Как мы подключали и тестировали дата-центр в Канаде. Обзор
Недавно мы подключили новый дата-центр в Северной Америке, поэтому теперь в панели управления доступно создание VM в Канаде. Наши специалисты разместили и настроили оборудование в Cologix TOR3 — дата-центр в Торонто, сертифицированный по стандарту
Tier III. Ведущий системный инженер Владимир Емельянов, сетевой инженер Алина Барышева и инженер эксплуатации «vStack» Андрей Фесенко поделились со мной опытом запуска и тестирования оборудования, а также рассказали о своих впечатлениях о работе с Cologix. Об этом всем — под катом.
TORонто
TOR3 — это канадский центр обработки данных, где было размещено оборудование. Он принадлежит компании Cologix, глобальной сети, занимающейся предоставлением
дата-центров и площадок для размещения оборудования. Это уже второй ЦОД Cologix, которой мы подключили в Северной Америки, поэтому размещение оборудования не вызвало сложностей. Первым был NNJ3 в Нью-Джерси.
Интересно, что дата-центр площадью 20 тыс. кв. футов расположен в необычном для ЦОДа месте — в центре города Торонто. И в здании по адресу 905 King Street находится не один, а целых два дата-центра Cologix TOR2 и TOR3.
 Дата-центры Cologix TOR2 и TOR3 в Торонто
Дата-центры Cologix TOR2 и TOR3 в Торонто
Немного об оснащении ЦОД. Оборудован он современными системами электроснабжения, кондиционирования и безопасности, и имеет следующие характеристики:
Электроснабжение
резервирование системы бесперебойного питания по схеме 2N;
резервные генераторы, поддерживающие инфраструктуру охлаждения;
автоматическое переключение резерва (АВР).
Охлаждение
охлаждение по схеме N+1. В случае возникновения сбоя, резервный элемент примет на себя всю его нагрузку;
система водяного охлаждение APC InRow для помещений с Rack-серверами;
система изолирования горячего коридора.
Охрана
круглосуточная охрана;
трехфакторная аутентификации с биометрическим доступом;
система с CCTV-камерами видеонаблюдения, передающими информацию в HD формате.
Противопожарная защита
система аспирационного оповещения о пожаре VESDA с минимальным временем обнаружения;
пожаротушение с предварительным срабатыванием и двойной блокировкой.
Международные стандарты
ISO 27001 для системы управления информационной безопасностью (ISMS);
PCI DSS, оценивающий средства контроля поставщика услуг для защиты данных платежных карт от несанкционированного доступа или использования.
Cologix получает ежегодную оценку средств контроля в отношении правил безопасности HIPAA и правил уведомления о нарушениях HITECH. Проходит проверки SOC 1 и SOC 2 и получает отчеты об аттестации, показывающие эффективность средств контроля организации.
Мы как бы здесь, а проблемы как бы и там, и здесь
Настройка оборудования в дата-центре на другом конце земли имеет свои особенности. Так как основные наши специалисты: системные и сетевые инженеры находились в России, а в Канаде у нас был один представитель и местные наемные сотрудники, то управлять процессом приходилось «удаленными руками». Поэтому важным моментом стала поддержка со стороны Cologix. В этом плане компания обеспечила и продолжает обеспечивать всю необходимую помощь.
Нам предоставили клиент-менеджеров, с которыми мы могли общаться персонально и решать все вопросы. Плюс дали доступ в Cologix Customer Portal — портал, где мы осуществляем контроль над нашей экосистемой в дата-центре. На самом деле портал довольно простой, но полезный. Заходишь туда, выбираешь, что надо, например, нужно переключить линк из одного порта в другой. Переходишь в форму заявки, заполняешь, и все сотрудники дата-центр делают. Удобно.
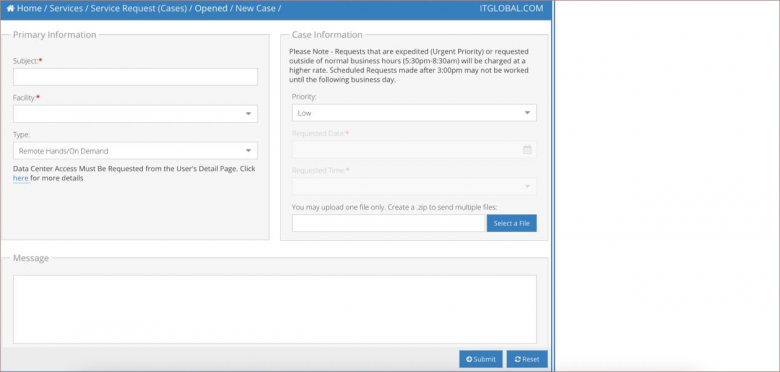 Форма заявки на портале
Форма заявки на портале
Наиболее важные параметры, которые позволяет отследить портал — это питание и потребляемая мощность стоек в режиме реального времени. Также через сайт производится доставка оборудования и его расходников.
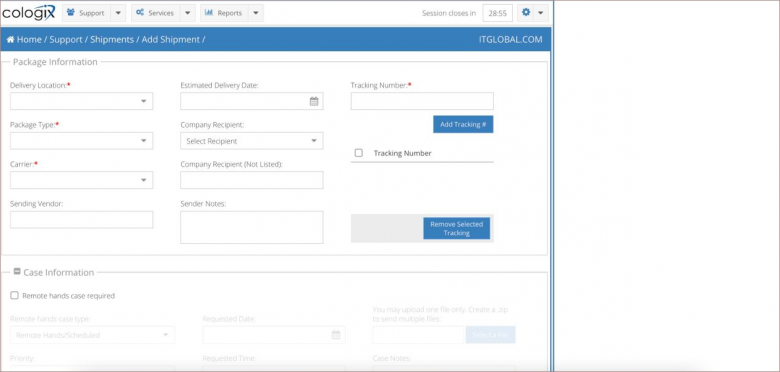 Форма принятия доставки на портале
Форма принятия доставки на портале
Доступ в интернет был организован через классическую схему подключения стоек и оборудования с помощью трех провайдеров. Два провайдера могут друг друга подхватить — это Hurricane Electric и Cogent, и один — backdoored. Hurricane Electric — почти монополист в Америке, а Cogent — это трансконтинентальный провайдер, который присутствует и в Европе, и в Америке. По ним течет основной трафик, которым пользуются клиенты и мы. А третий провайдер необходим на случай «Ooops», чтобы восстановить систему.
Что в стойке?
В дата-центре было размещено 7 серверов Supermicro со следующей конфигурацией:
Сборка Server Platform: 2U Supermicro CSE-216BE1C-R920LPB
Материнская плата: Supermicro X11DPi-NT
Процессоры: Intel® Xeon® LGA 3647 6248R, 3 GHz, 24-Core, 205W
Память: DDR4 3200 Ecc Reg. 128GB SAMSUNG
Диски: SSD Enterprise 2.5'' SATA TLC 3D2 NAND Intel DC S4510 — 240GB
SSD Enterprise 2.5'' SATA TLC 3D2 NAND Intel DC S4510 — 960GB
HBA 9500–8i Tri-Mode Storage Adapter
NIC: Intel® Ethernet Controller X710 for 10GbE SFP+
 Фото стойки на момент ввода оборудования в эксплуатацию
Фото стойки на момент ввода оборудования в эксплуатацию
Supermicro хорошо показали себя в дата-центрах в Амстердаме (AM2) и в Нью-Джерси (NNJ3). Там у нас расположены кластеры vStack и все работает без проблем уже не один год. Поэтому с установкой и запуском оборудования вопросов не было. С помощью «удаленных рук» оборудование было смонтировано в стойки и скоммутировано по проекту за неделю.
В Канаде оборудование также настраивалось для работы с гиперконвергентной платформой vStack. Здесь была выполнена коммутация и подключение узлов vStack с использованием технологии vPC, организован VPC домен и по VPC линкам подключены узлы кластера vStack. Также было организовано сетевое взаимодействие во внутренней сети между сегментами площадки, затем установлена связь с глобальной сетью путем подключения внешних провайдерских линков по отказоустойчивой схеме. Для работы с платформой была настроена сеть управления.
vStack — это полноценное гиперконвергентное решение, объединяющее в единой платформе вычислительные ресурсы (SDC), хранение данных (SDS) и управление сетями (SDN), что дает преимущество в сравнении с классическим конвергентным подходом к построению ИТ-инфраструктуры. Если хотите узнать подробнее про vStack, то советую прочитать эту статью.
Как проходило тестирование?
Переходим к тестированию сети и оборудования. На рисунке ниже представлена схема подключения серверов к коммутаторам с помощью пар линков. Нам было необходимо обеспечить отказоустойчивость всего кластера, а значит проконтролировать, чтобы они были все подключены и видели друг друга.
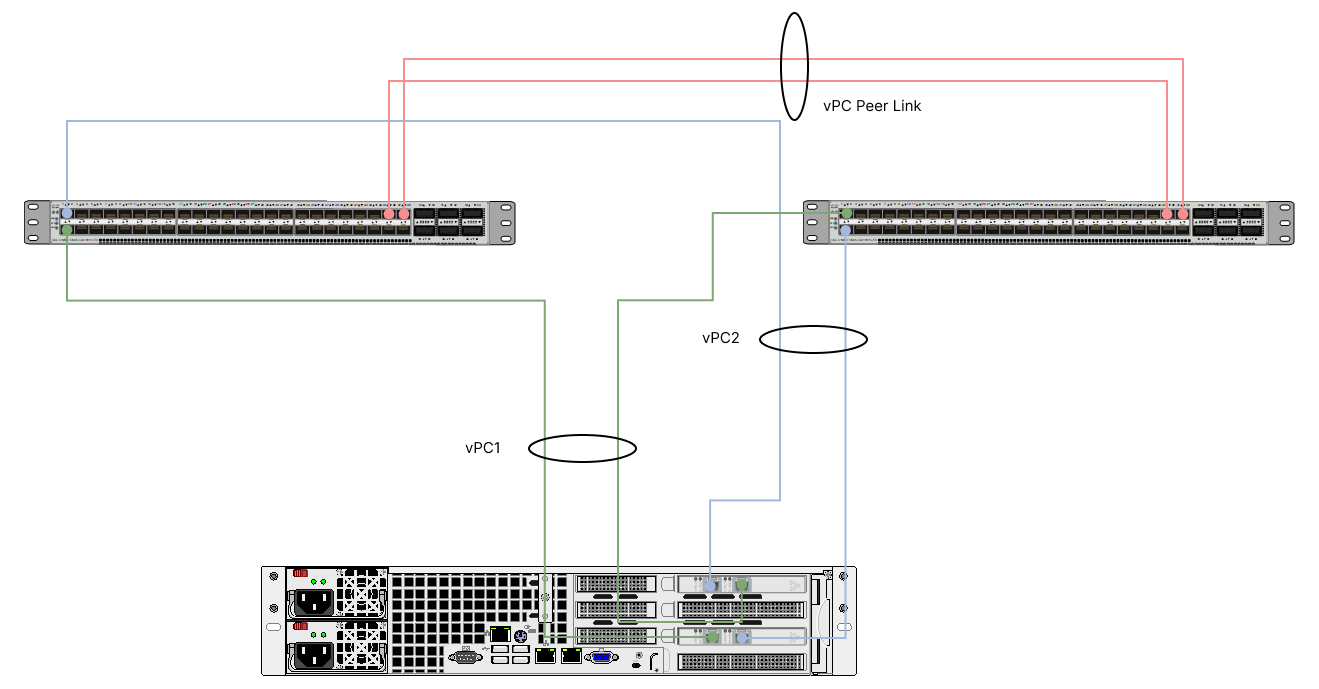 Схема подключения
Схема подключения
Линки с сетевых карт сервера приходят в коммутаторы (в один и другой). Логически они собраны в один агрегированный (объединенный) канал, что и обеспечивает отказоустойчивость. Кроме того, оба коммутатора также соединены между собой виртуальным линком, собранным из двух физических, чтобы образовать домен. Бордеры подключены по vPC.
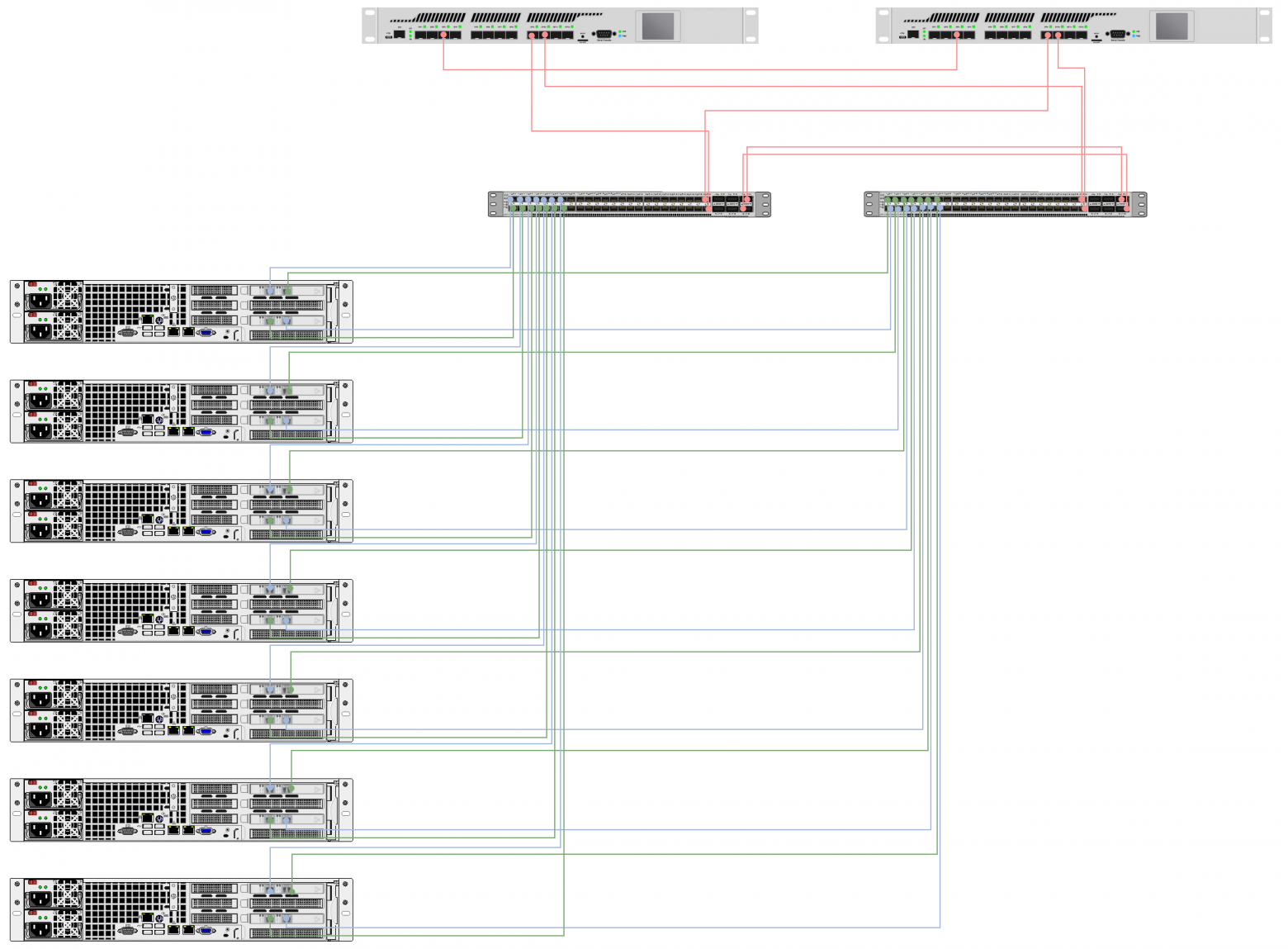 Общая схема подключения серверов в Канаде
Общая схема подключения серверов в Канаде
Сетевая связность
В начале тестирования мы проверяли полную сетевую связность на узлах кластера. Мы задействовали JumboFrames (требование корректного функционирования), которое позволяет посылать большие пакеты данных до 9 тыс. в одном пакете. Оно используется для оптимизации нагрузки на сеть, получения более высокой пропускной способности, в том числе в SDS слое (программно-определяемое хранилище). Проверяем, если поддерживается 9000, при большем значении увеличиваем проверяемый MTU.
О том, как проверить, работают ли 9000 MTU на JumboFrames, можно прочитать в этой статье.
Для примера, ниже показано сначала, какой размер MTU проходит при передаче данных, и как выглядит потеря пакетов.
 MTU проходит при передаче данных
MTU проходит при передаче данных Потеря пакетов MTU
Потеря пакетов MTU
Если в обоих случаях наблюдаем ошибку, то просим сетевых инженеров проверить и скорректировать с их стороны. В нашем же случае ошибок не было.
Пропускная способность
С помощью сервиса iperf3, которая обеспечивает генерацию трафика, проверяли канал между узлами, измеряли максимальную пропускную способность сети. На одной из нод запустили iperf3 в виде демона.
 iperf
iperf
На каждой из остальных нод, последовательно запустили сервис в режиме клиента.
 iperf в режиме клиента
iperf в режиме клиента
При использовании сетевых карт 25Гб и выше, необходимо запускать данный тест в несколько потоков, запустив несколько серверных процессов iperf на разных портах. Для примера покажем тестирование интерфейса с двумя портами 25GBe в LACP-режиме. Первый тест — на одной из нод запущено три сервера iperf, и на них дана одновременная нагрузка с трёх других нод в режиме --bidir (двунаправленном iperf3 -c 192.0.2.2 -i 5 -t 60 --bidir -p 5204). Второй — шесть серверов и нагрузка с шести нод. Как пример одного из тестов:
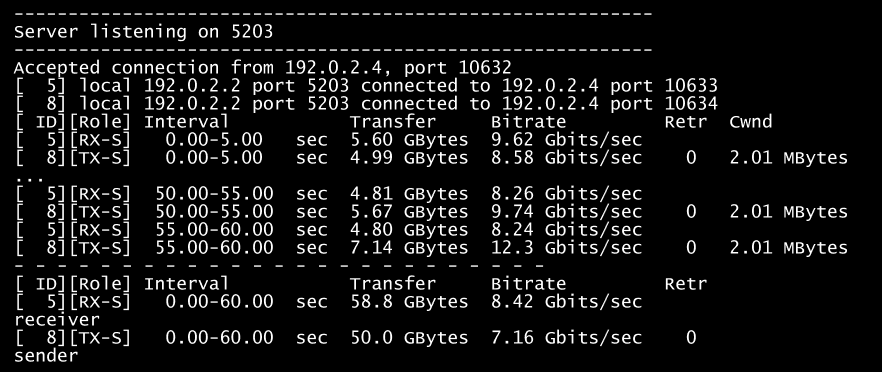 Тестирование интерфейса с двумя портами 25GBe в LACP-режиме
Тестирование интерфейса с двумя портами 25GBe в LACP-режиме
На графике ниже видно, в первом случае нагрузки недостаточно для полной загрузки имеющегося канала. Если хочется добиться полной нагрузки, то можно добавить тестовых потоков, либо взять иной нагрузочный инструмент.
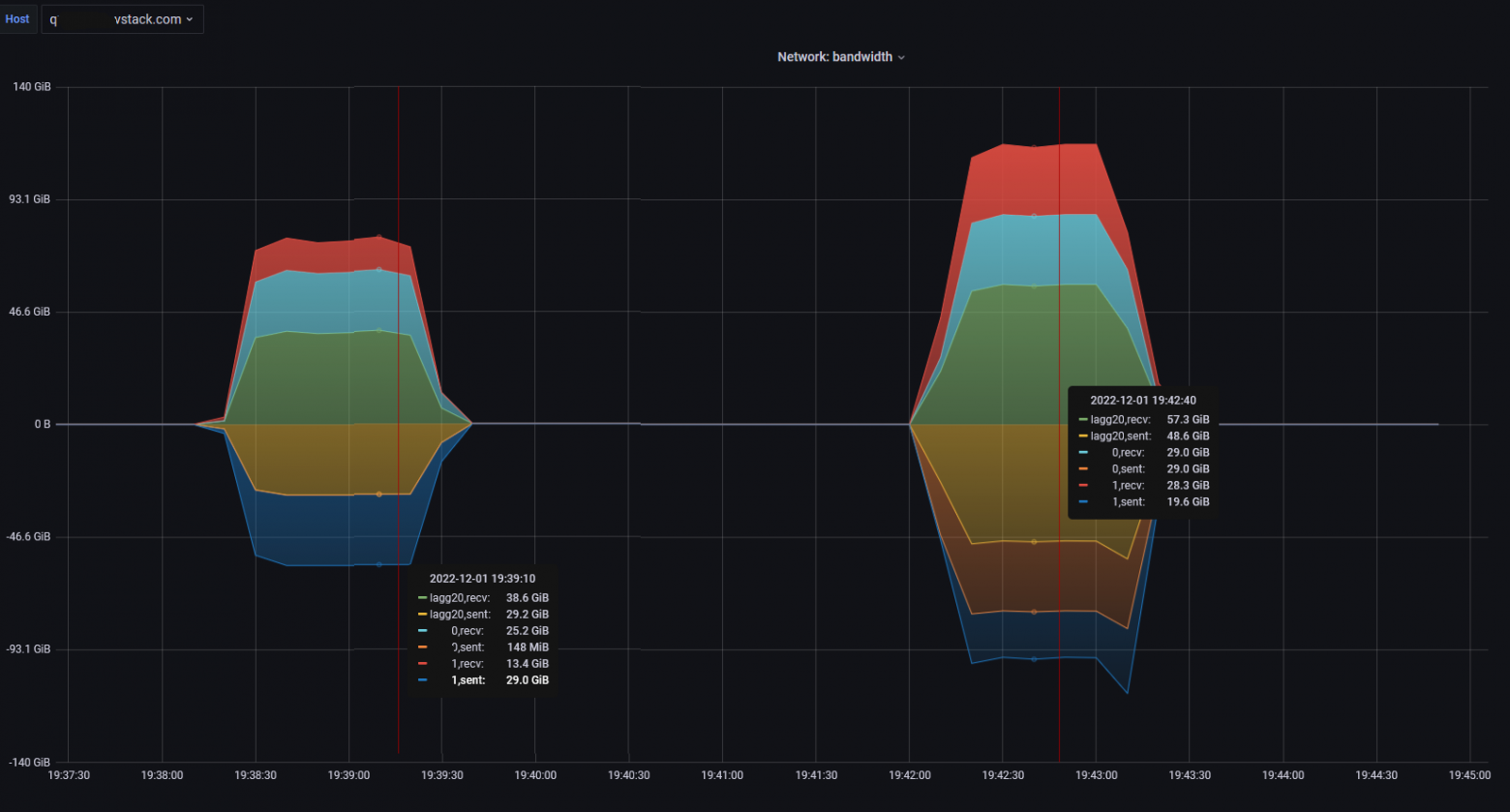 Тестирование iperf
Тестирование iperf
Также мы проверяли коннективити между гостевыми виртуальными машинами. Запускали iperf между ними и во внешнюю сеть для проверки связности внутри кластера, и наружу. Проверяли 3 критические точки: линки наружу, линки от наших коммутаторов до border-роутеров и связность с серверной фермой. Тестирование прошло без замечаний.
Производительность дисков
Для тестирования производительности SDS мы использовали утилиту fio. Она позволяет проверить IOPS (количество операций ввода/вывода) на чтение и запись и пропускную способность. Мы тестировали слой хранения vStack (SDS) и скорость дисков внутри виртуальной машины. Гарантированное количество IOPS для СХД соответствует целевым значениям SLA. Для примера, ниже показаны тесты fio из виртуальной машины: 4 CPU 4GB RAM на ОС Ubuntu 20, fio на отдельном 4К диске.
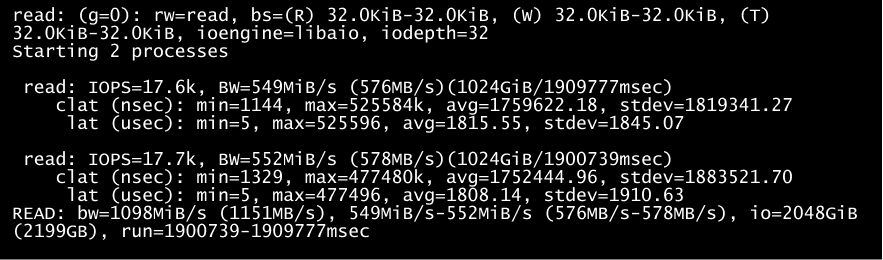 Тест fio
Тест fio Тест fio
Тест fio
Отказоустойчивость кластера
Так как у нас кластер состоит из 7 узлов, то в дата-центре реализована схема резервирования N+2. Если больше двух узлов выйдут из строя или с ними необходимо будет провести технические работы, то кластер переходит в аварийный режим. Чтобы проверить корректную работу механизмов обеспечения отказоустойчивости, специалисты имитировали подобную ситуацию.
Проверяли выпадение одного узла из кластера. В данном случае отключали у узла все четыре линка сразу. Кластер видит, что пропал один узел, поэтому все что работало автоматически на выключенной ноде переносится на другую. Кластер автоматически выполняет процедуру аварийного переключения (failover) ресурсов данного хоста. При этом проверяется, что пулы переехали без потери, слой хранения отработал корректно, и пулы перенесены на другие ноды. Смотрим, что виртуальные машины, работающие на этом пуле, восстановили свое состояние, которое было до переезда.
 Имитирование аварийной ситуации
Имитирование аварийной ситуации
Также проводилось тестирование на обрыв линков, имитировали пропадание ввода первого или второго от одного из провайдеров. Отключение каждого свича не влияет на работу системы, связь для клиентов не теряется.
Что же это дает?
Благодаря подключению новой локации теперь в панели управления Serverspace можно развернуть сервер в защищенном дата-центре Канаде со следующими конфигурациями:
Поддерживаемые ОС:
Ресурсы на один сервер:
