Как мы сделали и оптимизировали механизм правил для персонализации UI

Всем привет! Меня зовут Александр, я занимаюсь backend-разработкой в KTS.
В одной из прошлых статей мы рассказали про архитектуру фронтенд-приложения для проекта личного кабинета (ЛК) сотрудников Пятёрочки. В этой статье расскажу, как мы решали проблему персонализации интерфейса пользователя на бэкенде и с какой проблемой столкнулись через какое-то время.
Что будет в статье:
Что такое ЛК и недостатки первой версии
Мы уже писали, что такое личный кабинет сотрудника ЛК2. Если вкратце — это нагруженный сервис личного кабинета, которым пользуются офисные рабочие и сотрудники розничных магазинов: кассиры, супервайзеры, директоры, hr-администраторы и др. Помимо обычного профиля сотрудника в личном кабинете можно оформлять множество разных справок, брать отпуска, отгулы, просматривать информацию о предстоящих и прошедших сменах, зарплате и многом другом.
Как и в любой компании, в Х5 есть иерархическая структура подчинения. У каждого сотрудника может быть одна или несколько ролей в компании. От этого зависят его обязанности и зона ответственности. Для ЛК это означает, что у пользователя, в зависимости от его роли, могут добавляться или изменяться доступные разделы, сервисы, виджеты и т.д. Вот как это выглядело в старой версии личного кабинета ЛК1.
 Рис. 1 — Главная страница ЛК1 у обычного сотрудника
Рис. 1 — Главная страница ЛК1 у обычного сотрудника Рис. 2 — Главная страница ЛК1 у директора магазина
Рис. 2 — Главная страница ЛК1 у директора магазина
Можно заметить, что у директора магазина в ЛК отображаются дополнительные разделы, такие как «Согласование переноса отпусков», «Контроль подписания ЛНА», «Мои заместители» и т.п. Все это настраивается в зависимости от роли сотрудника. Но что, если нужно настраивать внешний ЛК в зависимости от других параметров работника, либо как-то изменять отображение или порядок карточек и сервисов?
В ЛК1 не было возможности динамически настраивать контент под каждого сотрудника или группу. Чтобы изменить, добавить или убрать какой-то раздел или карточку, нужно было передавать задачу в разработку, ждать выполнения, тестировать.
При проектировании новой версии ЛК заказчик попросил сделать динамическую настройку контента и вынести все это в админку сайта, чтобы любой администратор или менеджер мог сам управлять контентом на главной странице и в боковой панели, не прибегая к помощи разработчика. Ниже — скриншот главной страницы пользователя в ЛК2. Для удобства выделили основные UI-компоненты, которые можно настраивать динамически.
 Рис. 3 — Главная страница ЛК2 с выделенными основными компонентами
Рис. 3 — Главная страница ЛК2 с выделенными основными компонентами
Всего получилось 4 основных компонента: баннеры и карточки на главной странице и группа разделов с самими разделами в боковой панели.
Пару слов о бэкенде
Сервисы «Пятёрочки» строятся на микросервисной архитектуре. Наше приложение является основным сервисом интеграции данных из нескольких источников. Это ядро, с которым взаимодействуют фронтенд и другие сторонние команды. Главным источником данных является enterprise-решение — SAP HR. Это мастер-система, в которой хранится вся информация о сотруднике, команде, структуре подчинения компании и многом другом. Взаимодействие происходит через протокол OData. Сам бэкенд написан на Python/aiohttp, а для администрирования сайта использовали старую добрую Django. В качестве БД для хранения необходимых данных используется PostgreSQL.
Итак, вернемся к нашей задаче. В новом ЛК нам нужно уметь динамически кастомизировать отображение компонентов на сайте на основании полученных из SAP HR данных. Для этого нам понадобится:
набор данных, опираясь на которые, мы будем показывать или скрывать компоненты приложения
механизм для описания правил показа компонентов
связи с настраиваемыми компонентами
удобный интерфейс управления правилами
Подробнее о правилах
Со стороны пользователя, в данном случае администратора, правило — это обычная строка, которая содержит небольшой фрагмент Python-кода. Например:
any(unit in orgunit_path for unit in ["50623875", "51893158", "51893015"]) or int(personnel_number) in [1240519, 135160]
Данная запись означает, что если сотрудник принадлежит одному из региональных кластеров »50623875»,»51893158»,»51893015» либо имеет один из табельных номеров »1240519»,»135160», то правило считается успешным (вернёт True) и ему отобразятся все компоненты, которые привязаны к данному правилу.
Администратору доступны определенные переменные и операторы, которыми он может пользоваться в правилах. В качестве переменных прокидываются основные данные о пользователе, которые мы получаем из SAP, плюс некоторая дополнительная информация. Например, чтобы настроить отображение поздравительного баннера, администратору нужно создать правило birthday == today и привязать его к необходимому баннеру. Здесь переменная birthday — это дата рождения сотрудника, которую достаем из SAP, а today — сегодняшняя дата, которую мы добавляем как дополнительный параметр.
 Рис. 4 — Настройка правила в админке ЛК2
Рис. 4 — Настройка правила в админке ЛК2 Рис. 5 — Настройка баннера в админке ЛК2
Рис. 5 — Настройка баннера в админке ЛК2 Рис. 6 — Поздравительный баннер в ЛК2
Рис. 6 — Поздравительный баннер в ЛК2
Технически, правило — это таблица в базе данных, которая хранит в себе название правила (title) и его выражение (value). Выражение должно возвращать булево значение — True или False. У компонентов, которые должны настраиваться динамически, хранится внешний ключ на то или иное правило. В момент загрузки главной страницы фронт запрашивает данные по компонентам, которые нужно отрисовать для данного пользователя. На бэке в этот момент достаем все правила и вычисляем их выражение (value).
Вычисление происходит с помощью функции eval. На этом я немного остановлюсь.
Да, мы знаем все опасности и риски использования данной функции, но мы были готовы к этому, постаравшись максимально обезопасить выполнение eval в угоду гибкости и удобства ее использования для текущей задачи.
Мы перестраховались.
Во-первых, ограничили доступность встроенных __builtins__ функций:
local = {
**ALLOWED_BUILT_IN_FUNCTIONS,
**{"__builtins__": None},
**evidence.Schema().dump(evidence),
**self.get_evidence_extra_conditions(),
}
...
result = eval(value, local, local)
Во-вторых, всё это дело логируется. Если правило написано некорректно или выполняется с ошибкой, то мы сразу отследим это. В-третьих, доступ к админке есть у ограниченного доверенного круга людей.
Продолжим.
Из всего набора вычисленных правил оставляем только успешные (те, которые вернули True) и получаем все объекты, которые привязаны к этим правилам. Схематично это выглядит так:
 Рис. 7 — Схема процессаПример кода с вычислением правил:
Рис. 7 — Схема процессаПример кода с вычислением правил:
# Основной метод, в котором получаем id всех успешных правил,
# получаем все необходимые компоненты, на основании
# переданных id-шников правил, и подготавливаем ответ.
async def get_access_control_tree(
self,
sap: "SapAuthorizedProxy",
app: "ApiApplication",
user: "ContextUser",
platform: Optional[str] = None,
query: Optional[str] = None,
) -> "GetTabsResponse":
rules = await self.store.rule.get_success_rule_ids(
sap=sap,
app=app,
user=user,
platform=platform,
)
tabs_themes, groups_themes, banners, tabs = await gather(
self.collect_tabs_themes(rules, query),
self.collect_groups_themes(rules, query),
self.collect_banners(rules, query),
self.collect_tabs(rules, query),
)
return await self._reduce_tabs(
tabs, tabs_themes, groups_themes, banners
)
# Метод, в котором достаем из БД все правила и данные пользователя
# для подстановки в правила.
async def get_success_rule_ids(
self,
sap: "SapAuthorizedProxy",
app: "ApiApplication",
user: "ContextUser",
platform: Optional[str] = None,
) -> List[int]:
evidence, rules = await gather(
self.store.rule.get_evidence(
sap=sap,
app=app,
user=user,
platform=platform,
),
self.collect_rules(),
)
return self._handle_rules(rules, evidence)
# Метод, в котором вычисляются правила и отдаются только
# успешно выполненные.
def _handle_rules(
self, rules: List["Rule"], evidence: "Evidence"
) -> List[int]:
local = {
**ALLOWED_BUILT_IN_FUNCTIONS,
**{"__builtins__": None},
**evidence.Schema().dump(evidence),
**self.get_evidence_extra_conditions(),
}
success_rules_ids: List[int] = []
result = False
for rule in rules:
if rule.lk1:
result = evidence.check_app(rule.value)
elif rule.executable:
result = self._eval_rule(rule, local)
local[gen_rule_value_name(rule)] = result
if result:
success_rules_ids.append(rule.id)
return success_rules_ids
В результате на фронт возвращается ответ со списком всех компонентов, которые доступны для текущего пользователя.
 Рис. 8 — Ответ на запрос доступных компонентов для текущего пользователя — /user.tabs
Рис. 8 — Ответ на запрос доступных компонентов для текущего пользователя — /user.tabs
Проблема вычисления правил
С развитием ЛК увеличилось количество и правил, и пользователей. ЛК стал работать медленно, а иногда просто не мог загрузить какую-то страницу. В моменты нагрузки возникали такие скачки:
 Рис. 9 — Время ответа эндпоинтов ЛК в момент нагрузки
Рис. 9 — Время ответа эндпоинтов ЛК в момент нагрузки
Основная сложность заключалась в том, что по графику было тяжело понять, где и в чем конкретно проблема, т. к. в определенный момент лавинообразно начинали «тормозить» все методы API, и нельзя было понять, из-за чего всё началось. При этом время ответа от внешних сервисов оставалось на прежнем уровне.
Мы проанализировали основной флоу использования ЛК и пришли к следующей гипотезе. После логина все пользователи попадают на главную страницу. На ней выполняется запрос за получением доступных компонентов. Ранее мы сказали, что в этом хэндлере вычисляются правила с помощью встроенной функции eval. В этом и заключалась проблема.
Все дело в том, что данная функция является синхронной. А это значит, что мы не можем переключить контекст процесса в момент ее исполнения, поэтому нам необходимо ожидать, пока выполнятся все правила. То есть из-за блокирования при вычислении правил у нас работал только текущий метод, а другие ожидали его завершения. Поэтому постепенно начинало возрастать время ответа от сервера и в пиковые часы возникали такие скачки.
Нужно было попытаться оптимизировать данный метод и посмотреть, как это отразится на общей работе ЛК. Для решения проблемы мы выделили несколько вариантов оптимизации:
хранить результат выполнения правил в уже существующей БД
кэшировать результат в памяти приложения
кэшировать в Redis.
Так как первые два подхода не требовали дополнительных ресурсов со стороны заказчика для выполнения этой задачи, решили сначала испытать их.
Использование БД
Первый вариант уменьшения времени ожидания вычисления правил — хранение результата в базе данных. При таком подходе мы можем один раз для каждого пользователя вычислить все правила и сохранить результат. В дальнейшем при обращениях к данному методу вычисления правил мы просто достаем эти результаты и, если правило не изменялось, а точнее — время последнего вычисления правила (время сохранения результата) больше, чем время последнего изменения (редактирования) самого правила — то просто отдаем результат. Иначе вычисляем заново и кладем в базу (сохраняем). Преимущества данного подхода:
Но не всё так хорошо, как кажется. Для каждого пользователя нужно хранить результат вычисления каждого правила, (результат вычисления — это промежуточная таблица для связи «многие ко многим» пользователь-правило), количество пользователей ≈ 300 000, правил — ≈ 100. По нехитрым подсчётам выходит около тридцати миллионов записей, при этом и количество пользователей, и количество правил может увеличиваться. Соответственно возрастает нагрузка на базу, потребуется больше ресурсов.
Кэширование в памяти
Другим вариантом оптимизации запроса было кэширование результатов вычисления правил прямо в программе. Для этого также не требуются дополнительные ресурсы, только оптимизация существующего кода.
Выше упоминалось, что вычисление правил происходит с помощью встроенной функции eval, и основная проблема возникает именно в этом месте. Чтобы понять, как ускорить вычисление правил и что лучше кэшировать, нужно разобраться, как работает eval().
Функция eval(expression, globals=None, locals=None) выполняет исходное выражение (expression), переданное ей в качестве обязательного аргумента, в контексте глобальных и локальных переменных. Исходное выражение может быть строкой либо объектом кода (результат выполнения функции compile). Если expression передавать в качестве строки, то eval «под капотом» сама будет компилировать и выполнять данное выражение. Но что, если передавать уже преобразованный код? Ведь именно процесс компиляции занимает большее время выполнения eval. Чтобы убедиться в этом, проведём небольшие замеры:
1) Функция eval со строкой в качестве аргумента:
import time
def eval_test():
arr = list(range(10 ** 6))
start = time.time()
for _ in range(10 ** 6):
eval('0 in arr')
print('Eval test time:', time.time() - start)
>>> eval_test ()
Eval test time: 6.970968961715698
2) Функция compile со строкой в качестве аргумента:
import time
def compile_test():
arr = list(range(10 ** 6))
start = time.time()
for _ in range(10 ** 6):
compile('0 in arr', '', 'eval')
print('Compile test time:', time.time() - start)
>>> compile_test ()
Compile test time: 6.661298990249634
3) Функция eval со скомпилированным объектом в качестве аргумента:
import time
def precompiled_eval_test():
arr = list(range(10 ** 6))
expr = compile('0 in arr', '', 'eval')
start = time.time()
for _ in range(10 ** 6):
eval(expr)
print('Precompiled eval test time:', time.time() - start)
>>> precompiled_eval_test ()
Precompiled eval test time: 0.27375197410583496
Как видно из результатов теста, основное время выполнения занимает не сама функция eval, а функция compile, которая выполняется «под капотом» eval. Исходя из этого было предложено кэшировать результат выполнения функции compile и передавать в eval() уже не строку, а объект скомпилированного кода.
Почему же тогда просто не сохранять результат вычисленного правила (результат функции eval)? Тогда бы пришлось хранить результат каждого правила для каждого пользователя, а, как мы выяснили ранее, это порядка 30 миллионов записей, что приведет к дополнительным затратам по памяти. При сохранении результата компиляции затраты по памяти будут равны количеству существующих правил. В настоящий момент количество правил — около 100 штук.
Для кэширования была выбрана библиотека cachetools. Ниже приведен пример ее использования:
from cachetools import cached, TTLCache
RULE_CACHE_TIME = 15 * 60
@cached(TTLCache(maxsize=inf, ttl=RULE_CACHE_TIME), key=gen_rule_value_name)
def _compile_lk_rule(self, rule: "Rule") -> Any:
return compile(rule.value, "", "eval")
def _eval_rule(self, rule: "Rule", local: dict) -> bool:
try:
# вот здесь получим закэшированный результат compile
compiled = self._compile_lk_rule(rule)
return eval(compiled, local, local)
except SyntaxError:
self.logger.exception(
"[Rule] Compile expression %s error: ", rule.value
)
except Exception:
self.logger.warning(
"[Rule] Eval expression %s error: ", rule.value, exc_info=True
)
Минус в том, что при изменении какого-либо правила результат кэширования обновится не сразу, а только через RULE_CACHE_TIME (время, на которое кэшируем результат).
Проверка теории
Чтобы проверить обе теории, было решено провести нагрузочное тестирование и посмотреть, во сколько раз увеличится количество запросов в секунду (RPS). Но перед тестированием нужно было убедиться, что вообще есть смысл его проводить, и любой из способов дает прирост в производительности.
Ниже приведены запросы и время их выполнения для каждого из способов.
 Рис. 10 — Исходная версия приложения
Рис. 10 — Исходная версия приложения Рис. 11 — Версия приложения с использованием БД
Рис. 11 — Версия приложения с использованием БД Рис. 12 — Версия приложения с использованием кэша
Рис. 12 — Версия приложения с использованием кэша
Как видно из результатов — время ответа на запрос при кэшировании скомпилированных правил и при хранении результатов в базе примерно одинаковое, и заметно отличается от исходной версии. Следовательно, обе теории имеют результат, поэтому можно переходить к тестированию под нагрузкой.
В качестве инструмента для воссоздания нагрузки был выбран locust.io. Locust — это простой в использовании инструмент для тестирования производительности с масштабируемостью и возможностью написания пользовательских сценариев в обычном Python-коде.
Перед тем, как попасть на сервер, запросы проходят фильтрацию на WAF, это влияет на общее время выполнения запроса, и из-за этого результаты тестов могут быть неточными. Для того чтобы можно было обращаться к нашему приложению по внутренней сети, тем самым исключить время фильтрации запроса на WAF, был поднят инстанс locust в том же контуре, что и само приложение. Кроме того, были замоканы походы в сторонние API. Тем самым мы сможем наиболее точно сравнить результаты всех тестирований и исключить влияние внешних факторов.
Для подготовки простого пользовательского сценария в locust хватило всего 8 строк кода.
import random
from locust import HttpUser, task
class QuickstartUser(HttpUser):
host = "http://localhost:8000"
@task
def user_tabs(self):
auth = {"Authorization": f"Bearer {random.randint(0, 100)}"}
self.client.get("/user.tabs?platform=web", headers=auth)
Мы тестируем метод /user.tabs, отправляя запрос на указанный host с авторизацией одного из 100 пользователей. Host можно изменить в UI, при старте тестирования. Также можно будет указать пиковую нагрузку, темп ее роста и продолжительность тестирования.
 Рис. 13 — Начальный экран locust перед стартом тестирования
Рис. 13 — Начальный экран locust перед стартом тестирования
Ниже приведены результаты проведения нагрузочного тестирования для разных версий приложения.
Исходное приложение:
 Рис. 14.1 — График результатов нагрузочного тестирования исходного приложения
Рис. 14.1 — График результатов нагрузочного тестирования исходного приложения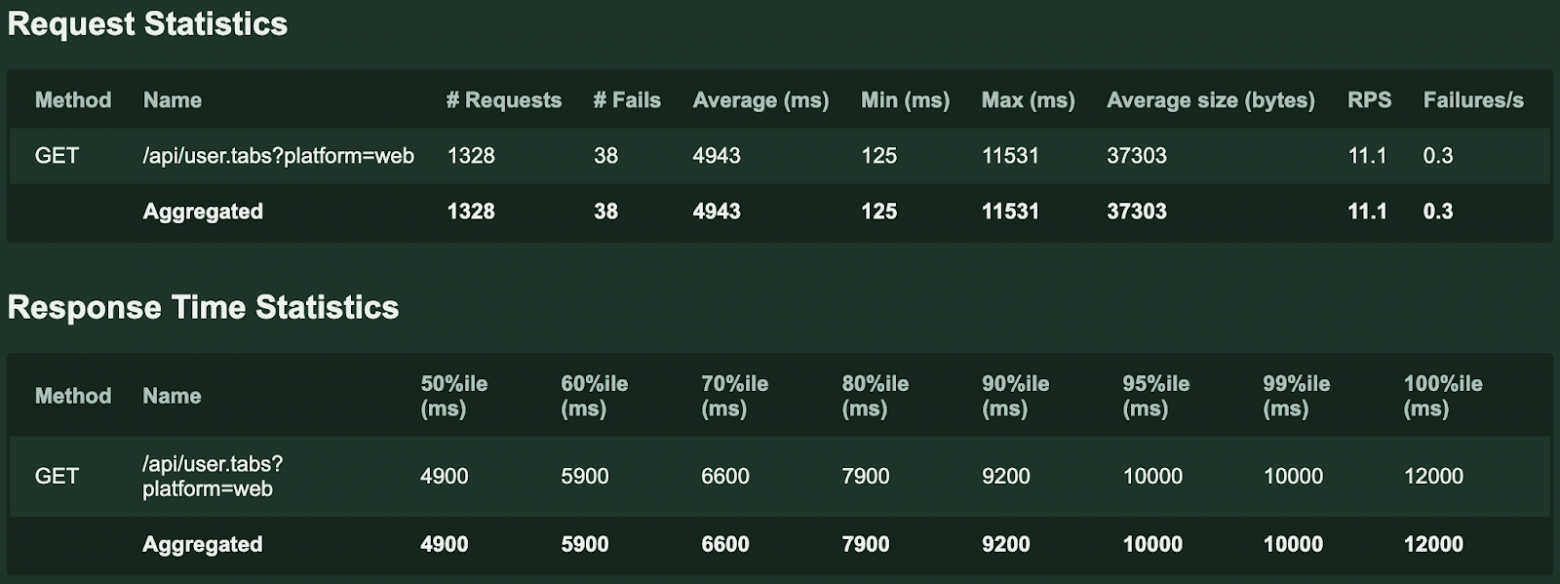 Рис. 14.2 — Сводная статистика результатов нагрузочного тестирования исходного приложения
Рис. 14.2 — Сводная статистика результатов нагрузочного тестирования исходного приложения
Версия приложения с хранением результата в БД:
 Рис. 15.1 — График результатов нагрузочного тестирования версии приложения с использованием БД
Рис. 15.1 — График результатов нагрузочного тестирования версии приложения с использованием БД Рис. 15.2 — Сводная статистика результатов нагрузочного тестирования версии приложения с использованием БД
Рис. 15.2 — Сводная статистика результатов нагрузочного тестирования версии приложения с использованием БД
Версия приложения с использованием кэша:
 Рис. 16.1 — График результатов нагрузочного тестирования версии приложения с использованием кэша
Рис. 16.1 — График результатов нагрузочного тестирования версии приложения с использованием кэша Рис. 16.2 — Сводная статистика результатов нагрузочного тестирования версии приложения с использованием кэша
Рис. 16.2 — Сводная статистика результатов нагрузочного тестирования версии приложения с использованием кэша
Для наглядности приведён общий рисунок с графиками результатов тестирований с использованием кэша, БД и исходного приложения соответственно.
 Рис. 17 — Общий график результатов нагрузочного тестирования
Рис. 17 — Общий график результатов нагрузочного тестирования
Анализ результатов
Как видно из графиков, результаты у версий приложения с использованием кэша и хранением результатов в БД примерно одинаковые. При использовании любого из этих подходов количество RPS выросло на 50%. Но как писали выше, при хранении результатов в БД будет увеличиваться нагрузка на базу. Поэтому в конечном итоге было решено использовать кэширование в приложении с использованием библиотеки cachetools.
Результат в проде
В теории мы нашли проблему, из-за которой происходила долгая загрузка главной страницы личного кабинета и провели нагрузочное тестирование возможных решений данной проблемы. Но как убедиться в том, что это будет работать в реальной жизни, и какой прирост производительности мы получим?
Очевидно, для этого нужна какая-то метрика, по которой можно понять, что время выполнения целевого метода уменьшится после релиза новой версии. У нас была метрика, которая замеряет полное время работы хэндлера от получения запроса и до возвращения ответа. Но использовать ее здесь было бы не совсем корректно. Как мы отмечали выше, в данном методе, помимо выполнения функции eval, делаются внешние запросы в SAP и в БД, что может влиять на конечное сравнение, так как время работы внешних сервисов не зависит от нас и может варьироваться от запроса к запросу.
Нужно было делать замер «чистого» рабочего времени — время, которое затрачивается на исполнение только синхронного кода (т.е. по сути время блокировки Event loop). Про это мы расскажем подробнее в другой статье. Вкратце скажу, что это патч метода _run класса asyncio.Handle, в котором с помощью ContextVar мы замеряем и сохраняем время выполнения каждого метода. Ниже привожу результат данной метрики до и после релиза новой версии приложения для эндпоинта user_tabs, в котором как раз фронт получает все необходимые компоненты:
 Рис. 17 — «Чистое» время выполнения метода user_tabs до и после релиза
Рис. 17 — «Чистое» время выполнения метода user_tabs до и после релиза
Как видно из графика, после релиза (промежуток времени с 18:46 и далее) кривая пошла вниз. Время работы метода user_tabs уменьшилось примерно в 3 раза, что практически соответствует нашим теоретическим данным, полученным при проведении нагрузочного тестирования.
Таким образом мы решили проблему медленной работы одного из основных методов на бэкенде, узнали о тонкостях работы с функцией eval и научились замерять «чистое» время выполнения любого хэндлера. Теперь мы пользуемся данными наработками, если необходимо замерить работоспособность сервиса при выкатке новой фичи или протестить оптимизацию какого-либо метода.
