Как построить прогноз спроса и не потерять голову
 Какой ваш прогноз спроса?
Какой ваш прогноз спроса?
Всем привет! Представьте себе ситуацию: ваша уютная маленькая команда Data Science занимается прогнозированием спроса для пары десятков дарксторов с помощью какого-нибудь коробочного Prophet. И в один прекрасный день к ней приходит бизнес. Бизнес садится, закидывает ногу на ногу, закуривает сигару и говорит:
«Мы хотим максимально автоматизировать закупки. Нам нужно, чтобы вы умели строить прогноз по всем товарам, старым и новым, для всех дарксторов, старых и новых. А их будет много, их будут сотни, тысячи, миллионы. А ещё у нас будет миллион видов скидок и разные типы ценообразования, и ещё куча промо-механик и конкурсов интересных. Мы хотим, чтобы прогноз обязательно адекватно на всё это реагировал». © Типичный Бизнес
Хорошо, думаем мы, кажется, что это звучит нетрудно…
С этой задачи и начинается наша история о прогнозе спроса в Самокат. Меня зовут Мария Суртаева, я Data Scientist и расскажу о концепции прогноза спроса, его практических задачах и роли градиентного бустинга.
Для начала сделаю краткое отступление, почему мы вообще заговорили об этом. Самокат растёт и развивается, складов (дарксторов) и поставщиков появляется всё больше, растёт ассортимент. В таких условиях необходимость в оптимизации закупок становится постоянной. Напрашивающийся способ оптимизировать их работу — это автоматический заказ и прогнозирование спроса.

Когда бизнес пришёл к нам с задачей «максимальной автоматизации закупок», мы первым делом прикинули, сколько прогнозов нужно будет строить.
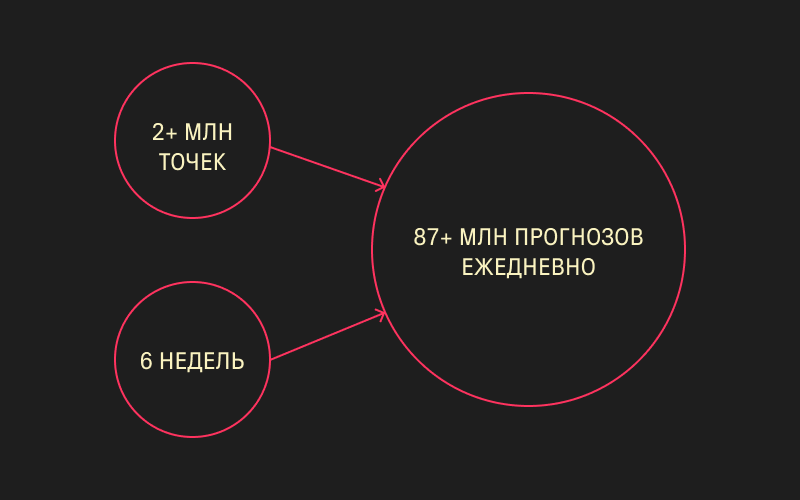
Если принять за прогнозную точку единицу спроса на товар, на одном дарксторе за один день, то нам нужно было строить прогноз по 2 миллионам точек с горизонтом прогнозирования шесть недель. Это более 87 миллионов прогнозов ежедневно. Понятно, что для того, чтобы справляться с этими объёмами, нужно было либо растить команду закупок теми же темпами, какими растёт сеть Самоката, либо выстраивать автоматизированный процесс.
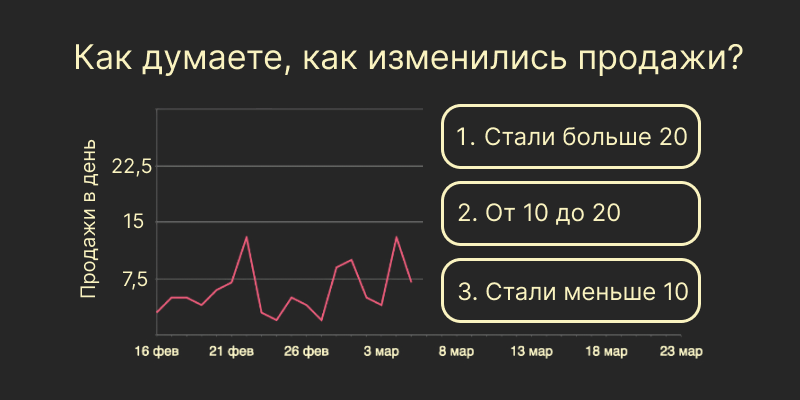
Перед тем, как мы перейдём к нашим трудностям и как мы их решали, у меня есть для вас небольшая задачка. Все персонажи вымышлены, совпадения случайны, поэтому это определённо не подсолнечное масло из заголовка.
Представим, что у нас есть временной ряд некоторого подсолнечного масла: он характеризует динамику продаж на одном дарксторе, и у него есть недельные средние значения. Вы — закупщик, и вам нужно предположить, сколько нужно закупить этого масла на следующие две недели, опираясь на историю продаж.
 На графике представлены восстановленные продажи, т.е. с учётом доступности товара (об этом речь пойдет далее); планируемые и исторические продажи являются регулярнымиОтвет
На графике представлены восстановленные продажи, т.е. с учётом доступности товара (об этом речь пойдет далее); планируемые и исторические продажи являются регулярнымиОтвет
На самом деле в следующие две недели произошла ситуация, похожая на ту, что приключилась с Берлиозом: что-то пошло не так.
Мы увидели «прекрасные» продажи — более 150 бутылей в день, которые, конечно, очень понравились наши маркетологам, и вообще не понравились нам.
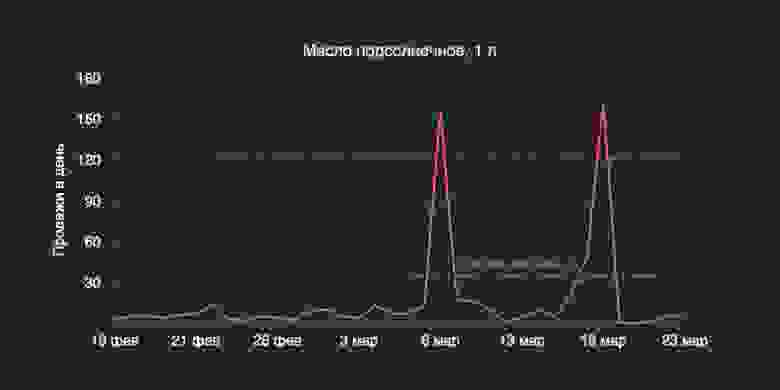 Раньше бутылки в принципе не продавались больше 15 штук в день
Раньше бутылки в принципе не продавались больше 15 штук в деньВот пример временного ряда, с которым приходится работать в реальном прогнозе спроса — от таких сюрпризов никто не застрахован.
Ниже речь пойдёт о временных рядах, так что на всякий случай вспомним основы.
Задача прогнозирования временных рядов
В зависимости от конкретной предметной области задача формулируется по-разному, но, как правило, звучит она так.
У вас есть последовательные точки процесса в определённые моменты времени t, вам нужно предсказать, где эти точки будут в последующие моменты времени, по возможности извлекая информацию из временной зависимости от t.
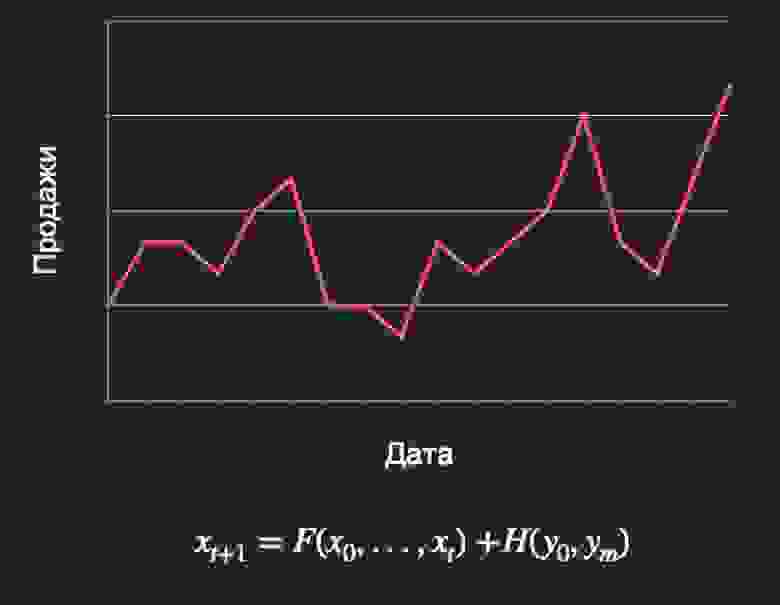
Базовые подходы к извлечению этой информации, как правило, строятся на разных скользящих статистиках и сглаживаниях (например, модель Хольта-Винтерса). Туда же можно отнести выявление авторегрессионных и сезонных компонент — семейство алгоритмов ARIMA, SARIMA, SARIMAX и другие.
Но мы хотим учитывать очень много разных факторов. Это достаточно однозначное пожелание бизнеса, мы не можем от него просто отмахнуться.
Можно посмотреть на Prophet, но как быть тогда с прогнозированием новых товаров и временных рядов без истории? Да и Prophet — не рекордсмен по скорости прогноза, простые тесты показались нам вечностью… У него есть прокачанный собрат, NeuralProphet, но и тут промах: нам нужно сохранять интерпретируемость для закупщиков и бизнеса.
Есть ещё семейство подходов MCMC, которые с некоторыми оговорками позволяют нам строить прогноз даже без исторических данных. Но будем честны, это очень тяжело поддерживать и масштабировать.
Через такие размышления мы пришли к методам классического машинного обучения, а именно: моделям градиентного бустинга. Они позволяют нам получать неплохой прогноз по большой сети, легко масштабироваться и учитывать много-много факторов. Вроде бы всё круто. На первый взгляд.

Бустинг: хороший, плохой, наш
Естественно, бустинг не может быть идеален, и у него есть ряд известных ограничений математической модели.
Мы не можем сразу получить хороший прогноз на коротком временном ряду или на отсутствующей истории (пока ещё нет).
Слабые экстраполирующие способности бустинга — это тоже проблема, потому что мы уже заранее знаем, что сеть и обороты будут расти и мы можем просто не успевать за растущим трендом.
Прерывистый временной ряд — это всегда проблемно для прогнозирования.
Всё это больно, но вот что смертельно. На самом деле бизнесу не нужен хороший прогноз по всей сети, бизнесу важен отличный прогноз по 5–10% самым маржинальным и самым важным для клиента товарам. От этой постановки меняется всё.
Это значит, что бизнесу не очень интересно, как классно мы опустили MAPE, или WAPE, или sMAPE или что угодно ещё по целой сети в Подмосковье. Бизнесу важно болеть за главного героя — за самый любимый продукт, за самый маржинальный и оборотистый товар. Потому что если его доступность или выручка упадёт на одном или двух дарксторов в Санкт-Петербурге, для бизнеса это будет критичнее, чем если мы просто не закупим целые категории в Наро-Фоминске (простите, ребята из Наро-Фоминска). Жестоко, но правдиво: товары не равнозначны с точки зрения ошибки модели.
Поэтому очень важно перестать смотреть на абстрактные цифры, которые позволяют нам сравнивать модели между собой, а начать задавать правильные вопросы к бизнес-процессам. Именно это позволит нам правильно найти золотую середину между перепрогнозом и недопрогнозом. Это позволит нам понять, какие цены ошибок нам нужно назначать, в каком направлении, для каких товаров. Возможно, понимание ответов приведёт нас к выводу о том, что нам нужна совсем другая базовая модель. Но мы этому выводу пока сопротивляемся, поэтому сейчас я буду рассказывать про четырёх злейших врагов прогноза спроса, если у вас в продакшене живёт градиентный бустинг.
Четыре всадника прогноза спроса
Новые товары
Первое очевидное препятствие на пути автоматизации — это прогнозирование того, о чём вы ещё ничего не знаете. Я начну с новых товаров, потому что это кейс, который в случае градиентного бустинга довольно просто нивелируется количеством и многообразием факторов в датасете. Важно добавить максимальное число факторов, которые не зависят от продаж товаров. Это категориальные признаки группы товаров: категории, подкатегории и их характеристики.
Также важно включать информацию о динамике продаж в категориях. Мы здесь исходим из предположения, что товары объединены в категории по некоторым общим свойствам, которые также могут отражать спрос на них. Поэтому если мы предполагаем, что доминант в этих категориях нет, то спрос на новый товар будет стремиться к некоторому обобщённому спросу на усреднённый товар в категории. В целом это даёт уже неплохое приближение в случае, если мы ещё не видели вообще никаких продаж.
Если ваш новый товар стартует с промо, это тоже обязательно нужно учесть в факторах, а также добавить информацию о ценовой категории, о средней цене в категориях и подкатегориях и о соотношениях между ними.
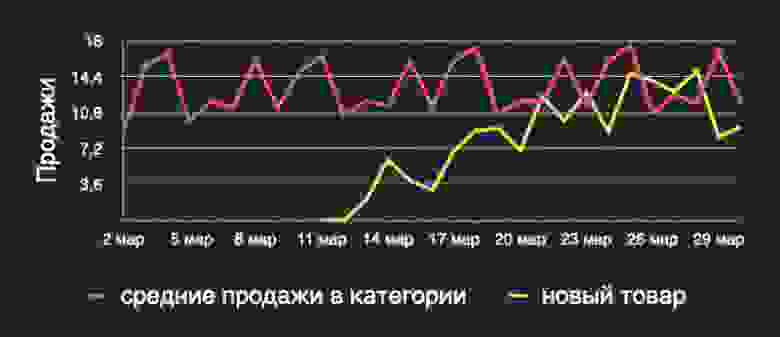
Всё это очень подробный способ сказать вашей обобщающей модели о том, что если у вас есть какой-то новый товар в категории «Йогурты», который выглядит как йогурт и который стоит как йогурт, скорее всего, его можно прогнозировать как некоторый усреднённый уже известный йогурт, который вы уже умеете прогнозировать.
Но что делать, если новых товаров много или вообще всё? Как быть, если даркстор только открывается, и вы ещё не знаете, как там вообще всё будет продаваться? На самом деле, здесь мы тоже используем подход с метаинформацией, с характеристиками даркстора, которые не зависят от продаж. В частности, мы можем использовать информацию о том, что это вообще за даркстор, как далеко он находится от центра, какая у него плотность населения, какая у него зона покрытия и так далее.
Эти характеристики позволяют вам построить многомерное пространство признаков дарксторов и натравить хотя бы наивный метод K ближайших соседей. Таким образом, вы можете найти K наиболее похожих дарксторов, и предположить, что спрос на них будет в целом походить на ваш новый даркстор. Тогда в качестве прогноза можно использовать статистики продаж за последний период на реальных самых похожих дарксторах. Иными словами, если вы не знаете, как будут продаваться все товары в новом спальнике в Казани, посмотрите на три других спальника в Казани. Это работает.
Ещё здесь нужно упомянуть о том, что если ассортимент товаров от даркстора к даркстору сильно варьируется, у вас, оказывается, много товаров, по которым у вас нет статистик, в том числе на наиболее похожих дарксторах. В этом случае можно использовать уже упомянутый мной подход с усреднением статистик в динамике категорий.
Ещё нюанс. На самом деле не каждое открытие — такое уж открытие. Очень часто бывает так, что новый даркстор открывается с переездом и отнимает часть зоны от уже существовавшего даркстора. Эта зона может занимать разный процент от территории к территории: от 1% до 99%. В этом случае это чисто дело техники хранения данных. Если вы заранее можете перенести часть заказов из общей зоны к обоим дарксторам, то есть создать дубликаты заказов для ещё не открывшегося дакрстора, то у вас уже имеется история продаж для этого переезда ещё до начала прогнозирования.
Таким образом, мы можем совместить прогноз, построенный на реальных данных с «общей» территории дарксторов, с усреднённым прогнозом от наиболее похожих соседей пропорционально долям этих территорий в зоне открывающегося даркстора. Этот «правдивый вклад» позволит дополнительно улучшить прогноз.
Заниженная доступность / уценка
Следующее препятствие — это злополучный баланс между перепрогнозированием и недопрогнозированием. Есть ловушка, в которую можно попасть, если смотреть только на сырые данные продаж. Предположим, что вы заказали мало товаров для даркстора, недопрогнозировали, и товар быстро закончился. Его, конечно, купили, но купили не так много, как могли бы. Модель увидела низкие продажи, построила на этом заниженные статистики и снова даёт низкий прогноз.
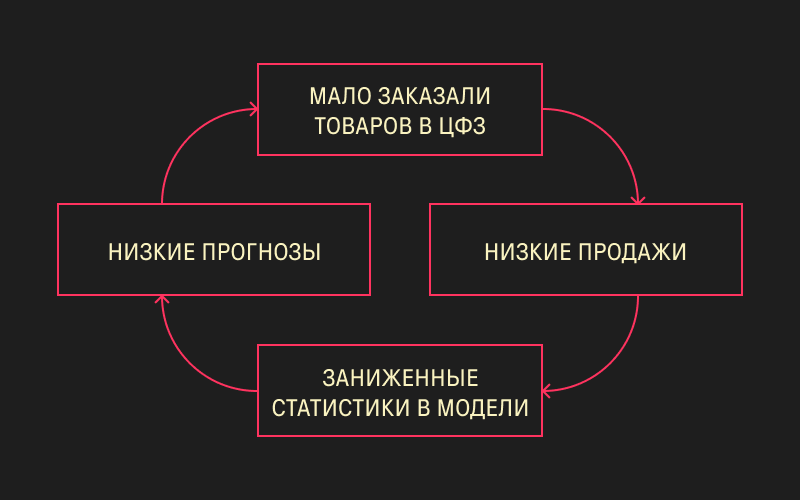 ЦФЗ — центр формирования заказов
ЦФЗ — центр формирования заказов
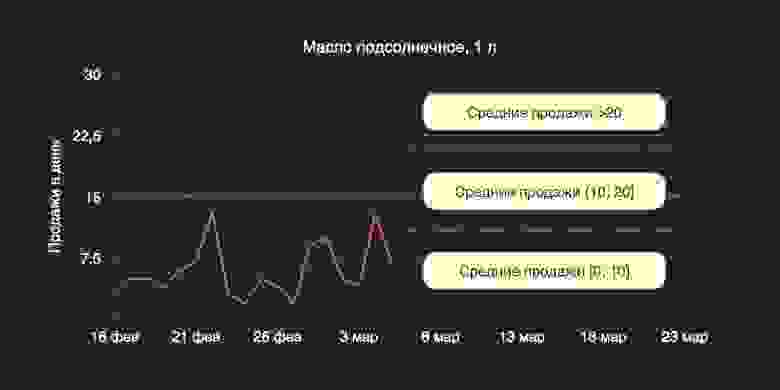
Возмутительно, но так. Это называется «ловушка заниженной доступности», и любой закупщик знает, как с этим бороться. Мы применяем к нашему таргету преобразование под волшебным названием «восстановление спроса с учётом доступности».
Доступность — это очень важный фактор, который присутствует в любом ритейле; он отражает реальную причину того, почему продажи товара низкие. Либо на товар существует в действительности низкий спрос, и товар просто никто не хочет; либо в дарксторе присутствует постоянный недостаток товара на полках. Это супер-нежелательная ситуация для бизнеса — ведь вы не максимизируете выручку, и необходимо искусственно увеличить эти продажи.
На картинке показываю, как преобразуется линия фактических продаж с учётом доступности. Понятно, что если вы хотите максимизировать выручку с даркстора, вам нужно стремиться к жёлтой линии, а не к розовой.
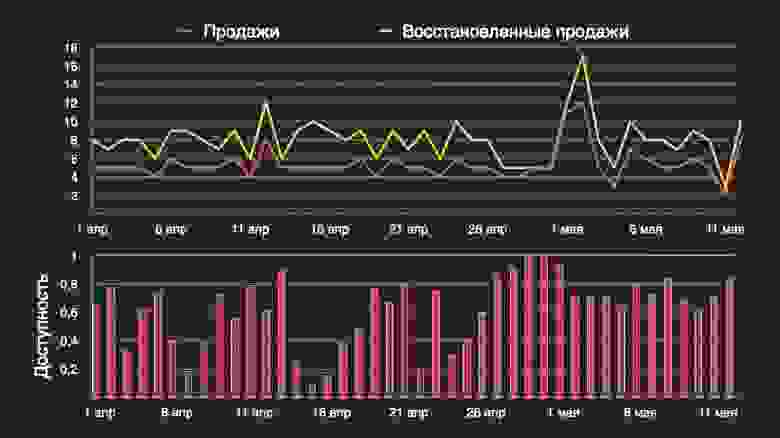
Преобразование нужно проводить аккуратно. Функция должна быть подобрана достаточно нежно, потому что вы не можете просто огульно завысить продажи, так как они получатся слишком большими — такими, как никогда не могли бы быть в реальности.
Поэтому не заигрываемся с преобразованием таргета и всегда добавляем информацию о том, насколько таргет изменён, насколько он достоверен в вашем датасете. Чтобы модель могла взвешивать, в какой мере это истинный ответ, а в какой мере — наши домыслы и целевые показатели бизнеса.
Есть также противоположная ловушка, с перепрогнозами. В Самокате есть система автоуценки: если вы заказали слишком много, и срок годности товаров скоро истекает, то назначаются большие скидки автоматически. Это то, что вы можете видеть в блоке «Распродажа» в нашем приложении — всегда с большими скидками на товар.
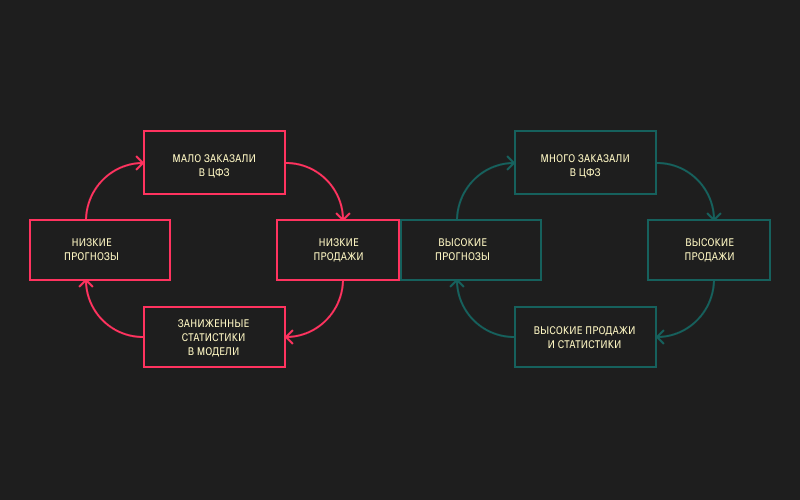
Люди любят большие скидки, люди покупают много товара. Но этот процесс не является нормальным, и товар продаётся в убыток бизнесу. Модель видит при этом большие продажи, строит завышенные статистики, и такая: «Классно, давайте я буду прогнозировать ещё больше, почему бы нет?»
Выход из этой ловушки получается чуть более техническим. Скорее всего у вас достаточно накопленных данных, чтобы не продумывать преобразование таргета в этом случае, просто исключайте его. В системе хранения данных обязательно должен быть однозначный источник скидки, который отражает, насколько эта продажа соответствует запланированному процессу. Важно показывать модели те данные и такое поведение, к которым вы стремитесь, то есть доступность порядка 90–100% и исключительно запланированные промоакции, никакой самодеятельности.
Плохая экстраполяция и нечувствительность к трендам
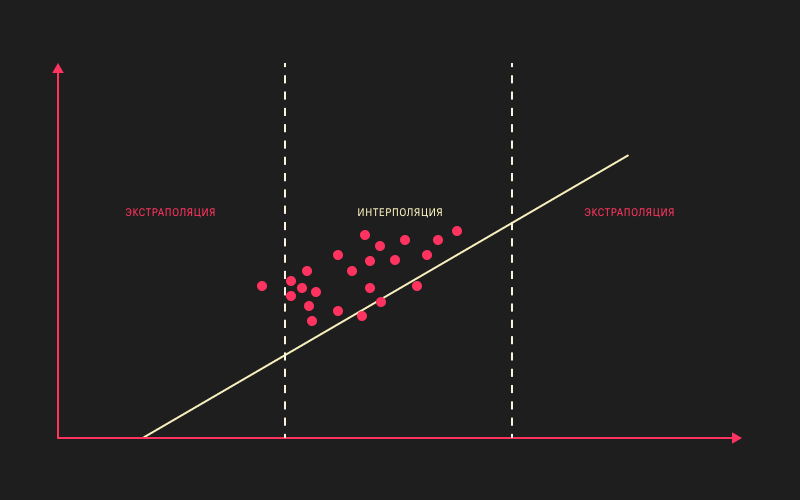
Другой частый камень в огород градиентного бустинга — это слабые экстраполирующие свойства. На самом деле бо́льшая часть моделей машинного обучения построена таким образом, чтобы обобщать и интерполировать, а не экстраполировать; с экстраполяцией у них довольно плохо. В частности, если мы рассматриваем деревья решений, то кусочно-линейное приближение с постоянным ответом в областях разбиения нам закономерно не помогает приближаться к ответу вне примеров обучающей выборки. В случае с прогнозом спроса, когда у вас таргет неотрицательный, это ещё значит, что ваша модель будет склонна недопрогнозировать.
На практике существует три способа этого избежать.
Первый способ — это бизнес-решение и замечание к логистике. У вас всегда должны быть страховые запасы. Они позволяют вам не сильно обращать внимание на ошибку с товарами с низким оборотом — всегда есть какой-то минимальный запас, который хранится на дарксторе. Но при этом в случае со скоропортящимися товарами и высокооборотистыми товарами страховые запасы довольно сильно влияют на доступность и на другие бизнес-показатели. Поэтому вам нужно как можно глубже интегрировать эти данные в прогноз скоропорта.
Второй способ — несимметричные лоссы. Если вы будете штрафовать модель за недопрогноз больше (потому что бизнесу, как правило, недопрогнозы обходятся дороже, чем перепрогнозы), то модель будет больше обращать внимания на недопрогнозы — результаты улучшатся, бизнес удовлетворится.
Третий способ, на мой взгляд, самый эффективный — это дополнительный модуль управления уже готовым прогнозом. О нём поговорим подробнее.
Мы построили модуль статистических корректировок, чтобы напрямую влиять на экстраполирующие свойства градиентного бустинга и подталкивать нашу модель. Статистический блок смотрит на последние сформированные прогнозы, на исторические продажи за последний период и строит распределение ошибок.
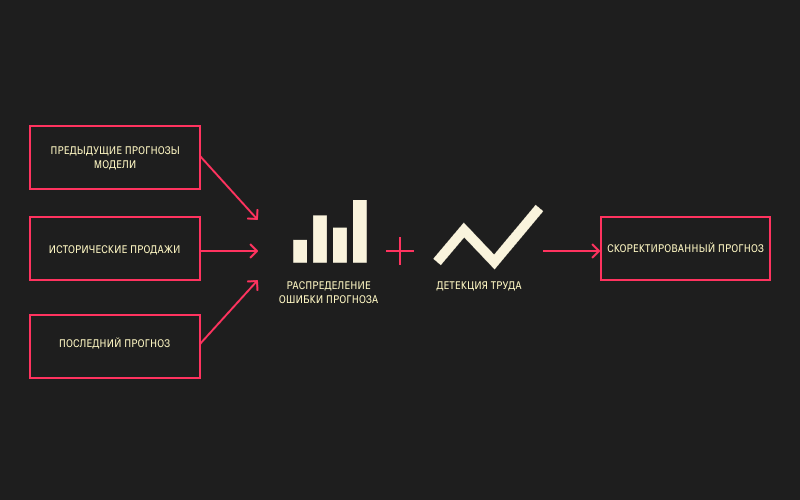
Если мы видим, что ошибки сохраняют знак на протяжении длительного времени, если они увеличиваются в абсолюте, то мы добавляем смещение. Смещение, естественно, вычислено в зависимости от направления ошибки и в зависимости от её величины. Бонусом у нас идёт детектор тренда. Это могут быть разные математические инструменты его обнаружения, но в нашем случае довольно неплохо справляются базовые линейные подходы. Если мы видим тренд, мы также можем добавить смещение. В итоге у нас получается более корректный прогноз и ускоренная реакция модели на изменение поведения временного ряда. Примеры таких прогнозов приведены ниже.
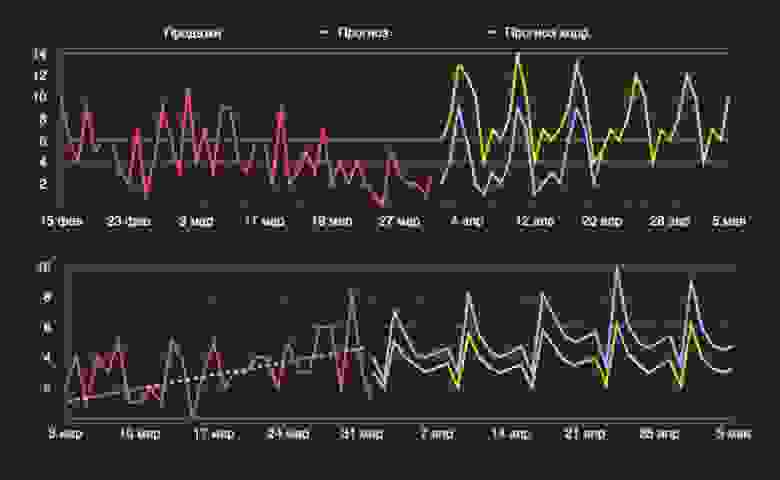 Если у нас сохраняется ошибка, постоянная по направлению, или детектирован тренд (ряд снизу), то мы добавляем смещение к готовому прогнозу. На примере с перепрогнозом (сверху) видно, что спрос снижается, в то время как исходный прогноз остаётся на прежнем уровне, корректировки улучшают ситуацию
Если у нас сохраняется ошибка, постоянная по направлению, или детектирован тренд (ряд снизу), то мы добавляем смещение к готовому прогнозу. На примере с перепрогнозом (сверху) видно, что спрос снижается, в то время как исходный прогноз остаётся на прежнем уровне, корректировки улучшают ситуацию
И что мы в итоге имеем? У нас есть бустинг, который учится на хорошем таргете — преобразованном или исключённом. У нас есть дополнительный модуль, добавляющий смещение к нашему прогнозу, чтобы модель реагировала оперативнее и лучше экстраполировала. У нас также есть дополнительный блок с kNN, позволяющий получать прогнозы на новых дарксторах.
В целом, эта система уже даёт хороший прогноз по большей части сети. Поэтому сейчас самое время встретиться с нашим главным злодеем — с препятствиями, которые не позволяют нам отлично предсказывать вообще всё.
Выбросы и шумы
Это те пики продаж при невероятном маркетинге из примера в начале статьи, любые ошибки и внешние обстоятельства. Всё то, что отличает модели машинного обучения от ясновидящих, кроме того, что машинное обучение не берёт денег за прогноз.
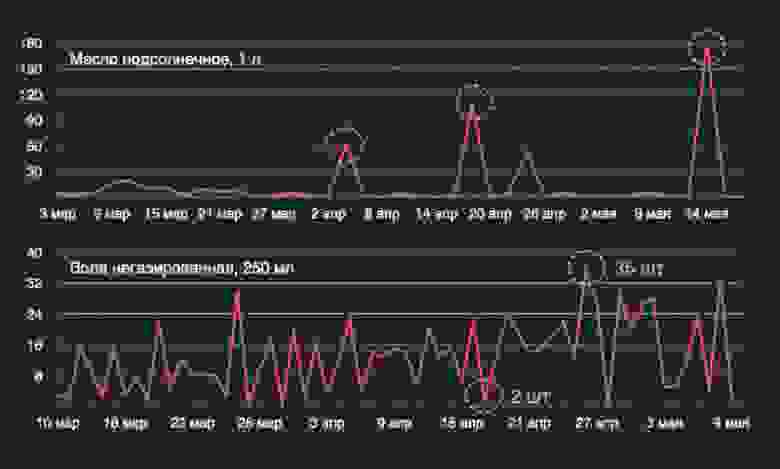 Здесь уже знакомый нам временной ряд с выбросами: при обычных колебаниях продаж в пределах 20 штук ежедневно у нас внезапно появляются выбросы больше 60, и даже больше 150 штук в день. В нижнем ряду — пример волатильного временного ряда
Здесь уже знакомый нам временной ряд с выбросами: при обычных колебаниях продаж в пределах 20 штук ежедневно у нас внезапно появляются выбросы больше 60, и даже больше 150 штук в день. В нижнем ряду — пример волатильного временного ряда
Помимо зашумлённых рядов есть суперволатильные временные ряды, где подневные продажи варьируются от 2 до 35 штук, что тоже довольно неприятно.
У нас есть мистические исчезновения товара из продаж на нехарактерный период. Причиной может служить почти что угодно: внезапный вывод товара из ассортимента, разрыв отношений с поставщиком, массовое разочарование в чипсиках и так далее, нужное подчеркнуть.
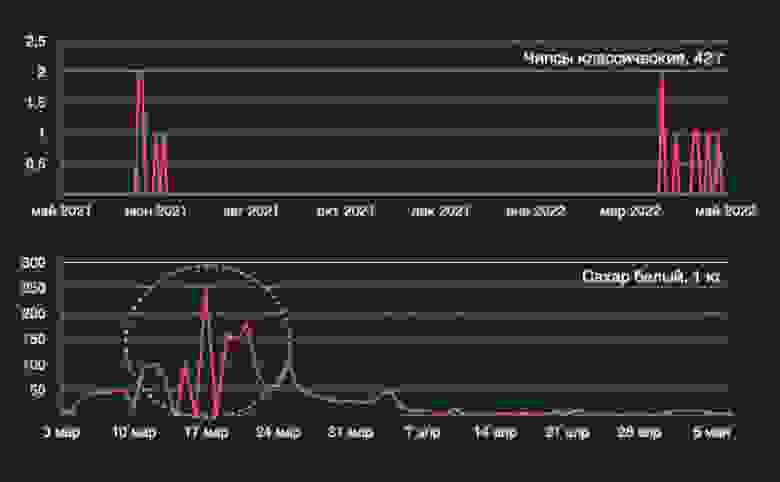 В верхнем ряду временное прекращение поставок делает характер спроса гораздо более прерывистым, чем это есть в действительности — получаем сильный недопрогноз. Внизу пример того, что в юридической литературе называется внешними обстоятельствами непреодолимой силы
В верхнем ряду временное прекращение поставок делает характер спроса гораздо более прерывистым, чем это есть в действительности — получаем сильный недопрогноз. Внизу пример того, что в юридической литературе называется внешними обстоятельствами непреодолимой силы
Я не знаю, есть ли серебряные пули от всех этих корнер-кейсов. Скорее всего, решение каждой этой проблемы потребует от вас построения системы, по сложности и громоздкости сравнимой со всей остальной архитектурой прогноза. Но вот к каким мыслям это приводит:
Здорово, если у вас есть детектор аномалий, и вы можете скрывать вот эти ужасы от модели. В этом случае временная дестабилизация временного ряда не попортит все последующие прогнозы.
Хорошо, если в модель зашиты разные виды сглаживания — либо исторических продаж, либо прогнозов, какие угодно. Вы делаете ставку на сходимость сумм продаж и прогнозов в среднем и можете прогнозировать волатильные ряды с помощью агрегаций.
Прекрасно, если у вас есть механизм исключения подозрительных пробелов из данных. В нашем случае работает исключение данных с нулевой доступностью для построения статистик.
Превосходно, если у вас есть механизм учёта сезонности товара, и резкое повышение спроса или снижение спроса не будет для вас сюрпризом.
К этому моменту мы уже перечислили то, что нам пришлось провернуть для того, чтобы градиентный бустинг более или менее хорошо работал у нас в проде. Самое время подсчитать количество соломы, которое оказалось раскиданным в результате того, что в самом начале мы (возможно) немножечко неправильно приоритизировали пожелания бизнеса.
Как жить дальше
Нам хотелось, чтобы всё было так: у нас есть данные, мы отдаём данные в модель, модель выдаёт нам прекрасный прогноз всегда и везде. Супер!
Но на практике мы быстро поняли, что нам нужно очень много данных, очень разных, из разных источников, а ещё логика преобразования таргета.
Затем у нас добавился модуль с кластерным анализом и с kNN, чтобы получать прогноз по новым товарам и для новых дарксторов.
Далее мы решили, что наш прогноз всё ещё недостаточно идеален, и добавили модуль статистических корректировок, чтобы подталкивать его в нужном направлении изменения спроса.
Потом у нас появился ещё детектор тренда, потому что, а почему нет — чтобы корректировать прогноз ещё лучше.
И даже это тоже не всё: есть ещё много модулей, описание которых уже никак не укладывается в рамки данной статьи.
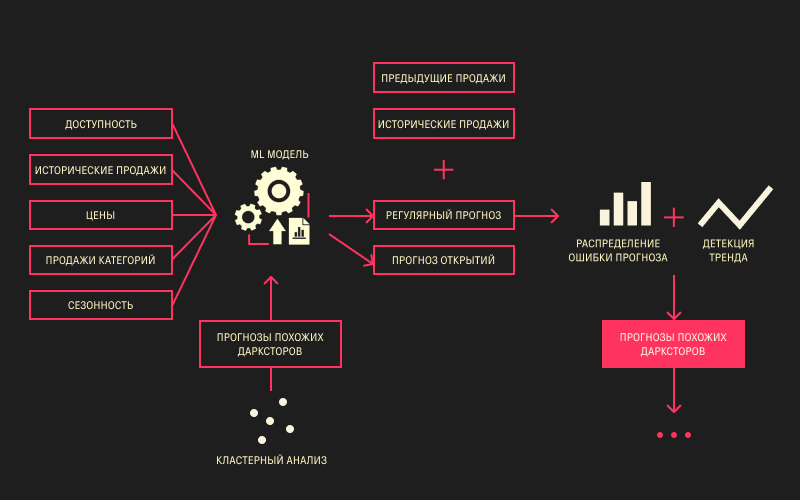
И вот мы здесь. Сидим, смотрим на разрастающуюся схему архитектуры прогноза и доработок с чётким осознанием того, что проект призван решать гораздо больше задач, чем просто прогнозирование числа проданных товаров на дарксторах. Этот факт может остаться незамеченным при стандартной методике подсчёта ошибок прогноза, но достаточно сильно при этом влияет на бизнес-показатели и сказывается на бизнесе.
От наивного прогноза спроса к интеллектуальной системе прогнозирования за четыре шага
Итак, что мы вынесли из этой истории? Очень важно изначально понимать суть бизнес-задачи. Это позволит от исходной наивной схемы, где есть только данные, модель и прогноз с простым установка «прогнозируем все товары на всех дарксторах», прийти к более детальной задаче о построении полноценной интеллектуальной системы.
Чтобы эта система максимизировала выручку, нужно пройти четыре этапа:
Хорошо отфильтровать данные. Фильтрация и препроцессинг — это то, с чем нельзя переборщить.
Построить упрощённые подходы для новинок. Простой подход в условиях отсутствия данных — скорее всего, лучший подход.
Восстановить спрос, преобразовав таргет там, где это необходимо.
Помочь деревьям экстраполировать и улавливать тренды. Нам нужно подталкивать нашу модель там, где она недотягивает.
Только таким образом мы и можем растить бизнес-метрики –, а значит, прогнозировать спрос, не теряя головы.
P.S.: Костыли вокруг бустинга — увлекательное дело, но не единственное, чем мы занимаемся в команде Data Science.
Ещё мы моделируем промо-механики и эластичность по различным факторам, изучаем эффекты перетекания спроса и каннибализации. Исследуем, как наша система прогноза спроса взаимодействует с другими продуктами из Data Science: с персонализацией, рекомендациями, минимальными чеками и всем-всем-всем.
Напишите в комментах, если вам хотелось бы почитать о каких-нибудь из этих тем?
