Как полюбить машинное обучение и перестать страдать

Библиотеке numpy чужды любые человеческие чувства
Я взяла курс Машинного обучения по своей воле. На первом занятии нам сказали, что годового курса матана, а также базового понимания Python будет достаточно для нормального освоения курса. Звучит прекрасно! До тех пор, пока не приходит осознание того, что программа у разных вузов — разная. Во фразу «годовой курс матана» нечаянно попали линейная алгебра, дискретная математика, асимптотический анализ, и так далее.
О том, что такое «базовое понимание Python», я также сильно заблуждалась. «Это же один из самых простых языков!» — утверждали все вокруг. Читать хороший код можно как художественную литературу. И я верила своим знакомым, потому что, ничего не написав на Python до этого, я сама часто предпочитала читать на нем реализацию разных алгоритмов. Ведь он так лаконичен и отлично передает суть.
Проблема лишь в том, что читать код и писать самому — это разные задачи. Сразу начать писать хороший код на Python — это большая проблема (простите за капитанство).
После долгих страданий и попыток освоить первый в моей жизни динамический интерпретируемый язык, у меня наступил момент счастья и гордости. Как вы уже догадались, момент был недолгим. Почти сразу ко мне пришло осознание, что этого недостаточно. Научившись хоть как-то писать на питоне, необходимо переучиваться, чтобы грамотно использовать библиотеки машинного обучения. Я слышала, что у многих это не вызывает особых трудностей. Кто-то может даже не заметить этой стадии. Но мне было очень тяжело сперва в быстром темпе освоить стандартные коллекции и полюбить их всей душой, а затем узнать, что у библиотек ML свое мнение на этот счет. Им совершенно неинтересно, как удобны и просты в использовании милые питонячьи списки и словари. Библиотеке numpy чужды любые человеческие чувства.
Как вы уже поняли, курс давался мне катастрофически сложно. Я с трудом смогла сдать первую часть курса, получив оценку «удовлетворительно». Курс состоял из 2 частей и был рассчитан на год, но я решила не ранить себя еще больше. У меня осталось крайне удручающее мнение обо всем машинном обучении в целом. Я на полном серьезе решила, что это просто не для меня.
Однако, как и все прочие раны, эта со временем затянулась. В последнее время я все чаще стала читать разные статьи о том, как люди покоряют новые вершины с помощью разных методов машинного обучения. Прекрасные загадки галактик или жизненно важные вопросы медицины — мы имеем шанс приблизиться к их решению, всего лишь обучив компьютер думать в нужном направлении. Эта мысль не дает мне покоя, и поэтому я решила попробовать еще раз, заодно наполнив мотивацией вас.
С чего начать
Если вы находитесь в начале моего пути — начните с простого. Для первых попыток не нужны глубокие познания в математике. Когда я попала в Microsoft, для меня стало сюрпризом, что сегодня можно даже не уметь писать код, чтобы научиться ML. Давайте пройдемся по общему пути, заодно найдем базовое решение для простой задачки.
Сделайте себе аккаунт на Azure ML Studio.Там есть бесплатная квота, без привязки банковской карты, для нескольких попыток. Все алгоритмы и необходимые процедуры реализованы за нас, а что еще более круто — все будет быстро работать даже на слабом ноутбуке. Все вычисления происходят в облаке.
Можно залить свои данные, но для начала нам отлично подойдут и предложенные семплы. Я выбрала датасет про задержки авиаперелетов. Имея обученную модель, можно будет говорить друзьям например о том, что их рейс могут задержать… (Хотя, если я хочу остаться вживых, нужно будет придумать другой способ применения)
Для того, чтобы просмотреть доступные датасеты, нажмите на Datasets → Samples:
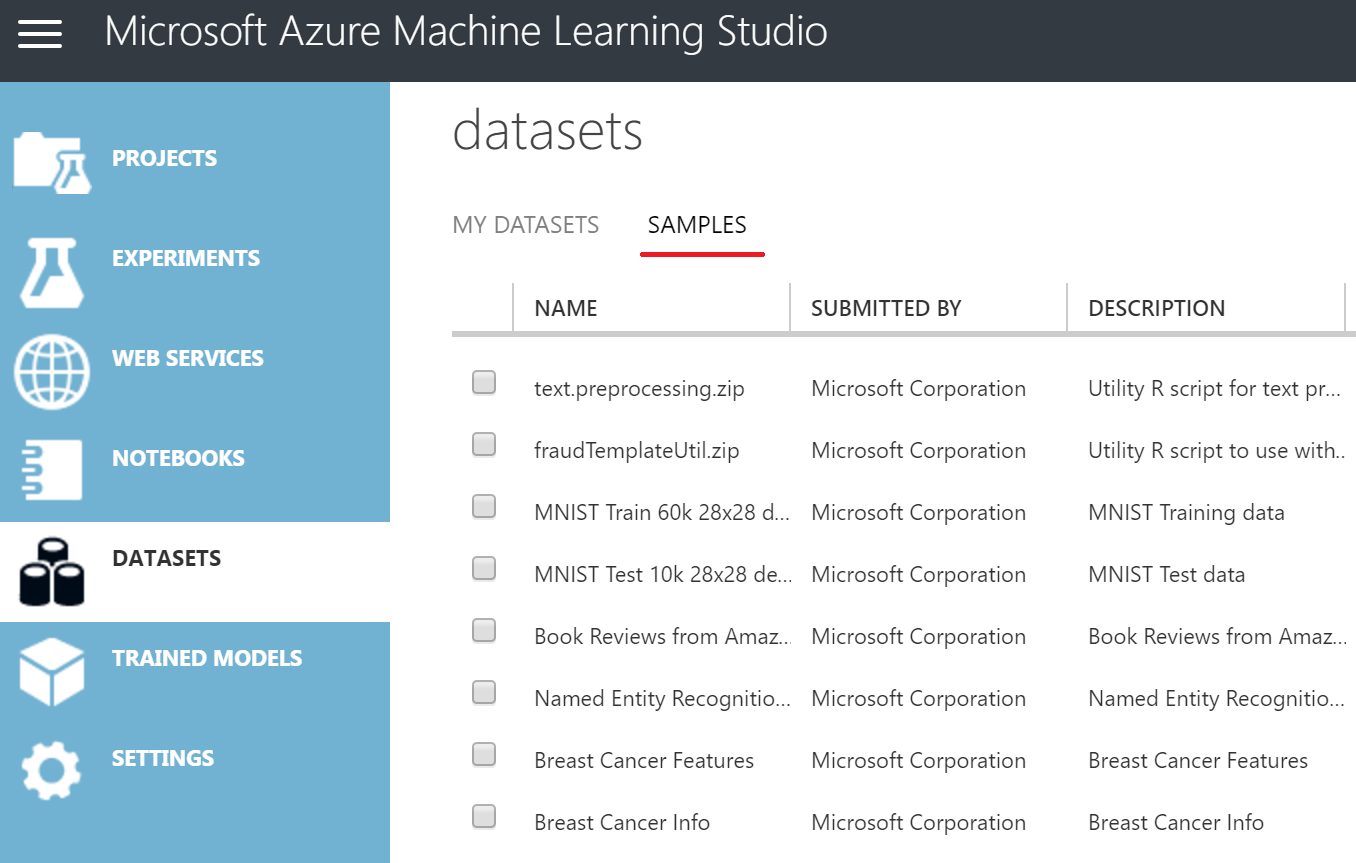
Выбранный мною датасет называется Flight Delays Data.
Создадим свой эксперимент. Для этого нажмем Experiment → New (внизу страницы) → Blank Experiment. К слову, в экспериментах также есть вкладка Samples, там можно изучить уже готовые модели. Но нам сейчас интереснее сделать все самим.
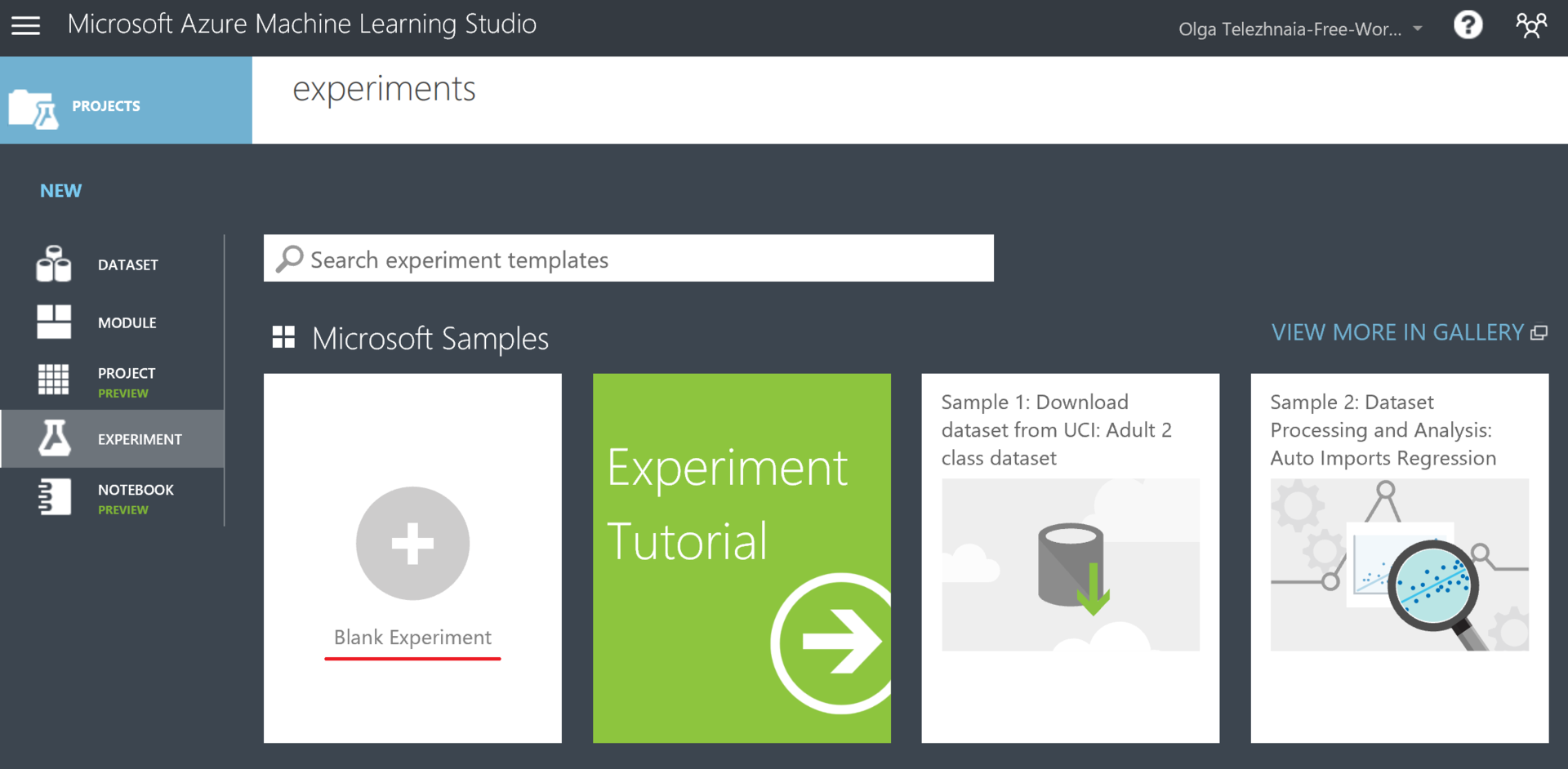
Платформа Azure ML приятно удивила меня свой гибкостью и ненавязчивостью. В этой статье мне хотелось показать, что машинное обучение доступно каждому. Весь дальнейший процесс работы у нас будет выглядеть как «выбрали нужные блоки, кинули на рабочую поверхность, соединили логически, запустили, радуемся».
Если вы чувствуете себя уверенно, вы можете создавать собственные блоки, для этого нужно написать программный код на языке Python или R. Если за вашей спиной уже есть армия обученных моделек, то вам наверняка привычен и удобен Jupyter Notebook, и вы можете работать с Azure ML через него.
Даже если у вас острейшая аллергия на веб-интерфейс, но вам хочется вкусить плюсы облака — разработчики учли даже такую ситуацию и дали возможность подключаться к Azure через консоль. Подробнее тут.
Вернемся к нашей модельке. Все нужные блоки мы будем брать в меню слева. Они удобно разделены на группы. Во время первых попыток я советую искать нужное, попутно изучая соседние разделы. Но если вы знаете примерное название нужного блока, то можно воспользоваться поиском.
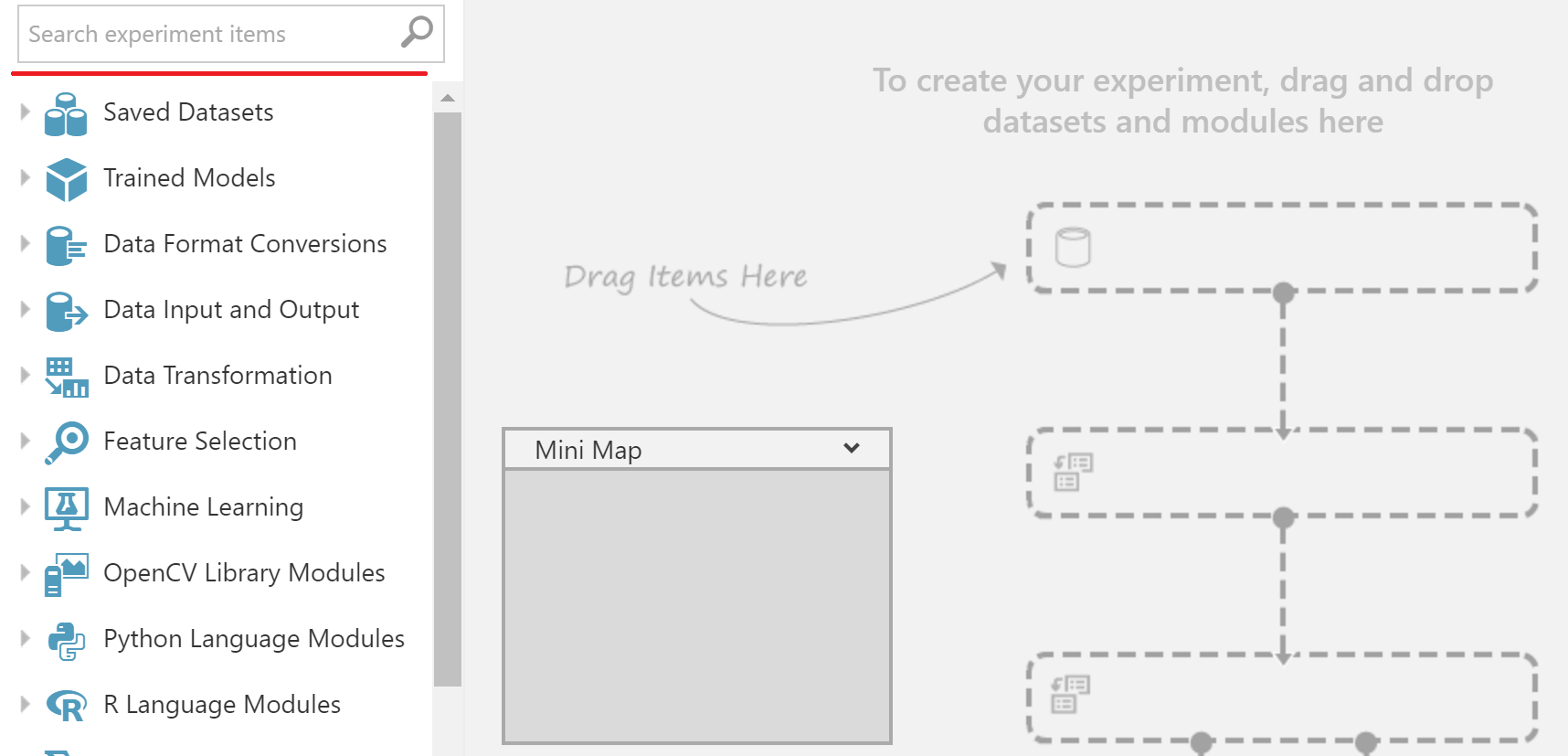
Предсказываем задержку рейсов
Классический сценарий применения алгоритма машинного обучения выглядит так:
- Находим хорошие данные и делаем их еще лучше. Чистим от мусора, добавляем полезную информацию.
Напомню, мы выбрали датасет про полеты.
Перетаскиваем нужный блок на рабочую поверхность.
Необходимо получше изучить и подготовить данные. Для этого нажимаем правой клавишей по выходу из блока и выбираем Visualize:
Видим прекрасную таблицу.
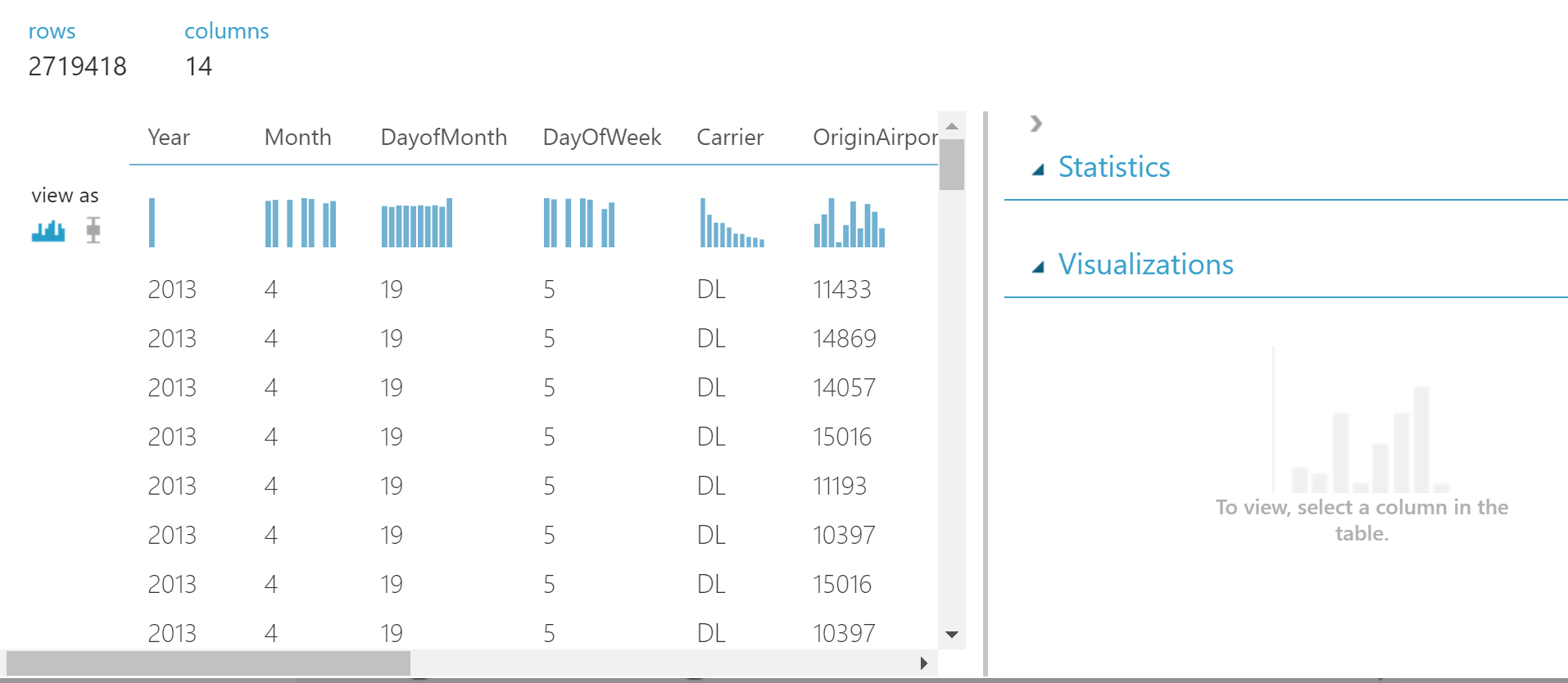
Мы можем нажать на любую колонку и посмотреть для нее статистику.
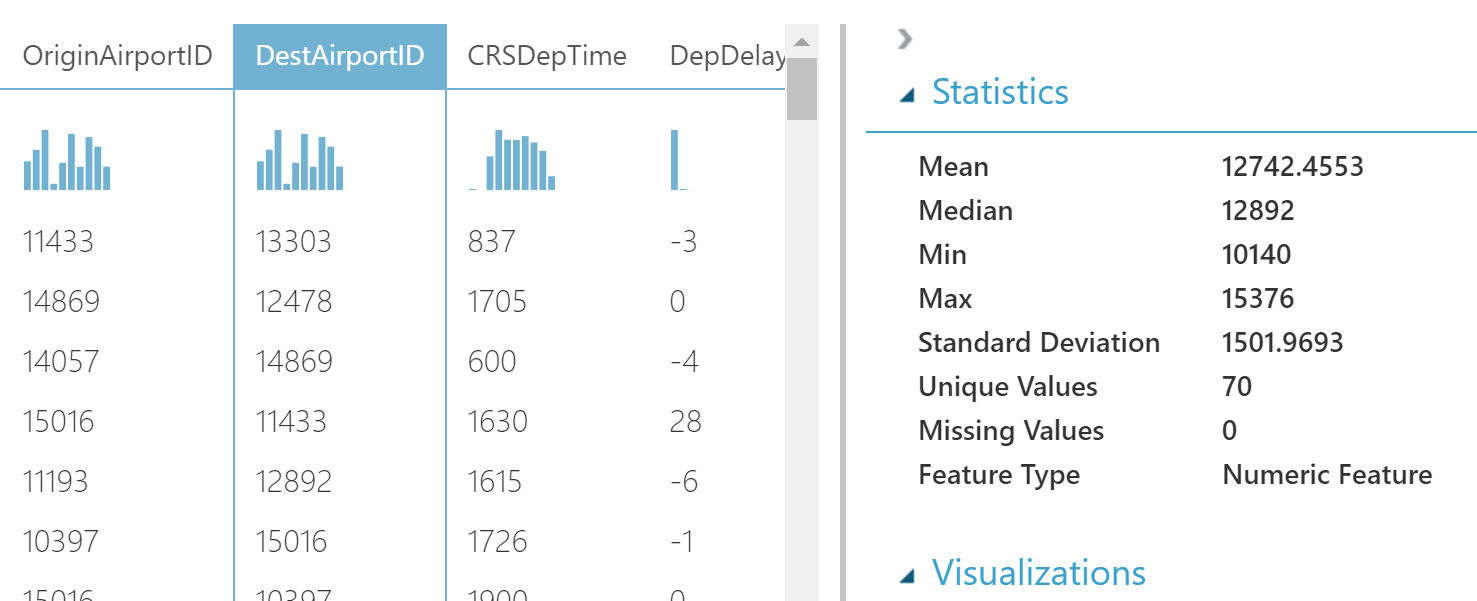
Изучая данные, я нашла колонки DepDelay и DepDel15. Они содержат пропуски, и поэтому я решила удалить данные столбцы.
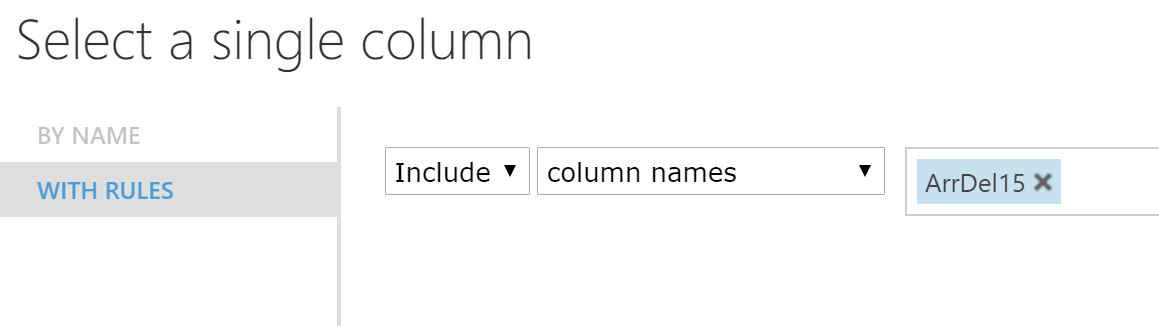
Я планирую предсказывать бинарный признак — правда ли, что самолет опоздает более чем на 15 минут. За него отвечает колонка ArrDel15. Кроме нее, есть также колонка ArrDelay, которая хранит время опоздания в минутах. К сожалению, мы вынуждены удалить и ее, иначе эксперимент получится не совсем честным)
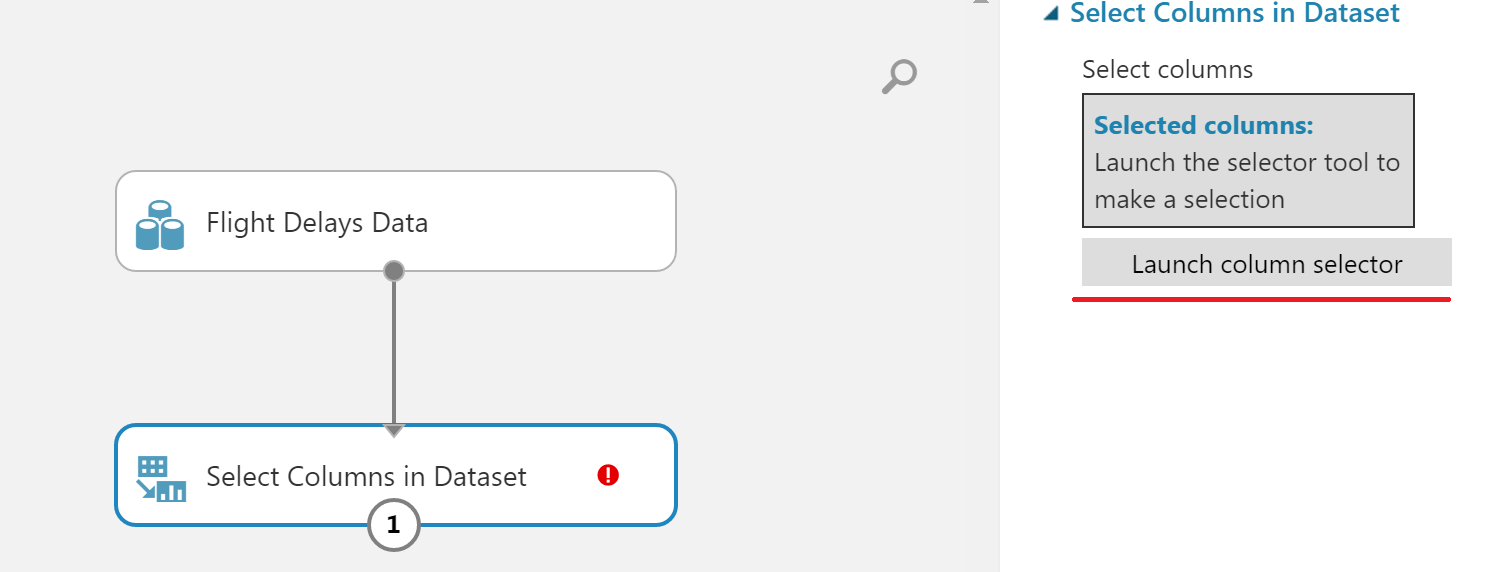
Чтобы удалить колонки, выберем блок Select Columns in Dataset, соединим его с прошлым блоком, а затем в меню справа нажмем на кнопку Launch column selector.
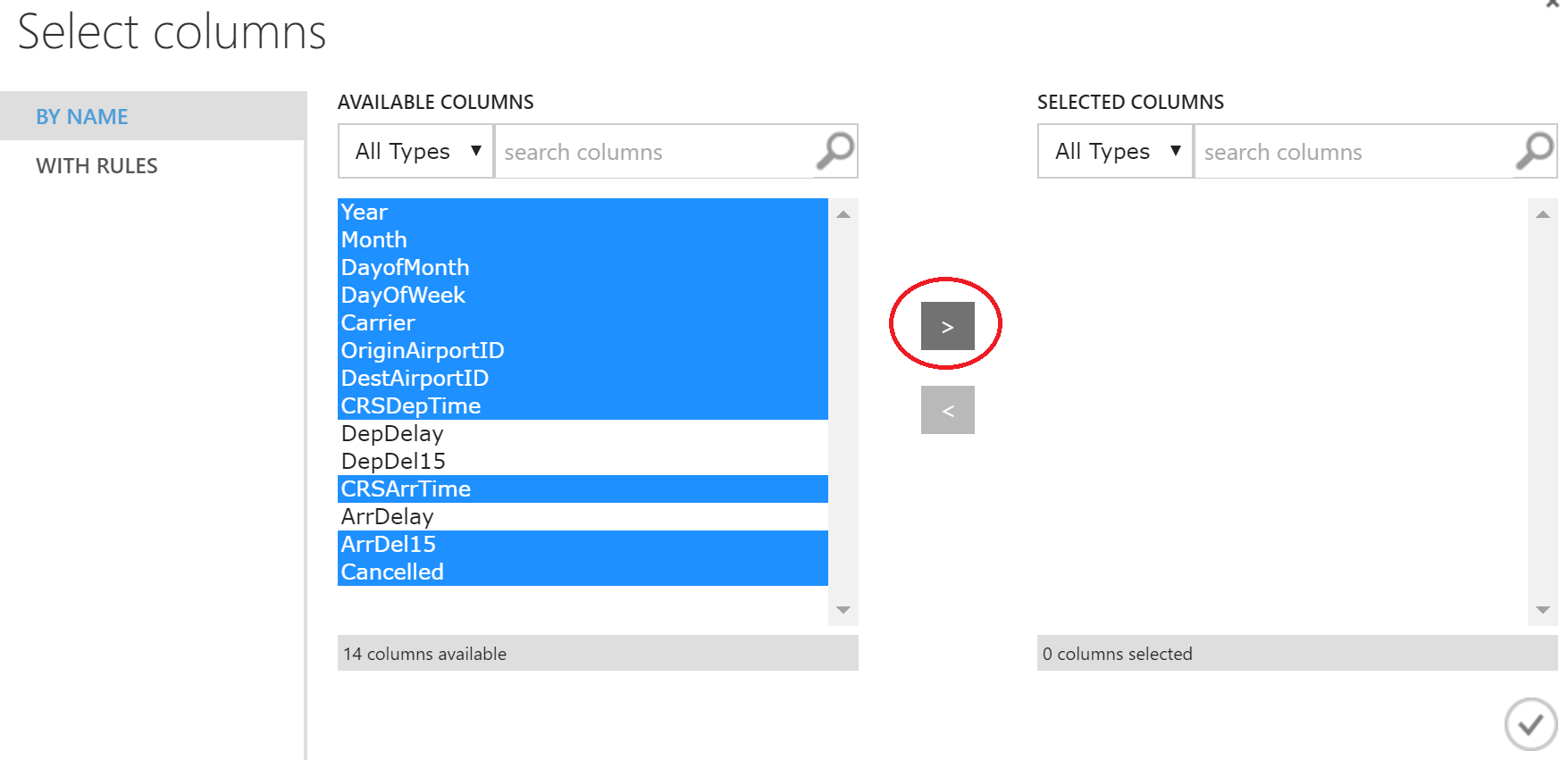
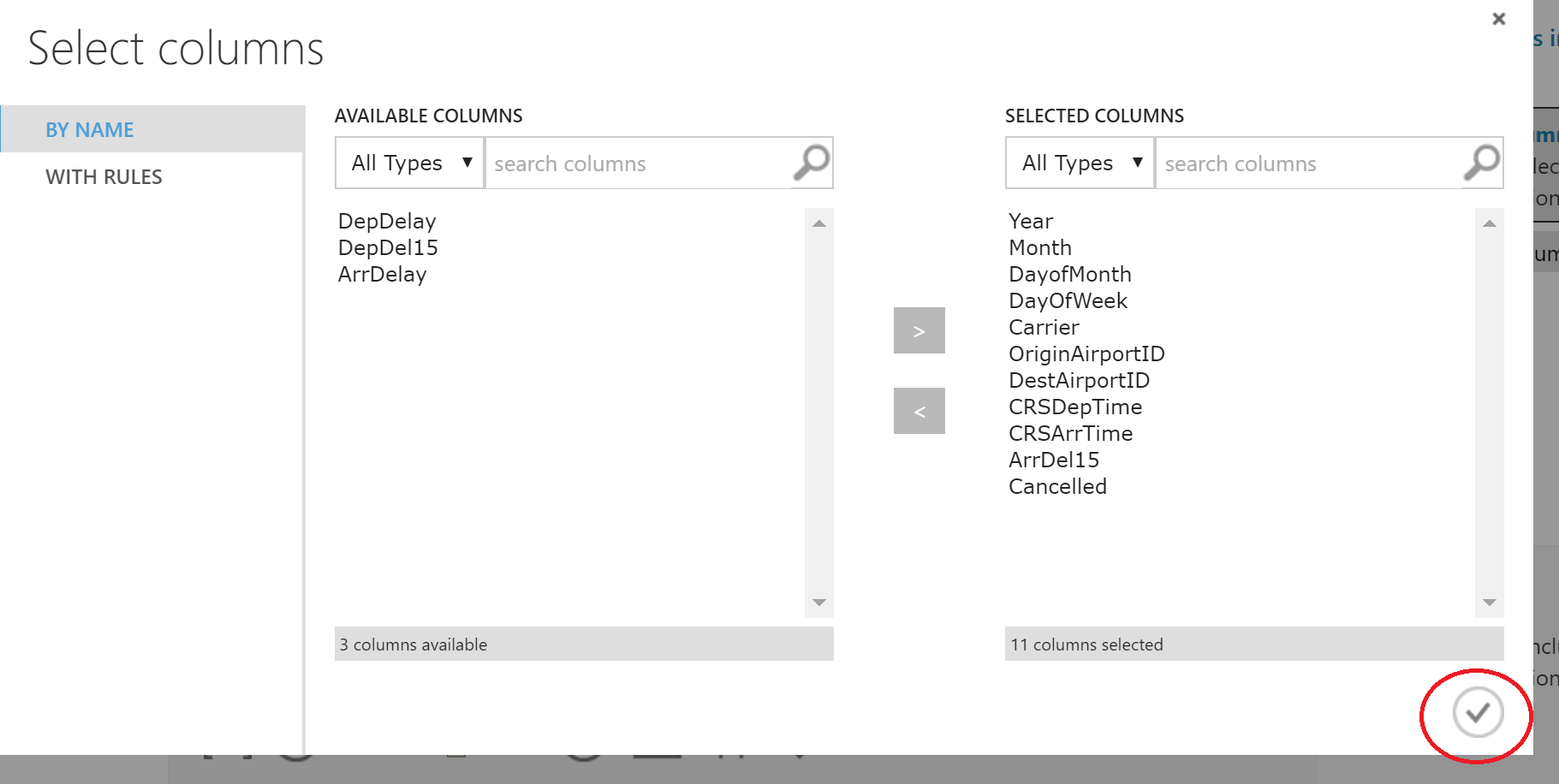
В появившемся окне выберем нужные колонки.
- Делим данные на 2 части — train и test. Наша задача — на время забыть про часть test.
Подробнее про то, что такое train/test set тут. Нам поможет блок Split Data.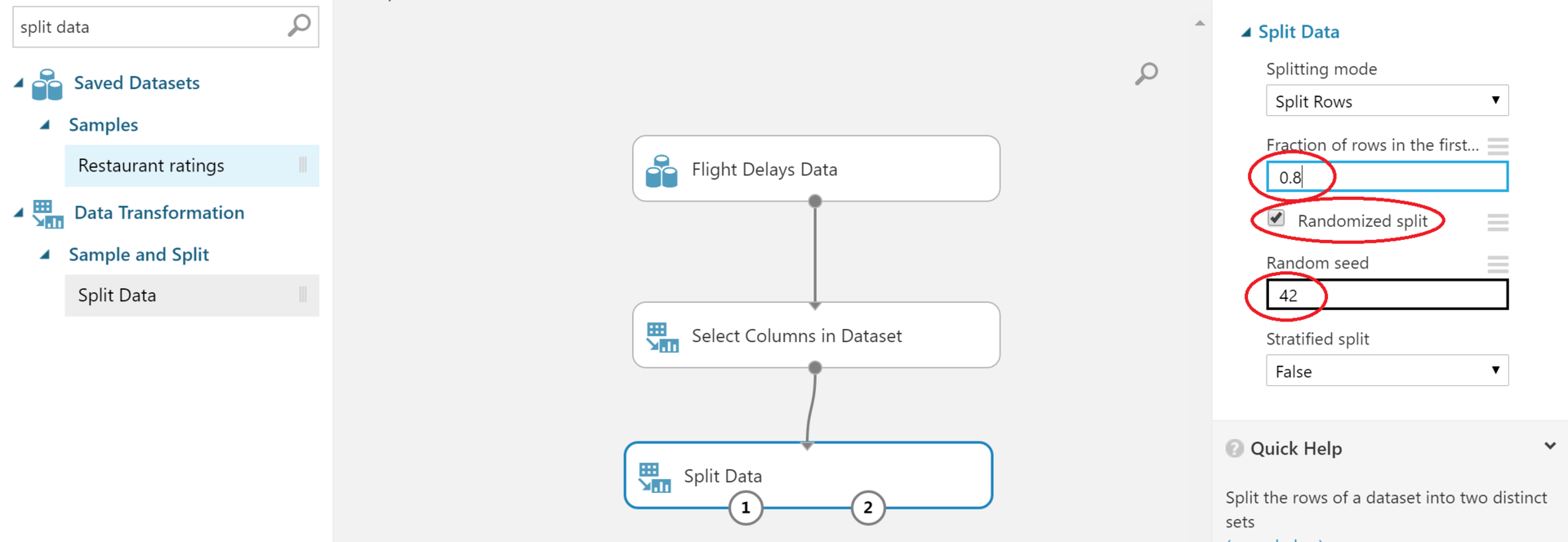
Обязательно заполните обведенные поля справа. Первое — в какой пропорции разбить — обычно ставят около 0.7–0.8. Второе — рандомно ли наше разбиение. Галочка там уже стоит: убедитесь, что вы случайно ее не сняли. Также будет неплохо задать Random seed, почитать про него можно тут.
- Отдаем часть train какому-нибудь алгоритму машинного обучения.
Самое сложное сделают за нас. Выбор алгоритма — тонкий момент. Я по светлой памяти взяла Random Forest (аккуратно — здесь его назвали Decision Forest). Нам подойдет любой алгоритм two-class classification.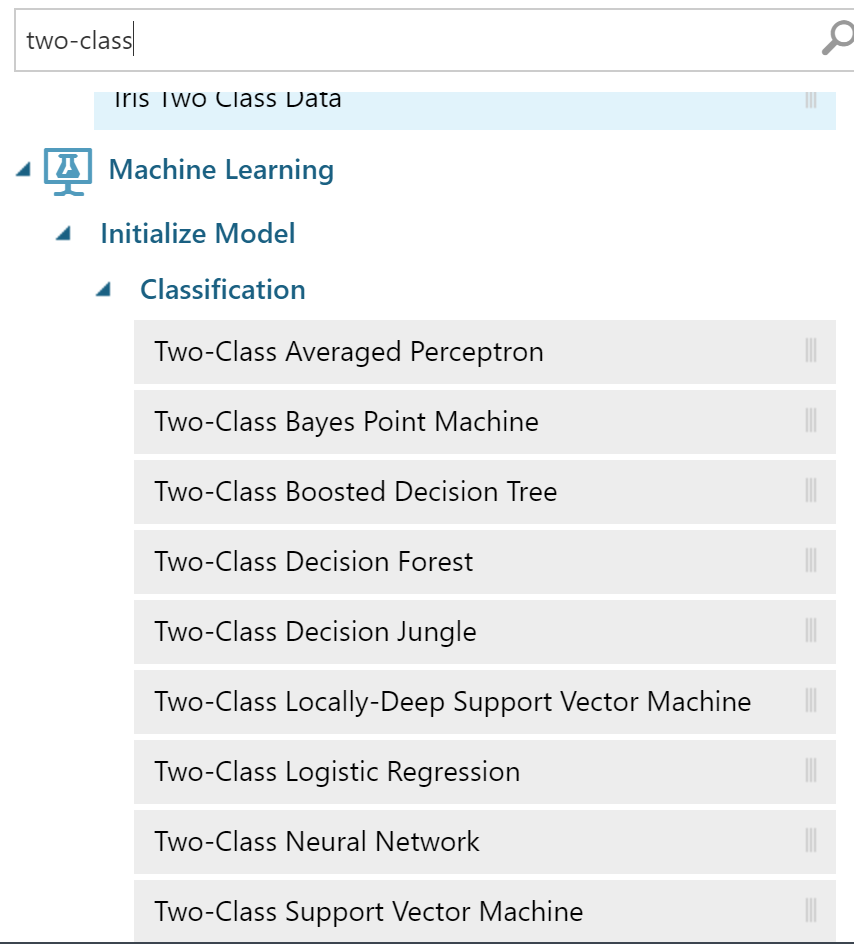
Вы можете выбрать что-то другое, получить результат получше и рассказать об этом в комментариях)
Нам также потребуется блок Train Model. Соединить блоки будет нужно так, как представлено на скрине ниже:
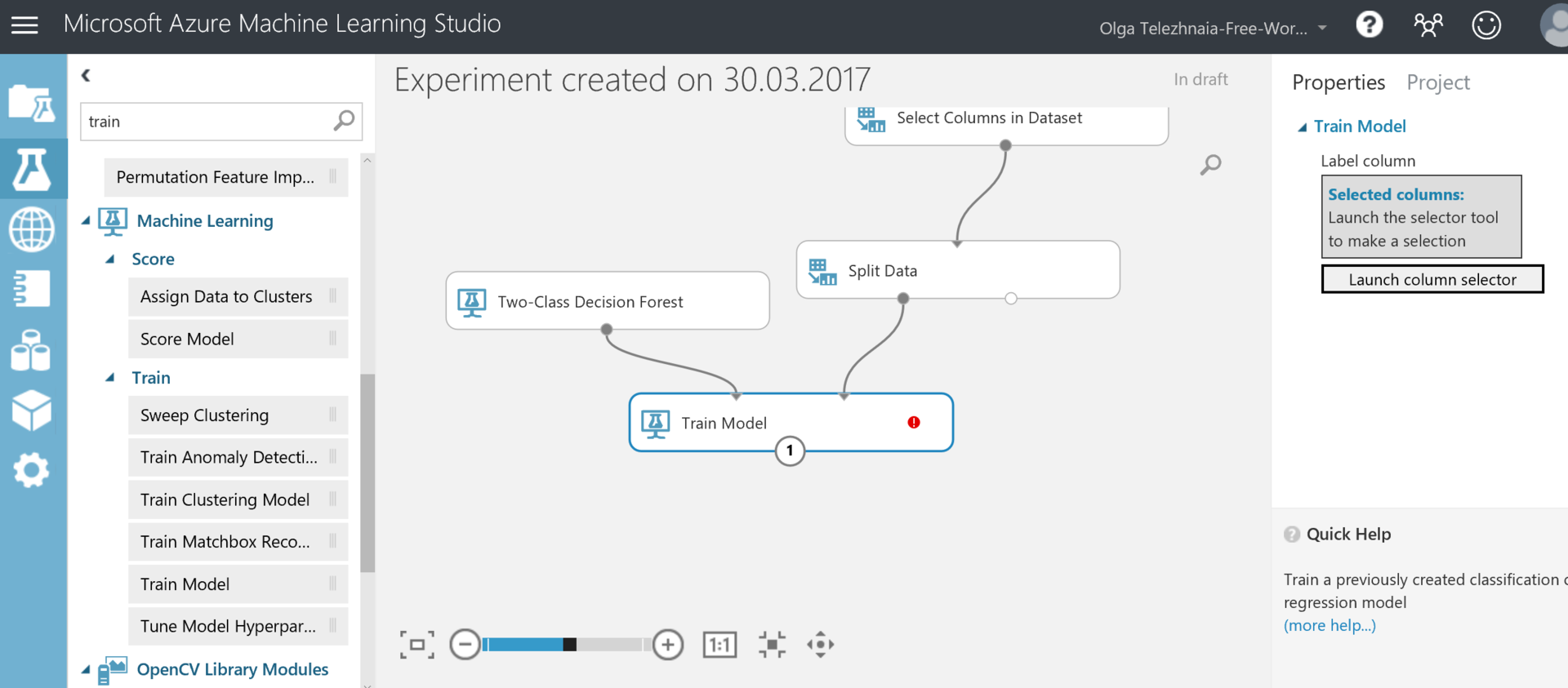
У блока Train Model нам также будет необходимо нажать на Launch Column Selector и выбрать столбец, который мы хотим предсказывать — в нашем случае ArrDel15.
- Полученную модель проверяем с помощью части test
С этим нам поможет справиться блок Score Model. Не забудьте подсоединить к нему также вторую часть данных после разбиения.
Последний блок на сегодня — Evaluate Model — представит нам результат в удобной форме. Итоговый граф выглядит так:
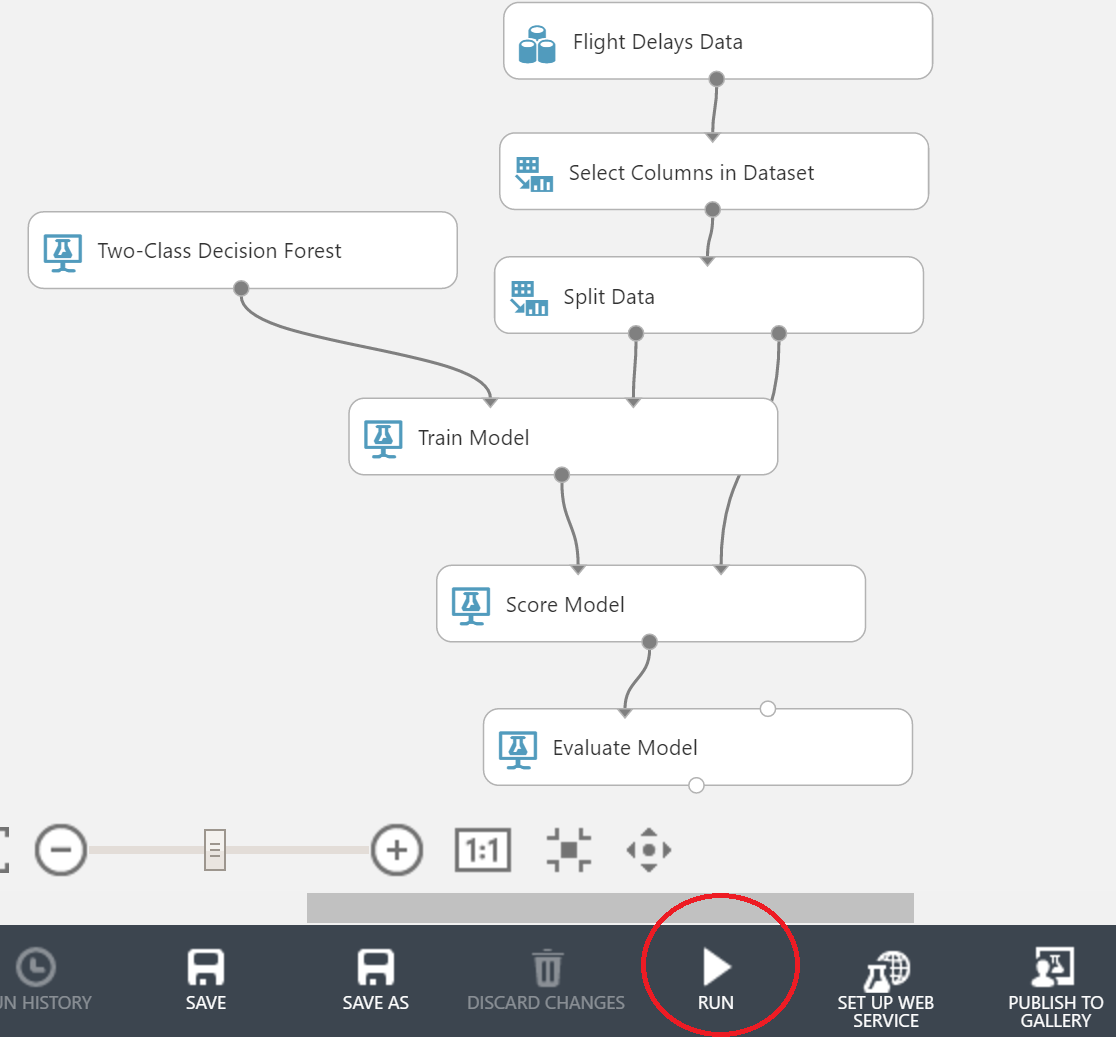
Пора с гордостью жать кнопку «Run» и идти пить чай. Даже для облака обучение — не самый быстрый процесс.
Если чай уже допит, а процесс так и не завершился, советую изучить пару материалов, которые помогут нам читать данные о качестве результатов обучения нашей модели.
Вот такое мы могли бы увидеть, если бы не удалили линейно зависящий столбец ArrDelay из данных. Модель предсказывает идеально, она не ошиблась ни одного раза. Я увидела это, пустила скупую слезу радости и пошла проводить эксперимент повторно, по-честному)

А вот такой результат я получила после удаления столбца ArrDelay. Похуже, зато похож на правду.
- Вас устроило качество? Поздравляю! Теперь вы можете брать новые объекты из реального мира, и компьютер предскажет для них все необходимое. Я получила точность предсказания 80%, и это не волшебство, но отличный старт.
- Если качество вас не устраивает — возвращаемся к началу задачи и ищем, что можно улучшить.
Конечно, я максимально упростила процесс. Искусство подготовки данных, их разделения на части, выбора алгоритма и измерений качества оттачивается годами. Тем не менее, факт «собрать модель с нуля буквально за 10 минут» придает мне второе дыхание и оживляет огромный интерес к этой теме. А что, если я возьму не Random Forest, а SVM? Кстати, а вы знаете, чем отличаются эти алгоритмы? Оба имеют внутри себя огромную мат.базу и довольно сложную реализацию, однако общую идею сможет понять каждый. Было бы желание;-) Кстати, можете начать с изучения этой шпаргалки.
Надеюсь, что моя статья поможет вам избежать страданий и влюбиться в ML, так же как и я. Делитесь своим мнением и опытом в комментариях, будет интересно пообщаться!
Если вам была бы интересна статья для новичков по какой-то более конкретной теме, сообщите об этом в комментариях, и я постараюсь поделиться своим опытом более детально. Вы можете также ознакомиться со статьей Евгения Григоренко, в ней вы найдете больше практических сценариев, направленных на более опытных пользователей.
