Как мы ускоряли сборку Android-приложения из двух миллионов строк кода

Всем привет! Наверняка каждый Android-разработчик хоть раз сталкивался с проблемой скорости сборки своего проекта. После нехороших слов в адрес кодогенерации, покупок более мощного железа и многочисленных попыток распилить проект на небольшие параллельно собираемые модули и прохождений всех стадий торга мы продолжаем искать решение этой проблемы. К счастью, за годы развития и в Gradle, и Android Gradle Plugin (AGP) появилось много полезных штук для ускорения сборки, о которых я расскажу дальше.
Несмотря на шутку в адрес многомодульности, это действительно полезный подход, но для большого проекта с богатой историей модуляризация может быть очень сложным процессом. Поэтому пока давайте посмотрим, что можно сделать без больших болей на уровне Gradle и AGP.
Я расскажу на примере мобильного Яндекс Браузера. У нас было ~150 Gradle-модулей, ~2 млн LoC на Java/Kotlin, десяток Gradle-плагинов, тысячи строк кода в buildSrc и лёгкая дрожь от вопроса, сколько ещё может переварить билд-система. Не скажу, что это всё было категорически необходимо, но к написанным строчкам кода надо проявлять уважение.
Измерение скорости сборки
Когда стоит задача что-то улучшить, сначала нужно научиться это «что-то» хорошо измерять, а дальше — следить за результатом своих трудов.
И уже на этом этапе появляются вопросы.
Во-первых, что именно нужно измерять? Время холодной сборки проекта (условный ./gradlew clean app:assembleDebug). Но разработчики гораздо чаще выбирают инкрементальную сборку. Ок, давайте измерять инкрементальную сборку. А насколько инкрементальную? При правке в базовом модуле, в модуле посередине графа или в app-модуле? К сожалению, единого ответа нет. Общая рекомендация — определите набор сценариев (холодная сборка и несколько разных инкрементальных), оцените, где чаще всего разработчики вносят правки, снимайте метрики со всех сценариев и следите за каждым.
Во-вторых, как мы будем измерять? Самый простой способ — собирать метрики прямо со всех разработческих машин, репортить их на свой сервер и строить графики из полученных данных. Плюс такого подхода в том, что мы видим данные от пользователей и понимаем, насколько они страдают. Минус — это чрезвычайно нестабильная метрика. У разработчиков могут быть разные ноутбуки, в разные дни они могут делать разные правки в коде и собирать приложение разное количество раз. Также в какой-то момент они могут делать это, параллельно сидя в Zoom и Figma, запустив два эмулятора, а в другой — только собирая проект. В итоге эта метрика будет сильно неустойчивой, создаст много поводов понервничать из-за скачков графиков, и самое главное — она не позволит искать изменения, создающие ухудшения.
Более правильный вариант — взять один или несколько усреднённых эталонных ноутбуков, которые будут постоянно собирать проект по выбранным сценариям (эти сценарии легко запрограммировать), снимать данные по времени и репортить их. Если ноутбук хорошо откалиброван и не выполняет посторонней работы, вы будете получать достаточно стабильные результаты. Более того, если приложить дополнительные усилия, можно настроить и сценарии сравнения коммитов — запускаете процесс измерения на двух разных коммитах и сравниваете результаты. Это позволяет заранее проверять все вносимые изменения. При ещё большем желании можно настроить и bisect для поиска просадок, которые появляются на графиках. У нас в Яндексе для этого используется система performance-тестирования, которая изначально применялась для скорости старта. Это внутренний инструмент, поэтому опустим детали реализации. Общая идея должна быть понятна.
И, конечно, непосредственно для измерений лучше использовать не самописные скрипты, а готовые решения. Самым мощным инструментом профилирования и измерения скорости сборки является Build Scan, но если вы не готовы публично делиться результатами профилирования своих проектов, придётся платить, это подойдёт не всем. В целом, Build Scan не сильно необходим для успешного решения задачи по скорости сборки. Непосредственно с задачами измерения более чем справляется Gradle profiler — 1st-party-решение от Gradle. Его основное удобство в том, что он напрямую интегрирован с Gradle, что позволяет получать более точные и надёжные результаты и не заниматься поддержкой своих скриптов при обновлении Gradle. Поэтому для интеграции измерением рекомендую использовать именно его.
Тюним Gradle и AGP
Самое простое, что можно сделать, — добавить флаги в gradle.properties. Разных флажков много, надо изучать гайды Gradle и рекомендации для Android. Но можно выделить несколько флажков, которые, скорее всего, помогут всем.
Для начала рекомендую использовать последние версии Android Gradle Plugin (как минимум 7+) и JDK 11 (это в любом случае нужно для сборки с targetSdk 31+).
Итак, несколько базовых флажков:
org.gradle.configureondemand=true
org.gradle.parallel=true
org.gradle.daemon=true
org.gradle.vfs.watch=true
org.gradle.jvmargs=-Xmx6G -Xms256m -XX:+UseParallelGCСтоит пояснить насчёт последнего флага. Пороги памяти стоит выставлять исходя из вашего проекта. Тут надо помнить, что больше не всегда значит лучше. Не забывайте, что память вашего ноутбука ест ещё и демон Kotlin, да и все остальные приложения. И если её станет недостаточно, то скорость сборки точно не улучшится. Параллельный GC же лучше включать, только если у вас сборка с JDK 9+.
android.disableAutomaticComponentCreation=trueAGP создаёт software-компоненты для всех билд-вариантов (например, это часто используется в плагине maven-publish), что делать необязательно. С AGP 8.0 этот флаг будет включён по умолчанию, но пока его можно выставить самостоятельно заранее.
android.defaults.buildfeatures.buildconfig=false
android.defaults.buildfeatures.aidl=false
android.defaults.buildfeatures.renderscript=false
android.defaults.buildfeatures.resvalues=false
android.defaults.buildfeatures.shaders=falseЕщё один полезный набор опций, который советует документация — отключать генерацию разных билд-классов в модулях. Так мы экономим время там, где, например, нет классов BuildConfig. Минус этого в том, что в модуле надо вручную указывать, что нужна определённая билд-фича:
android {
buildFeatures {
buildConfig = true
}
}Это лёгкая и полезная оптимизация, поэтому её стоит использовать.
android.enableJetifier=falseВ 2022 году давно пора забыть страшные слова android.support и отказаться от использования Jetifier, который может занимать по 10–15 секунд на каждую сборку. Если у вас в проекте есть зависимости на библиотеки, которые всё ещё используют android.support вместо androidx, обновитесь на свежие версии, напишите авторам, если таких версий нет, перейдите на альтернативы или перепакуйте библиотеку.
Мы поговорили об основных оптимизациях, которые можно включать и использовать. Но есть и более сложные опции, среди которых, например, android.nonTransitiveRClass=true.
nonTransitiveRClass
Итак, каждый ресурс, будь то drawable, string, dimen и другие, имеет свой уникальный id, который формируется во время сборки и складывается в специальный класс R.java. Это позволяет ссылаться на ресурсы из Java/Kotlin-кода.
По умолчанию для каждого модуля создаётся свой класс R.java, который помимо ресурсов самого модуля содержит и айдишники всех зависимостей модуля — других модулей и всех сторонних библиотек. Далее уже на уровне application-модуля все айдишники ещё раз мержатся в финальный R.java, который содержит айдишники вообще всех модулей и зависимостей. Плюс такого подхода в удобстве использования в коде. В каждом модуле используется свой package name, заданный в AndroidManifest.xml (или namespace из build.gradle в более новых версиях Android Gradle Plugin) и разработчику не нужно думать о том, в каком модуле или зависимости есть конкретный ресурс. Однако есть и очевидный минус — нужны уникальные названия ресурсов, а также есть менее очевидный — при добавлении/удалении ресурса в одном модуле нужно будет заново генерировать айдишники и мержить R.java в этом модуле, в тех, что от него зависят, и, конечно же, в application-модуле.
Флаг android.nonTransitiveRClass=true, добавляемый в gradle.properties, убирает этап мержинга R.java класса. Теперь если разработчик хочет использовать ресурсы из разных модулей или библиотек, нужно явно указывать package name R-класса этого модуля.
Миграция в последних версиях Android Studio стала довольно простой, так как в меню появился пункт Refactor -> Migrate to Non-Transitive R classes.... Android Studio сама добавит флаг и поменяет ссылки на айдишники во всём коде. Но как и с миграцией на AndroidX, не всё проходит идеально, и где-то нужно вносить правки самостоятельно. В нашем проекте было немного мест, где был выставлен неправильный package name для R-класса. Так заодно подсветились проблемные места с одинаковыми названиями ресурсов или одинаковым package name для разных модулей.
После всех проделанных работ и включения флага мы получили:
- ускорение сборки application-модуля примерно на 20%, всего приложения — примерно на 10% при изменениях в ресурсах (добавление строки),
- -35% в количестве .dex файлов и -21% в их размере дебажной .apk (что также улучшило скорость работы локальной .apk).
Дополнительную информацию об этом флаге можно найти в хабрастатье Кирилла kirich1409.
Отказ от флейворов
Практически в каждом проекте бывает необходимо собирать разные варианты .apk: релизные и дебажные, для разработки, тестирования и продакшена, платные и бесплатные, с minSdk 23/26/28 и т. д. И документация учит нас использовать для этого флейворы. Но каждый новый билд-вариант замедляет и шаг конфигурации проекта, который выполняется на каждой сборке, и, конечно, синк проекта. А каждый новый dimension создаёт комбинаторный взрыв билд-вариантов. Поэтому я сильно не рекомендую использовать для таких задач флейворы.
В качестве альтернативы им можно использовать обычные билд-параметры. Непонятно, зачем делать флейворы для разных minSdk, когда можно получать её как project.property('...'), а каждый разработчик с помощью local.properties установит нужное ему значение. С помощью билд-флагов можно регулировать произвольные параметры. Каждый разработчик может задавать тот набор, с которым ему удобнее всего работать, а в сборках на CI вы укажете те параметры, которые нужны непосредственно собираемому артефакту. Поэтому лучше много раз подумать, прежде чем добавлять новый флейвор в проект.
Если же ваш проект плотно застрял на использовании флейворов, и переделать его на билд-флаги не выйдет, можно написать небольшой хак с игнорированием ненужных вариантов. Конечно, его нужно писать так, чтобы разработчикам можно было его включить локально, а не везде).
default_min_sdk_version=api26
default_update_channel=canary
// ...
android {
val minSdkFlavor = project.property("default_min_sdk_version")
val updateChannelFlavor = project.property("default_update_channel")
variantFilter { variant ->
def names = variant.flavors*.name
if (!names.contains(minSdkFlavor) && !names.contains(updateChannelFlavor)) {
// ignore all build variants except forced
setIgnore(true)
}
}
}Это позволит отфильтровать лишние варианты и ускорить синк проекта.
Использование minSdk 24+
Уже довольно давно для написания кода можно использовать Java 8 и фичи этой версии. Часть фичей на уровне системы стала доступна на API level 24 (Android 7.0), например static и default методы в интерфейсах. Остальные же появились уже в API level 26 (Android 8.0), например поддержка invokedynamic или java.time.
Чтобы разработчики могли использовать новые возможности Java 8 без повышения minSdk, в Google на уровне D8 сделали так называемый desugaring. Это один из этапов сборки, он занимает ощутимое количество времени.
В документации к D8 указано, что для поддержки static и default методов в интерфейсах нужно передавать classpath — путь до Java байт-кода всего проекта. Как было указано выше, эта функциональность из Java 8 поддержана на уровне системы в API level 24, поэтому, если minSdk >= 24, этот шаг не нужен во время сборки, а именно он, как оказывается, сильно замедляет сборку на уровне application-модуля.
minSdk < 24:
Скомпилированный код модуля собирается вclasses.jar, который потом с помощьюDexingWithClasspathTransformтрансформируется вclasses.dex. Эта трансформация не инкрементальная, так как с точки зрения Gradle просто меняетсяclasses.jar, но неизвестно, что конкретно внутри поменялось.
Далее в application-модуле всеclasses.dexиз модулей и application-модуля собираются в финальные.dexфайлы, которые будут лежать в .apk. При изменении одного файла в модуле меняется весьclasses.dexэтого модуля, из-за чего в application-модуле нужно сильно больше времени, чтобы смержить все.dexфайлы из всех модулей и на выходе получить то, что будет в .apk.minSdk >= 24:
Скомпилированный код модуля собирается в специальной директории, каждый файл.classлежит отдельно, все файлы лежат в папках согласно своему package. Далее с помощьюDexingNoClasspathTransformкаждый файл.classтрансформируется в.dexтаким образом, что на один класс приходится один файл.dex. Затем на уровне application-модуля с помощью внутренней эвристики определяется, какой из.dexфайлов, которые будут лежать в .apk, нужно обновить. Такой подход позволяет поддержать инкрементальность и трансформировать только изменённые классы. Стоит ещё отметить, что в дебажных APK.dexфайлов сильно больше, чем в релизной. Это как раз нужно для лучшей инкрементальной сборки. Так вот приminSdk >= 24.dexфайлов становится значительно больше, за счёт чего они становятся небольшими и при изменении одного класса нужно пересобрать один небольшой.dexфайл вместо того, чтобы тратить время на мержинг больших файлов каждый раз.
Ещё подробнее можно посмотреть в исходниках DexingTransform.kt.
Согласно нашим замерам, minSdk=24 ускоряет инкрементальную сборку примерно на 30–40%, а application-модуль собирается в 2–3 раза быстрее.
Также в Android Gradle Plugin версии 4.2.0 при minSdk >= 28 убирают компрессию дексов внутри .apk, благодаря чему увеличивается raw size у .apk, однако installation size уменьшается, и .apk устанавливается быстрее.
Мы даём возможность менять minSdk через билд-флаг, как было описано выше, и рекомендуем разработчикам использовать minSdk 24+. Однако важно не забывать, что при локальной разработке Android Studio не будет подсвечивать места вызова методов, которые доступны только в новых версиях Android. Поэтому нужно обязательно настраивать сборки на пул-реквестах или хуки Git, чтобы они проверяли наличие таких вызовов (например, в lint есть issue NewApi, на возникновение которой можно ронять сборку).
Ревизия задач и плагинов
Ещё один способ ускорить сборку проекта — отключение разных плагинов и дополнительных шагов, которые не нужны в локальной сборке, а нужны только для релизной. Допустим, мы используем плагин для трансформации кода с помощью AspectJ для определённых задач (логирования, корректной работы с языковыми пакетами в AppBundle и т. д.), что довольно сильно замедляет сборку, но является совсем необязательным для локальной работы. Такие тяжелые вещи стоит выключать по умолчанию билд-флагом и включать только в сборках на CI или же включив флаг локально, если нужно отладить конкретно эту часть проекта. Другой пример — плагин com.huawei.agconnect, который вам может быть не нужен, если только вы прямо сейчас не разрабатываете на Huawei без Google Play Services. То есть это плагин, который делает лишнюю работу и который вам конкретно сейчас не нужен. Поэтому его спокойно можно отключить в локальных сборках, то есть применять под выключенным по умолчанию билд-флагом.
Вывод — бывает очень полезно посмотреть, какие плагины (внешние или написанные вами) подключены в вашем проекте, провести их ревизию и подумать, какие из них можно отключить. Однако это несёт небольшой дополнительный риск, о котором мы говорили чуть выше, в разделе про minSdk. Поскольку по умолчанию у разработчиков эти плагины будут отключены, они не увидят какие-то проблемы, которые возникают с ними. Поэтому нужно обязательно на CI прогонять тесты, проверяющие, что в релизной конфигурации всё работает корректно.
Configuration cache
Configuration cache — это фича Gradle, которая позволяет в общем случае полностью избавиться от этапов Evalution/Configuration в инкрементальных сборках (которые без этой фичи выполняются на каждую сборку и могут занимать большое время — на нашем проекте это было в среднем 6–15 секунд). Базово Configuration Cache работает по той же логике, что и обычное кэширование тасок. Если в рамках инкрементальной сборки вы не меняли Gradle-файлы, переменные окружения и код в buildSrc, тогда шаг конфигурации повторно не выполняется. Конечно, на самом деле всё не так тривиально, поэтому первая поддержка Configuration Cache появилась только в Gradle 6.7+, и разработка активно продолжается (например, передача параметров через -Pkey=value была поддержана только в Gradle 7.4).
Итак, как включить себе Configuration Cache? В первую очередь стоит обновить Gradle и Android Gradle Plugin до последних версий. Дальше можно запустить любую сборочную таску через командную строку с опцией --configuration-cache или же прописать org.gradle.unsafe.configuration-cache=true в gradle.properties. Лучше начинать с минимальных задач, которые выполняются быстро (например, со сборки/тестов в каком-нибудь небольшом модуле) и постепенно чинить все сценарии вплоть до сборки приложения.
Скорее всего, с первого раза Configuration Cache у вас не заработает, конечно если только вы не пишете сразу идеальный код в сборочных скриптах или у вас почти нет таких скриптов и плагинов. Возникающие ошибки бывают двух видов: доступ к переменным окружения/системным переменным и использование объекта Project во время выполнения тасков. В документации достаточно подробно описано, на что стоит поменять, чтобы поддержать работу Configuration Cache. Общие правила — из своих тасок/плагинов не читать внешние переменные и проперти проекта, а передавать их как @Input параметры, тогда Gradle сможет кэшировать эти таски корректно. И, конечно, не надо использовать в сборочных скриптах никакие значения, которые меняются с каждой сборкой. Например, текущее время, что многие могут использовать для отображения информации, когда был собран артефакт. Такие параметры стоит выключать в локальных сборках и оставлять только на CI.
Кроме вашего собственного сборочного кода, проблемы с Configuration Cache могут быть и у плагинов, которые вы используете в проекте. Сейчас большинство плагинов уже поддерживают Configuration Cache, и вам надо просто обновиться до последних версий. Если же нужной версии нет, можно попробовать отключать проблемные плагины через билд-проперти в локальных сборках.
Build Сache
Ещё один тип кэширования — Gradle Build Cache. На него мы смотрели давно, но долго не трогали по нескольким причинам. Во-первых, у нас были попытки включить его какое-то время назад, когда это давало лишь ухудшения в скорости сборки, ни Android Gradle Plugin, ни Kotlin ещё не были так совместимы с Build Cache, как сейчас. Во-вторых, был постоянно обновляющийся buildSrc из-за версий библиотек (раздел ниже). А как известно, любое изменение в classpath сбрасывает весь кэш.
Что мы сделали:
- С помощью стороннего плагина https://github.com/burrunan/gradle-s3-build-cache настроили хранение кэша в нашем S3. Срок хранения кэша — неделя. Чуть позже уменьшили до пяти дней, так как кэш занимает значительное место в хранилище.
- Подключили плагин android-cache-fix-gradle-plugin. В нём исправляется много различных известных проблем в Android Gradle Plugin, которые могут вызывать cache miss или, например, зря включено кеширование, так как в таске просто выполняется перемещение/архивирование объектов и быстрее выполнить эту работу, чем скачивать кэш.
- Включили экспериментальные флаги в Android Gradle Plugin:
android.experimental.enableSourceSetPathsMap=trueиandroid.experimental.cacheCompileLibResources=true. Их применение существенно улучшило кэширование задач, связанных со сборкой ресурсов. - В сборках, которые прогоняются в пул-реквестах, включили использование кэша только на чтение.
- Завели отдельную «прогревочную» сборку на ветке master, которая запускается, как только в ветке появились новые коммиты и включилась загрузка кэша в хранилище.
Проблемы, которые мы встретили:
- Недетерминизм сборок без изменений. Нашли одно место в коде, где в начале каждого билда в
BuildConfigзаписывалось время начало сборки. Это вызывало перекомпиляцию модуля, даже если не изменять ничего. - В компиляторе Kotlin есть баг: https://youtrack.jetbrains.com/issue/KT-48798. Если говорить вкратце, то при изменении количества product flavor для компилятора меняется список sourceSets, из-за чего случаются cache miss. Мы на это натолкнулись из-за пункта «Отказ от флейворов», так как по умолчанию этот фильтр выключен, и только разработчики локально его задают в local.properties. В итоге в «прогревочной» сборке мы добавили ещё конфигурацию, когда фильтр флейворов включён.
- В Gradle 7.4.1 сторонний плагин для Build Cache несовместим с Configuration Cache: https://github.com/gradle/gradle/issues/14874. Это починили в версии 7.5. По этой причине на момент написания статьи Build cache в экспериментальном режиме, ещё не включён по умолчанию.
- В пул-реквестах значительную часть времени сборки занимает lint, который в свежих версиях Android Gradle Plugin совместим с Build cache. Однако наличие больших модулей, в которых часто делаются изменения, сводит на нет всё кэширование.
- Наличие большого количества билд-флагов может привести к тому, что у каждого разработчика может быть свой набор флагов, каждый из которых каким-то образом влияет на сборку и может свести на нет всё кэширование.
Здесь можно пойти двумя путями:
- Выставлять значение флагов по умолчанию таким, чтобы сборка была максимально быстрой и удобной для разработчика локально, а уже в пул-реквестах проверять правильный набор флагов. Но тут есть очевидный минус — локально может всё собираться, а на пул-реквесте может внезапно что-то упасть. По опыту могу сказать, что таких ситуаций бывает довольно мало.
- Добавлять новую конфигурацию в «прогревающую» сборку с другими флагами. Но тут нужно быть аккуратным, так как это замедляет саму «прогревающую» сборку и увеличивает размер кэша.
Результаты:
- В пул-реквестах мы получили порядка 10–20% ускорения конкретно сборки проекта.
- Локально холодная сборка ускорилась в 2–4 раза. Инкрементальные сборки при включенном кэшировании также проверяли, там особых изменений нет, но они и не ожидались.
Другое
Итак, мы рассмотрели разные идеи и подходы, как можно оптимизировать скорость сборки Gradle-проекта. Кроме всех этих подходов у нас есть ещё одна забавная история и обещание поговорить про многомодульность, так что перейдём к этому.
Версии зависимостей
Небольшая забавная история. Когда-то мы потратили довольно много времени на то, чтобы придумать максимально удобную систему для хранения и использования зависимостей в проекте, чтобы и автокомплит работал, и библиотеки, и их версии указывались в одном месте и чтобы вообще всё было хорошо. В итоге мы пришли примерно к такой конструкции в buildSrc:
class Dependencies private constructor() {
//Dependencies groups
val androidX = AndroidX()
//...
val okio = dependency("com.squareup.okio:okio", "2.9.0")
val playCore = dependency("com.google.android.play:core", "1.10.3")
//..
class AndroidX {
val lifecycle = Lifecycle()
val activity = dependency("androidx.activity:activity", "1.4.0")
val appcompat = dependency("androidx.appcompat:appcompat", "1.4.0")
//...
class Lifecycle {
val version = "2.4.1"
val common = dependency("androidx.lifecycle:lifecycle-common", version)
// ...
}
}
}
object Project {
lateinit var params: BuildParams
lateinit var deps: Dependencies
@JvmStatic
fun initWith(target: Project) {
require(target ## target.rootProject) {
"Projet must be initialized only with rootProject"
}
params = BuildParams.load(target, corePaths)
deps = Dependencies.create(target)
}
}И уже в build.gradle используем красиво и с автокомплитом и навигацией:
dependencies {
implementation Project.deps.androidX.activity
implementation Project.deps.androidX.appcompat
implementation Project.deps.playCore
}Всё было замечательно, пока мы не заметили одну интересную особенность. Разных зависимостей в проекте у нас было много (одних AndroidX-зависимостей больше 30 штук), разработчиков в проекте тоже было много, и они часто что-нибудь обновляли. И получалось так, что практически после каждого git pull у разработчика в дефолтной ветке обновлялась какая-то версия библиотеки, а это автоматически приводило к перекомпиляции кода в buildSrc, что в свою очередь означало фактически сборку с нуля.
К сожалению, тут нам пришлось пойти немного против изначального желания и вынести версии в отдельный файл, чтобы изменения в нём не приводили к пересборке buildSrc. В качестве формата выбрали .json5, что позволяет в том числе писать комментарии, а в качестве ключей для версий — группу и артефакт нужной зависимости (поэтому версии зависимостей все ещё достаточно удобно смотреть).
{
"androidx.activity:activity": "1.4.0",
"androidx.appcompat:appcompat": "1.4.0",
//...
"com.google.android.play:core": "1.10.3",
//...
"com.squareup.okio:okio": "2.9.0",
}Далее эти версии читаем при создании объекта Dependencies и подставляем в нужные места примерно так:
object DependenciesStore {
private val gson = GsonBuilder().setLenient().setPrettyPrinting().create()
private lateinit var nameToVersion: Map
fun load(json: String) {
val type: Type = object : TypeToken>() {}.type
nameToVersion = gson.fromJson(json, type)
}
fun get(name: String): String {
return requireNotNull(nameToVersion[name]) {
"No version found for '$name'!"
}
}
fun dump(toFile: File) {
DependenciesStoreDumper.dump(gson, toFile)
}
}
fun dependency(
artifactName: String,
version: DependencyVersion? = null,
): String {
val versionToUse = if (version != null) {
version.load()
} else {
DependenciesStore.get(artifactName)
}
return "$artifactName:$version"
} Разумеется, такие структуры нужны далеко не каждому проекту, но, как и говорилось, это скорее забавная история, которая показывает то, какие разные проблемы в скорости сборки могут возникать, и как их можно решать. Так что всегда есть интересные места, которые можно поисследовать.
Многомодульность
Уверен, что вы хотя бы раз слышали о том, что Gradle-проект надо разбивать на модули. На это есть две основные причины: архитектурная и сборочная. С точки зрения скорости сборки, задача состоит в том, чтобы дать возможность Gradle собирать проект максимально параллельно. В идеальном мире у вас должен быть очень тонкий app-модуль, который зависит от дерева модулей, причём это дерево должно быть больше широкое, чем глубокое (как крокодил, хе-хе). Но в реальности обычно всё не так радужно, и есть жирный модуль, на котором сборка любит посидеть подольше, и в один поток. Похожая история была и есть у нас. На картинке это выглядит примерно так:
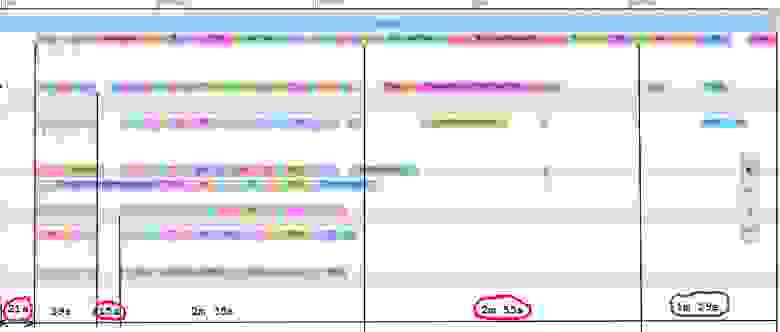
Конечно, это полная чистая сборка, но даже так числа без лишних слов объясняют важность разбивки проекта на модули. В основном модуле у нас сосредоточена примерно треть всего кода, что довольно неоптимально.
Как я и говорил в начале текста, обычно нет лёгкого и простого рецепта, как исправить эту проблему. Но могу дать несколько советов, как распиливать большой модуль на более мелкие.
- Развивайте культуру разработчиков в команде, чтобы они понимали важность разбивки проекта на модули. Нужно рассказывать, объяснять, контролировать, стараться весь новый код писать в отдельных модулях. Можно сделать график количества строк кода или процента LoC от всего в проекте в самом большом модуле и следить за ним.
- Добавьте в процесс разработки чистку старого неактуального кода. Завершённые эксперименты, старые фичи и другой ненужный код всегда надо стараться удалять. Ведь удалять код сильно проще, чем рефакторить и переносить его в отдельные модули.
- Оцените самые большие по размеру кодовой базы компоненты и фичи проекта. Попробуйте понять, сколько будет стоить перенос каждого в отдельный модуль. Составьте список задач, приоритезируйте по соотношению «перенесённый LoC/оценка по времени» и попытайтесь брать задачи в рамках технического бэклога. Тут у каждой команды будет по-разному, но обычно у разработчиков получается выбить себе время и приоритеты на технические задачи. Кстати, для оценки сложности вынесения кода из модуля мы даже написали наколеночный инструмент, который помогает оценить степени «зависимости» пакетов/классов на модуль, в котором они находятся. Инструмент черновой, так что пользоваться им можно только на свой страх и риск:)
- Следите за структурой зависимостей модулей. Нет смысла разбивать проект на модули, если ваше дерево — связный список. Также иногда бывает так, что между модулями, которые могли бы собираться параллельно, возникает зависимость буквально из-за одного-двух классов, которые можно было бы перенести в общий модуль ниже по дереву.
- Не подключайте модуль «ниже», чем он реально нужен, иначе при изменении этого модуля будет пересобрано больше модулей. Часто такие лишние зависимости остаются как раз после рефакторинга.
Это, без сомнений, полезная работа, которую нужно стараться делать. И она позволит улучшить не только скорость сборки вашего проекта, но и его архитектуру в целом.
Заключение
Я рассказал о разных возможностях оптимизации сборки Gradle-проекта. Каждая из рассмотренных оптимизаций улучшала скорость сборки нашего проекта на разные значения, где-то это были буквально 1–2%, где-то — и все 10%, так что могу смело их рекомендовать. Помните, что локальная скорость сборки напрямую влияет на производительность вашей команды, поэтому ей необходимо заниматься. И надеюсь, что эта статья поможет вам понять, с чего можно начать.
Конечно, мы обсудили не всё. Мы не говорили об альтернативных системах сборки, например о Bazel, но это уже совсем отдельная тема. Также мы умолчали про кодогенерацию, хотя, скорее всего, в большинстве текущих проектов она приносит основную боль. Эту проблему мы тоже научились решать — постараюсь позже поделиться с вами подробностями, так что ещё увидимся.
