Как научить веб-приложение говорить на 100 языках: особенности локализации

Ключевой особенностью онлайн-сервисов является то, что к ним имеют доступ пользователи практически со всего мира, говорящие на разных языках. Если вы разрабатываете такой сервис и хотите, чтобы им могли пользоваться люди из разных стран, то вам нужно его перевести и адаптировать, иными словами — локализовать.
Идея написания этой статьи возникла после MoscowJS митапа, на котором я говорил о том, как происходит процесс локализации в компании Badoo. Но в этой статье я бы хотел рассказать немного подробнее об особенностях локализации на примере веб-приложений, о том, какие существуют решения для локализации и почему в Badoo пошли своим путем. Всем неравнодушным — добро пожаловать под кат.
Зачем и почему?
Если вы ориентируетесь только на российский рынок, то, скорее всего, локализация вам никогда не понадобится, или как минимум не понадобится до тех пор, пока ваш продукт не станет интересен международной аудитории. Тогда придется очень быстро адаптировать ваше приложение к новым реалиям, а это не так уж и просто. Поэтому стоит сразу определиться и ответить на вопрос: а нужна ли вам вообще локализация? Если вы склоняетесь к положительному ответу, то ваш сервис необходимо будет подготовить к различным языковым особенностям. В целом приемы и инструменты, которые позволяют учесть такие особенности, называются интернационализацией, что есть процесс создания приложения, которое может работать на различных языках и с различными региональными особенностями без каких-либо дополнительных изменений.

Следующий вопрос, на который нужно дать ответ: почему локализация важна? А важна она в первую очередь для пользователей и клиентов, ведь каждый из них должен чувствовать себя комфортно, используя ваше приложение. Например, резиденты какой-либо страны, даже если они хорошо знают английский язык, предпочитают совершать покупки на родном языке. Большинство из них также предпочитает пользоваться услугами службы поддержки на родном языке. Если мы возьмем Европу, в которой порядка 50 стран, то практически у каждой из них будут свои региональные особенности по отображению дат, чисел или валюты. А если мы расширим нашу аудиторию на весь мир, то появляются такие страны, как Китай, Иран, Афганистан или Саудовская Аравия, в которых запись текста идет справа налево или сверху вниз, а сами числа записываются с помощью индо-арабских или персидских цифр.
Особенности языков
На какие особенности языка стоит обратить внимание в первую очередь, если принято решение внедрять локализацию? В первую очередь стоит обратить внимание на отображение даты и времени в привычном для них формате. В нижеследующей таблице отображены несколько зависимостей формата от страны. Как вы видите, в большинстве стран формат разный.
| Формат | Пример даты | Страна |
|---|---|---|
| гггг.ММ.дд | 2016.09.22 | Венгрия |
| гггг-ММ-дд | 2016–09–22 | Польша, Швеция, Литва, Канада |
| гггг/ММ/дд | 2016/09/22 | Иран, Япония |
| дд.ММ.гггг | 22.09.2016 | Россия, Словения, Турция, Украина |
| М/д/гггг | 9/22/2016 | США |
Следующей особенностью является формат чисел и отображение валюты. Как видно из таблицы ниже, тысячный и десятичный разделитель может выглядеть как запятая, точка или пробельный символ. А положение знака валюты может отличаться не только в разных языках, но и в разных странах. Например, такие страны, как Германия и Австрия, говорят на одном языке, но денежный формат имеют разный.
| Пример | Локаль | Страна |
|---|---|---|
| 123 456,79 € | ru-RU | Россия |
| €123,456.79 | en-US | США |
| 123.456,79 € | de-DE | Германия |
| € 123 456,79 | de-AT | Австрия |
Кроме того, проблемой может стать английская система мер, которая используется в США, Мьянме и Либерии. Почему это важно: стоит вспомнить спутник «Марс климат орбитер», который подлетел к Марсу и упал на него, так как команды на космическом оборудовании использовали силу в ньютонах, а программное обеспечение на Земле — фунт-силах. За все время полета никто не заподозрил ошибку. В итоге она стоила $ 125 млн. Так что не забывайте отображать результаты в привычных для пользователей мерах.
Когда с форматом дат и чисел разобрались, можно переходить к особенностям переводов. И самая очевидная проблема — это склонение существительных после числительных. Как мы знаем, в русском языке существует три формы множественного числа (plural forms), в то же время в английском их всего две. Но существуют языки, в которых таких форм может быть шесть. Например, по этой ссылке вы найдете таблицу форм для каждого языка.
| Русский язык | Английский язык | |
|---|---|---|
| У вас 1 подарок | Singular | You have 1 gift |
| У вас 5 подарков | Plural | You have 5 gifts |
| У вас 2 подарка | Few |
1. Переводить фразы и предложения целиком. Их нельзя делить на составляющие, так как последовательность слов в разных языках может быть разной.
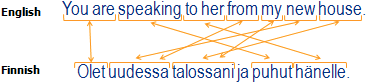
Например, возьмем такую фразу: 8,283 out of 15,311 people liked you!
Для английского языка она выглядит следующим образом:
{{num_voters_yes_maybe}} out of {{num_voters_total}} {{people}} liked you!А вот в японском это же предложение уже выглядит иным образом:
{{num_voters_total}}{{people}}中{{num_voters_yes_maybe}}人があなたを気に入っています!Как видно из этого примера, в японском языке обратная последовательность слов. Поэтому, как часто многие делают, нельзя просто так написать
'Страница ' + pageNum + ' из ' + total2. Некоторые переводы отличаются в зависимости от пола человека.
Как видно из примера ниже, если для английского языка можно указать одну фразу как для мужского, так и для женского пола, то в словацком языке для каждого пола будет своя фраза.
Английский
You got an award on {{award_date}}Словацкий
М: Toto ocenenie si získal {{award_date}}
Ж: Toto ocenenie si získala {{award_date}}3. Перевод строк должен зависеть от контекста. Переводчик должен знать смысл всего предложения, фразы или абзаца, иначе он может неправильно понять и некорректно перевести. Например, такое предложение как »You can save this {{item}}» может иметь различный перевод:»Вы можете спасти/сохранить этот {{item}})». В идеале переводчик не только должен видеть набор строк для перевода, но и изображение области, где данная строка находится.
4. Повторное использование ресурсов перевода может быть небезопасным. Например, «Сохранить» (файл) и «Сохранить» (настройки) в некоторых языках могут иметь разные названия. Или такое слово как thread может быть переведено как «поток», а может быть переведено как «нить».
Вот, пожалуй, мы определили наиболее популярные особенности, которые встречаются при локализации веб-приложений. Но это еще далеко не все, что может затрагивать локализация, потому что сюда можно отнести и особенности дизайна (например, японский и китайский требует увеличенного шрифта, в некоторых языках длина текста будет в 2 раза больше, чем, например, в английском); цветовую палитру (красный и зеленый цвет в разных культурах означают противоположные вещи, например, красная галочка в японском означает, что вы сделали что-то не так); используемые изображения (да-да, в Азии неплохо бы показывать азиатов, а в Европе — европейцев) и многие другие аспекты, которые характерны для той или иной страны и культуры. Все это выходит уже за рамки статьи, но об этом стоить помнить.
А теперь заглянем в интернет и посмотрим, а какие существуют инструменты для клиентской локализации?
Способы локализации на клиенте
Развитие интерфейсов и внедрение сложной бизнес-логики уже требовало от разработчиков решать многие проблемы локализации на клиенте. Возможности интернационализации, которые до определенного момента предоставлял ECMAScript, были достаточно скудными, поэтому стали появляться библиотеки, такие как Closure, Globalize, YUI, Moment.js или же какие-то собственные решения у каждого из разработчиков. Все они расширяли возможности ECMAScript и заполняли пробелы в интернационализации, но решения имели различный программный интерфейс и определенные ограничения, связанные, например, со сравнением строк. Так, в декабре 2012 года, появился стандарт ECMA-402, который должен был упростить жизнь фронтенд-разработчикам при интернационализации приложений. Но действительно ли это так? Давайте посмотрим, что сейчас предлагает нам этот стандарт.
ECMAScript Internationalization API
Это стандарт, который описывает программный интерфейс ECMAScript для адаптации к лингвистическим и культурным особенностям языков или стран. Работа происходит через объект Intl, который предоставляет функции форматирования чисел (Intl.NumberFormat), дат (Intl.DateTimeFormat) и сравнения строк (Intl.Collator). На данный момент поддерживается всеми современными браузерами. Последний браузер, который недавно добавил поддержку, был Safari, для устаревших браузеров можно использовать полифилл.
Большой плюс этого стандарта в том, что его разрабатывали при поддержке Google, Microsoft, Mozilla, Amazon, и, как нам обещают, он будет развиваться. Будут добавлены возможности форматирования строк с учетом форм множественного числа и пола, парсинг чисел и многое другое. Жаль, что происходит это все достаточно медленно. Например, сам стандарт был утвержден еще в 2013 году, а поддержка самыми популярными браузерами была реализована только в 2016. А пока что функционал объекта Intl достаточно ограничен и не предоставляет возможности для переводов. Поэтому приходится использовать сторонние решения или использовать полифилл для еще не утвержденного формата.
Плюсы:
- нативная реализация в браузере;
- высокая производительность;
- не требует загрузки дополнительных ресурсов;
- форматирование строк с разными локалями без подгрузки JavaScript-ресурсов;
- развитие стандарта ECMAScript 2017 Internationalization API.
Минусы:
- для устаревших браузеров необходима загрузка полифилла;
- зависимость от системы. Некоторые локали могут не поддерживаться клиентом;
- могут быть разные результаты в разных браузерах.
Примеры ECMAScript Internationalization API
var mFormat = new Intl.NumberFormat("ru", {
style: "currency",
currency: "GBP"
}).format(1234567.93);
console.log(mFormat); // 1 234 567,93 £
var nFormat = new Intl.NumberFormat('ru-RU').format(1000.15);
console.log(nFormat); // "1 000,15"
var utc = new Intl.DateTimeFormat("en-US", {
timeZone: "utc",
hour: "numeric",
minute: "numeric"
});
console.log(utc.format(new Date())); // 2:38 PMЧуть больше примеров можно посмотреть тут.
Как вы можете заметить, много чего еще в стандарте не реализовано, учтены не все особенности, с которыми сталкиваются разработчики веб-приложений. Поэтому, как я писал выше, многим приходится либо искать уже готовые решения, либо разрабатывать свои собственные. На данный момент решений достаточно много, и у каждого есть свои достоинства и недостатки. Если обратиться к Google, то при поиске в первых результатах будут i18next, FormatJS, Globalize, jQuery.i18n и другие. Некоторые из этих библиотек предлагают свои собственные решения, другие стараются идти по стандарту ECMA-402. Возьмем для примера две библиотеки, которые нам выдает в первых результатах в поиске Google и посмотрим, что они умеют.
i18next
Как утверждает разработчик, это очень популярная библиотека для интернационализации как на клиенте, так и на сервере (node.js). Для нее существует множество плагинов, утилит, она интегрируется с разными фреймворками. Предоставляет интерфейс для переводчиков, в который вы можете загружать файлы переводов, но, к сожалению, он уже платный. В ней действительно много чего реализовано, и библиотека продолжает развиваться, что, конечно, радует. Но она не следует спецификации ECMA-402 и имеет свой структурный формат для сообщений, а не ICU Message syntax. Кроме того, для форматирования чисел и дат требуется загрузка moment.js или numeral.js. Соответственно, вам придется загрузить в проект еще и эти библиотеки и к ним добавить еще локали для нужных языков.
Плюсы:
- поддержка многих особенностей языка;
- возможность загрузки ресурсов с бэкенда;
- дополнительные плагины и различные утилиты;
- расширения для популярных фреймворков, шаблонизаторов.
Минусы:
- требует загрузки ресурсов (i18next 35 кб + moment 20 кб + необходимые локали);
- не следует стандарту ECMA-402;
- платный интерфейс для переводчиков.
Более подробную информацию по работе с библиотекой и больше примеров можно найти на официальном сайте.
Format JS
Format JS — это модульная коллекция JavaScript-библиотек для интернационализации. Она основывается на стандартах ECMA-402, ICU, CLDR и имеет интеграцию со множеством фреймворков и шаблонизаторов, например, такими как Dust, Ember, Handlebars. Данная библиотека при необходимости либо загружает полифилл для работы с интернационализацией, или же использует возможности браузера. Кроме того, она поддерживает работу как на клиенте, так и на сервере.
Плюсы:
- модульность;
- использует возможности ECMA-402 или полифилл;
- расширения для популярных фреймворков, шаблонизаторов.
Минусы:
- требует загрузки ресурсов при необходимости;
- не все возможности для переводов.
Например, текст для перевода в ICU формате будет иметь такой вид:
{ gender, select,
female {{
count, plural,
=0 {У нее нет яблок}
=1 {У нее всего одно яблоко}
one {У него # яблока}
few {У нее # яблока}
other {У нее # яблок}
}}
other {{
count, plural,
=0 {У него нет яблок}
=1 {У него всего одно яблоко}
one {У него # яблока}
few {У него # яблока}
other {У него # яблок}
}}
}Проверить работу можно по этой ссылке. Используйте пример выше и впишите локаль «ru». Формат, на первый взгляд, достаточно сложный, но позволяет учесть многие особенности языка. Единственное, я пока что не встречал удобных систем для переводчиков, которые работали бы с подобным форматом.
Как видно, решений существует достаточно много, вам нужно лишь выбрать. Но процесс локализации не заканчивается просто на выборе какой-то системы для локализации и попыткам справиться с различными особенностям языков. Любая система переводов должна быть тесно интегрирована в ваш процесс разработки, она должна представлять единую инфраструктуру как для разработчика, так и для переводчика, и ответить на несколько важных вопросов, например:
- как будет выглядеть процесс перевода?
- как файлы переводов будут попадать к переводчикам и обратно в систему?
- как узнать переводчику где находится конкретный текст?
И только тогда, когда у вас будут ответы и на эти вопросы, можно сказать, что вы имеете хорошо интегрированную систему локализации, удобную для работы.

На все эти вопросы и особенности языков нам пришлось обратить внимание, когда Badoo выходил на международный рынок. В те уже далекие времена, даже если похожие системы для локализации и существовали, то они не удовлетворяли всем нашим требованиям, и, само собой, нам пришлось разработать свою систему для локализации (о который мы уже писали на Хабре, а также рассказывали об особенностях верстки мультиязычных приложений). Данная система должна была хорошо интегрироваться в наш общий процесс, быть прозрачной и не задерживать процесс разработки (так как, например, мы «релизимся» два раза в день, и нам очень важно, чтобы новые продуктовые идеи быстро оказывались в продакшен-окружении). Кроме того, ей необходимо было иметь возможность работать не только с вебом, но и со всеми другими нашими платформами, такими как iOS, Android, Windows Phone, а также использоваться для email-рассылок.
С появлением общего формата общения между нашими клиентами и сервером (далее — протокол), или, как мы это называем, «апификацией», многие тексты стали приходить с сервера. Этот подход для нас оказался удобным, так как не надо хранить большие объемы переводов на клиенте и благодаря такому подходу мы, например, можем проводить AB-тестирование лексем или же создавать такие лексемы, которые зависят от действия пользователя. Каждый клиент также может хранить нужные переводы у себя. Решение, где хранить переводы — на клиенте или сервере, принимает команда, отвечающая за разработку протокола. Если какие-то переводы обновляются, то каждый клиент может запросить новые (так как переводы обновляются часто, а новые релизы появляются в магазинах приложений с определенной периодичностью). Такой механизм мы называем Hot Lexem update.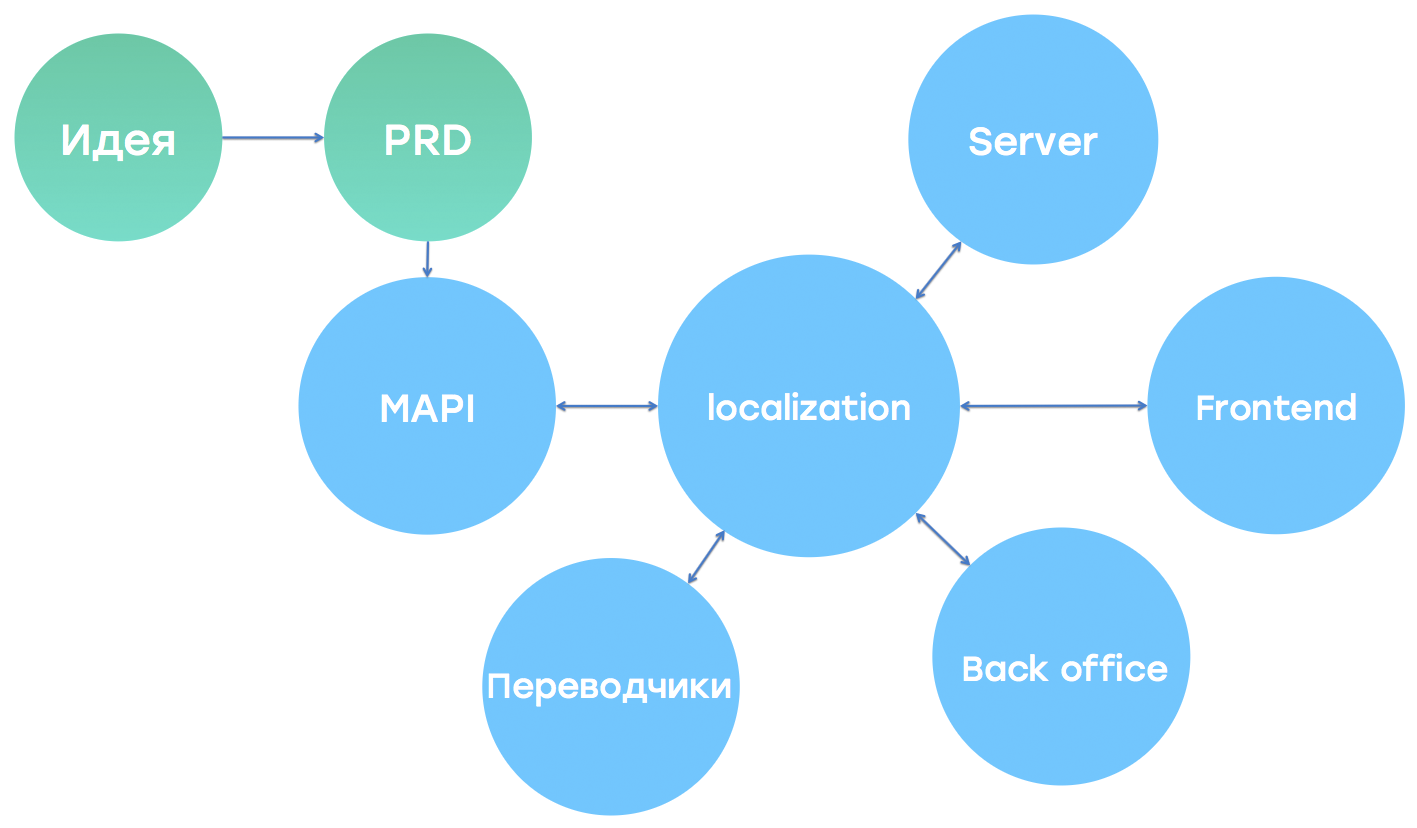
Как видно из рисунка выше, в процессе локализации у нас заняты не только клиентские разработчики и переводчики, но и множество других команд. Например, команда MAPI, как я писал выше, проектирует протокол и решает, где будут храниться переводы. Команда BackOffice предоставляет удобный интерфейс для переводчиков, переводчики, само собой, делают переводы, а команды SRV (серверные разработчики) или Frontend (клиентские разработчики) генерируют и отображают нужный перевод. Кроме того, когда мы создали такую систему, то на ее основе нам удалось создать коллоборативную систему переводов (https://translate.badoo.com/), в которой могут участвовать и наши пользователи. И они очень помогают нам делать переводы с учетом местных особенностей каждой страны.
Заключение
Совершенно понятно, что процесс локализации любого приложения — это достаточно серьезная и кропотливая работа, потому что она затрагивает разные команды проекта, а не только разработчиков и переводчиков. И в конце этой статьи я хочу еще раз обратить ваше внимание на основные, на мой взгляд, моменты при локализации приложений:
- Локализация — достаточно сложная процедура для внедрения «поверх». Если она вам понадобится, то должна быть заложена в проект с самого начала.
- Ресурсы локализации должны быть независимыми от приложения.
- Локализация распространяется не только на строки, и это тоже должно быть учтено при проектировании.
- Сделайте вашу систему удобной не только для разработчиков, но и для переводчиков, автоматизируйте процесс переводов.
- Если не уверены в качестве перевода, лучше вообще не переводите текст.
- Старайтесь учитывать культурные особенности каждой страны и языка.
- Дизайны, макеты, цветовая гамма, используемые изображения должны быть подвержены локализации.
Пожалуй, по этой теме у меня все. Надеюсь, что вы почерпнули для себя какие-то новые тонкости процесса локализации. Если же у вас есть свой интересный опыт, то поделитесь им и замечаниями в комментариях. Make web great again!
Вячеслав Волков, frontend разработчик, Badoo
