Как мы сделали рекомендации, отказались от подрядчика и заработали денег

Привет, Хабр! Меня зовут Данила Федюкин и я тимлид в X5 Digital. Руковожу командой, которая занимается рекомендациями и метчингом. Так получилось, что занимаюсь этим всю свою карьеру. Раньше — в Билайне, последние 2,5 года — в X5. На досуге пишу диссертацию.
X5 Digital — один из цифровых бизнесов крупнейшего ритейлера страны. Работаем в режиме Highload с RPS в 7500 и доставляем продукты в 73 регионах страны. Мы отвечаем за онлайн-канал, то есть за всю доставку. За 2023 год доставили более 75 млн заказов. За 2024 год — свыше 119,5 млн.
Мы создаём собственную in-house WMS для дарксторов, приложения для сборщиков и курьеров, CRM, каталоги товаров и другие онлайн-продукты, делаем мобильное приложение для торговых сетей и онлайн-гипермаркета Vprok.ru.
Делая всё это, отталкиваемся от разных форматов доставки. Из «Пятёрочки» доставка приходит в течение 30 минут, из «Перекрёстка» — в течение часа, из Vprok.ru — за несколько дней, так как речь про большой объём товаров и большую машину.
С чего мы начинали
Персонализация играет ключевую роль в развитии бизнеса. На первых этапах, когда у компании ещё нет собственных решений для адаптации под клиентов, часто приходится обращаться к внешним подрядчикам. Именно так поступили и мы.
У нас был подрядчик, дочерняя компания одной крупной сети общественного питания. Рекомендации были в двух местах:
Карточка товара.
Чек-аут, где пользователь кликает «заказать», выбирает время, оплачивает заказ.
Подрядчик предлагал следующие виды рекомендаций:
Альтернативные товары, то есть товары-заменители. Далее будем называть их заменами. Например, если пользователь заказывает пельмени, а их не оказалось, мы предложим ему равиоли.
Комплиментарные товары или товары-допродажи. Например, если клиент покупает пиво, мы порекомендуем чипсы.
Персональное ранжирование этих двух алгоритмов.
Но работа с подрядчиком для нас оказалась дорогой, болезненной и долгой. Раскрою эту мысль историей.
История 0: работа с подрядчиком

В 2022 году многие компании, особенно с главным офисом за рубежом, уходили с нашего рынка. Они закрывали старое юрлицо, открывали новое, зарегистрированное в России и продолжали работу, уже никак не связанную де-юре с зарубежной компанией.
Наш подрядчик решил сделать по такой же схеме. Когда компания зарегистрировалась как российское юрлицо, нужно было сделать реинтеграцию алгоритмов, которые контрагент нам предоставлял как коробку. На интеграцию выделили три недели, на настройку логов ещё неделю. Решили, что за четыре недели справимся.
Но реальность сыграла с нами злую шутку.

По воле обстоятельств больше недели дорабатывали фиды, которые отправляли подрядчику. Потом ещё 11 недель фиксили события, которые тоже отправляли подрядчику, потому что они почему-то тоже изменились. Ещё почти шесть недель ушло на важные для бизнеса кастомные события, которые, опять же, стали другими. В придачу потратили время на настройку логов. В результате вместо месяца ушло почти полгода.
Зато убедились, что нас это не устраивает и рушит планы. Решили делать in-house.
История 1: замены

Начали с замен. Ведь замена — это наиболее важная часть в рекомендациях в e-grocery. Обеспечить стопроцентную доступность всех товаров на полке — крайне сложная, почти невозможная и очень дорогая задача. В идеале операционно это можно сделать лишь на 95%, а остальное добивать товарами-заменителями.
Есть конкретная особенность работы во Vprok.ru. Поскольку заказ может быть большим и его можно заказать на 8 утра, то собирать его будут в 5 утра. Если в 5 утра сборщик позвонит и сообщит, что горошка «Бондюэль» нет и предложит взять «Дядю Ваню», клиент не обрадуется. И будет абсолютно прав! Мы не хотим такого допускать.
Проще сделать контентные рекомендации, так как данные для них уже есть в MDM-системе. Но мы вывели принципы, на основе которых будем отказываться от подрядчиков в пользу in-house. Для этого:
Начали с простого решения, чтобы быстро итерироваться, посмотреть фидбэк и решить, что делать дальше.
Поскольку задача item—item, то, по факту, наша задача сводится к получению эмбеддингов товаров.
Решение для первой итерации выбрали такое:
Берём имеющиеся данные о товаре.
С помощью TF-IDF-преобразования получаем векторы. TF-IDF-преобразования в данном контексте — это оценка важности слова в наборе документов.
Сохраняем полученные векторы со второго шага в PostgreSQL.
Собираем витрину для каждого товара.
Берём топ-100 похожих по косинусному расстоянию, помещаем это в память, пишем сервис с API на Python и отдаём по ключу товара эти рекомендации, когда к нам придёт каталог.
Пришла пора тестировать. Оказалось, мы просчитались. Кто бы мог подумать, что Python — медленный! Выдача ответов из БД не соответствовала нашим требованиям по latency. Перед нами встала следующая микрозадача — модернизировать схему так, чтобы она выдерживала по latency, и чтобы при разработке других алгоритмов мы могли масштабироваться без серьёзных доработок.
У нас большая экспертиза в Go, поэтому мы реализовали API на нём. У этого API есть база и кэш. Go — быстрый, из-за этого сервис рекомендаций превращается в cron job. Мы хотим сэкономить время, поэтому берём в техдолг поднятие какого-то сложного MLOps вроде Airflow. Получаем решение проблемы со змеями с помощью Go и вот такой схемы:

Мы реализуем схему, сервис замен используется как cron job, пишет в API сформированные предложения и засыпает до следующего обращения. Дальше работает только API рекомендаций и общается уже с каталогом.
Протестировали и всё заработало, latency выдерживает. Пора идти в A/B-тесты! И это оказался наш первый маленький успех.
A/B-тест проходил в карточке товара. Логика такая — если товар отсутствует, то мы отображаем замены. Половина пользователей видит наши рекомендации, другая видит рекомендации подрядчика. Конверсия в покупку с рекомендацией в отсутствующем товаре у нас выросла на 7%, и в абсолюте мы получили тоже значимые цифры.
Первые выводы, которые мы сделали:
Переход с подрядчика на in-house — это дёшево. Потому что никакого rocket science мы не сделали. TF-IDF может сделать любой человек с курсов, «гошную» API тоже можно написать относительно быстро и сразу получить +7% и сэкономить на отказе от подрядчика.
Подход «начинай с простого» работает прекрасно.
Мы, воодушевлённые, выкатили сервис замен на всех наших пользователей и двинулись дальше.
История 2: комплименты
Пришла пора рекомендовать товары для увеличения чека, чтобы клиент, покупающий котлетки, купил по нашей рекомендации ещё и картошку для пюре.
Мы хотели показывать не только популярные товары, потому что они для всех пользователей одинаковые, а рекомендации, зависящие от выбранного товара.
Руководствовались такими принципами:
Решение всё ещё должно быть простым, так как это работает.
Задача по-прежнему item-item, но теперь мы оцениваем не контент товара, а как часто встречаются вместе одни и те же позиции в корзине клиентов.
Мы всё ещё генерируем возможные варианты, пока без персонального ранжирования.
Что нужно было сделать:
Составить матрицу совместных покупок товаров — что с чем покупают.
Посчитать ассоциативные метрики между парами.
Для каждого товара из ассортимента сформировать выдачу из 100 товаров по убыванию этих метрик.
Внедрить в API-сервис Kafka. Чтобы API-сервис менеджерил не эндпойнты, в которые мы обращаемся, а только топики в Kafka.

Мы поместили сервисы и API-рекомендации в Kafka, консьюмили их, прогревали свой кэш и обновляли базу. Схема рабочая. Мы просто пишем новую cron job, как ML.
Короткий ликбез о том, что такое ассоциативные правила.

Представим задачу: есть два товара в чеке, и мы хотим оценить, как часто они встречаются вместе.
Ассоциативные правила — это три метрики:
Support даёт представление о том, насколько часто эти два товара встречаются среди нашего множества чеков.
Confidence — вероятность появления рекомендуемого товара, при условии, что товар, к которому мы подбираем рекомендацию, уже находится в корзине.
Lift (дополнение Confidence) — некая мера увеличения вероятности совместной покупки, но только при условии, что товар X в корзине.
Рассмотрим на конкретном примере:
Есть 1000 чеков, из них:
500 чеков с молоком;
200 чеков с зубной щёткой;
240 чеков с зубной пастой.
Совместные покупки:
150 чеков с зубной щёткой и молоком;
190 чеков с зубной щёткой и пастой;
Задача: Сформировать рекомендации для зубной щётки.
Сначала считаем пару зубная щётка / молоко:
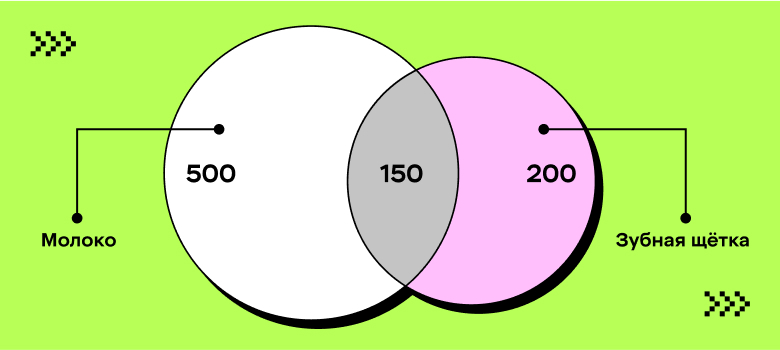
Support = 150/1000 = 0,15
Confidence = 150/200 = 0,75
Lift = (150/200)/500 = 0,0015
Если будем рассматривать пару товаров, это не значит абсолютно ничего, потому что нужна вторая пара товаров, чтобы можно было ранжировать покупки относительно друг друга. Поэтому посчитаем те же самые метрики, только для пары зубная щётка / зубная паста:

Support = 0.19
Confidence = 0.95
Lift = 0.04
Мы можем составить таблицу, где выстраиваем рекомендации, ранжируя по трём метрикам. Условно, к зубной щётке сначала советуем зубную пасту, что вполне логично, а уже потом молоко.

Вроде разобрались. Но есть нюансы.

Поскольку матрица очень широкая, есть проблема длинного хвоста при реализации алгоритма. У нас около 30% товаров отсеивались по минимальному порогу саппорта. Мы решили эту проблему просто — уменьшили порог в десять раз, и для несформированных товаров запустили алгоритм ещё раз. Если есть позиция, которой до 100 не хватает рекомендаций, мы добивали значение популярными товарами.
Поскольку под капотом алгоритм предполагает, что вы держите в памяти матрицу размером (товары * товары), то для расчёта нужна вся матрица. В результате при росте количества позиций увеличивается матрица и, соответственно, потребление RAM. В определённый момент можно столкнуться с тем, что единственный способ масштабирования — вертикальный. Да, можно горизонтально делить по регионам, если у вас в зависимости от региона отличается ассортимент, но всё равно вы дойдёте до момента, когда возможно только вертикальное масштабирование. Это существенный минус.
Но проблем с out-of-memory не случалось, мы вновь запустили A/B-тесты, и нас настигла первая неудача.
A/B-тест проходил в карточке товара «товар в наличии», 50% пользователей видят наши рекомендации, 50% пользователей видят комплементарные предложения от подрядчика. В результате, конверсия в покупку относительно подрядчика упала на 10%. Да, мы по-прежнему выигрываем в экономике, ведь отказываемся от подрядчиков. Но нам не понравился такой вариант. Мы хотели быть лучше по конверсии, так как делаем продукт.
Вывод: нет гарантии, что самый простой вариант сработает, особенно если вы сравните с другой моделью. Если бы мы сравнивали с отсутствием рекомендаций или с популярными товарами, шансы были бы выше.
Немножко раздосадованные, отправились дальше разбираться с персонализацией.
История 3: персонализация
У нас были такие предпосылки:
Наши комплементарные рекомендации не самые классные, поэтому надо переводить пользователей на что-то сильнее.
Бизнес хочет, чтобы в любой момент рекомендации были наиболее релевантны пользовательским интересам.
Давайте подумаем, как реализовать это требование.
Немного изменили наши принципы:
Усложнили решение. Теперь уже не обойтись без полноценных моделей, не отделаться только статистиками, но сначала решили попробовать сделать без нейросетей, чтобы не удариться в rocket science.
Задача трансформируется в user-item, мы идём в коллаборативные рекомендации.
Мы всё ещё генерируем кандидатов, но у нас добавляются два пункта:
Хотим как можно раньше предлагать наши персональные рекомендации, чтобы как можно раньше пользователи отказались от алгоритма cross-sell.
Хотим, чтобы рекомендации были актуальны и подстраивались под смену пользовательских интересов.
Что для этого нужно было сделать
Выбрать ML-модель.
Придумать, как учитывать смену интересов пользователей.
Научиться горизонтально масштабироваться.
Придерживаться наработанных ранее решений, используя cron job в Kafka.

Выбираем модель
Нам важно:
Чтобы из коробки у модели минимизировать проблему холодного старта.
Протестировать разные пороги по совершённым покупкам, чтобы понять, после какой мы можем предлагать нашу персонализацию.
Сравнивать будем LightFM vs ALS по NDCG.
Начали со сравнения моделей, обучили их на покупках клиентов, смотрели предложенные рекомендации и читали по ним NDCG.

Метрики получились не очень, но особенность в том, что мы и не очень качественные данные подали на вход. На тот момент архитектурно тяжело было получить данные по клиентскому взаимодействию, поэтому мы брали косвенные данные о покупках. Но LightFM всё равно оказался чуточку лучше. Выбрали его, начали тестировать наши пороги. Для этого построили метрику роста NDCG в зависимости от количества покупок:

Здесь k — количество совершённых покупок, и оно растёт. Логично, что после 18-й покупки у нас относительно классные метрики, но 18-й заказ — это довольно долго, особенно если доставка длительная. Поэтому мы выбрали на основе наших метрик переход через 0.2, и после третьего заказа предлагаем клиентам наши персональные рекомендации вместо cross-sell.
Учёт изменений интересов пользователей
Мы обсудили с бизнесом и пришли примерно к такому образу результата.
Некий рандомный Валера полгода назад насмотрелся видео про здоровый образ жизни и стал веганом. Но месяц назад увидел на Food.ru много рецептов «Как вкусно приготовить мясо». Теперь Валера уважает гриль, и Валере нужно рекомендовать больше продуктов для мяса, чем для веганов. Визуально это должно выглядеть так:
До того, как Валера зашёл на Food.ru два месяца назад, мы должны были рекомендовать морковь, лук и спаржу, а сейчас — стейки.

С точки зрения математики нужно:
Добавить взвешивание пользовательских взаимодействий относительно времени.
Взвешивание должно стремиться к максимуму, когда пользователь совершил покупку буквально вчера, и стремиться к минимуму, когда не покупал товар давно.
Помним, что у нас разная скорость доставки («Пятёрочка» — быстрее, Vprok.ru — медленней), поэтому подбираем скорость устаревания интересов, чтобы адаптировать модель под разный формат доставки.
Напрашивается что-то связанное с экспонентами:

Как раз с помощью b мы можем подбирать скорость устаревания интересов.
Вот так это выглядит на графике:

Если b стремится в минимальные значения, то график прижимается к оси Y. Если стремится к максимальным значениям, то график будет всё более пологим, скорость устаревания интересов будет замедляться. На основе этого добавляем фичу в модель, умножаем на вес, когда строим матрицу пользователей на товары.
Теперь снова A/B-тесты. В этот раз их два и они раздельные: первый в карточке товара, второй на чек-ауте.
Логика отображения: если авторизованный пользователь имеет больше двух покупок, то мы показываем персональные рекомендации, если меньше или клиент не авторизован, показываем cross-sell. Так 50% пользователей видели наши рекомендации, 50% — подрядчика.
Метрики оказались ошеломляюще высокие — CTR в покупку относительно персональных рекомендаций подрядчика вырос на 56%, средний чек на чек-аут увеличился на 3% и выручка с рекомендацией при использовании каскада, когда для неавторизованных пользователей добавляем cross-sell, поднялась на 60%.
Мы это объяснили вполне логично: работает персональный алгоритм. То есть мы строим user-item матрицу, раскладываем её на две, получаем эмбеддинги клиентов. У подрядчика же индивидуальное ранжирование общего алгоритма. То есть он берёт обычный cross-sell и как-то его персонализирует на основе фидбэка. Поэтому у нас изначально были высокие шансы на успех.
Выводы:
Чёткая формулировка критериев отбора моделей позволяет выбрать оптимальный путь. Это к тому, что должен быть минимальный холодный старт. В LightFM он по факту минимальный, и LightFM в своём whitepaper на этом делает акцент.
Каскад модели, даже если у неё слабые методы, работает лучше, чем отсутствие каскада.
В целом мы удовлетворены и раскатываем каскад на всех пользователей на чек-ауте и карточке товара.
За три большие итерации мы полноценно отказались от подрядчика. И теперь ежемесячно не платим никому деньги за то, чтобы у нас были рекомендации.
Глобальные результаты и выводы
Переход от подрядчика в in-house — это НЕ ДОРОГО. Потому что всё сделано небольшой командой на основе довольно простых базовых алгоритмов, которые уже превосходят подрядчика. Вы выигрываете за счёт того, что получаете больше прибыли как бизнес и экономите на том, что не платите денег другой компании.
При подходе от простого к сложному максимизируем шансы на успех. Это простейшая мысль, но иногда про неё забывают, поэтому лишний раз напомнить об этом не будет лишним.
Если на каком-то этапе не получилось превзойти результаты подрядчика, то можно учиться на его данных. Мы этим не успели воспользоваться, но как вариант можно взять на вооружение. Изучите, как пользователь взаимодействует с рекомендациями подрядчика, научитесь на этом. Как минимум, сравняетесь с подрядчиком, возможно, даже превзойдёте его.
Можно брать в инфраструктурный техдолг, в рамках офлайн ML — это не очень страшно. Мы взяли в инфраструктурный техдолг cron job, и не тратили время на подъём Airflow, MLflow и других безумно полезных вещей. Но на первом этапе, если ML ещё работает в офлайн 1–2 раза в сутки, можно сначала проверить гипотезу, а потом уже поднять то, что упростит работу ML-инженеру.
Следуя этим четырём принципам, вы получите профит.
