Как мы создали систему оповещения о ядерной угрозе, или как я обучил нейросеть на заголовках Хабра
Заголовок статьи может показаться странным и это неспроста — он прекрасен именно тем, что написал его не я, а LSTM-нейросеть (а точнее его часть перед «или»).
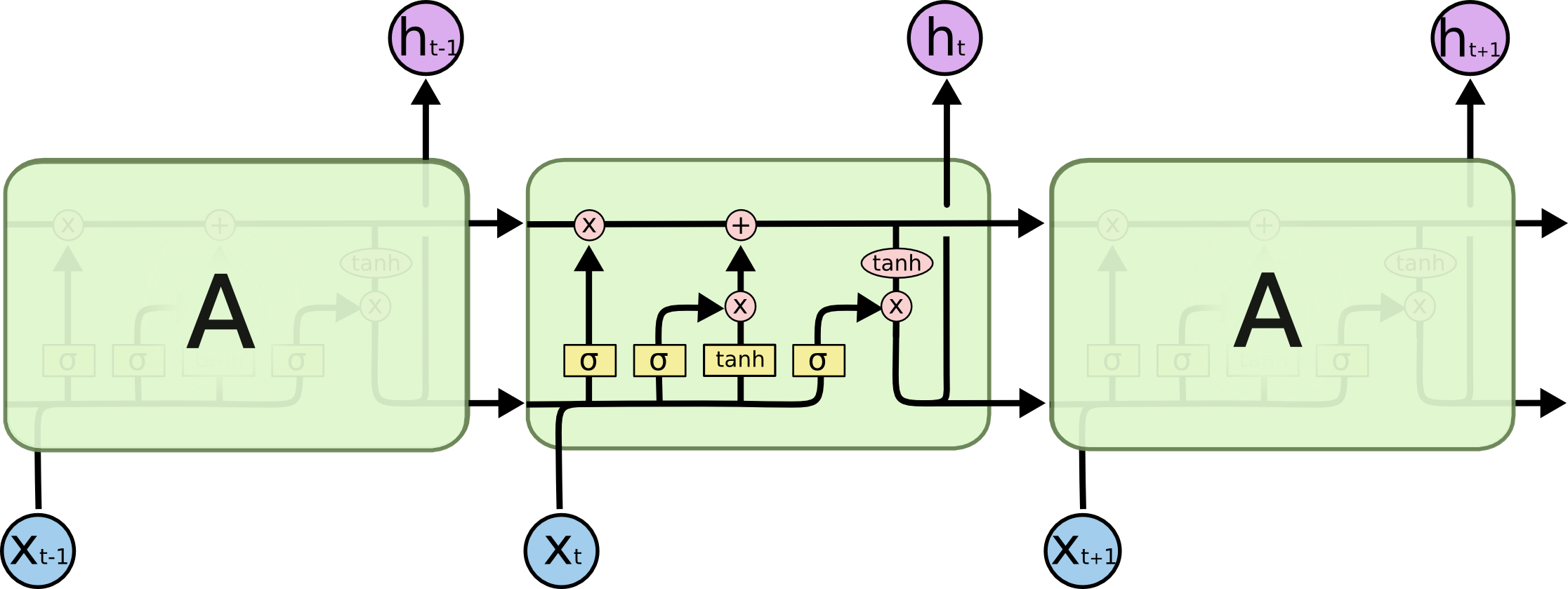
(схема LSTM взята из Understanding LSTM Networks)
И сегодня мы разберёмся, как можно генерировать заголовки статей Хабра (и в принципе сам текст можно генерировать этой же нейро-архитектурой). Весь код доступен для запуска онлайн в notebooks от Гугла. Данные, как всегда, открыты на github.
А вот здесь можно запустить уже обученную модель на GPU от Гугла (бесплатно и без смс) и собственно погенерить заголовки.
Теория и описание нейросетей (в частности LSTM) в этой статье основаны на
Всего было собрано порядка 40k заголовков статей: каждый заголовок был дополнен двумя спец символами
Пример из собранных данных:
Маленький ноутбук для системного администратора
Почему я ушёл из Google и начал работать на себя
Почему работать в IT не так уж и классно
Богатейшие гики Кремниевой долины начали готовиться к апокалипсису
Тема бронелифчиков в культуре Востока и Запада
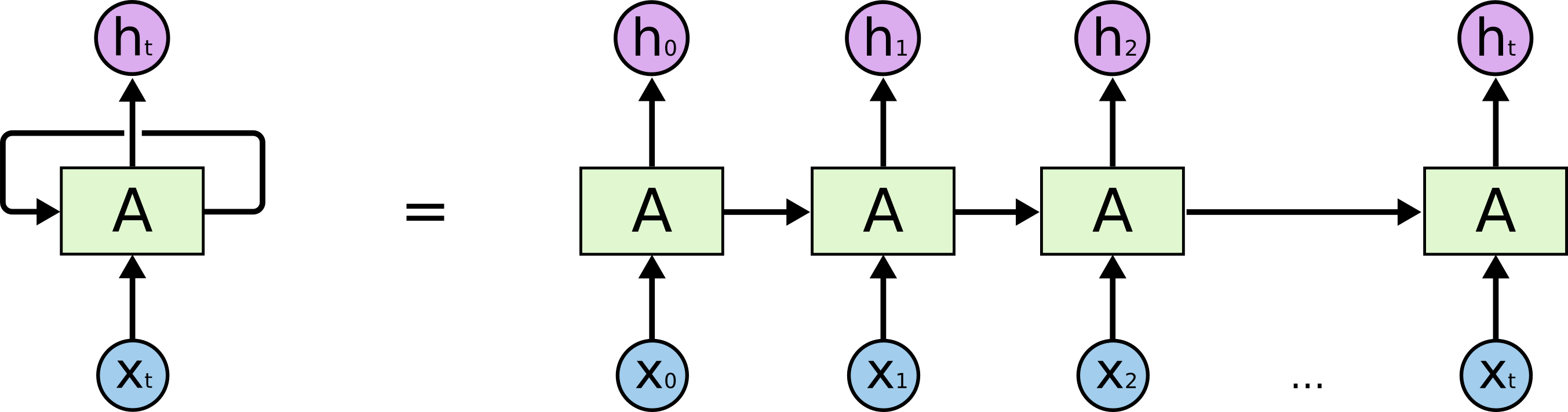
Амиго всё. Now it's officialНачнем с того, какую собственно задачу мы решаем: мы хотим по строке в N символов предсказать (N+1)-ый, иллюстративно с точки зрения LSTM модели это выглядит, как на картинке ниже: иксы снизу — входные данные; hi сверху — выходные; между ними — внутреннее состояние сети. Чуть подробнее — изображение слева с петлёй обратной связи, эквивалентно развернутой цепочке справа.
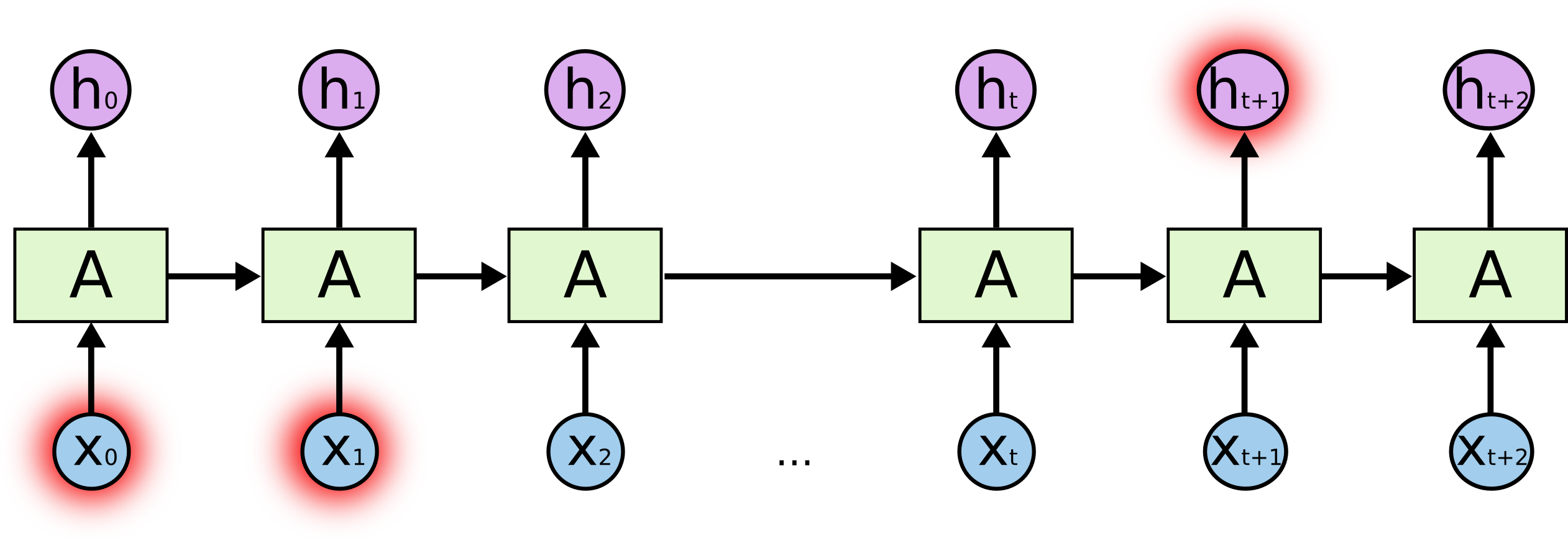
В чём соль? В предсказании выделенного символа в конце могут играть ключевую роль символы, выделенные в начале — отсюда и термин Long-Term Dependencies. Понятно, что часто существенную роль играют и непосредственно стоящие рядом символы — такие зависимости называются Short-Term Dependencies.
Внутренности ячейки LSTM:
Ячейка целиком содержит четыре основных элемента.
- Гейты забывания — элемент решает, что уйдет из памяти
- Входящий гейт — он создает набор «значений кандидатов», которые мы можем использовать для записи и апдейта памяти
- Память — элемент решает, что собственно и как мы сохраним
- Выходной элемент — определяет вывод модели
Обозначения:

Гейт забывания
Если мы пытаемся предсказать окончание слова — важно знать пол текущего существительного, если мы увидели новое существительное — стоит забыть предыдущее значение:

Входящий Гейт
Далее, мы вычисляем it, которые определит какие значения ячейки памяти мы хотим обновить, а

вычисляет значения «кандидаты» для обновления.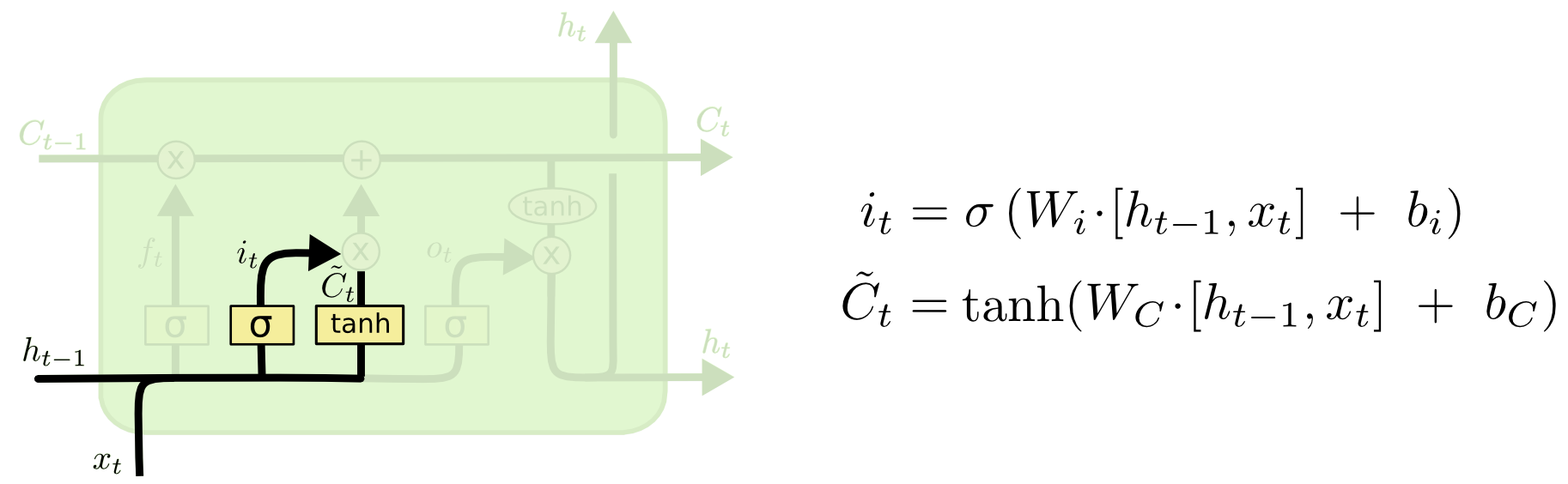
Ячейка памяти
Дальше, значения памяти — это суперпозиция того, что мы забыли в текущем состоянии и того, что мы добавили

Вывод модели
Что такое вывод модели — это комбинация трех вещей: текущего входного символа, предыдущего предсказания и памяти модели

Ниже представлена основная логика модели, как правило — это примерно 5–10% всего кода, весь оставшийся код — очистка, подготовка и обработка данных, а также вывод в человеко-читаемом виде.
Здесь можно запустить код с уже обученной моделью.
model = Sequential() # Создает линейную модель из ряда слоев
model.add(LSTM(unit_size, input_dim=num_chars, return_sequences=True)) # первый слой LSTM ячейка
# за ним чередуем Dropout + LSTM
for i in range(num_layers - 1):
model.add(Dropout(dropout))
model.add(LSTM(unit_size, return_sequences=True))
# Заканчиваем еще одним слоем регуляризации dropout
model.add(Dropout(dropout))
# Применяем полносвязный слой к каждому временному окну
model.add(TimeDistributed(Dense(num_chars)))
# Превращаем веса в вероятности
model.add(Activation('softmax'))
# Компилируем, выбираем метод оптимизации и метрику
model.compile(optimizer=optimizer, loss='categorical_crossentropy')Персональная выборка:
простой способ создания продукта и почему в этом виноват ии
как мы создали собственный сервер с помощью python
как мы построили сервис по поиску уязвимостей на сайтах
простой способ получить пользу от мероприятия и создать себе имя
как сделать ваше приложение быстрее
как создавать сервис для всех проектов
простой способ обратной связи в россии
простой способ поддерживать информацию о внешнем мире
как создать свой стартап или как я перестал беспокоиться о спаме и полюбил его грант джордан
поддержка проекта с помощью powershell(особенно радуют случайные референсы модели к Dr. Strangelove)
Что такое температура (в контексте DL)
На выходе модель порождает веса xw слов w — у нас есть опции, как эти веса превратить в вероятности p (w), например по формуле:

Где T — свободный параметр (в физике именно так статистически определяется температура — отсюда и название), чем меньше температура — тем больше показатель экспоненты и высокие веса «заберут себе» всю вероятность, т.е., модель будет предсказывать только несколько слов с максимальными весами, если температура большая, то распределение будет двигаться к равномерному и больше «креативить». Это дает нам возможность контролировать баланс между точным следованием имеющимся данным и условным творчеством модели.
using temperature 0.03
как мы построили сервис по поиску уязвимостей на сайтах
как мы построили сервис по поводу проекта с помощью python
как мы построили сервис по поводу проекта с помощью sql azure federations часть 2 исходные данные
temperature 0.04
простой способ получить пользу от мероприятия и создать себе имя
как мы создали свой код разбираемся в конфигурации
простой способ получить количество программиста в рамках devcon 2013
temperature 0.05
как мы создали собственный сервер с помощью python
как мы создали свой код разбираемся в конфликте
как мы построили сервис оценки реальных задач и веб разработчика
temperature 0.06
как мы построили сервис оценки реальных задач с jbreak часть 2
как мы построили сервис по машинному обучению главы 10 19
как мы построили сервис по созданию своего бизнеса
temperature 0.07
как мы создали систему программистов и приложений
как сделать ваше приложение быстрее
простой способ создания продукта и почему не стоит смотреть порно на рабочем месте
temperature 0.08
почему не стоит использовать сервер на php
почему вам не просто и быстро
как мы создали свой код в 10 раз
temperature 0.09
почему вам нужно знать о создании игры составь слова
как мы построили сервис по поводу прав на unix
как мы построили сервис оценки ресурсов и мониторинга баз oracle
temperature 0.1
как мы построили сервис по продуктам на полной удаленке
как мы проводили программирование в php
как мы создали свой стартап из старого железа
как мы подготовили стартап проектов в россии
temperature 0.11
как построить поддержку android приложений с помощью android studio
почему вам нужно знать о безопасности пользователей по github используя vue js
как мы проводили программирование в php и ruby
temperature 0.12
простой способ создания продукта и почему в этом виноват ии
как мы построили сервис оценки эффективности работы с пользователями asp net
простой способ создания продукта
temperature 0.13
как мы делали сервис по созданию своего бизнеса
почему стоит использовать продуктовые решения для google glass
как мы создали систему оповещения о ядерной угрозе
using temperature 0.14
почему вам не сервис по созданию своего блокчейна и криптовалют
как начать пользователя и не сойти с ума
как построить поддержку android приложений
temperature 0.15
как мы создали новый стандарт для новой процессорной компании
простой способ создания проекта с помощью python
как построить поддержку android приложений с помощью sql azure federations часть 2 исходные данные
temperature 0.16
как мы проводили программу создания проекта
как мы построили сервис под windows
подключение проекта с помощью python
using temperature 0.17
создание и развертывание в scala
как мы создали интернет проект с помощью apache solr ч 1 учимся
как настроить процесс по созданию сервера на c, часть 2 3
temperature 0.18
создание процессов проекта с помощью python
как мы подготовили стартап по сети
как начать продавать продукты на страницы сайта плагинами браузеров cpatext content security policy
temperature 0.190
полезные материалы для мобильного разработчика 52 28 мая 27 мая
разработка игр под nes на c главы 1 3 подготовка данных в облаке
как начать пользоваться scanner
temperature 0.2
простой способ получить облачную инфраструктуру сервисы в своей компании
обзор программного обеспечения для создания google chrome и ms ie
простой способ построить колонизацию проекта- LSTM-архитетура хорошо и наглядно моделирует последовательности
- Грамматика и логика часто страдают — скорее всего проблемы в двух местах: первое, устройство памяти достаточно простое и не может уловить все правила и контекст; второе, мощность корпуса — датасет достаточно небольшой и не слишком разнообразен
- Было бы интересно взглянуть на вариант Better Language Models and Their Implications на большом корпусе русского языка — понять, решает ли архитектура и более мощный корпус указанные проблемы
- Некоторые из заголовков вышли невероятно смешными и само-ироничными, например,»… и почему в этом виноват ии»
- Мы видим определенные закономерности заголовков Хабра, например, «мы сделали\создали\построили», явный индикатор того, что люди любят делиться персональными историями на Хабре
