Как мы в хакатоне AI.HACK победили, или Когда нужно выключить искусственный интеллект и включить естественный

В марте команда наших разработчиков с гордым названием «Руки-Ауки» двое суток неусыпно сражалась на цифровых полях хакатона AI.HACK. Всего было предложено пять задач от разных компаний. Мы сосредоточились на задаче «Газпромнефти»: прогнозирование спроса на топливо со стороны В2В-клиентов. Нужно было по обезличенным данным — регион приобретения топлива, номер заправки, вид топлива, цена, дата и ID-клиента — научиться прогнозировать, сколько в будущем купит тот или иной клиент. Забегая вперёд — наша команда решила эту задачу с наивысшей точностью. Клиенты были разбиты на три сегмента: крупные, средние и мелкие. И помимо основной задачи мы также построили прогноз суммарного потребления по каждому из сегментов.
Выгрузка содержала данные о покупках клиентов за период с ноября 2016 по 15 марта 2018 года (за период с 1 января 2018 по 15 марта 2018 данные НЕ включали объемы).
Пример данных:
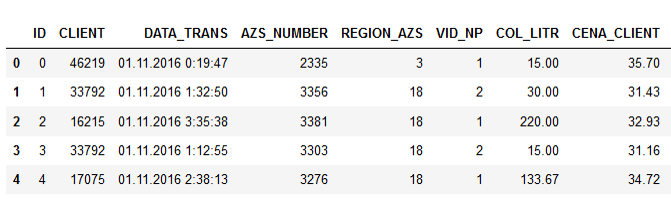
Названия колонок говорят за себя, думаю, пояснять нет смысла.
Кроме обучающей выборки организаторы предоставили и тестовую выборку за три месяца этого года. Цены указаны для корпоративных клиентов с учётом конкретных скидок, которые зависят от объёмов потребления того или иного клиента, от спецпредложений и прочих моментов.
Получив исходные данные, мы, как и все, начали пробовать классические методы машинного обучения, пытаясь построить подходящую модель, нащупать корреляцию каких-то признаков. Старались извлечь дополнительные признаки, строили регрессионные модели (XGBoost, CatBoost и др.).
Cама постановка задачи изначально подразумевала, что на спрос каким-то образом влияет цена на топливо, и нужно точнее понять эту зависимость. Но когда мы начали анализировать предоставленные данные, то увидели, что спрос никак не коррелирует с ценой.

Корреляция признаков:
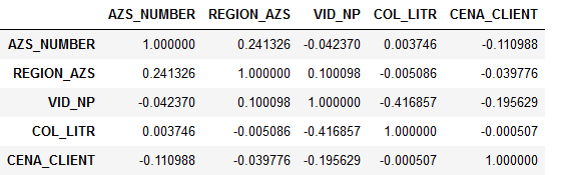
Получалось, что количество литров практически никак не зависит от цены. Это объяснялось вполне логично. Водитель едет по трассе, ему нужно заправиться. У него выбор: либо он заправится на заправке, с которой сотрудничает компания, либо на какой-то другой. Но водителю всё равно, сколько стоит топливо — его оплачивает организация. Поэтому он просто сворачивает на ближайшую заправку и наполняет бак.
Однако несмотря на все усилия и перепробованные модели, никак не удавалось достичь минимально допустимой точности прогнозирования (baseline), которая вычислялась по этой формуле (Symmetric mean absolute percentage error):

Перепробовали все варианты, ничто не срабатывало. И тут одному из нас пришло в голову плюнуть на машинное обучение и обратиться к старой доброй статистике: просто взять среднее значение по виду топлива, провалидировать и посмотреть, какая получится точность.
Так мы впервые превысили пороговое значение.
Начали думать, как улучшить результат. Пробовали брать медианные значения по группам клиентов, видам топлива, регионам, номерам АЗС. Проблема была в том, что в тестовых данных отсутствовало около 30% ID клиентов, которые были в обучающей выборке. То есть в тестовой появились новые клиенты. Это было ошибкой организаторов, не проверили. Но решать проблему нужно было нам самим. Мы не знали потребления новых клиентов, и поэтому не могли построить для них прогнозы. И тут как раз помогло машинное обучение.
На первом этапе заполняли недостающие данные средним или медианным значением по всей выборке. А потом появилась идея: почему бы не создать профили новых клиентов на основе имеющихся данных? У нас есть срезы по регионам, сколько там покупают топлива клиенты, с какой частотой, какие виды. Кластеризовали существующих клиентов, составили характерные профили для разных регионов и на них обучили XGBoost, которая затем «достроила» профили новых клиентов.
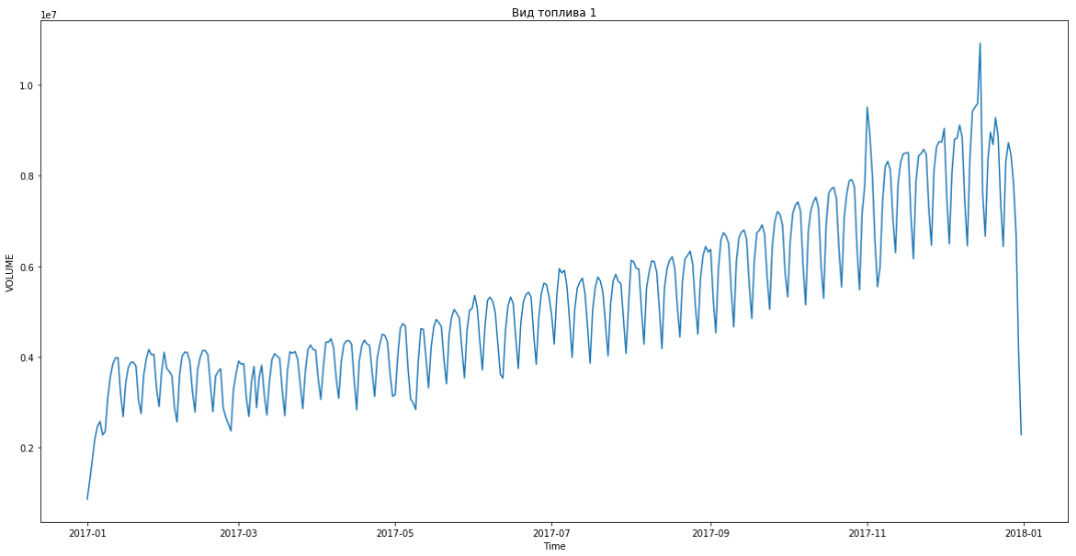
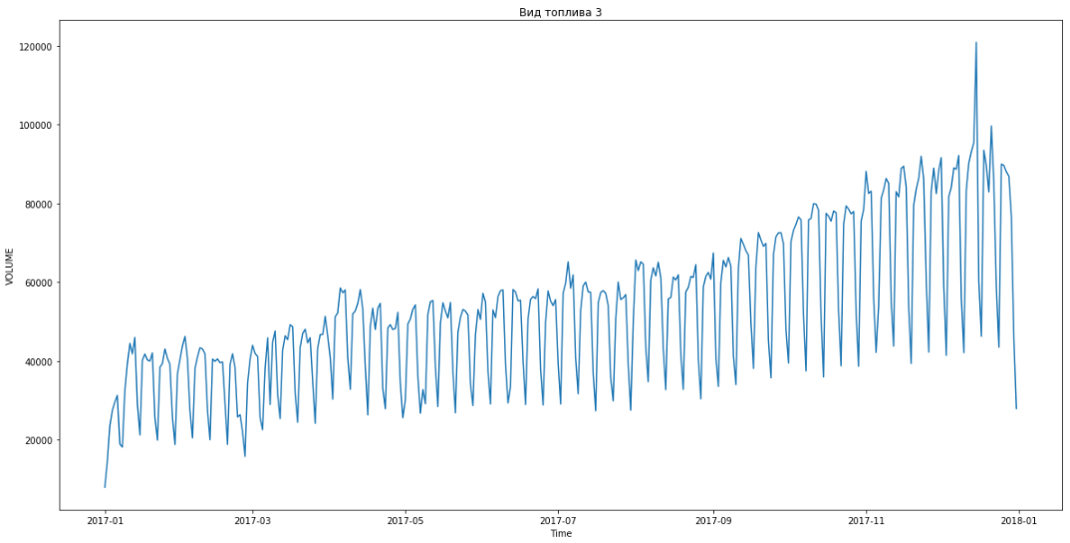
Это позволило нам вырваться на первое место. До подведения итогов оставалось ещё часа три. Обрадовались и начали решать бонусную задачу — прогнозирование по сегментам на три месяца вперед.
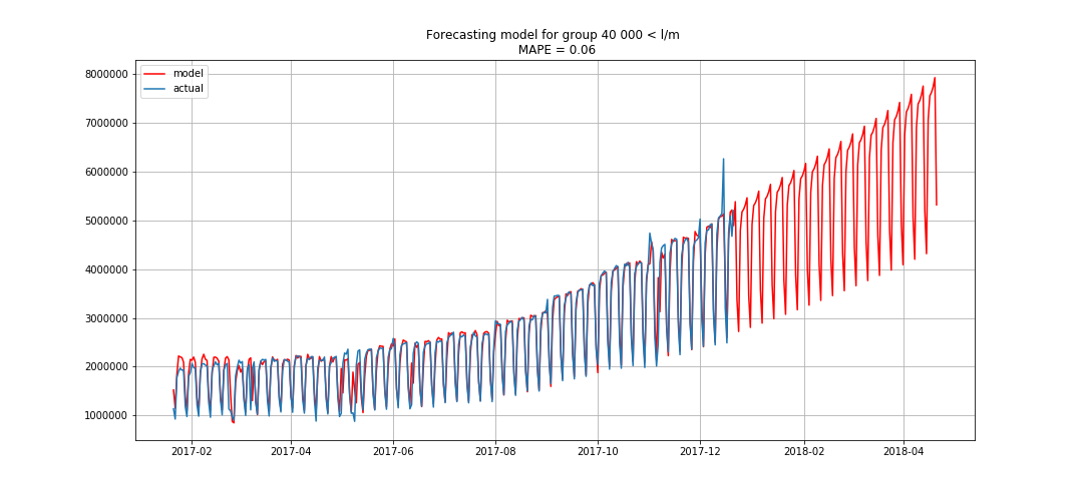
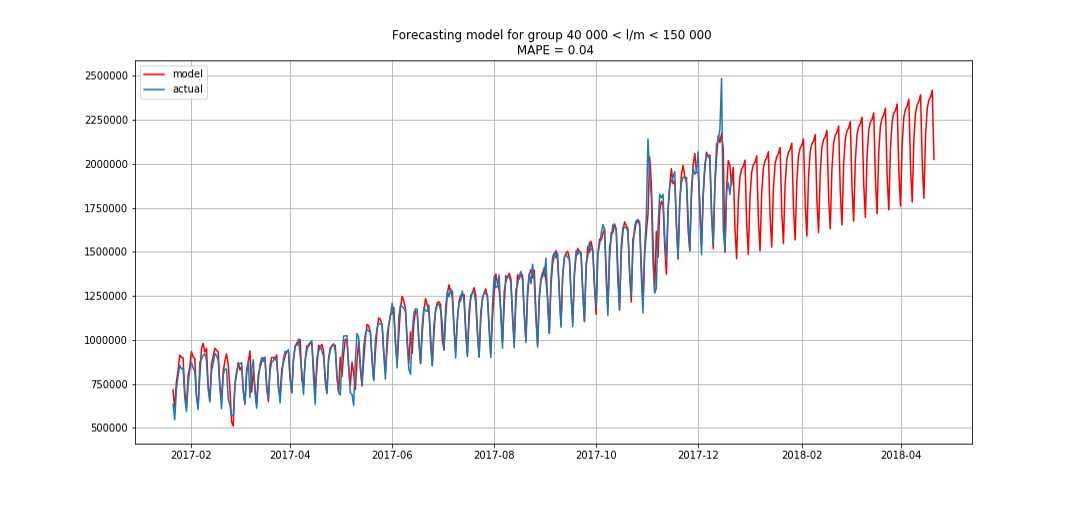
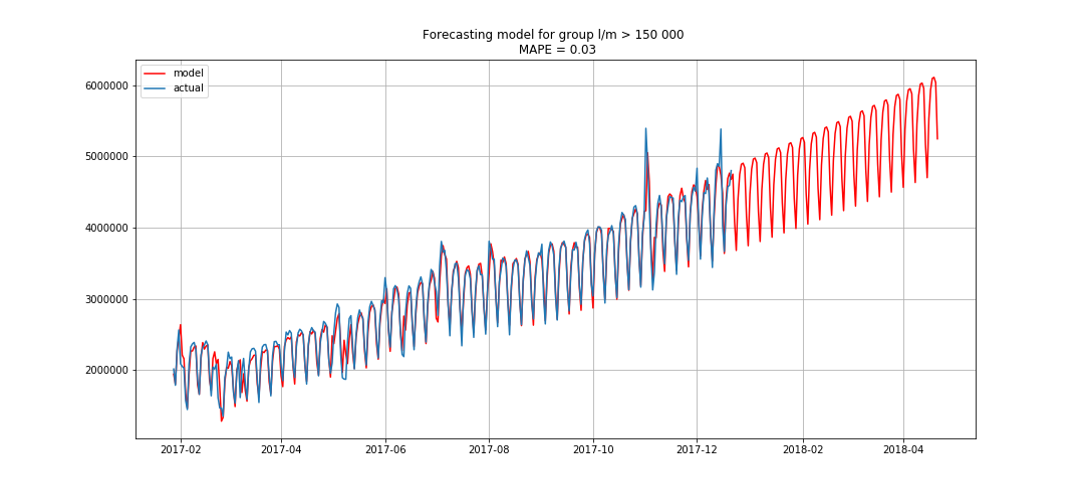
Синим показаны реальные данные, красным — прогноз. Ошибка составляла от 3% до 6%. Можно было посчитать ещё точнее, например, учтя сезонные пики и праздничные дни.
Пока мы этим занимались, одна команда начала нас догонять, каждые 15–20 минут улучшая свой результат. Мы тоже засуетились и решили что-нибудь предпринять на случай, если они нас догонят.
Начали параллельно делать другую модель, которая ранжировала статистику по степени значимости, её точность была чуть ниже, чем у первой. И когда конкуренты нас обошли, мы попробовали объединить обе модели. Это дало нам небольшой прирост метрики — до 37.24671%, в результате мы вернули себе первое место и удержали его до конца.
За победу наша команда «Руки-Ауки» получила сертификат на 100 тыс. рублей, почет, уважение и…преисполненная чувством собственного достоинства отправилась спаааать!
Команда разработчиков «Инфосистемы Джет»
