Как общаться с ChatGPT с помощью голосовых сообщений в Telegram
Пару недель назад я написал бота, который позволяет говорить с ChatGPT с помощью голосовых и текстовых сообщений. Это удобно, потому что не нужно использовать VPN для работы с OpenAI, а про клавиатуру можно забыть вовсе.
В этой статье делюсь пошаговой инструкцией, как реализовать ChatGPT Telegram-бота на NodeJS и задеплоить его на виртуальный сервер. Подробности под катом!
Каркас Telegram-бота
Настройка рабочего окружения
Начнем с самого простого: инициализируем проект и установим необходимые зависимости для среды разработки.
npm init -y
npm i -D nodemon cross-env
После инициализации в директории проекта сгенерируется конфигурационный файл package.json. А вторая команда подтянет необходимые пакеты, которые позволяют запускать приложения NodeJS в режиме разработки.
Теперь добавим поддержку установленных ES-модулей в package.json для разработки и продакшена.
"type": "module",
"scripts": {
"start": "cross-env NODE_ENV=production node ./src/main.js",
"dev": "cross-env NODE_ENV=development nodemon ./src/main.js"
},
package.json
Установка Telegraf и регистрация бота
Рабочее окружение настроено — давайте приступим к написанию самого бота. Создаем главный файл ./src/main.js, устанавливаем фреймворк Telegraf и config.
npm i config telegraf
После установки необходимых пакетов и создания главного файла, можно запустить самого бота. Для этого нужно импортировать Telegraf и config, а после — добавить ключ API для работы с Telegram.
import { Telegraf } from 'telegraf'
import config from 'config'
const bot = new Telegraf(config.get('TELEGRAM_BOT'))
bot.launch()
process.once('SIGINT', () => bot.stop('SIGINT'))
process.once('SIGTERM', () => bot.stop('SIGTERM'))
./src/main.js
О настройке config.get () ниже.
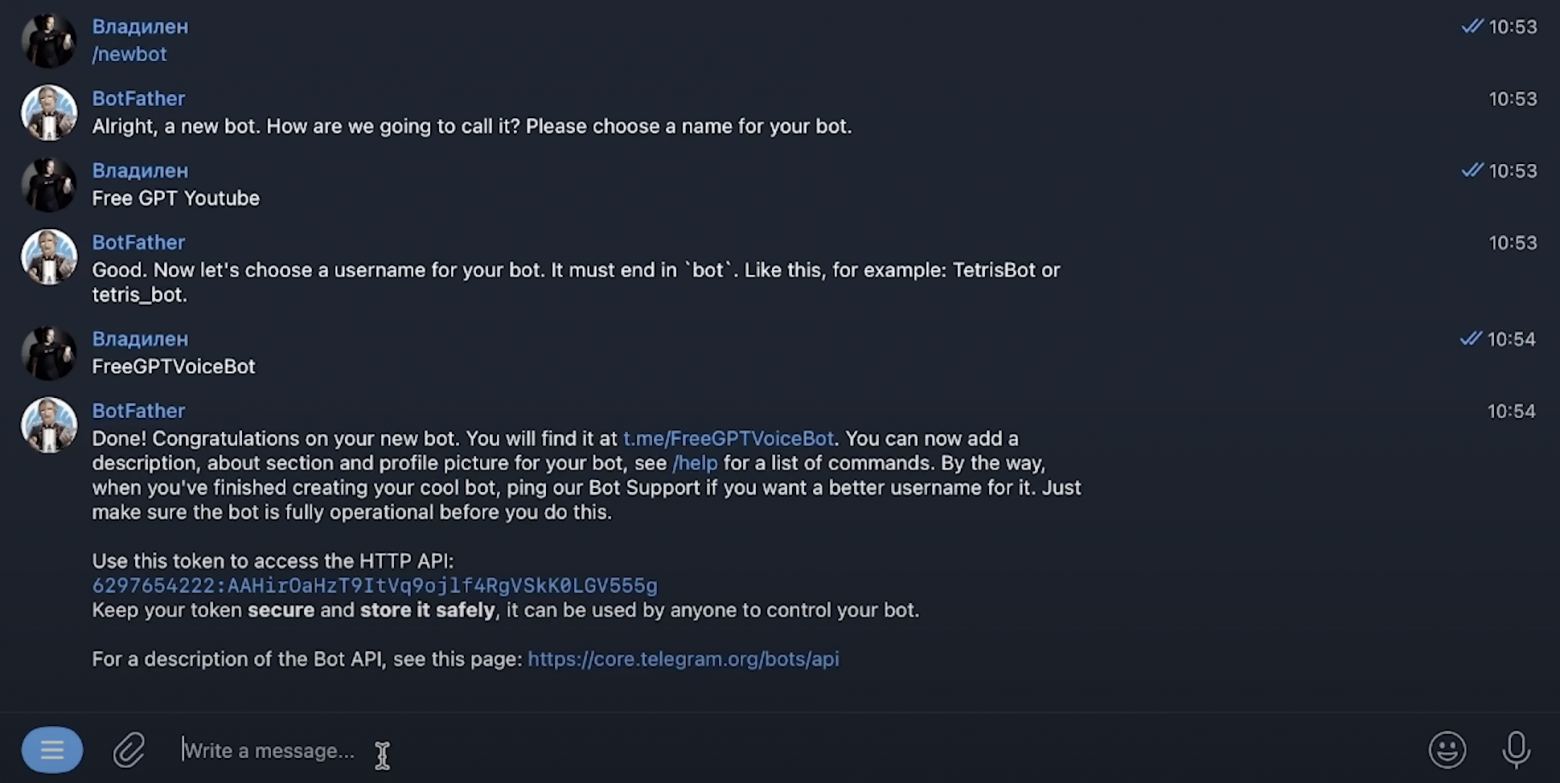
API-ключ для Telegram можно получить у @BotFather, введя /newbot — команду для создания и регистрации нового бота.
Теперь создадим «заготовки» для настроек приложения, где будут расположены данные для Telegram-бота. Добавляем два файла — ./config/default.json с конфигурациями для разработки и ./config/default.json — для продакшна.
{ "TELEGRAM_TOKEN": "token dev" }
config/default.json
{ "TELEGRAM_TOKEN": "token prod" }
config/production.json
На практике, если в продакшене API-токен не меняется, вы можете обойтись одним конфигурационным файлом — например, только config/default.json.
Добавление функционала
Бот запущен и работает, но пока ничего не умеет делать. Поэтому нужно добавить первый функционал: научиться фильтровать голосовые сообщения и получать на них ссылки в формате ogg, а после конвертировать в mp3.
Последний шаг нужен, чтобы в дальнейшем переводить голосовые сообщения в текст через сервисы OpenAI. Они принимают на вход файлы формата ogg. Подробнее нюансы описаны на официальной странице.
Фильтрация голосовых сообщений
Отбирать голосовые сообщения можно с помощью встроенного фильтра Telegraph — message. Достаточно в качестве аргумента передать значение voice — и бот будет «считывать» голосовые сообщения.
import { Telegraf } from 'telegraf'
import { message } from 'telegraf/filters'
import { code } from 'telegraf/format'
import config from 'config'
import { ogg } from './ogg.js'
const bot = new Telegraf(config.get('TELEGRAM_BOT'))
bot.on(message('voice'), async (ctx) => {
try {
await ctx.reply(code('Сообщение принял. Жду ответ от сервера...'))
const link = await ctx.telegram.getFileLink(ctx.message.voice.file_id)
const userId = String(ctx.message.from.id)
const oggPath = await ogg.create(link.href, userId)
const mp3Path = await ogg.toMp3(oggPath, userId)
} catch (e) {
console.log(`Error while voice message`, e.message)
}
})
./src/main.js
Чтобы получить ссылку на голосовое сообщение, нужно передать в метод getFileLink специальный идентификатор.
Конвертация голосовых сообщений и получение ссылок в формате ogg
Чтобы обрабатывать и конвертировать полученные из getFileLink данные, создадим обработчик — например, ./src/ogg.js — и установим зависимости. А также создадим директорию для хранения голосовых.
npm i axios fluent-ffmpeg @ffmpeg-installer/ffmpeg
mkdir voices
touch voices/keep
Далее в ./src/ogg.js создадим объект OggConverter, который будет создавать ogg-записи и сохранять их в специальной директории.
import ffmpeg from 'fluent-ffmpeg'
import installer from '@ffmpeg-installer/ffmpeg'
class OggConverter {
constructor() {
ffmpeg.setFfmpegPath(installer.path)
}
toMp3(input, output) {
}
async create(url, filename) {
}
}
export const ogg = new OggConverter()
./src/ogg.js
В методе create мы сначала скачиваем ogg с серверов Telegram, а потом записываем их локально в файл через stream. Голосовой ogg-файл будет храниться в ./voices/${user id}.ogg.
import axios from 'axios'
import { createWriteStream } from 'fs'
import { dirname, resolve } from 'path'
import { fileURLToPath } from 'url'
const __dirname = dirname(fileURLToPath(import.meta.url))
// ====
async create(url, filename) {
try {
const oggPath = resolve(__dirname, '../voices', `${filename}.ogg`)
const response = await axios({
method: 'get',
url,
responseType: 'stream',
})
return new Promise((resolve) => {
const stream = createWriteStream(oggPath)
response.data.pipe(stream)
stream.on('finish', () => resolve(oggPath))
})
} catch (e) {
console.log('Error while creating ogg', e.message)
}
}
OggConverter.create ()
Дальше конвертируем ogg в mp3 с помощью функции toMp3. Выходной файл будет лежать по адресу: ./voices/${user id}.mp3
toMp3(input, output) {
try {
const outputPath = resolve(dirname(input), `${output}.mp3`)
return new Promise((resolve, reject) => {
ffmpeg(input)
.inputOption('-t 30')
.output(outputPath)
.on('end', () => resolve(outputPath))
.on('error', (err) => reject(err.message))
.run()
})
} catch (e) {
console.log('Error while creating mp3', e.message)
}
}
OggConverter.toMp3
Опционально. Чтобы после конвертации в mp3 файлы ogg удалялись, можно написать дополнительную утилиту.
import { unlink } from 'fs/promises'
export async function removeFile(path) {
try {
await unlink(path)
} catch (e) {
console.log('Error while removing file', e.message)
}
}
./src/utils.js
Голосовой чат с ChatGPT
Теперь давайте напишем основные функции для перевода mp3 в текст и работы с ChatGPT соответственно. Для этого нужно подключить API ChatGPT: установить библиотеки, сгенерировать и добавить в настройки приложения уникальный ключ.
npm i openai
Установка пакета openai.
https://platform.openai.com/account/api-keys
{
"TELEGRAM_TOKEN": "bot token",
"OPENAI_KEY": "open ai key"
}
./config/default.json
Для работы с API OpenAI создадим файл ./src/openai.js и опишем базовый класс. В его конструкторе создаем объект с конфигурациями, которые будут использоваться при отправке запросов на серверы OpenAI, и объект для подключения к API.
import { Configuration, OpenAIApi } from 'openai'
import config from 'config'
import { createReadStream } from 'fs'
class OpenAI {
roles = {
ASSISTANT: 'assistant',
USER: 'user',
SYSTEM: 'system',
}
constructor(apiKey) {
const configuration = new Configuration({
apiKey,
})
this.openai = new OpenAIApi(configuration)
}
async chat(messages) {
}
async transcription(filepath) {
}
}
export const openai = new OpenAI(config.get('OPENAI_KEY'))
./src/openai.js
Здесь roles — формат ролей, который принимает сервер openai. assistant — сообщения из gpt-чата; user — пользовательские сообщения; system — контекст для чата (например, «ChatGPT, веди себя как программист с многолетним стажем»).
Функция transcription отвечает за перевод mp3 в текстовые сообщения с помощью модели whisper-1. Притом она достаточно хорошо распознает русский язык.
async transcription(filepath) {
try {
const response = await this.openai.createTranscription(
createReadStream(filepath),
'whisper-1'
)
return response.data.text
} catch (e) {
console.log('Error while transcription', e.message)
}
}
OpenAI.transcription ()
Функция chat отвечает за самое главное — общение с ChatGPT на базе модели gpt-3.5-turbo. Четвертую модель можно использовать только по предварительно одобренной заявке.
async chat(messages) {
try {
const response = await this.openai.createChatCompletion({
model: 'gpt-3.5-turbo',
messages,
})
return response.data.choices[0].message
} catch (e) {
console.log('Error while gpt chat', e.message)
}
}
OpenAI.chat ()
Асинхронная функция chat принимает messages — массив объектов с сообщениями, ролями и именами отправителей. А после — возвращает данные из response, ответ ChatGPT.
Осталось только добавить вызовы функций OpenAI.transcription и OpenAI.chat из головного скрипта ./src/main.js.
import { openai } from './openai.js'
import { removeFile } from './utils.js'
// =====
bot.on(message('voice'), async (ctx) => {
try {
await ctx.reply(code('Сообщение принял. Жду ответ от сервера...'))
const link = await ctx.telegram.getFileLink(ctx.message.voice.file_id)
const userId = String(ctx.message.from.id)
const oggPath = await ogg.create(link.href, userId)
const mp3Path = await ogg.toMp3(oggPath, userId)
removeFile(oggPath)
const text = await openai.transcription(mp3Path)
await ctx.reply(code(`Ваш запрос: ${text}`))
const messages = [{role: openai.roles.USER, content: text}]
const response = await openai.chat(messages)
await ctx.reply(response.content)
} catch (e) {
console.error(`Error while proccessing voice message`, e.message)
}
})
src/main.js
Готово — бот «понимает» голосовые сообщения и умеет отвечать на них текстом. Но это еще не все: сейчас бот не сохраняет контекст общения, не запоминает предыдущие ответы и запросы. Он работает как друг, которому все равно, что вы ему рассказывали в прошлом.
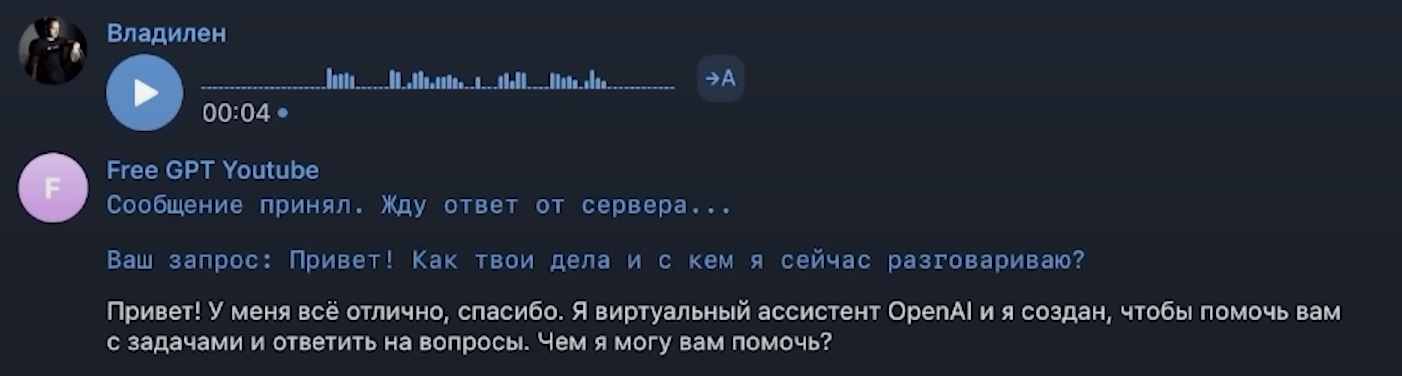
Тестирование функции OpenAI.chat (). Запись голоса доступна по ссылке.
Сохранение данных сессии
Осталось переписать код так, чтобы сообщения и их контексты сохранялись для каждого пользователя. Подробнее в комментариях к коду.
// импортируем вместе с Telegraf пакет session
import { Telegraf, session } from 'telegraf'
import { initCommand, processTextToChat, INITIAL_SESSION } from './logic.js'
// ======
const bot = new Telegraf(config.get('TELEGRAM_TOKEN'))
// говорим боту, чтобы он использовал session
bot.use(session())
// при вызове команды new и start бот регистрирует новую беседу,
// новый контекст
bot.command('new', initCommand)
bot.command('start', initCommand)
bot.on(message('voice'), async (ctx) => {
// если сессия не определилась, создаем новую
ctx.session ??= INITIAL_SESSION
try {
await ctx.reply(code('Сообщение принял. Жду ответ от сервера...'))
const link = await ctx.telegram.getFileLink(ctx.message.voice.file_id)
const userId = String(ctx.message.from.id)
const oggPath = await ogg.create(link.href, userId)
const mp3Path = await ogg.toMp3(oggPath, userId)
removeFile(oggPath)
const text = await openai.transcription(mp3Path)
await ctx.reply(code(`Ваш запрос: ${text}`))
await processTextToChat(ctx, text)
} catch (e) {
console.log(`Error while voice message`, e.message)
}
})
./src/main.js
import { openai } from './openai.js'
export const INITIAL_SESSION = {
messages: [],
}
export async function initCommand(ctx) {
ctx.session = INITIAL_SESSION
await ctx.reply('Жду вашего голосового или текстового сообщения')
}
export async function processTextToChat(ctx, content) {
try {
// пушим сообщения пользователя в сессию (в контекст)
ctx.session.messages.push({ role: openai.roles.USER, content })
// пушим сообщения бота в сессию (в контекст)
const response = await openai.chat(ctx.session.messages)
ctx.session.messages.push({
role: openai.roles.ASSISTANT,
content: response.content,
})
await ctx.reply(response.content)
} catch (e) {
console.log('Error while proccesing text to gpt', e.message)
}
}
./src/openai.js
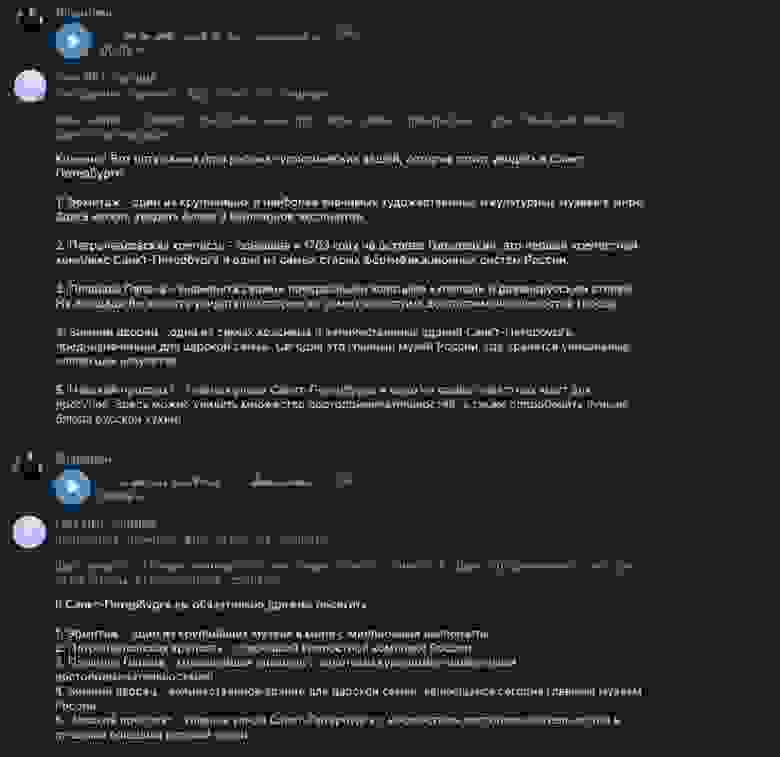
Бот сохраняет контекст общения до тех пор, пока вы не сделаете новую сессию.
Текстовый чат с ChatGPT
Бот умеет отвечать на голосовые сообщения и сохранять результаты в сессию. Давайте не будем ограничивать пользователей без микрофона и добавим обработку текстовых запросов. Для этого нужно просто обработать через фильтр сообщения с типом text и передать значение напрямую в ChatGPT.
bot.on(message('text'), async (ctx) => {
ctx.session ??= INITIAL_SESSION
try {
await ctx.reply(code('Сообщение принял. Жду ответ от сервера...'))
await processTextToChat(ctx, ctx.message.text)
} catch (e) {
console.log(`Error while voice message`, e.message)
}
})
./src/logic.js

Деплой бота на облачный сервер
Все готово, но есть проблема: программа запущена на компьютере. Это неудобно, если вы хотите обеспечить круглосуточную работу бота. Ведь тогда нужно поддерживать бесперебойную работу компьютера и постоянное соединение с интернетом. Поэтому лучше перенести бота в облако — это сделать довольно просто.
Подготовка контейнера
Чтобы задеплоить бота на сервер, сначала нужно создать Dockerfile, который будет описывать процесс сборки приложения в контейнер. А для автоматизации команд docker build и docker run можно завести Makefile.
FROM node:16-alpine
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ENV PORT=3000
EXPOSE $PORT
CMD ["npm", "start"]
Dockerfile
build:
docker build -t tgbot .
run:
docker run -d -p 3000:3000 --name tgbot --rm tgbot
Makefile
Теперь для запуска приложения на сервере будет достаточно написать команду make run.
Запуск сервера и загрузка бота
Поскольку бот работает с ChatGPT через API и потребление вычислительных ресурсов минимально, для деплоя подойдет сервер линейки Shared Line. Это линейка облачных серверов с возможностью оплаты только части ядра, например 10, 20 или 50%. Shared Line позволяет использовать все преимущества облака и не переплачивать за неиспользуемые ресурсы.
Для начала зарегистрируемся в панели управления и создадим новый сервер в разделе Облачная платформа. Затем — настроим его.
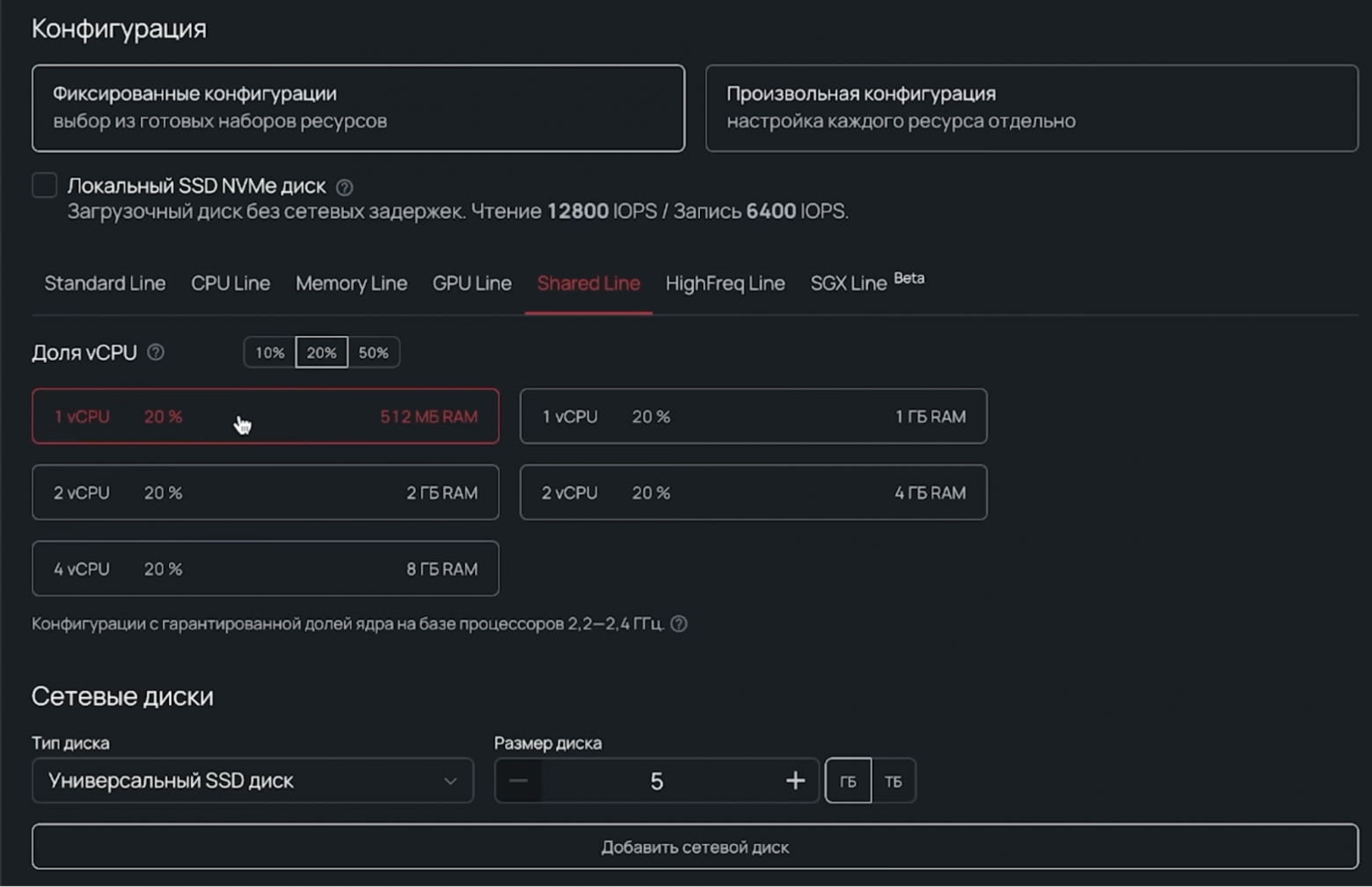
Боту подойдет ОС Ubuntu 22.04 LTS, 1 виртуальных ядра с минимальной границей в 20% процессорного времени, 512 МБ оперативной памяти, а также 5 ГБ на сетевом диске (базовый HDD). С учетом новой публичной подсети (/29, 5 адресов IPv4) такая конфигурация выйдет примерно в 41 ₽/день.
Далее устанавливаем на сервер Docker согласно инструкции, git и клонируем репозиторий с проектом. Проверяем конфигурации и API-ключи, собираем образ через make build и запускаем c помощью make run!
Пример работы бота.
Супер — бот работает! Дальше вы можете внедрить свой функционал. Например, по сохранению диалога с ботом и выводу истории запросов.
Как мы видим, в разработке подобных Telegram-ботов нет ничего сложного. Тем более для хостинга такого проекта не нужно платить полную стоимость сервера: ресурсы оплачиваются по модели pay-as-you-go. Видеоверсия инструкции доступна по ссылке.
