Как не проиграть с производительностью в длительном скроллинге

Привет, хабр!
Меня зовут Михаил Кириченко. Я разрабатываю клиентскую часть в компании Bimeister.
В этой статье хочу поделиться своим опытом и практиками, которые мне приходилось применять в своей работе, а главное, ответить на вопрос: как лучше подходить к построению интерфейсов, чтобы не проиграть с производительностью при скроллинге.
Отмечу, что я не буду детально рассматривать описанные мной подходы и показывать примеры кода, иначе я буду размышлять об избитых темах. Любопытный читатель сможет быстро найти всю необходимую информацию во всемирной паутине, если будет такая необходимость. Моя цель — предоставить вам идеи и мысли в описательно-пояснительном ключе.
Вместо введения
В современных приложениях используются очень насыщенные интерфейсы с большим количеством элементов на странице. Рендеринг такого объема данных влечет за собой наличие громоздкого DOM-дерева, что является одной из основных причин тормозов на сайте. Если изучить вопрос как браузер рендерит страницу, то становится понятно, что чем больше дерево, тем больше ресурсов требуется механизмам repaint и reflow. Процитирую информацию с официального сайта Google, который призван помогать веб-разработчикам делать продвинутые интерфейсы
Разработчики браузеров рекомендуют, чтобы страницы содержали менее 1500 узлов DOM. Рекомендация — это глубина дерева < 32 элемента и менее 60 дочерних/родительских элементов. Большой DOM может увеличить использование памяти, вызвать более длительные вычисления стилей и привести к дорогостоящим перекомпоновкам layout.
Итак, имеем промежуточный вывод: нужно трепетно следить за размером DOM-дерева. Одним из немногих выходов из этой ситуации является использование пагинации. Понятно, что самый простой случай — это использовать пагинацию на кнопках. Если на вашем проекте этот способ рабочий, с ним согласны дизайнеры, тогда считайте, что вам повезло. Однако на практике дела обстоят иначе. Дизайнеры не хотят использовать кнопки для этих целей. Как минимум потому что теряется контекст и приходится постоянно возвращаться к предыдущим страницам, чтобы вспомнить что же там было. Современный веб-дизайн предполагает бесконечную прокрутку, потому что это более естественный сценарий взаимодействия с интерфейсом. В самом деле, одним из самых популярных действий пользователя на сайте является скролл.
Стандартными решениями являются виртуальный и бесконечный скроллинг. Ниже мы сравним эти подходы, чтобы понять их сильные и слабые стороны. Далее я продемонстрирую умный бесконечный скроллинг, который может помочь вам спроектировать более производительный интерфейс.
Виртуальный скроллинг
Идея виртуального скроллинга состоит в том, чтобы отображать только те элементы в списке, которые непосредственно видны на экране. Тем самым не важно, какой длины у вас список, в DOM-дереве у вас находятся только элементы в зоне видимости.
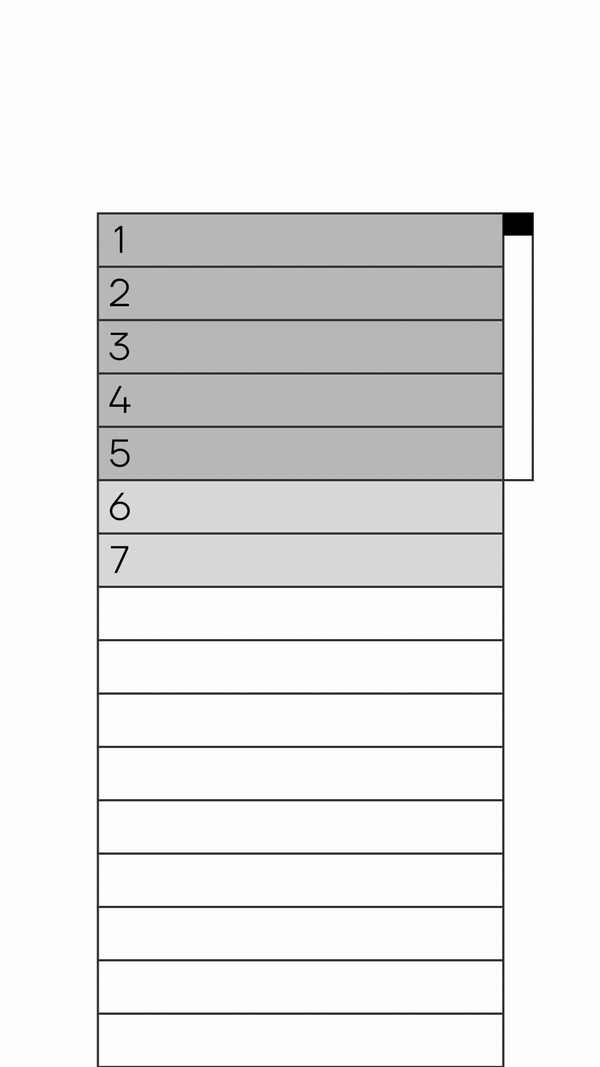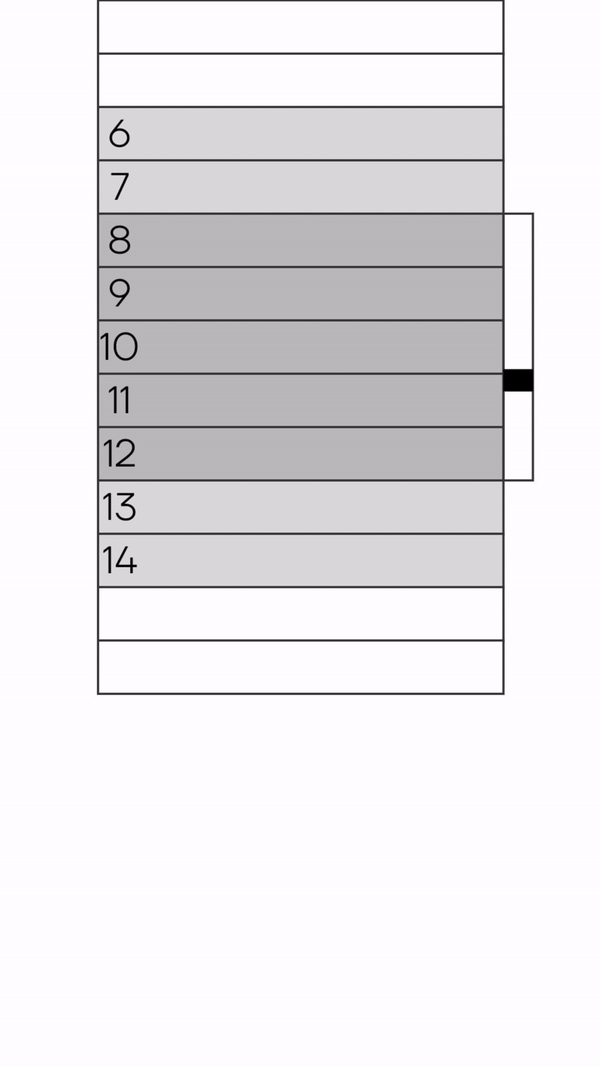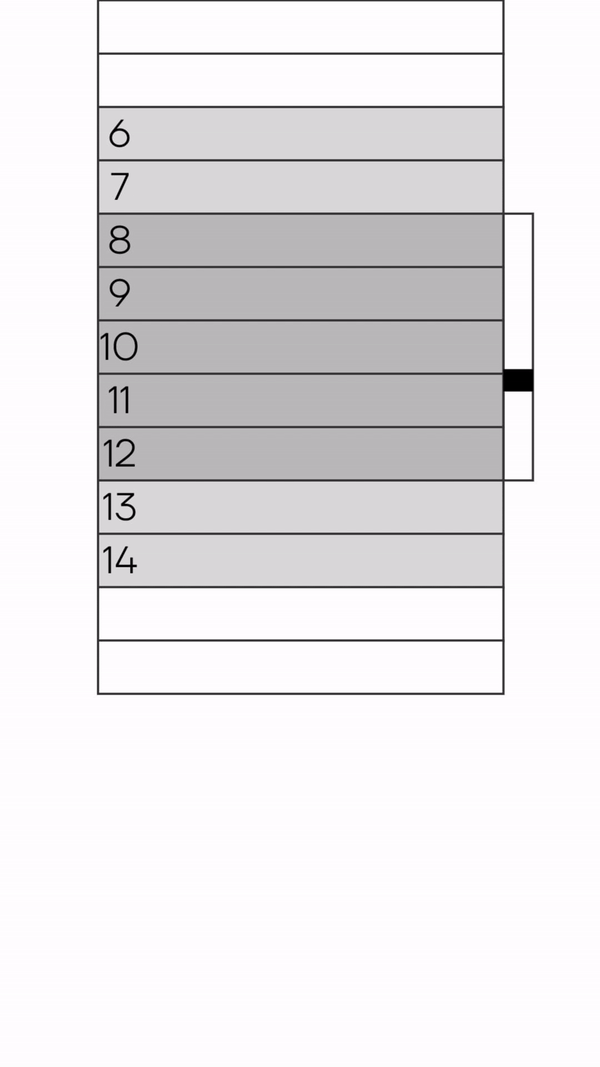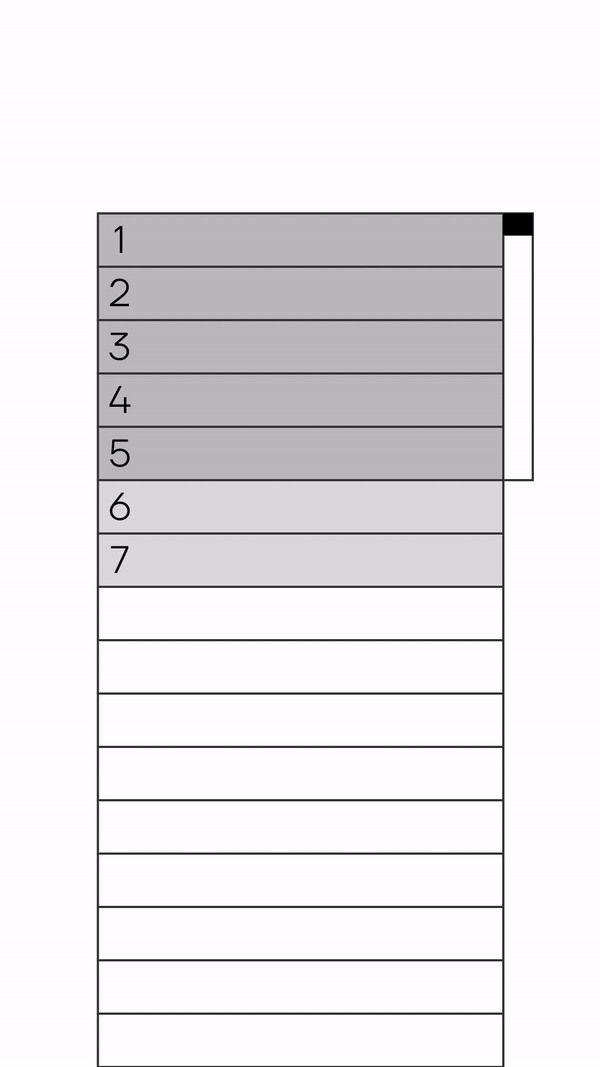 Virtual Scrolling
Virtual Scrolling
Виртуальный скроллинг добавляет слайсы данных с одной стороны, а также убирает данные с другой. Чтобы это работало — размеры элементов должны быть предсказуемы. Однако обычно нам это неизвестно, поэтому мы начинаем просить дизайнера рисовать карточки равной размерности, чтобы мы могли применить данный подход.
Если размеры элементов известны/предсказуемы, то это, наверное, лучший способ вывода списков. Примеры, когда размеры действительно можно предугадать:
Календарь. Размер каждого месяца любого года можно рассчитать.
PDF-документ. Формат PDF сразу в себе имеет необходимую мета-информацию, в которой числятся все размеры входящих страниц.
Также несомненным плюсом данного подхода является честный скроллбар. Его высота показывает сколько действительно данных находится в этом списке, а также позволяет сразу переместиться в любое место списка.
Итого:
Размеры элементов должны быть предсказуемы ➖
Честный скроллбар ➕
Отображается только то, что в зоне видимости ➕
Бесконечный скроллинг
Наверное, это самый популярный подход к скроллингу на данный момент. Идея заключается в следующем: каждый следующий слайс данных грузится, как только подошли к концу списка.
 Infinity Scrolling
Infinity Scrolling
В данном подходе нам не важен размер элементов — мы можем рендерить элементы любой размерности. Казалось бы, дизайнеры счастливы, поэтому можно смело внедрять его в свой проект. Но не торопитесь.
В данном подходе мы никак не удаляем из DOM-дерева элементы, которые уже не видны. Поэтому, если немного постараться и поскроллить относительное время, можно перенагрузить дерево. Страница станет тормозить, а в худшем случае браузер попросит ее закрыть.
К тому же, если у нас динамически меняются данные, то придётся заново загружать элементы, вне зависимости от их попадания в область видимости и позиции скроллбара. Что несомненно вызовет рекалькуляцию дерева и уменьшит производительность.
В данном подходе мы имеем нечестный скроллбар. Он не показывает действительное количество элементов в списке, а также у пользователя нет возможности потянуть за ползунок и переместиться в любое место.
Итого:
Размеры элементов могут быть любые ➕
Нечестный скроллбар ➖
Элементы не исчезают из DOM-дерева, если они уже не видны ➖
Что же делать? Умный подход к бесконечному скроллингу
У двух вышеописанных подходов есть свои плюсы и минусы. Предлагаю объединить все лучшее из них, чтобы создать новый скроллинг, который не будет иметь проблем с производительностью, а также позволит нам не задумываться о размерах элементов списка.
Общаясь в одном популярном мессенджере, я обратил внимание как сделан скроллинг. При изучении веб-версии мне удалось обнаружить:
Сообщения в ленте разной размерности. Что логично.
Сообщения подгружаются через бесконечный скроллинг.
Как бы долго я не скроллил, проблем с производительностью не было обнаружено.
И вот почему. Пока ты скроллишь и подгружаешь новые слайсы данных, уменьшается ползунок скроллбара. Но в какой-то момент ползунок скроллбара снова увеличился. Это означает, что раннее загруженные данные были выкинуты из памяти и из DOM-дерева.
Данный подход к скроллингу мне удалось объяснить следующим образом: это обычный бесконечный скроллинг, который подгружает данные. В данном скроллинге мы имеем некоторое значение буфера, например, 500 элементов. Как только мы пересекаем это значение — то выкидываем лишнее из памяти. Значение буфера достаточное, чтобы точно удостовериться, что элементы, которые мы будем выкидывать, точно не видно. Нам все известно, чтобы понять с какой стороны списка выкидывать элементы. Если скроллили вниз — выкидываем сверху. Если скроллили вверх — снизу.
Я буду псевдокодом показывать примерную имплементацию данного скроллинга на Angular-е. Такой механизм можно воспроизвести на любом фреймворке, если понятна сама идея.
Для начала необходимо переконструировать привычный бесконечный скроллинг, так чтобы он мог подгружать данные сверху и снизу. Сделать это можно через якоря и IntersectionObserver. Проектируем infinityScrollComponent. Вот как будет выглядеть его шаблон:
Как только якорь появился в области видимости — отображаем следующий слайс. При желании якорем может быть любой элемент, например, это может быть спиннер, который будет демонстрировать пользователю, что данные грузятся.
Также в данном компоненте мы следим за скроллом: его позицией, направлением и за всем тем, что нам может помочь в принятии решений. Как за этим можно следить — я оставляю за рамками.
Как будет выглядеть использование компонента снаружи:
Some Item {{ item.name }}
На вход мы передаем контроллер. Контроллер — это единственный источник принятия решений. Вся бизнес-логика будет обрабатываться там, что позволяет нам сделать наш компонент максимально прозрачным. В таком случае, наш компонент просто рендерит список и сообщает, что с ним происходит: какое состояние скроллбара, направление скролла, сколько элементов отображается и т.д. Что именно будет рендериться в DOM-дереве мы передаем через директиву. Компонент внутри себя следит за этой директивой, забирает темплейт и отображает в нужном месте.
Обработка событий может выглядеть следующим образом:
enum ScrollMoveDirection {
FromTopToBottom,
FromBottomToTop,
}
interface SomeItem {
id: string;
name: string;
}
@Component()
export class ClientScrollerComponent {
/**
* Создаем контроллер.Передаем настройки взаимодействия.
* Поле scrollMoveDirection отвечает за направление изначального скролинга.
* По умолчанию значение FromTopToBottom.
*
* Поле useBuffer отвечает за то использовать buffer или нет.
* Если буффер не используется, то компонент работает как обычный скролбар.
*
* Поле trackBy поможет ангуляру понять, какие именно элементы подлежат ререндрингу.
*
* А также еще много опций здесь может передаваться в зависмости от вашей логики.
*/
public readonly controller: InfinityScrollerController = new InfinityScrollerController({
scrollMoveDirection: ScrollMoveDirection.FromBottomToTop,
useBuffer: true,
trackBy: (_: number, item: SomeItem) => item.id,
/**
* Здесь можно прокинуть еще много опций конфигурации.
* Ограничиваясь, лишь вашей логикой использования.
* Например, pullToRefresh. Или кастомную стратегию буферизации.
*/
});
private getNextPageHandler(): Subscription {
return this.controller
.getEvents(InfinityScrollerEvents.GetNextPage)
.subscribe((event: InfinityScrollerEvents.GetNextPage) => {
/**
* Здесь логика дозапроса следующего слайса.
* Когда дозапросили -- необходимо заново положить данные.
*/
this.controller.setData(data);
});
}
private getPrevPageHandler(): Subscription {
return this.controller
.getEvents(InfinityScrollerEvents.GetPrevPage)
.subscribe((event: InfinityScrollerEvents.GetPrevPage) => {
/**
* Здесь логика дозапроса предыдущего слайса. Когда дозапросили -- необходимо заново положить данные.
* Соответственно, если использовать скроллинг без буфера, то это событие не будет приходить.
* Ведь мы ничего не выкидываем из данных.
*/
this.controller.setData(data);
});
}
private applyBufferContaining(): Subscription {
return this.controller
.getEvents(InfinityScrollerEvents.BufferFull)
.subscribe((event: InfinityScrollerEvents.BufferFull) => {
/**
* Здесь логика урезки данных. В событии может приходить сопутствующая информация.
* Например, с какой стороны резать данные: сверху или снизу.
*/
this.controller.setData(data);
});
}
}Здесь создается контроллер, в который прокидываются все необходимые конфигурации. И для примера реализации приведены хендлеры getNextPageHandler, getPrevPageHandler и applyBufferContaining. Работают они на принципе получения событий из контроллера. Контроллер посылает события, которые можно обработать через метод getEvents(…). Хендлеры обрабатывают события и дозапрашивают данные. Их основная цель — это передать новые элементы через метод setData(…), доступным в контроллере.
Вот как может выглядеть примерная реализация контроллера:
export class InfinityScrollerController {
/**
* EventBus -- класс для передачи/получения событий.
*/
public readonly eventBus: EventBus = new EventBus();
/**
* Необходимые мета-данные:
* направление скрола, размер буфера, данные, общее количество данных,
* функиция трекинга и многие другие
*/
public readonly scrollMoveDirection: ScrollMoveDirection;
public readonly bufferSize: number | null;
public readonly data$: BehaviorSubject = new BehaviorSubject([]);
public readonly totalCount$: BehaviorSubject = new BehaviorSubject(0);
public readonly trackBy$: BehaviorSubject> = new BehaviorSubject>(
InfinityScrollerController.trackBy
);
constructor(config: InfinityScrollerOptions) {
/**
* Здесь обрабатываем переданные конфигурации.
* Сохраняем их для дальнешего использования.
*/
}
public handleTopAnchorIntersect(): void {
/**
* Здесь обрабытываем, когда нижний якорь показался в зоне видимости.
* То есть обрабатываем сценарий дозапроса данных снизу.
* Отправляем событие, по которому можно выполнить дозагрузку данных.
*/
this.eventBus.dispatch(InfinityScrollerEvents.GetNextPage);
}
public handleBottomAnchorIntersect(): void {
/**
* Здесь обрабытываем, когда верхний якорь показался в зоне видимости.
* То есть обрабатываем сценарий дозапроса данных сверху.
* Отправляем событие, по которому можно выполнить дозагрузку данных.
*/
this.eventBus.dispatch(InfinityScrollerEvents.GetPrevPage);
}
public setData(data: T[]): void {
/**
* Здесь обновляем данные в data$.
* Также именно здесь можно проверять переполнение буфера
* и соответственно резать данные.
*/
}
public getEvent(eventType: Type): Observable {
/** Метод позволяет отлавливать события снаружи. */
}
} Стоит немного остановиться на объяснении класса EventBus. Это класс-хелпер, который позволяет манипулировать событиями: отправлять и слушать. Можете относиться к этому классу следующем образом: он просто содержит Subject, который кеширует последнее событие.
private readonly event$: Subject = new Subject(); Также этот класс имеет вспомогательные методы, которые позволяют отправлять событие и слушать его появление.
Сам контроллер можно положить рядом с компонентом infinityScrollerComponent. По реализации видно, что контроллер создается на месте использования компонента. А это означает, что мы имеем гибкий подход: мы можем передавать на вход компоненту любой свой кастомный контроллер, который будет обрабатывать скролл на свое усмотрение. Если коротко, получили расширяемость и переиспользуемость. Схематично это выглядит так:
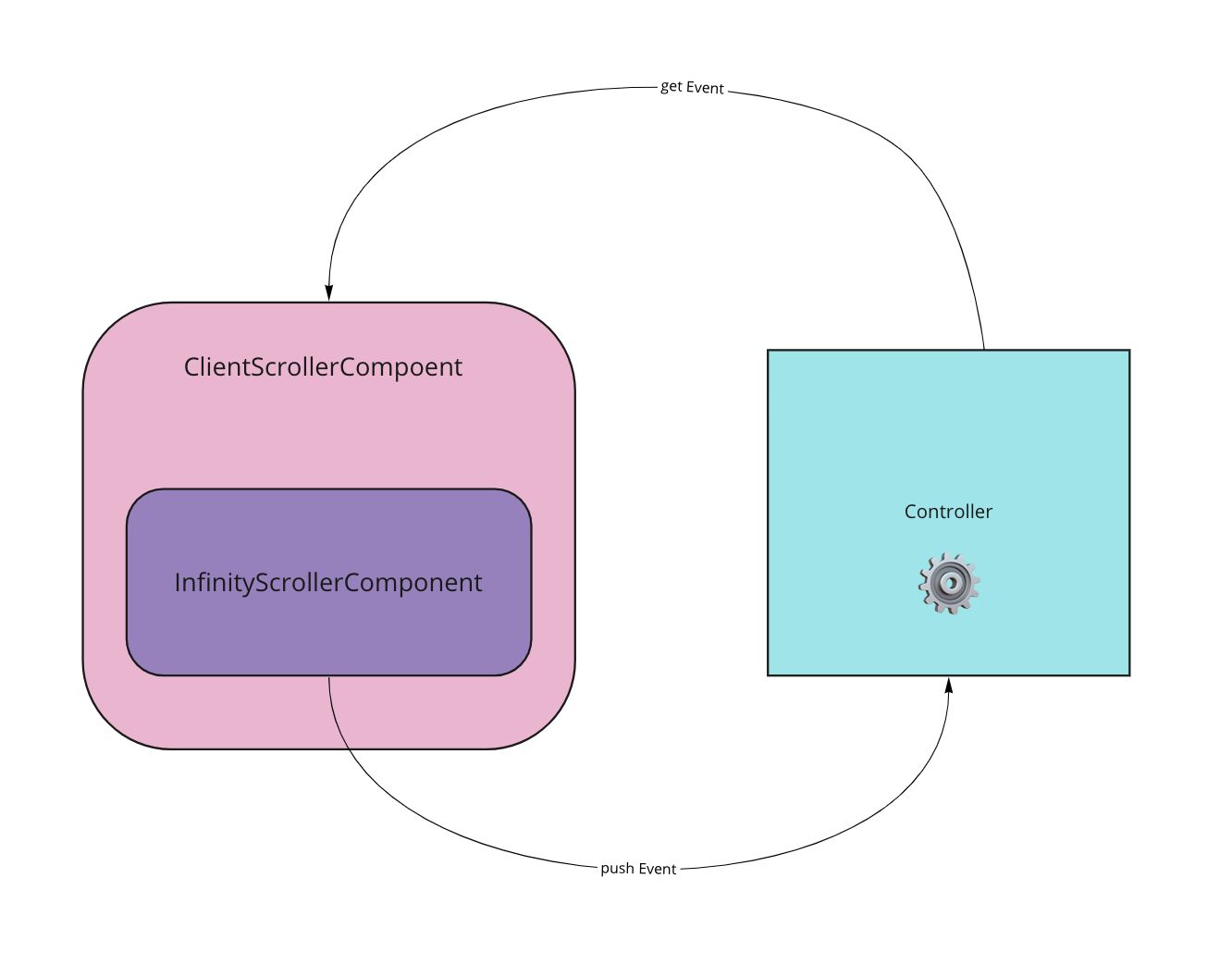
Что стоит учитывать: привязка скролла
Когда подгружаешь данные через бесконечный скроллинг снизу, то визуально позиция контента не меняется. Ползунок скроллбара автоматически отпрыгивает в нужное место. Это происходит из-за CSS-свойства overflow-anchor: auto;. Данное свойство включено по умолчанию почти во всех популярных браузерах, оно позволяет привязать скролл к якорному элементу. Вот пример, который поможет вам понять, как работает это свойство.
Важно заметить, что привязке скролла могут препятствовать другие CSS-свойства, которые могут влиять на положение и размеры элемента: top, left, right, bottom, margin, padding, transform.
Если подгружать данные сверху, то такой трюк перестает работать. Поэтому необходимо закешировать позицию скроллбара и при появлении новых данных подскроллить к этой позиции.
const scrollHeight: number = this.scrollable.element.scrollHeight;
const newScrollTop: number = scrollHeight - cacheContentHeight;
this.scrollable.setScrollTop(newScrollTop);Оптимизации
Так как внутри скроллящейся области мы постоянно меняем контент, что приводит к изменению DOM, то браузеру приходится пересчитывать layout. Это является дорогостоящей операцией. Чтобы помочь браузеру в расчетах, можно добавить CSS-свойство contain: content;, которое сообщает браузеру, что скроллящийся блок и все его содержимое не влияет на внешние слои и их компоновку.
Также имеет смысл вынести все содержимое скроллящегося контейнера в отдельный слой, чтобы компоновка и перерасчет стилей был отделен от основного потока. Сделать это можно следующим образом.
transform: translateZ(0);
will-change: transform;CSS-свойство will-change: transform; позволяет нам дать рекомендацию браузеру, что «тут будет часто меняться позиционирование, имеет смысл вынести все в отдельный слой».
Промежуточный итог
Конечно, не обошлось без жертв. В данном подходе не удалось сохранить честный скроллбар, то есть нельзя будет потянуть за ползунок и переместиться в любое место списка. Важно это или нет — зависит от того как к этому относиться. Скорее всего, если пользователь скроллит весь список целиком или ему важно через ползунок перемещаться в любое место, то вы спроектировали интерфейс неправильно. Вам стоит подумать над тем, как организовать фильтрацию таким образом, чтобы нужные элементы были в поисковой выдаче как можно раньше.
Теперь у нас нет проблем с производительностью, ведь элементы удаляются из DOM-дерева. А также мы можем отображать любой контент любой размерности. Дизайнеры довольны.
Кроме оптимизации потребления памяти, мы получили преимущество в передаваемых данных по сети, ведь если нам надо будет обновить список, то мы обновим лишь необходимую видимую часть. Грузить весь список целиком до нужного слайса не придется, как это было с обычным бесконечным скроллингом. Поэтому батарейки на мобильных устройствах будут вам благодарны.
Будьте аккуратны при выборе размера буфера: он должен быть таким, чтобы данные точно смогли бы перекрыть область видимости. Например, если область просмотра 600px по высоте при вертикальном скролле, элементы высотой 10-20px, а буфер равен 50, то данные точно не перекроют всю область. Будут дырки, которые пагубно влияют на отзывчивость интерфейса. Но это решаемая проблема.
Я лишь для демонстрации своей идеи предложил зафиксировать буфер. Конечно, так делать не стоит. Лучше всего сделать его динамическим. Компонент, который выводит элементы списка, можно сказать, знает о них все, что требуется. Чтобы динамически выставлять значение буфера, надо следить за общей габаритной высотой элементов списка и сравнивать ее с высотой области видимости, чтобы гарантировано ее перекрывать. Также следует не забывать, что пользователь может изменять размеры экрана, поэтому вычисления надо будет повторить при ресайзе.
Итого:
Размеры элементов могут быть любые ➕
Нечестный скроллбар ➖
Элементы, которое не входят в значения буфера, удаляются из DOM ➕
Доступность
Используйте данный вид скроллинга осознанно. Только для тех мест, где он действительно пригоден. Есть несколько проблем, которые стоит учитывать при проектировании интерфейса.
Поиск по странице через комбинацию ctrl + f. Так как мы грузим данные по слайсам, то у нас нет всех данных, чтобы браузер смог найти совпадения. Но это решаемая проблема. Необходимо перехватить комбинацию клавиш и обработать до того момента, пока это сделал браузер. Дальше — дело техники.
Стоит учитывать, что вашим сайтом могут пользоваться слабовидящие пользователи. Они пользуются страницей через переключение фокуса. Проблема настанет, когда фокус оказался на последнем элементе списка, а новый слайс еще не загружен. В таком случае скрин-реадер просто скажет, что страница закончена, хотя, это не так. Поэтому важно отображать чуть больше, чем умещается в области видимости. Тогда при переключении фокуса будет немножко скроллиться контент, а значит, будет отрабатывать наша логика подгрузки данных.
Если пользователи захотят распечатать страницу, то у них отобразиться только тот слайс, который был загружен. Как с этим быть решайте сами. Например, можно перехватить событие печати и загрузить все данные в DOM-дерево, тогда на печать будет выводиться весь контент.
Выводы
В данной статье был продемонстрирован новый подход к построению интерфейсов благодаря использованию умного бесконечного скроллинга. Бесконечный скроллинг с буфером позволяет отображать списки любой размерности и не засоряет DOM-дерево.
Данный вид скроллинга полезен для того контента, где заранее нельзя предугадать размеры элементов. Например, это могут быть чаты или ленты новостей.
И, конечно же, какой именно скроллинг подходит именно вашему продукту — решайте сами. Но не забывайте следить за размером DOM-дерева, чтобы не проиграть с производительностью! Буферный умный скроллинг может помочь вам выиграть.
