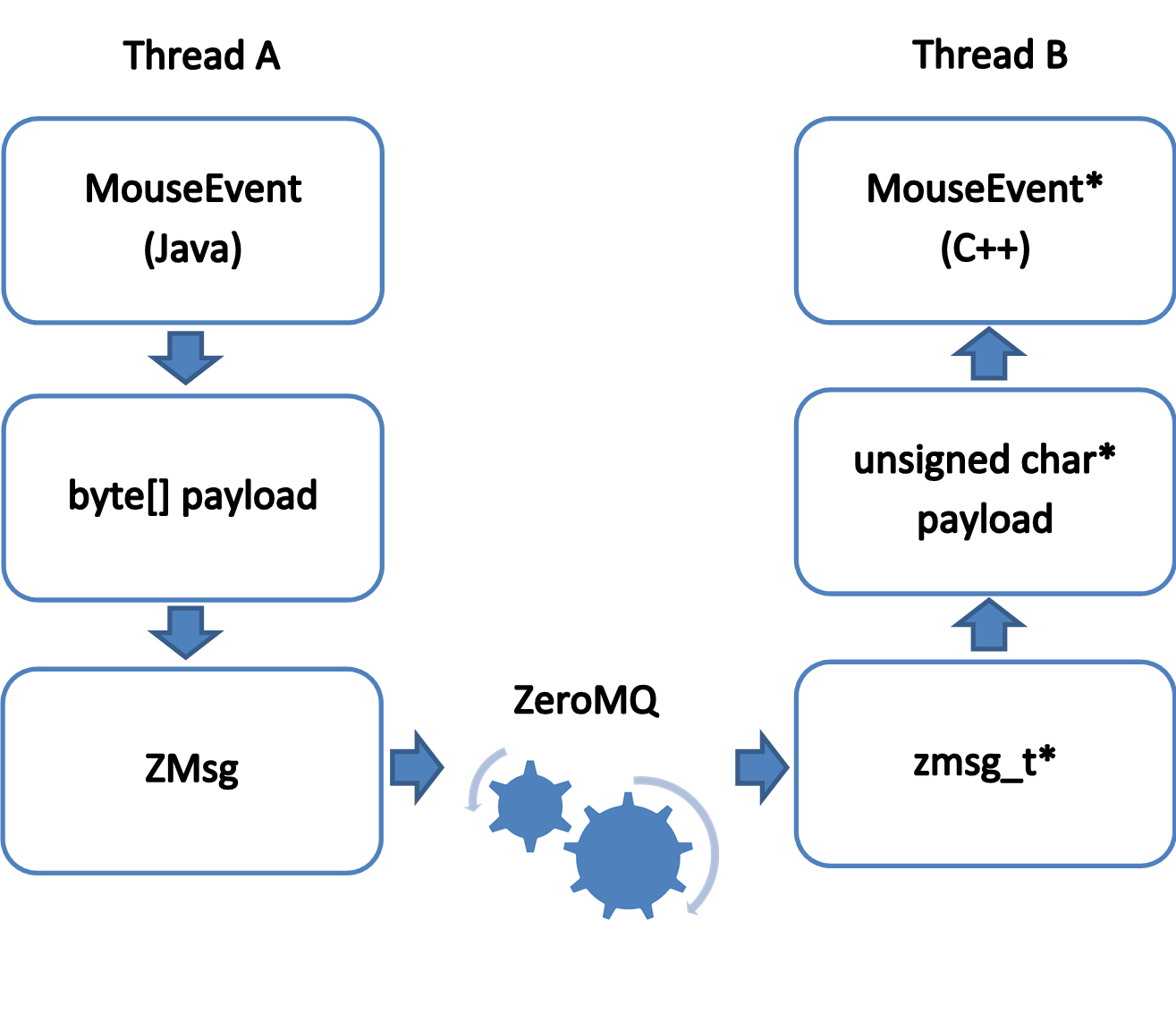 Таким образом, c помощью связки Google Protocol Buffers + ZeroMQ мы получили не зависящее от языка средство для описания данных и потокобезопасное средство для обмена данными и командами между «платформенным» и «кроссплатформенным» кодом.
Таким образом, c помощью связки Google Protocol Buffers + ZeroMQ мы получили не зависящее от языка средство для описания данных и потокобезопасное средство для обмена данными и командами между «платформенным» и «кроссплатформенным» кодом.
Использование этой связки:
Прозрачно для разработчиков на Objective-C, Java и С++. Работа с данными и операциями ведется полностью на «родном» языке Освобождает разработчиков клиентского UI-кода от необходимости помнить о синхронизации при обращении к данным. Сериализованный и десериализованный объект — суть разные объекты, общая память (при определенных условиях) нужна только при передаче через ZeroMQ. Заключение Подводя итоги, можно сказать следующее: во-первых, при изучении задачи всегда стоит «приподняться» над ней и увидеть общую картину того, что есть и что вы хотите получить в итоге — это иногда помогает упростить задачу. Во-вторых, не стоит изобретать велосипеды и незаслуженно забывать все то, что помогало эффективно работать в предыдущих решениях.А как вы писали свое кроссплатформенное приложение — с нуля для каждой платформы и сразу закладывали в архитектуру? Давайте обсудим плюсы и минусы в комментариях.
