Как организовать потоковую обработку данных. Часть 1
Привет, Хабр! Меня зовут Евгений Ненахов, я работаю в центре Big Data МТС Digital. В этой статье я расскажу о том, как мы создали универсальный инструмент потоковой обработки данных и построили с его помощью мощную систему стриминга. Если вам интересна обработка данных — welcome!

Последние несколько лет я занимаюсь проектами Big Data, поэтому расскажу о методологии потоковой обработки данных и её применении на практике. Статья получилась подробной и масштабной и для простоты восприятия я разделил её на две части. В первой половине мы обсудим основные компоненты методологии, а во второй части поговорим о том, как их применять.
Что это за методология такая?
Преимущество подобной методологии потоковой обработки данных в том, что она универсальна и позволяет решить широкий круг задач. А ещё её можно реализовать практически на любом стеке технологий. Я верю в то, что после прочтения статьи вы сможете создать подобный инструмент сами, используя эту концепцию. И сэкономите тем самым массу времени и сил.
В тексте под словами стриминг, стриминг процессинг или streaming я подразумеваю потоковую обработку данных.
Все мы прекрасно знаем что «время — деньги», а применительно к IT эта фраза означает вот что: чем быстрее мы обработаем данные — тем больше выгоды из этих данных мы сможем получить. Лучший способ — обрабатывать данные в режиме реального времени, то есть применять так называемый стриминг процессинг.
Стриминг процессинг дает возможность обрабатывать и получать выгоду из скоропортящихся данных, актуальных в небольшой промежуток времени. На основе этих данных мы можем делать персонализированную рекламу, предлагать скидки, кредиты, да почти что угодно. Телеком, например, такие данные может использовать для предложений новых тарифных планов и более сложных кейсов.
В МТС много данных, которые можно и нужно обрабатывать в режиме реального времени. В основном это данные, которые поступают с коммутационного оборудования базовых станций, различных устройств, сайтов, приложений. Все эти данные можно разделить на несколько доменов: геолокация, звонки, нахождение абонента в роуминге, типичный кликстрим (большой поток по URL) и прочая информация.

Данные нужно обрабатывать, а для этого требуется мощная и при этом универсальная концепция. Требования к такой системе предъявлять сложно, поэтому мы пошли от наших желаний. Нам хотелось производительности, причем достаточной высокой, от 5 млн до 10 млн событий в секунду. Не хотелось терять события — поэтому понадобился надежный механизм отказоустойчивости. Хотелось масштабироваться без боли как вертикально, так и горизонтально.
Нам хотелось иметь гибкий функционал фильтрации, трансформации данных из одного формата в другой, научиться дедублицировать данные на потоке. Важно было сделать zero code- или хотя бы low code-настройки обработки данных, подключения новых источников. Желания закладываться в полный жизненный цикл разработки ПО при малейших изменениях и тратить на это время у нас не было. Стриминг — вещь капризная, за ним нужно следить, причем следить пристально. Поэтому мы захотели организовать детализированный мониторинг.
Какие варианты?
С «хотелками» разобрались, а что есть на рынке из стека технологий, которые позволят исполнить хотя бы часть наших желаний? В процессе поиска список сократился до четырех технологий: Spark Streaming, Flink, NiFi и Kafka. Для каждой мы провели отдельно RND, взяли совокупность «железок» и свой специфический набор данных.
Мы учитывали несколько критериев:
развитость комьюнити технологии;
как часто выходят релизы;
куда движется технология, как развивается;
опыт и компетенции нашей команды (или «уровень душнильства).
возможность реализовать наши пожелания

В итоге выбор пал на Spark Streaming. В качестве основного языка программирования мы выбрали Scala — считаю, что это мощный язык, который со своим функциональным стилем идеально подходит для решения задач потоковой обработки данных. В качестве шины данных взяли Kafka — инструмент, который отлично себя зарекомендовал для решения задач Big Data.
Стек выбрали, а что с ним делать?
Первая мысль, которая приходит в голову — подобрать обработчик, написать монолит, взять щепотку Scala, запихнуть это всё в мясорубку Spark, запустить на кластере и пустить гонять данные из Kafka в Kafka. А можно сделать наоборот: декомпозировать задачу, на каждый поток сделать свою кастомную обработку. Но у любого из этих решений есть минусы, которые нас не устраивали.
Любое изменение — это долгий процесс. Это полный жизненный цикл разработки ПО: мы ставим задачу в аналитику, начинаем писать код, тестировать на различных стендах, ставить план релизов, релизить. Долго, занимает несколько дней или даже недель. А к нам может прийти клиент и сказать: хочу посмотреть гипотезу на потоковых данных за пару часов.
Такие системы сложно документировать, сложно тестировать. А значит, что появляется высокая вероятность появления критичных багов на продакшне. Возникает эффект лавины, становится сложно в принципе писать код, потому что мы тратим время не на развитие нашего проекта или на внедрение новых фич, а занимаемся поиском этих неуловимых багов. И мы не чиним баги, а просто делаем их меньше.
Сложнее становится релизить, появляется куча различных версий, конфигураций, которые тяжело поддерживать.

В таких условиях легко выгореть, уехать куда-нибудь в деревню, выращивать овощи и жить замечательной жизнью. Мол, ну вас со всеми вашими Scala и Spark. Заманчивая идея, но не сегодня, дружок.
Поэтому решение, приведенное выше, не подходит, хочется что-то более универсальное, какую-то более гибкую концепцию. Выход — сделать так называемый конвейер данных, в нашей терминологии — Pipeline. Мы берём данные из потока, ставим их на конвейерную ленту, и эти данные путешествуют от обработчика к обработчику последовательно, при этом изменяя свое текущее состояние. Когда данные доходят до терминального (то есть последнего) обработчика, он смотрит на конечное состояние этих данных и принимает решение, что же с ними делать.
Какие у нас обработчики?
В нашей реализации Pipeline всего пять обработчиков, два из них — обязательные, это Source и Action. Если у нас есть источник и направление передачи данных — значит, поток у нас тоже есть. Остальные обработчики, в принципе, могут не принимать участия в процессе.
Но мы же помним, что у нас есть «хотелки»? А значит, у нас есть и другие обработчики. Тут стоит обратить внимание на обработчик фильтрации. Мы очень хотели иметь гибкую систему фильтрации и задавать в рамках этого пайплайна не один фильтр, а несколько. Чтобы создать такую гибкую методологию достаточно было сделать небольшой DSL и реализовать два логических операнда. Это логические операторы AND и OR, а также скобки для установки приоритета. Уже этих операндов достаточно, чтобы создавать большие выражения, которые позволят гибко фильтровать данные. Потребителю достаточно указать только это выражение, чтобы фильтровать свои данные.
Но нам и этого функционала пайплайна было недостаточно. Хотелось сделать что-то типа конструктора Lego, чтобы у нас был своего рода кубик (наш пайплайн) и из таких кубиков мы могли бы собрать что-то большое. Хотелось таким способом расширить наши возможности.
Мы поняли, что нужен конструктор, чтобы все пайплайны могли собираться в один мега-пайплайн в цепочке, и запускаться в рамках единственного Spark Streaming. А ещё мы хотели, чтобы это запускалось параллельно, чтобы несколько потоков работало. Вот тогда наши возможности станут поистине безграничными.

Наша реализация выглядит так: обычный класс пайплайна, который содержит в основном только два метода: start и stop. Причем start принимает основную, главную движущую силу нашего решения, — стриминг контекст.
StreamingContext — это сердце, наше все. Он создается один раз на уровень абстракции выше, в так называемом пайплайн-менеджере, который следит за всем жизненным циклом коллекции пайплайнов. Чтобы запустить или перезапустить какой-нибудь пайплайн, достаточно обновить эту коллекцию и перезапустить стриминг контекст.
Запуск пайплайна — в принципе вещь тяжёлая. Это перезапуск стриминг контекста, поэтому прежде чем запускать какой-то пайплайн, нужно сначала проверить все конфигурации. А так как терминальный обработчик у нас Action, лучше проверить именно его настройки, прежде чем запускать конкретный пайплайн. Ну и, конечно же, хотелось бы реализовать метод Stop, чтобы всё-таки останавливать пайплайн, когда нам хочется.
Теперь давайте поподробнее поговорим о каждом обработчике в пайплайне.
Source — он должен принимать данные из источника, создавать на основе этих данных стриминг и десериализовывать эти данные в нашу внутреннюю модель. Дальше эта внутренняя модель, Message, будет путешествовать от обработчика к обработчику, изменяя своё состояние. Вводится своего рода контракт.
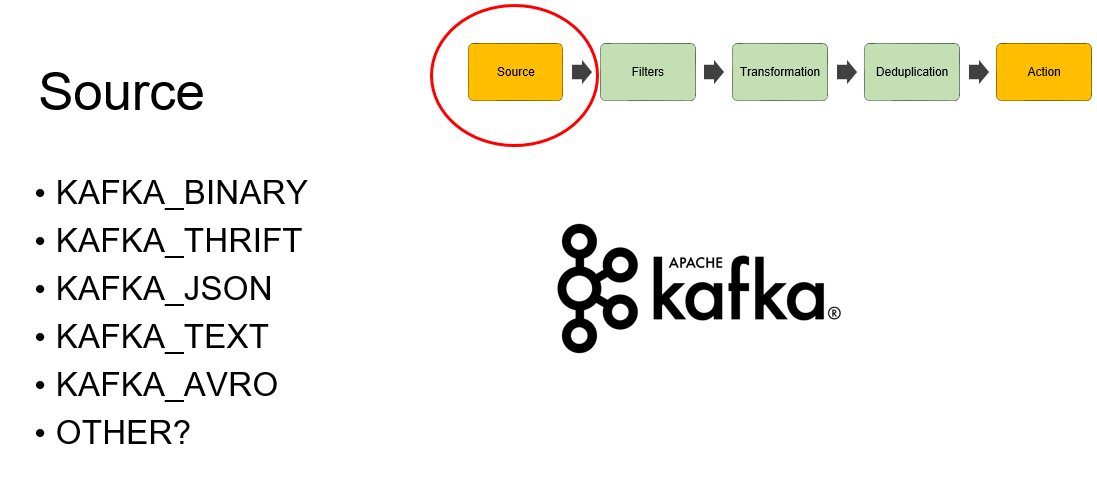
Основной источник данных для нас — это Kafka, туда отправляются в потоковом режиме все данные которые у нас есть. Мы реализовали несколько типов Source Kafka, основные — Thrift и Json. 70–80% данных хранятся именно в формате Thrift.
Можно ли сделать другой источник данных, не Kafka? Конечно, можно использовать HDFS Avro, натравить этот Source на HDFS-директорию и смотреть, как появляются новые файлики, какие изменения вносятся в какой-нибудь файл. Чтобы это сделать, достаточно реализовать trait Source, в котором есть основные методы.
Основные методы — это stream, message, и onRDDEnd. Stream принимает StreamingContext, причём он у нас у нас будет путешествовать транзитивно через каждый пайплайн и каждый обработчик данных. На основе StreamingContext создается InputDStream, то есть дискретный поток данных. После этого применяется метод message, который в зависимости от типа десериализует наши данные во внутреннюю модель.
Еще один интересный метод — onRDDEnd — он позволяет нам реализовывать некоторые вещи, связанные с доступностью данных на источниках. Например, для Kafka мы можем вручную коммитить оффсеты. Это очень удобно: если вдруг в нашем пайплайне произойдет инцидент, какой-то из обработчиков будет себя плохо вести, выдавать исключения, то мы не потеряем данные. Мы перезагрузим пайплайн и начнем считывать данные с того момента, на котором последний раз закоммитились.
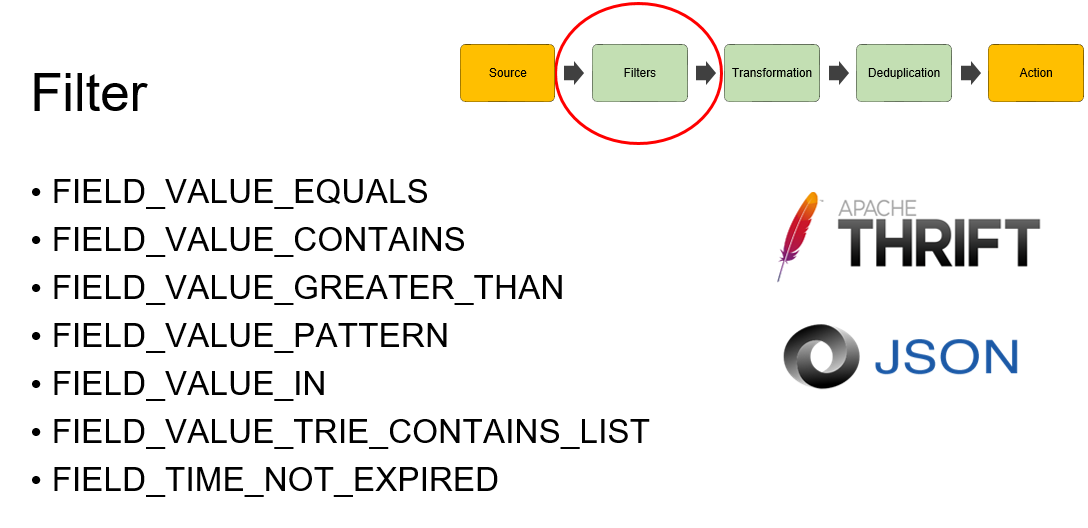
Переходим к следующему обработчику — это фильтры, и мы сделали их много. Причем сначала мы клепали более-менее общие фильтры. Это видно по названиям: есть Equals, Contains, нахождение по паттерну. Но все эти фильтры были недостаточно производительны. У нас огромный поток, и самая его мякотка идет как раз-таки на фильтрацию. CPU загружен «в потолок» именно на этих фильтрах, тем более, что у нас может быть множество фильтров в одном DSL.
Соответственно, мы стали делать более производительные и специальные фильтры, учитывающие специфику данных. Например, стоит обратить внимание на Trie contains list. Он содержит реализацию алгоритма Ахо-Корасика для поиска подстроки в строке.
В нашем случае он используется для поиска доменов определенного уровня в потоке URL-ов. Такая штука нам позволила увеличить производительность по сравнению с обычным Contains-ом на 30% и снизить нагрузку на CPU.
Фильтр у нас имеет частично определенную функцию, которая содержит по умолчанию сразу два метода — isDefinedAt и Apply. isDefinedAt у нас проверяет, участвует ли этот фильтр в обработке данных, участвует ли он в пайплайне, в конкретном DSL. Если участвует, то применяют метод Apply, в котором реализована фильтрация к конкретному сообщению.
Следуем дальше. Когда данные отфильтрованы — они поступают уже в трансформацию, и тут все просто. Так как основной формат данных — Thrift, то потребители хотят видеть глазами эти данные, а Thrift у нас — это sequence byte, глазами его не очень получается смотреть. Соответственно, мы сделали трансформацию данных в CSV, в Json, есть даже трансформация Json to Json.

В эту трансформацию мы просто убираем лишние поля и переделываем их так, как хочется потребителю. Например, если на вход у нас пришло сто полей — мы выдаем только пять, нужных клиенту. И уменьшаем тем самым размер самого потока. Все это, конечно же, настраивается потребителем на самообслуживании. Нужно только взять trait и реализовать, реализация похожа на фильтрацию. Методы аналогичные, isDefineAt и Apply с тем же назначением.
Потом наступает очередь следующего обработчика, дедубликации. Есть вопрос:, а как в принципе делать дедубликацию данных на потоке? Когда у нас есть конечный набор данных — там все понятно: есть сообщения и записи, на основе которых мы можем понять, где какие данные являются дублем. На потоке у нас бесконечное количество данных, соответственно, нам нужно выбрать какой-то интервал времени, в рамках которого необходимо хранить состояние нашего объекта. И только после него уже сравнивать состояние конкретно других объектов для поиска дублей.
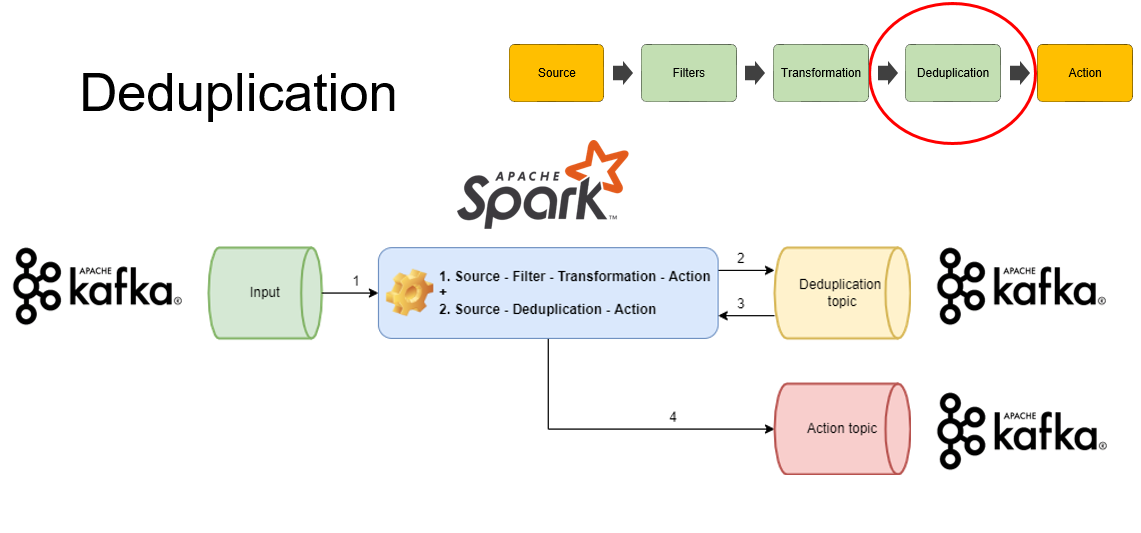
Где хранить эти объекты и какое время хранить? Время мы отдали на откуп потребителям, а вот место… Мы хотели иметь самодостаточный инструмент и не плодить большое количество технологий или же использовать для этого какую-то внешнюю хранилку.
Мы подумали: есть же Spark Streaming, у него есть executors, они запускаются на различных нодах, которые умеют между собой общаться, есть механизм бродкастов. Может быть есть что-то, что позволит именно из спарк стриминга сделать так, чтобы можно было сохранить состояние? У нас есть dstream, дискретный поток данных, а у него есть так называемый метод mapWithState. Причем в исходниках спарка он помечен как experimental. Мы именно экспериментировали с этим решением и нам этот эксперимент очень понравился. Достаточно просто передать туда функцию по правилам определения дедубликации и всё, спарк стриминг сам у себя будет хранить определенное состояние. Нам даже любезно предоставили метод timeout, время жизни состояния объекта, то есть сколько времени хранить этот объект.
Это решение казалось очень удачным, но в какой-то момент мы поняли, что и у него есть недостатки. Если мы вдруг перезагрузим наше приложение или инструмент, то получится ситуация, когда мы уже потеряем отфильтрованные и трансформированные данные. Это нас не устраивало. При этом мы не могли никак понять, правильно ли у нас работает дедубликация.
Выход нашли такой: просто разделить на два пайплайна конкретное решение. То есть взять, вычитать данные, отфильтровать, трансформировать, отправить эти данные с помощью Action в промежуточный топик Kafka для дедубликации. И вторым пайплайном этим же приложением вычитать данные и просто дедублицировать, в конечном итоге отправив их в конкретный топик.
Реализация дедубликации — это метод Apply и DStream с MapWithState, туда передаем функцию высшего порядка, которая дедублицирует данные и сохраняет все по механизму бродкастов. Таймаут указан для timetoleave нашего конкретного состояния.
Переходим к терминальному обработчику. В нем нам достаточно было реализовать три выхода: это Kafka, HDFS и HBASE. В Kafka мы можем лить данные в любой кластер в любом направлении, также мы можем данные записывать как файлики на HDFS в различных форматах. Причем мы умеем ролировать файлики как по времени, так и по размеру. А еще мы можем записывать данные в HBASE по ключу, для этого всего у нас есть конфигурации, и пользователи этими конфигурациями пользуются.
При этом в рамках пайплайна у нас может быть несколько Action, то есть Source у нас минимум один в пайплайне, а экшнов может быть несколько. Это сделано для того, чтобы трансформированные и уже отфильтрованные данные мы могли параллельно записывать в несколько топиков Kafka или в несколько директорий HDFS.
Я уже упоминал о том, что Action должен принимать решения о том, что же делать с данными, когда данные к нему уже пришли и когда Action уже видит его конечное состояние. Здесь есть интересный момент. Допустим, у нас есть некоторый простой DSL и несколько фильтров, которые соединены логическим операндом AND. И у нас есть сообщения, которые вычитываются из источника в поток.

У нас есть выражения, у нас есть фильтры, и каждый фильтр принимает участие в обработке сообщения. То есть сообщение путешествует абсолютно по всем фильтрам, которые указаны у нас в DSL. Каждый фильтр устанавливает отметку в нашем сообщении, точнее даже битик в битовой маске этого сообщения о том, что конкретный фильтр успешно прошел фильтрацию для этого сообщения.
Соответственно, пройдя каждый фильтр, каждое сообщение накопит в себе конкретное состояние и, когда оно придет в Action, у него посмотрят так называемый триггер. Триггер сравнит состояние битовой маски конкретного сообщения с условием DSL фильтрации и поймет, что же с этими данными делать. Если условие по битовым маскам совпадают, то данные передаются в Action, и Action уже знает, куда эти данные дальше отправлять. Если нет — то данные будут просто отфильтрованы.

Action реализовывается просто. Это тот же PartialFunction, значит у него есть isDefinaAt и Apply, но при этом есть еще пара интересных методов, например, OnPartitionEnd и OnRDDEnd. Для чего нам нужен OnPartitionEnd? Например, для реализации HDFS Action. По записи данных в HDFS мы в этом методе ролируем файлик по времени и по его размеру. А OnRDDEnd в случае успешной обработки RDD может отправлять какие-то дополнительные метрики помимо технических метрик, например, метрики данных для Data Quality.
На этом заканчиваем первую часть. Если у вас возникли вопросы или вы хотите поделиться опытом — добро пожаловать в комментарии!
Продолжение — в ближайшее время.
