Как повысить эффективность ИИ-рекомендаций преемников и карьерного диалога с сотрудниками?

По прогнозам ИТ-аналитиков и геополитиков, в 2023–2028 гг. самая серьёзная конкуренция в мире развернётся за данные и методы ИИ-аналитики. Уже сейчас можно наблюдать, как результаты ИИ-анализа становятся самым ценным активом, зачастую дороже топливных и валютных ресурсов. Аналитика позволяет решать массу важнейших бизнес-задач: понимать, совершит ли покупку клиент в интернет-магазине [1–4], отслеживать эффективность команд, находить преемников ключевым специалистам, диагностировать выгорание сотрудников на ранней стадии и предотвращать нежелательные увольнения при помощи проактивного карьерного диалога. Последнее для бизнеса особенно важно. Организации нанимают людей в условиях «рынка кандидата»: стоимость привлечения и аппетиты соискателей растут, а вовлечённость и эффективность сотрудников снижается.
Мы ищем эффективные методы «сканирования» положения дел в компании для последующего принятия решений: оценки рисков оттока, защиты ключевых позиций от нежелательных увольнений и максимального сохранения талантов в компании. И реализуем в цифровых инструментах. Расскажем, как HR-аналитики Сбера работают с данными о сотрудниках и какие алгоритмы мы применяем для обучения ИИ-моделей HR-платформы «Пульс».
Что такое «Пульс»?
Как и 95% HR-процессов банка, HR-аналитика Сбера реализована на единой платформе «Пульс». Это комплексное, иммерсивное цифровое решение, доступное всем сотрудникам банка. В нём можно оформлять документы, менять режим работы, узнавать прогноз по выплатам, заказывать справки, искать контакты коллег, обучаться, строить карьеру, управлять командой, эффективностью и временем. Платформа помогает ставить цели и связывать их с целями руководителей, обучаться и формировать личный карьерный путь.
Наличие единой системы —, а значит, и единой среды данных — позволило нам реализовать сквозную аналитику на основе искусственного интеллекта. В том числе оценивать риски оттока сотрудников и синтезировать рекомендации по карьерному диалогу и преемникам. Как анализ данных с помощью ИИ помогает нам решать эти задачи? Обо всём по порядку.
Задача №1: поиск преемника
При любом кадровом перемещении, будь то повышение, смена подразделения или уход сотрудника, на освободившуюся позицию нужен преемник. Это не обязательно должен быть сотрудник той же команды: специалист с подходящими навыками, компетенциями, лидерскими качествами и карьерными интересами может работать в смежной команде, в другом филиале и даже в другом регионе. Но в компаниях со штатом более 150 сотрудников HR не может знать всех лично, поэтому поиск преемников по всей компании — задача, с которой лучше всего справится искусственный интеллект.
Мы разработали ИИ-модель «Пульса», о которой подробно рассказали в статье о генераторе эмбеддингов. После внедрения мы предположили, что дополнительные источники данных позволят повысить эффективность модели. В частности, это могли быть сведения о том, какой функциональностью «Пульса» пользуются сотрудники и насколько активно. Для проверки гипотезы мы изучили развёрнутую статистику по пользователям (одна строчка — одно действие):
Дата | Приложение | Размер экрана | Элемент | Офис | Мобильный телефон | Wi-Fi | Местоположение |
2022–04–01 13:46:27 | coreui | 1800×899 | search | false | false | false | globalSearch |
2022–04–01 04:27:25 | sales-kpi | 1600×900 | home | Nan | Nan | Nan | homepage |
2022–04–01 05:19:24 | virtualTrain | 1280×1024 | corr | false | true | false | test |
В развёрнутом формате содержится множество данных: о посещённом сервисе, об устройстве, с которого пользователь зашёл на платформу, об использовании VPN и др. Но для машинного обучения нам потребуется не весь объём данных, а только базовые признаки, а именно — какими сервисами пользовался сотрудник. С этой точки зрения наиболее полно действие сотрудника описывают три параметра (триада):
Application — название сервиса;
Location — страница на сервисе;
Element — конкретный элемент на странице сервиса.
В среднем каждый сотрудник Сбера в месяц совершает порядка 30–40 действий на «Пульсе». Однако руководители и HR-специалисты пользуются платформой чаще линейных сотрудников: их показатели активности могут достигать тысячи действий в месяц. Общая статистика по банку за 1 месяц составляет около 9 млн действий.
Чтобы уменьшить объём данных и при этом учесть сотрудников, регулярно пользующихся «Пульсом», подсчитаем количество уникальных триад для каждого сотрудника, а также — сколько раз в месяц сотрудник пользовался каждой триадой. Ниже представлена гистограмма, отражающая количество уникальных триад. На основе этого исследования мы взяли 128 наиболее частотных триад в порядке возрастания частоты их использования. Почему именно 128? При увеличении размера уникальных триад объём набора данных возрастает в пропорции ~x2. Это повышает нагрузку на серверы и увеличивает длительность работы нейросетевых алгоритмов. При этом прирост качества от использования множества больше 128 триад незначителен.
А при сокращении происходит серьёзная потеря информации. Например, при использовании 64 триад деятельность более чем 40% сотрудников описывается не полностью. 5% сотрудников имели более 128 уникальных триад: такие случаи обрезались до 128 триад. Сотрудники, которые не добирали до 128 триад, заполнялись паддингами — специальными 0-векторами.

Рис. 1. Гистограмма количества триад сотрудников Сбера (в разные месяцы)
Мы получили набор из токенов размером (128, 3) для каждого сотрудника. Чтобы алгоритмы машинного обучения могли с этим работать, нужно перевести данные из категориального формата в цифровой.
Оценим количество уникальных вариаций каждой из составляющих триады: 56 Application, 789 Location и 1928 Element.
Существует несколько вариантов кодирования категориальных признаков: One-Hot Encoding, бинаризация, кодирование вектором произвольной длины (int/float) и т. п. Так как мы работаем с токенами, возможны методы кодирования типа Word2Vec, FastText, BPE. Мы выбрали бинаризацию, так как по сравнению с One-Hotона не принуждает нас работать с разреженной матрицей, и количество получаемых признаков гораздо меньше. Также после бинаризации мы в результате получаем сопоставимое количество нулей и единиц в закодированных элементах триады. Проведём бинаризацию.
Шаг 1. Создадим словари для каждого параметра триады Application, Location и Element по отдельности.
Шаг 2. Поставим каждому уникальному значению Application, Location и Element в соответствие число от 1 до размера словаря выбранного элемента триады, а затем переведем в двоичный формат.
Шаг 3. Получаем векторы следующей длины:
Application: 6;
Location: 10;
Element: 11.
Шаг 4. Не забудем применить паддинги, из которых получаются 0-вектора.
Шаг 5. Объединим полученные векторы для параметров триады и получим общий вектор длиной 27.
Теперь наш набор данных состоит из нулей и единиц и имеет размер (n*k, 128, 27), где n — количество рассматриваемых сотрудников, а k — количество месяцев в периоде, за который мы использовали данные.
Архитектура
Пришло время заняться архитектурой алгоритма. Важно, чтобы на выходе мы получали не матрицу размером (128, 27), а вектор. Для начала, мы решили попробовать необучаемые методы PCA и NNMF для матрицы (128, 7) (128×7), разложенной в вектор. Но эмбеддинги различной размерности (32, 64, 128), полученные с помощью этих методов, не дали прироста метрики решаемой задачи, поэтому мы перешли к исследованию других методов.
Для анализа пользовательских данных используются различные нейросетевые архитектуры, в том числе рекуррентные (GRU, SRU, LSTM, ClickGraph) [5–7], позволяющие работать не только с отдельными действиями, но и их последовательностями. Однако для формирования набора данных для решения задачи получения вектора необходим соответствующий таргет. Воспользуемся нейросетевой архитектурой Encoder-Decoder, которая в качестве таргета может принимать исходный набор, чтобы полученный вектор максимально сохранил исходную информацию. Почему именно Encoder-Decoder? Encoder предназначен для преобразования исходной информации (матрицы или вектора) в вектор заданной длины. Decoder же выполняет обратную функцию, восстанавливая из полученного с помощью Encoder вектора исходный формат данных. Таким образом, сравнивая оригинальные данные и полученный из Decoder дубликат, можно оценить, насколько хорошо свою функцию выполняет предложенная архитектура. Конечно, оценка качества будет косвенной. Поэтому сгенерированные в Encoder векторы обязательно нужно будет протестировать в реальной задаче, а именно — в поиске преемников.
Мы рассмотрели два варианта архитектуры Encoder-Decoder:
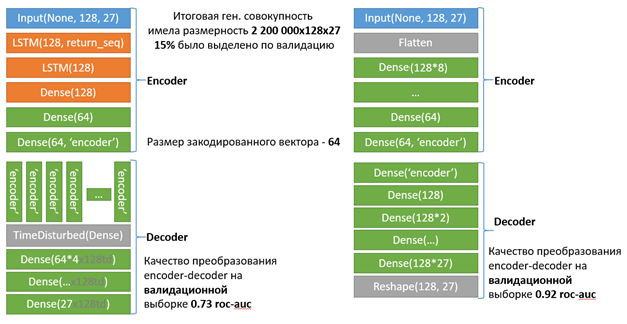
Слева — архитектура на основе полносвязных слоёв, качество преобразования на валидационной выборке roc-auc = 0,92 (напомним, наш набор данных состоит из нулей и единиц, поэтому мы правомерно можем использовать для оценки качества roc-auc). Это отражает работоспособность подхода.
Справа — более сложная архитектура: с применением слоёв LSTM, позволяющих оценить влияние как отдельных триад, так их последовательностей. Также здесь был использован специальный слой TimeDisturbed, позволяющий применить, например, слой Dense к исходному вектору N раз, чтобы получить больше информации из преобразованного в вектор оригинального набора данных. Подобная архитектура дала нам меньшее качество в Decoder: roc-auc = 0,73.
Качество модели мы оценили с помощью подхода на основе библиотеки pytorch-lifestream, предназначенной для анализа и преобразования потоковых данных. Эта библиотека хорошо зарекомендовала себя для работы со сложноструктурированными данными [8].
В результате мы получили три варианта векторов пользователя: Dense-векторы, LSTM-векторы и векторы pytorch-lifestream.
Протестируем эмбеддинги в задаче поиска преемника. Это задача ранжирования, где в исходной формулировке на каждого сотрудника приходится один преемник и все остальные не подходят (в нашем случае negative sample — 100 шт., этот параметр подобран эмпирически при составлении набора данных). Метрика качества для такой задачи — HitRate@1 и HitRate@10: попал ли искомый преемник в топ-1 или топ-10 рекомендаций модели. Посмотрим на качество, полученное с применением эмбеддингов и без них (oos — out-of-sample и oot — out-of-time наборах данных. Опущенные значения близки к 1, и их сравнение не несёт информационной ценности):
HitRate@10 oos, % | HitRate@10 oot, % | HitRate@1 oos, % | HitRate@1 oot, % | |
PyTLS embeds | 52,3 | 48 | 16,4 | 14 |
NN embeds | 47,7 | 46 | 8 | 8,9 |
LSTM embeds | 73,3 | 68 | 19,7 | 18 |
PyTLS +LSTM | 74,9 | 71 | 22,4 | 19 |
Original | - | - | 84,4 | 77 |
Original + NN embeds | - | - | 84,6 | 78,3 |
Original + LSTM | - | - | 85,9 | 79,7 |
Original + PyTLS | - | - | 84,9 | 78,5 |
При обучении и проверке только на эмбеддингах наилучший результат показал объединённый вектор LSTM и pytorch-lifestream. Если рассматривать присоединение векторов к уже имеющимся данным, то лучшим показателем здесь могут похвастаться LSTM — эмбеддинги на выборках out-of-time и out-of-sample. А архитектура на основе полносвязных слоёв переобучилась и дала меньшее качество (NN embs).
Итак, использование дополнительных данных позволило нам повысить эффективность модели поиска преемника. Вероятность подбора релевантного преемника для сотрудника в рекомендациях топ-1 возросла более чем на 1,3 п. п. относительно оригинальной модели.
Задача №2: рекомендация карьерного диалога
Рассмотрим следующую выбранную нами задачу — повышение эффективности моделей, которые рекомендуют карьерный диалог. Мы дали им и второе название: модели проактивного удержания сотрудников. Они предназначены для выделения сегмента сотрудников, которые наиболее склонны к уходу в ближайшем будущем. Определение таких сотрудников полезно для удержания талантов в компании и увеличения среднего стажа: проведения карьерного диалога, получения обратной связи от руководителя и выстраивания дальнейшего трека развития.
Для определения качества работы модели использовалась метрика roc-auc, а также precision@N и recall@N на топе-N прогнозов. Такие модели работают на большом количестве признаков разной природы, например:
социально‑демографический профиль;
учёт рабочего времени;
почтовые и календарные метрики;
оценки эффективности;
зарплатные метрики;
ситуация в команде (текучесть);
обучения и награды;
и многое другое.
Вся эта информация собирается различными модулями «Пульса» и может быть дополнена данными о пользовательской активности на платформе.
В ходе проработки этой гипотезы мы сформировали ключевые признаки, вносящие наибольший вклад в повышение эффективности ИИ-моделей рекомендаций карьерного диалога. Самые значимые числовые признаки:
количество событий, связанных с карьерой (просмотр внутренних вакансий, заказ карьерной консультации и пр.);
количество событий «Нажатие на строку поиска вакансий»;
количество событий «Отклик на определенную вакансию»;
количество событий за месяц, связанных с изменением карьерного статуса.
Также мы добавили признаки, характеризующие временны́е изменения и динамику перечисленных выше показателей. Например, средние значения за предыдущие N месяцев, или процент роста или убыли текущего значения показателя к N предыдущему.
Помимо числовых признаков сформировали эмбеддинг-представления наиболее популярных событий на основе top-128 триад. Для этого случая генерация эмбеддингов с помощью архитектуры Encoder-Decoder не дала существенного прироста качества, как и необучаемые методы Matrix Factorization. Поэтому мы решили воспользоваться NLP-методологиями, учитывающими семантическую близость, а именно — FastText, Word2Vec, BPE.
Переобучив модели удержания на признаках, которые объединены с полученными с помощью FastText эмбеддингами, мы увеличили roc-auc в среднем на 0,8 п. п. Предобученные векторные представления слов от FastText дообучали на массиве слов из статистики активности пользователей на платформе «Пульс». При этом мы формировали эмбеддинги действий (триад) так. Создали эмбеддинги для top-128 самых частых действий сотрудников за месяц:
Через FastText получили для каждого слова эмбеддинг размерностью 50 (подбирали эмпирически), нормализовали вектор (делили на корень квадратный из суммы квадратов элементов вектора).
Посчитали эмбеддинг предложения (одного действия) как среднее арифметическое нормализованных эмбеддингов слов. Полученное значение также нормализовали.
Посчитали эмбеддинг top-128 действий как среднее арифметическое нормализованных эмбеддингов предложений.
Получили представление top-128 наиболее частотных действий пользователя за каждый месяц в виде эмбеддинга размерностью 50. Таким образом мы сформировали дополнительные 50 признаков для моделей удержания. Это позволило повысить метрики качества рекомендаций карьерного диалога в «Пульсе» на 4 п. п.: с 0,67 до 0,71 roc-auc.
Выводы
Данные об использовании сервисов «Пульса» позволили нам повысить эффективность двух ИИ-моделей платформы:
С помощью эмбеддингов, полученных с помощью архитектуры Encoder‑Decoder, нам удалось повысить качество рекомендации преемников для руководителей более чем на 1,4 п. п. HitRate@1.
В моделях рекомендации карьерного диалога дополнительные признаки позволили повысить качество на 4 п. п. roc‑auc.
Мы доказали возможности подхода по решению других аналитических задач бизнеса с помощью HR-платформы «Пульс», например, в ранжировании внутренних вакансий для сотрудников или в улучшении рекомендаций обучающего контента.
Авторы: Р.В. Захаров, А.А. Щирова, Д.С. Горев и А.М. Марченков.
Список литературы
Shopper intent prediction from clickstream e‑commerce data with minimal browsing information
Predicting Online Shopping Behaviour from Clickstream Data using Deep Learning
The benefits and caveats of using clickstream data to understand student self-regulatory behaviors: opening the black box of learning processes
Key Event Analysis of Customer Behaviour Using Clickstream Data in Airline Market
Pattern2Vec: Representation of clickstream data sequences for learning user navigational behavior
ClickGraph: Web Page Embedding using Clickstream Data for Multitask Learning
Генератор эмбеддингов: как провести качественный анализ метрик сотрудников без прямого доступа к персональным данным
Мое первое серебро на Kaggle или как стабилизировать ML модель и подпрыгнуть на 700 мест вверх
