Как мы следим за качеством unit-тестов

Меня зовут Александр Чекунков, я — Android‑разработчик в СБЕРе. Разрабатываю CSI‑опросы в мобильном приложении «СберБанк Онлайн», отвечаю за функциональность, которую используют бизнес‑команды для оценки удовлетворённости клиентов.
Во многих крупных компаниях написание unit‑тестов является ключевым этапом при разработке нового функционала. Тесты позволяют выявлять ошибки на ранних стадиях, служат своего рода документацией, помогая другим разработчикам быстрее понять, как должен работать тестируемый компонент системы. Также, в отдельных случаях, тесты помогают выявить и минимизировать зависимости между частями кода, что упрощает его поддержку и развитие.
Про основы unit‑тестирования мы уже говорили в этой статье.
Но для того чтобы получить максимальную пользу от тестов, важно писать их правильно. В этой статье мы обсудим best practices, применяемые командой СБЕРа для написания тестов, и рассмотрим подходы для повышения их эффективности.
Выбор библиотек и технологий
Эффективность разработки тестов зависит от выбранных инструментов. В наших проектах мы чаще всего используем JUnit5, MockK и Truth. Расскажу, почему мы выбрали эти инструменты.
JUnit5. При выборе библиотеки для unit‑тестирования на Java и Kotlin первыми на ум приходят JUnit4 и JUnit5. Мы остановились на более современной версии, которая значительно улучшена по сравнению с JUnit4. Этот фреймворк предоставляет более гибкие возможности для написания и выполнения тестов, что делает его предпочтительным выбором. Подробнее о причинах выбора JUnit5 вы можете узнать в этой статье.
MockK. При выборе инструмента для мокирования в Kotlin обычно рассматривают Mockito и MockK. Поскольку наши проекты написаны преимущественно на Kotlin, мы остановились на MockK. Эта библиотека изначально разработана с учётом особенностей Kotlin, и это делает работу с ней более естественной и удобной. Она поддерживает ключевые возможности языка, обеспечивая при этом мощные инструменты для создания заглушек и верификации поведения.
Truth. Для проверки утверждений мы выбрали библиотеку Truth, так как она предлагает лаконичный и читаемый синтаксис для написания assert’ов. В отличие от стандартных инструментов, Truth делает тесты более понятными. Её выражения строятся так, что их можно читать как обычные английские предложения, что делает код интуитивно понятным и снижает когнитивную нагрузку.
Типичные проблемы
Проблемы производительности unit‑тестов часто остаются незамеченными до тех пор, пока они не начинают серьёзно влиять на процесс разработки. Замедленные тесты, сложность их поддержки и нерациональное использование инструментов могут превращать удобный процесс тестирования в настоящую головную боль. Рассмотрим наиболее распространённые проблемы и способы борьбы с ними.
Заранее отмечу, что все замеры в этой статье проводились на ограниченном наборе тестов в небольшом проекте. Я сделал их для наглядной демонстрации, как различные подходы действительно влияют на скорость выполнения. В реальных проектах с большим количеством тестов разница в производительности может быть значительно заметнее.
Долгое выполнение тестов
Одна из очевидных, на первый взгляд, проблем unit‑тестов — их долгое выполнение. Тесты, которые должны выполняться за миллисекунды, могут неожиданно замедляться и потреблять больше ресурсов.
Причины этого часто кроются в использовании ненужных зависимостей — то есть компонентов, которые тест не должен затрагивать, но которые оказываются вовлечены в процесс выполнения. Например, если тест требует инициализации сложного объекта, а тот, в свою очередь, подтягивает реальную базу данных или внешний сервис, то это делает тест избыточно тяжёлым.
Ещё одна распространённая ошибка — некорректное использование зависимостей. Вместо моков в тестах может случайно использоваться реальный сервер, база данных или файловая система. Это не только замедляет выполнение тестов, но и создаёт дополнительные риски: непредсказуемость результатов, неконсистентность и т. д.
Решение достаточно простое: минимизировать влияние реальных зависимостей. Вместо обращения к базе данных, файловой системе или внешним API в тестах следует использовать моки или фейковые объекты.
Кроме того, мы рекомендуем регулярно отслеживать время выполнения тестов и отслеживать те тесты, которые выполняются слишком долго. Анализ производительности я затрону ниже.
Неэффективное использование моков и библиотек
Моки — мощный инструмент для тестирования, но их неправильное использование может существенно ухудшить производительность. Чрезмерное количество моков или сложные конфигурации могут делать тесты менее читаемыми и трудными в сопровождении. Например, избыточное мокирование всех методов класса, даже если они не используются в тестах, усложняет тесты.
Следует мокировать только те зависимости, которые действительно нужны. Использование библиотеки MockK позволяет писать лаконичные моки:
// Подменяем реальный вызов getData() на заранее подготовленный объект (mockData)
every { service.getData() } returns mockDataНо и этот инструмент можно использовать неэффективно. В нашей команде мы избегаем глубокой вложенности при использовании моков:
// Лучше так не делать:
every { service.api.repository.data } returns mockDataЗдесь происходит мокирование нескольких уровней зависимости — service.api.repository.data. Это не только затрудняет восприятие, но и может привести к проблемам с производительностью. MockK будет поочерёдно проверять каждый уровень на соответствие, а для каждого уровня потребуется конфигурировать мок. Это потребует дополнительных вычислений или проверок, даже если эти зависимости не используются в тесте.

Понимание проблем и их устранение помогает не только ускорить выполнение unit‑тестов, но и сделать их более надёжными, понятными и лёгкими в сопровождении, а это, в свою очередь, способствует повышению общей производительности команды и качества программного обеспечения.
Эффективная организация тестов
В нашей работе мы постоянно уделяем внимание структуре и организации unit‑тестов, ведь правильная их организация способствует улучшению читаемости и упрощает нам их поддержку. В проектах мы сосредотачиваемся на следующих ключевых аспектах.
Соблюдение структуры Arrange-Act-Assert
Использование четкой структуры Arrange‑Act‑Assert (AAA) в unit‑тестах помогает сделать их более понятными и организованными.
Arrange — блок инициализации. В этом блоке создаются необходимые условия для теста, включая объекты и моки, чтобы обеспечить контролируемую среду.
Act — блок действия. В нём выполняется действие, которое необходимо протестировать.
Assert — блок проверки. В нём проверяются результаты выполнения действия для подтверждения того, что поведение кода соответствует ожиданиям.
Хотя не каждый тест обязательно должен содержать все три блока, их наличие делает тесты читаемыми и понятными. Вот пример теста с плохо выстроенной структурой AAA:
import org.junit.jupiter.api.Test
import org.junit.jupiter.api.Assertions.*
import io.mockk.*
class UserManagerTest {
private val userRepository = mockk()
private val emailValidator = mockk()
private val userManager = UserManager(userRepository, emailValidator)
private var savedUser: User? = null
@Test
fun `test user creation and multiple conditions`() {
every { emailValidator.isValid(any()) } answers {
val email = firstArg()
return@answers email.contains("@") && email.length > 5
}
every { userRepository.save(any()) } answers {
val user = firstArg()
savedUser = user
return@answers user
}
every { userRepository.findById(1) } answers {
return@answers savedUser
}
val user = userManager.createUser("Alice", "alice@example.com")
assertNotNull(user)
assertTrue(user.id > 0)
assertTrue(user.email.contains("@"))
assertEquals("Alice", user.name)
if (user.role != "USER") {
fail("Role should be USER")
}
val fetchedUser = userRepository.findById(1)
assertNotNull(fetchedUser)
if (fetchedUser != null) {
if (fetchedUser.name != "Alice") {
fail("Fetched user name is incorrect")
}
if (fetchedUser.email != "alice@example.com") {
fail("Fetched user email is incorrect")
}
}
// Проверка не связанная с юзером
val list = listOf(1, 2, 3)
assertTrue(list.contains(2))
assertFalse(list.isEmpty())
assertEquals(3, list.size)
}
} А теперь тот же тест, но с чётко выстроенной структурой. Какой из вариантов выглядит приятнее?
import org.junit.jupiter.api.Test
import com.google.common.truth.Truth.assertThat
import io.mockk.*
class UserManagerTest {
@Test
fun `create user successfully`() {
// Arrange
val userRepository = mockk()
val emailValidator = mockk()
val userManager = UserManager(userRepository, emailValidator)
every { emailValidator.isValid("alice@example.com") } returns true
every { userRepository.save(any()) } answers { firstArg() }
// Act
val user = userManager.createUser("Alice", "alice@example.com")
// Assert
assertThat(user).isNotNull()
assertThat(user.id).isGreaterThan(0)
assertThat(user.name).isEqualTo("Alice")
assertThat(user.email).isEqualTo("alice@example.com")
assertThat(user.role).isEqualTo("USER")
}
@Test
fun `fetch user by id`() {
// Arrange
val userRepository = mockk()
every { userRepository.findById(1) } returns User(1, "Alice", "alice@example.com", "USER")
// Act
val fetchedUser = userRepository.findById(1)
// Assert
assertThat(fetchedUser).isNotNull()
assertThat(fetchedUser!!.name).isEqualTo("Alice")
assertThat(fetchedUser.email).isEqualTo("alice@example.com")
assertThat(fetchedUser.role).isEqualTo("USER")
}
} Документация тестов
Хорошо задокументированные тесты помогают новым участникам команды быстрее разобраться в проекте, а также ускоряют процесс ревью, снижая нагрузку на ревьюеров.
Чёткая документация тестов помогает нашей команде зафиксировать договорённости внутри команды, снизить технический долг и служит справочным материалом, особенно при сложной логике тестируемого кода.
По нашему опыту, всегда следует добавлять Test к названиям тестовых классов. Например, если у вас есть класс MainViewModel, то назовите тестовый класс для него MainViewModelTest.
Чёткие и описательные названия тестов также играют важную роль. Это кажется очевидным, но важно отметить, что вместо общих названий, вроде test1, лучше использовать осмысленные названия, такие как fetch data when flag is enabled returns success. Это снижает когнитивную нагрузку на читающих код.
Благодаря тому, что мы выбрали JUnit5, мы можем воспользоваться предоставляемыми им встроенными инструментами. Рассмотрим аннотацию @DisplayName, которая позволяет задать читабельное описание для теста или тестового класса, отображаемое в отчётах. Это облегчает уточнение контекста теста, особенно в сценарии со множеством различных наборов условий тестирования.
@DisplayName("Тесты для Calculator")
class CalculatorTest {
@Test
@DisplayName("Проверка сложения двух чисел")
fun `calculateTwoNumbers returns correct sum`() {
// arrange
val firstNumber = 5
val secondNumber = 3
val expected = 8
// act
val actual = calculator.calculateTwoNumbers(firstNumber, secondNumber)
// assert
assertThat(actual).isEqualTo(expected)
}
}Для параметризованных тестов в JUnit5 аннотации, такие как @ParameterizedTest, позволяют добавить поясняющие названия к каждому тестовому набору.
@ParameterizedTest(name = "Проверка суммы: {0} + {1} = {2}")
@CsvSource(
"1, 2, 3",
"5, 3, 8",
"10, 15, 25"
)
fun `calculateTwoNumbers returns correct sum`(a: Int, b: Int, expected: Int) {
// act
val result = calculator.calculateTwoNumbers(a, b)
// assert
assertThat(result).isEqualTo(expected)
}Если тестовый класс или метод покрывает набор кейсов, то мы используем аннотацию @Tag. Она позволяет классифицировать тесты, что бывает полезно для фильтрации в отчётах или при выполнении тестов.
@Tag("fast")
@Test
fun `quick calculation test`() {
// Тест, который выполняется быстро
}Рекомендуем обратить внимание на возможности JUnit5, чтобы сделать ваши тесты ещё более понятными и наглядными. Такой подход делает тесты не просто инструментом для проверки, но и частью культуры разработки.
Грамотное использование доступных инструментов
Для достижения максимальной производительности в unit‑тестировании недостаточно просто выбрать современные библиотеки. Всегда хочется использовать весь их потенциал на полную мощность. Инструменты, которые мы используем в наших проектах, предоставляют множество полезных функций, которые не только ускоряют выполнение тестов, но и влияют на качество проекта в лучшую сторону.
JUnit5 — ускорение и гибкость тестов
1. Использование параллельного выполнения тестов.
JUnit5 позволяет запускать тесты независимо друг от друга, значительно сокращая время тестирования в проектах с большим числом тестов. Для включения этой функции необходимо настроить файл конфигурации junit-platform.properties (подробнее здесь):
junit.jupiter.execution.parallel.enabled = true
junit.jupiter.execution.parallel.mode.default = concurrent Также можно настроить уровень параллелизма:
junit.jupiter.execution.parallel.config.strategy = fixed
junit.jupiter.execution.parallel.config.fixed.parallelism = 4 Для примера я измерил длительность выполнения 68 тестов разных по уровню сложности в модуле при включённом и отключённом параллельном запуске, получились такие результаты:
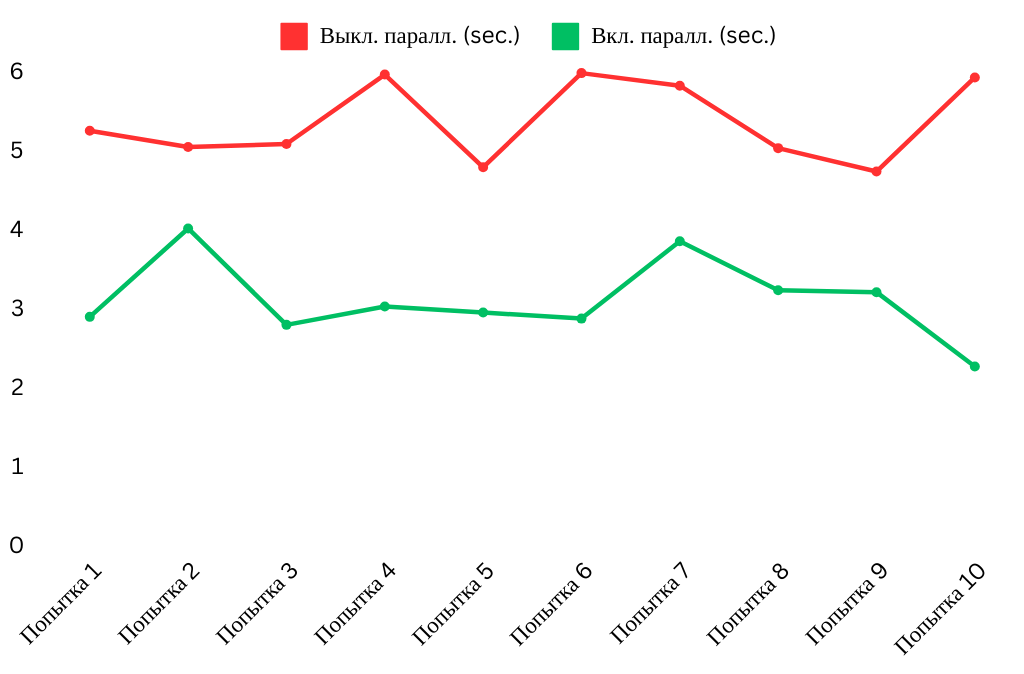
2. Использование параметризованных тестов для сокращения повторений.
При тестировании функций с разными входными данными часто возникает дублирование кода. JUnit5 позволяет решить эту проблему с помощью параметризованных тестов, которые автоматически запускают метод с различными наборами данных.
@ParameterizedTest
@ValueSource(ints = [2, 4, 6, 8])
fun `should return true for even numbers`(number: Int) {
val result = isEven(number)
assertTrue(result)
}Разумное использование параметризированных тестов в большинстве случаев уменьшает количество дублирующего кода, делая тесты компактными и читаемыми. Это также упрощает добавление новых входных данных, что ускоряет процесс написания кода.
3. Использование аннотации @Nested для структурирования тестов.
В крупных тестовых классах со множеством методов становится трудно ориентироваться. Аннотация @Nested позволяет группировать тесты по смысловым блокам, улучшая их читаемость и организацию.
class CalculatorTest {
@Nested
inner class AddOperationTests {
@Test
fun `should add two positive numbers`() {
val result = calculator.add(3, 5)
assertEquals(8, result)
}
@Test
fun `should add positive and negative number`() {
val result = calculator.add(3, -2)
assertEquals(1, result)
}
}
@Nested
inner class SubtractOperationTests {
@Test
fun `should subtract smaller number from larger`() {
val result = calculator.subtract(5, 3)
assertEquals(2, result)
}
@Test
fun `should subtract larger number from smaller`() {
val result = calculator.subtract(3, 5)
assertEquals(-2, result)
}
}
}Благодаря этой аннотации тесты легко структурируются по функциональным блокам, что упрощает их организацию, делая код более логичным. У себя в команде мы отметили, что подобная структура облегчает навигацию, позволяя понять цель и логику как каждого теста, так и всей структуры в целом.
На самом деле JUnit5 предлагает широкий набор мощных и инновационных инструментов, с которым рекомендуем ознакомиться в официальной документации или в этой статье.
MockK — тонкости мокирования
1. Использование relaxed-мока для автоматического возврата значений по умолчанию.
relaxed-моки позволяют автоматически возвращать стандартные значения, предопределённые MockK, для всех вызовов методов. Например, для String это », для Int — 0, для Boolean — false, а для списков — пустые коллекции.
Такое поведение снижает количество явных настроек и упрощает тесты, особенно в случаях, когда тестируемый код не использует результаты всех вызовов.
val mock = mockk(relaxed = true)
// Нет необходимости явно настраивать вызов mock.getData()
println(mock.getData()) // Output: "" (пустая строка, значение по умолчанию)
---
// Если нужно изменить поведение:
every { mock.getData() } returns "Кастомное значение"
println(mock.getData()) // Output: "Кастомное значение" 2. Использование clearMocks для освобождения ресурсов.
В больших наборах тестов ненужные моки могут занимать память, что увеличивает время выполнения тестов. По умолчанию очисткой памяти занимается Garbage Collector, но он не всегда срабатывает мгновенно, особенно если объекты хранятся в статических переменных.
В таких случаях моки могут сохранять состояние между тестами, что приводит к неожиданным результатам и трудноуловимым багам. Использование clearMocks помогает явно очищать настройки и вызовы моков после прогона теста, предотвращая утечки памяти и обеспечивая корректное выполнение тестов.
class UserServiceTest {
private val mockApi = mockk()
private lateinit var userService: UserService
@BeforeEach
fun setup() {
userService = UserService(mockApi)
}
@AfterEach
fun clear() {
clearMocks(mockApi) // Освобождаем ресурсы
}
@Test
fun `test getUserById`() {
every { mockApi.fetchUser(1) } returns "John Doe"
val result = userService.getUserById(1)
verify { mockApi.fetchUser(1) }
assert(result == "John Doe")
}
} 
Truth — читаемые и лаконичные ассерты
1. Работа с типами Java Optional и Kotlin nullable.
Truth предоставляет встроенные проверки для типов Optional из Java и nullable из Kotlin, упрощая тестирование данных, которые могут быть отсутствующими.
@Test
fun `test Optional and nullable values`() {
val optionalValue = java.util.Optional.of("Hello World")
val nullableValue: String? = "Kotlin is awesome"
// Проверка Optional
assertThat(optionalValue).isPresent()
assertThat(optionalValue).hasValue("Hello World")
// Проверка nullable значений
assertThat(nullableValue).isNotNull()
assertThat(nullableValue).isEqualTo("Kotlin is awesome")
}Встроенные методы позволяют тестировать присутствие или отсутствие значений без дополнительных проверок на null или isPresent(), экономя время и делая тесты чище.
2. Кастомные проверки с помощью Subject.
Truth поддерживает создание кастомных Subject, что позволяет писать проверки, специфичные для проекта.
data class User(val id: Int, val name: String, val email: String)
class UserSubject private constructor(subject: User) : Subject(UserSubject::class.java, subject) {
fun hasEmail(expectedEmail: String) {
check("email").that(actual.email).isEqualTo(expectedEmail)
}
fun hasName(expectedName: String) {
check("name").that(actual.name).isEqualTo(expectedName)
}
companion object {
fun users(): Factory = Factory { metadata, actual -> UserSubject(actual) }
}
}
@Test
fun `test custom subject`() {
val user = User(1, "John Doe", "john.doe@example.com")
assertAbout(UserSubject.users()).that(user)
.hasEmail("john.doe@example.com")
.hasName("John Doe")
} Кастомные проверки позволяют нам тестировать сложные объекты, такие как User, с минимальной нагрузкой на тестовый код, ускоряя написание тестов.
Продвинутое использование возможностей JUnit5, MockK и Truth не только ускоряет выполнение тестов, но и повышает их структурированность и упрощает поддержку. Эти библиотеки позволяют оптимизировать процессы тестирования, минимизировать ошибки и обеспечивать высокий уровень качества кода. Интеграция их функционала в повседневную практику разработки превращает тестирование в эффективный и удобный этап работы.
Регулярный анализ производительности
Регулярный анализ производительности unit‑тестов играет ключевую роль в нашем проекте для поддержания их эффективности и минимизации влияния на общий процесс разработки. Даже хорошо написанные тесты со временем могут начать замедлять сборку проекта из‑за роста кода, изменения зависимостей, в том числе обновления библиотек, или введения новых функциональностей, поэтому важно не только создавать качественные тесты, но и регулярно проводить их оценку.
На что мы обращаем внимание при анализе производительности?
Выявление «тяжёлых» тестов. Некоторые тесты, по разным причинам, могут потреблять чрезмерное количество ресурсов из‑за неоптимального использования моков, большого количества вызовов внешних методов, долгих операций инициализации и т. д.
Оптимизация времени сборки. В крупных проектах увеличение времени выполнения одного теста даже на несколько секунд может негативно сказаться на скорости разработки.
Раннее устранение проблем. Мониторинг выполнения тестов помогает предотвратить накопление проблем, которые могут привести к деградации производительности.
Как мы проводим анализ производительности?
Инструменты в Android Studio. Фреймворк предлагает встроенные возможности для профилирования и анализа тестов.
Запуск тестов через вкладку
Runи использование тайминга выполнения, чтобы выявить медленные тесты.Использование вкладки
Test Results, чтобы отсортировать тесты по времени выполнения и сразу увидеть, какие из них требуют внимания.
Логирование производительности.
В случае, если мы понимаем, что выполнение части кода необходимо производить за контролируемый отрезок времени, можно добавить аннотацию
@Timeout. Она помогает выявлять тесты, которые выполняются слишком долго.
Профайлеры JVM. Для более глубокого анализа можно использовать дополнительные инструменты. В этой статье мы не будем детально разбирать их возможности, но если вам интересно изучить тему подробнее, обратите внимание на следующие:
VisualVMпозволяет выявлять медленные методы, мониторить использование памяти и анализировать поведение тестов во время их выполнения.JProfilerилиYourKitпредоставляют детализированную информацию о потоках, загрузке CPU и использовании объектов.
Как часто мы проводим анализ производительности?
Регулярность анализа. На нашем проекте прогон всех тестов выполняется постоянно — они запускаются на каждом Pull Request, проходят в ночных сборках, а также сопровождаются подробными отчетами по каждому модулю. В случае возникновения проблем автоматически формируется уведомление с детализацией ошибки, которое отправляется в команду, что позволяет оперативно реагировать на возможные сбои.
При изменении инфраструктуры. Наша команда всегда повторно проверяет производительность тестов после обновления библиотек или перехода на новую версию Gradle. Это позволяет нам убедиться, что изменения не привели к неожиданному замедлению тестов и сохранилась стабильность их выполнения.
Таким образом, можно сделать вывод, что регулярный анализ производительности тестов — это не лишняя нагрузка, а важный этап разработки, который способствует ускорению сборки и повышению качества кода.
Улучшение производительности unit‑тестирования — это инвестиция в устойчивость и скорость разработки. Продуманная организация, правильный выбор инструментов и внимание к деталям позволяют тестам стать не только инструментом контроля, но и основой для уверенности в качестве продукта.
Эта статья создана для разработчиков, которые стремятся сделать свои unit‑тесты приятными для написания и поддержания, так чтобы они стали помощниками в проекте, а не обузой. Надеемся, наш опыт и рекомендации помогут вам определиться с выбором инструментов, избежать ключевых проблем и улучшить качество тестов в ваших проектах.
