Как мы научили заводчан строить красивые инженерные отчеты из Jupyter Notebook на Python
Была у нас тут история, когда легкий перфекционизм помог привести в порядок конструкторскую документацию и регулярно экономить инженерам кучу дней на прохождение бюрократических процедур. В ее основе — создание системы управления расчетными данными и переход от трудночитаемых и трудноинтегрируемых отчетов Mathcad к гибкой связке Jupyter Notebook с Python и Teamcenter. Но основной рассказ будет про то, как преобразовывать и экспортировать математические формулы, таблицы и другие элементы из Jupyter в красивый и удобный вид.

Мало кому нравятся рутинные задачи. Мне, например, сложно заставить себя следить за нумерацией таблиц и рисунков, за порядком упоминания ссылок в тексте, за нумерацией формул. Проверять, правильно ли я перенёс цифири из документа А в свой расчет, а потом правильно ли я перенес другие в документ Б. Бррр…
Когда я подобное встречаю, выхода остается два: либо отложить до завтра, либо автоматизировать.
Поэтому с универа я плотно увяз в различных способах автоматизации расчетов, а считать в инженерном вузе приходилось часто и помногу. Сперва я открыл для себя Mathсad. Вбил формулы в определенной последовательности, и расчет готов. Красота!
Но была одна беда — эти расчеты еще и показывать надо, а значит, все результаты, да еще с пояснениями и формулами надо было в какой-то нормальной программе составить. Ну то есть в Word или на худой конец в тетрадке. В Mathсad приличного документа не сделаешь. Может, сейчас по-другому, но раньше там было сложно текст и формулы в одной строке ровно поставить. Сделать постоянный межстрочный интервал было вообще невыполнимой задачей. Когда я приносил распечатку из Mathсad преподавателям, они обычно упоминали «эти ваши Маты-Кады», а еще другие эпитеты, и отправляли меня переделывать.

Стандартный вывод из Mathсad
Поэтому отчетность и в вузе, и в профессиональной деятельности я делал все же в Word. Но все это время что-то сверлило в мозгу: «Ну зачем все эти переписывания постоянно?» Из служебок в расчет, из расчета в отчет, из отчета в служебку. Ровно до того момента, когда я поднаторел в Python и окунулся в таинственный мир LaTeX. Вынырнул только после того, как у меня был готовый шаблон автоотчетов и пара-тройка заваленных сроков по остальной работе. Но шаблон был прекрасен. Картинки сами вставлялись пачками, главы укладывались штабелями. Титульный лист, ссылки на литературу, нумерация, подписи, шрифты — все выглядело идеально.
Пример вывода из LaTeX
Однако разобраться в этом спагетти-вестерне мог только я. Для обычных пользователей требовалось что-то другое.
Внедрение системы управления расчетными данными на заводе
В прошлом году мы в ЛАНИТ занялись внедрением расчетных программ в систему Teamcenter (это софт для поддержки жизненного цикла изделий) для одного предприятия, занятого проектированием и производством сельскохозяйственной техники. Коллеги-расчетчики проводили 3D CAE расчеты для своего предприятия, а также довольно активно решали разнообразные аналитические задачи (расчеты по методичкам и учебникам).
Мы хотели с помощью PLM Teamcenter построить систему управления расчетными данными SPDM (Simulation Process and Data Management). А именно:
организовать удобное хранение расчетов, исходных данных, результатов расчета и отчетной документации (все необходимые элементы хранятся в единой системе и доступны всем участникам процесса);
организовать удобный поиск расчетных данных (например, вы можете найти, какие расчеты проводились для определенной детали или сборки);
предоставить возможность запуска и редактирования расчетов из-под PLM Teamcenter с автоматической загрузкой результатов и других файлов в систему;
организовать обмен рабочими данными и все бюрократические процедуры через рабочие процессы Teamcenter, что позволит существенно уменьшить временные затраты.
В целом внедрение SPDM должно сделать работу с расчетами более удобной, практичной и эффективной. Более глубоко в тематику SPDM я здесь погружаться не буду. Эта тема для отдельной статьи.
Аналитические расчеты коллеги делали в Mathcad, но он не подходил для интеграции в Teamcenter. Мы же хотели пересадить коллег на более удобный программный продукт, достаточно гибкий в плане интеграции и обладающий мощными вычислительными возможностями.
Я практически сразу стал продвигать Python совместно с Jupyter Notebook. Для меня преимущества были очевидны.
Python удивительно гибок, его можно интегрировать с чем угодно. Более того, под многие программы уже написаны хорошие интерфейсы. Например, с Excel, который удобно использовать для задания начальных данных.
Python вполне подходит для аналитических и научных расчетов. Модуль Numpy позволяет работать с матрицами не хуже Matlab. С помощью Pandas можно обрабатывать табличные данные, Sympy позволяет сносно осуществлять операции символьной математики, а Matplotlib — выводить хорошо настраиваемые графики.
WEB-интерфейс Jupyter Notebook позволяет запустить расчет с любого утюга рабочего места и вполне удобен при работе над кодом.
Python свободно распространяется. Т.е. то, за что продавцы пакетов программ вычислительной математики Maple, Mathcad, Matlab и др. берут немалые суммы, Python предоставляет официально и бесплатно.
Что в Jupyter Notebook можно сделать полностью оформленный отчет, я тогда еще не знал. Но после того, как я стал прорабатывать это направление, я быстро понял, что существует возможность генерировать LaTeX-код через модуль Jupyter Nbconvert, и самое главное — можно гибко и просто настраивать шаблоны генерируемого кода. Соответственно на основе Jupyter Notebook можно сделать почти WYSIWYG-продукт, который генерирует отчетность по стандартам предприятия. Как это осуществить, будет показано далее.
Недостаток есть, и он большой. Требуется изучение языка программирования. Кривая обучения крутая, но все равно необходимо преодолеть этот больше психологический барьер. Мы договорились попробовать, провести обучение, а после посмотреть, что из этого получится.
Реакция на обучение
Обучение было рассчитано на пять дней. В его ходе я рассказывал про основные особенности языка и модули, использующиеся в расчетах. Так как курс был очень коротким, то я сразу сделал акцент на том, что запоминать все не надо, надо только ознакомиться с возможностями. Заранее проговорили, что с каждым из расчетчиков мы будем совместно прорабатывать его расчет. Но все равно, на обучении сложилось впечатление, что коллеги заперты со мной в аудитории и отчаянно пытаются выбраться. Тут, думаю, больше сыграли мои, прямо скажем, невеликие педагогические способности. Оказывается, задачи решать — это легко, а учить этому людей — в несколько раз сложнее.
После обучения были жалобы, что расчетчики — не программисты, что им это не подходит. Были разборки с руководством заказчика, почему вообще расчетчикам преподавался Python. Было много обсуждений и презентаций. Убедить коллег удалось только после того, как был презентована автогенерация отчета и были проработаны тестовые задачи с расчетчиками. У заказчика была история, когда начальство выдавало расчетчикам задание на расчет, сам расчет выполнялся за один день, а потом месяц уходил на отчетность и проведение бюрократических процедур. Наша система, с другой стороны, предлагала значительное ускорение этапов работы над отчетом и согласования отчетной документации.
Как настроить Jupyter Nbconvert
Jupyter Nbconvert — это инструмент трансляции Jupyter-блокнота в другие форматы. Нас интересует трансляция в PDF и в LaTeX. Также есть возможность сохранения в PDF через html, но полученный документ будет выглядеть как распечатка с сайта. Трансляция в pdf осуществляется тоже через LaTeX, поэтому он должен быть установлен на компьютере. Для установки я раньше использовал TexLive, но сейчас рекомендую MiKTeX потому, что последний умеет автоматически докачивать пакеты в процессе верстки документа. Эта способность сыграла ключевую роль при разработке окончательной версии системы.
Если у вас установлены Python, Jupyter Notebook или Jupyter Lab, а также LaTeX, вы можете приступать к настройке автогенерации отчета.
Предположим у вас есть такой простой Jupyter Notebook example.ipynb, как на картинке ниже.
Для того, чтобы превратить этот блокнот в выходной PDF документ, надо выполнить следующую команду в командной строке.
jupyter nbconvert --execute --config=cfg.py --to pdf --no-input example.ipynb--execute обеспечивает выполнение всех ячеек блокнота. Позволяет запустить блокнот в фоновом режиме и сгенерировать новый отчет при изменившихся исходных данных.
--to pdf — трансляция ведется сразу в pdf-файл, но генерируется файл через LaTeX. Если нам нужен именно .tex файл (например, для отладки) то используйте ключ --latex.
--config=cfg.py задает кастомизацию шаблона в файле cfg.py.
--no-input скрывает все кодовые блоки в отчете. В нашем случае код в отчете был неуместен.
В файле cfg.py следующее:
c = get_config()
# Добавляем в пути поиска папку с шаблоном
c.TemplateExporter.extra_template_paths = [os.path.dirname(os.path.realpath(__file__))]
# Полезный блок, который дает возможность не выводить ячейки с тегом Skip
# если некоторые блоки выполняют только служебную функцию
c.TagRemovePreprocessor.enabled=True
c.TagRemovePreprocessor.remove_cell_tags=("Skip",)
# Указывает основной файл шаблона
c.Exporter.template_file = 'article.tplx'Шаблоны для LaTeX хранятся как раз в article.tplx, настраиваются они с помощью Jinja. В замечательной статье великолепно описана настройка таких шаблонов. Я же хочу рассказать о других фишках, которые могут сделать ваш блокнот более дружелюбным. Настроенный шаблон для примера выше находится здесь.
Результат генерации документа pdf с настроенным шаблоном:
Результат генерации документа из example.ipynb
Настройка отображения формул
Формулы можно писать как в Markdown ячейках, так и кодовых ячейках. В Markdown надо писать формулы на языке LaTeX в окружении:
$<формула>$ — чтобы формула была в тексте,
$$<формула>$$ — чтобы формула была в новой строке.
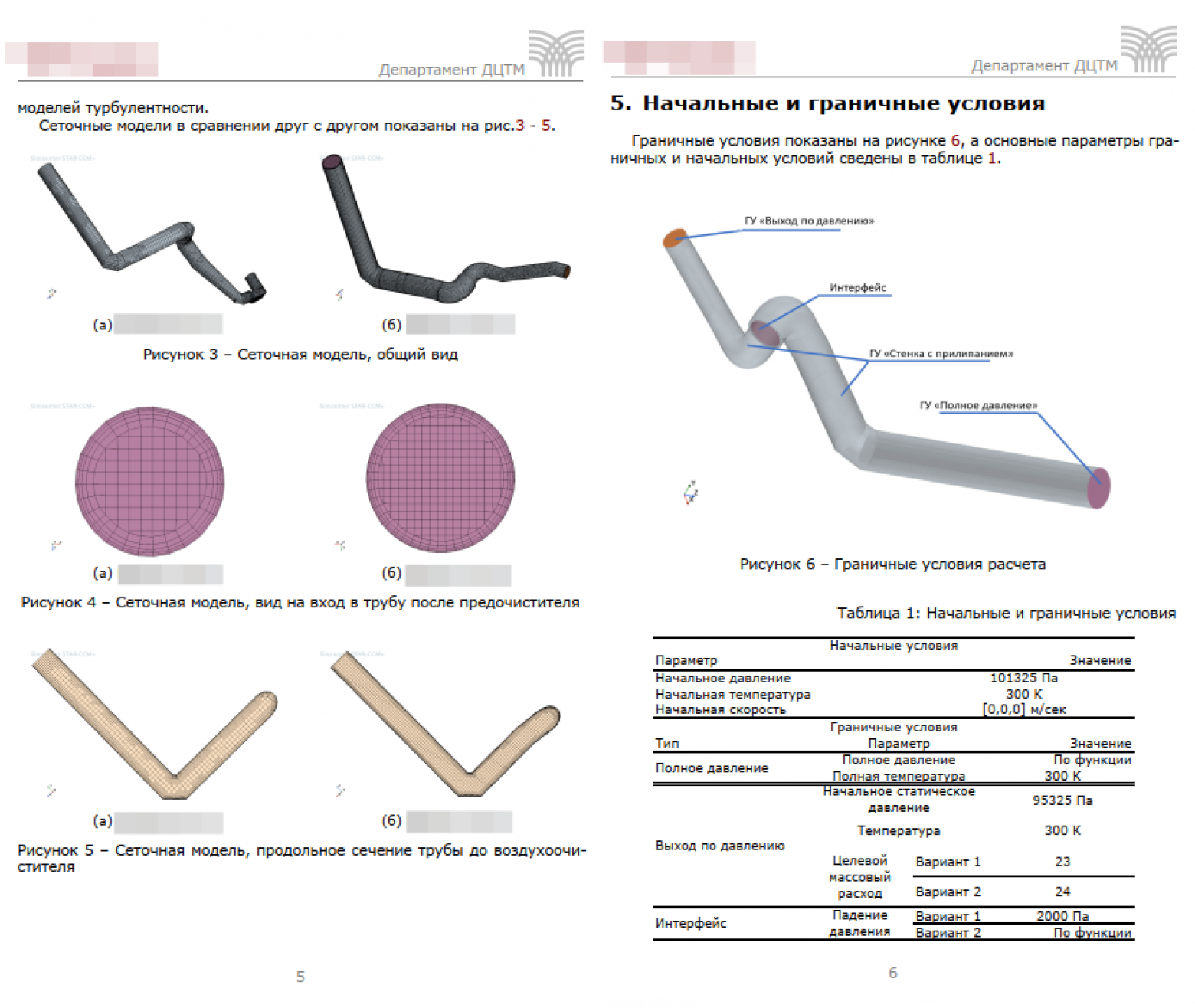
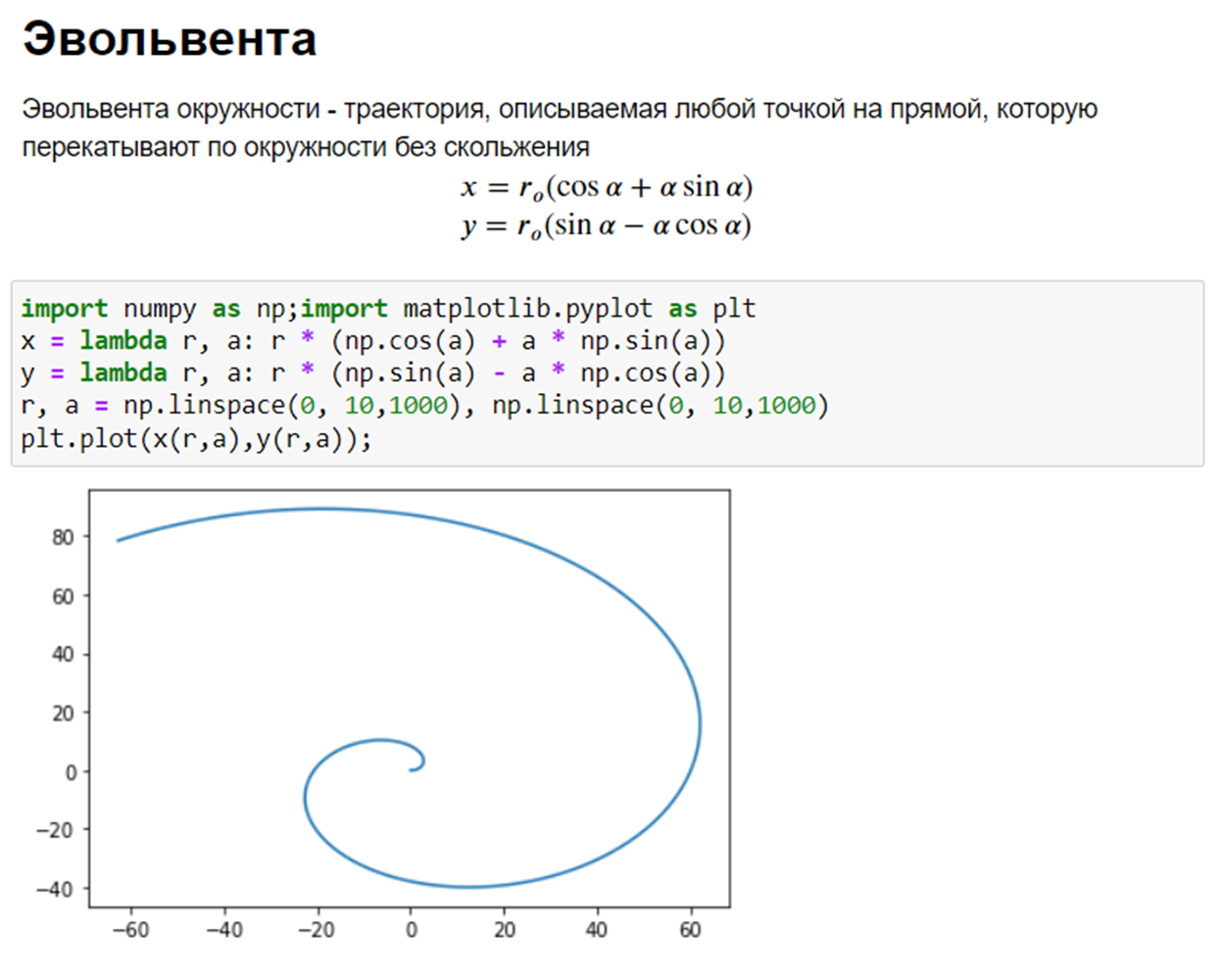
Эвольвента окружности - траектория, описываемая любой точкой на прямой, которую перекатывают по окружности без скольжения
$$x = r_o (\cos\alpha+\alpha\sin\alpha)$$
$$y = r_o (\sin\alpha-\alpha\cos\alpha)$$Чтобы к уравнению при верстке отчета автоматически добавлялся номер, надо в шаблоне применить следующий макрос:
\newcommand{\myequation}{\begin{equation}}
\newcommand{\myendequation}{\end{equation}}
let\[\myequation
let\]\myendequationТогда происходит следующее: nbconvert, когда встречает формулу в окружении $$<формула>$$ раскрывает ее как выражение \[<формула>\]. Макрос заменяет ее на окружение \begin{equation}<формула>\end{equation}, которая уже нумеруется автоматически.
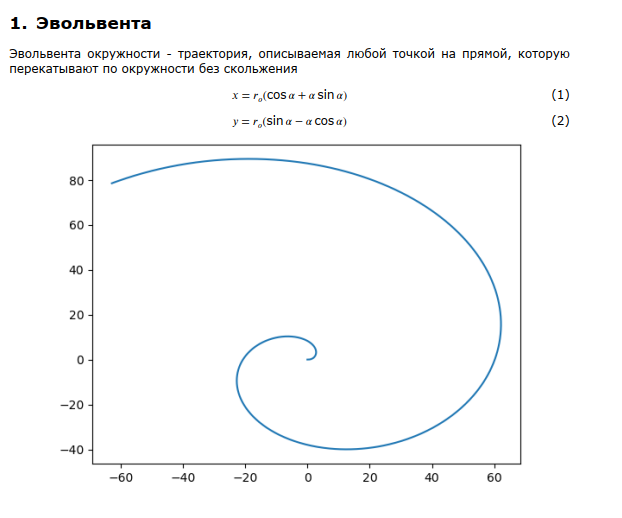
Если необходимо, чтобы после формулы стоял результат вычисления, то необходимо задавать формулу в кодовой ячейке, а для ее вывода определяется специальная функция:
def disp_tex(x: str):
x = Latex(x)
latex_x = x._repr_latex_()
latex_x = (
latex_x[:2].replace("$$", "\[")
+ latex_x[2:-2]
+ latex_x[-2:].replace("$$", "\]")
)
x._repr_latex_ = lambda: latex_x
display(x)Nbconvert не раскрывает должным образом окружение $$<формула>$$, если это результат вывода кодовой ячейки, поэтому приходится подменять метод классаLatex._repr_latex(), который отвечает за генерацию LaTeX-кода для уравнения.
Ячейки с формулами в Jupyter

Вывод в отчете
Настройка отображения таблиц
Одной из проблем были таблицы, которые коллеги использовали довольно часто. Дело в том, что настройка таблиц в LaTeX — это искусство для незаурядного пользователя, а надо было сделать это простым. Вот пример кода LaTeX небольшой таблицы.
\begin{table}[]
\begin{tabular}{ clcm{3cm} }
№ & Параметр 1 & Параметр 2 & Очень длинное название \\
1 & 0.1 & 1.000000e+01 & Январь \\
2 & 0.2 & 1.000000e+02 & Февраль \\
3 & 0.3 & 1.000000e+03 & Март \\
4 & 0.4 & 1.000000e+05 & Апрель \\
5 & 0.5 & 1.000000e+07 & Март
\end{tabular}
\end{table}
Так будет выглядеть таблица в отчете
Основная проблема вывода таблицы в нормальном качестве заключается в настройке ширины и смещения текста внутри ячейки для колонки. Для настройки используется строчка, которая пишется после объявления окружения \begin{tabular} и выглядит как-то так {lcrm{3cm}}.
Знаки l c r обозначают колонки с автоматической шириной и со смещением по левой стороне, по центру и по правой стороне соответственно.
m{3cm} обозначает колонку с шириной ровно 3 см, символ до размера колонки обозначает смещение текста в ячейке по вертикали. А вот для того, чтобы сделать пользовательское смещение текста по горизонтали надо определить в шаблоне следующие макросы:
\newcolumntype{L}[1]{>{\raggedleft\let\newline\\\arraybackslash\hspace{0pt}}m{#1}}
\newcolumntype{R}[1]{>{\raggedright\let\newline\\\arraybackslash\hspace{0pt}}m{#1}}Теперь мы можем в строке форматирования использовать L{3cm},R{3cm} которые позволяют установить столбцы нужной ширины со смещением текста по правой и по левой стороне соответственно.
Просить обычного пользователя оперировать всеми особенностями верстки таблиц LaTeX было бы жестоко. Для верстки основного тела таблицы легче всего использовать возможности пакета Pandas, который вполне справляется с версткой таблиц без объединенных ячеек. Поэтому пользователь может набирать таблицу в обычном Excel и загружать ее через функцию pd.read_excel().
Реализацию лучше скрыть от пользователя, оставив ему примитивные настройки, например, ширину определенной колонки в см. Для этого написан класс TABLE_REPR_LATEX, который возвращает объект с функциями _repr_html_()и _repr_latex_().
_repr_html_()вызывается в Jupyter, и это обычный вывод таблицы.
_repr_latex_()вызывается при вызове nbconvert.
Реализуя эти функции, мы даем возможность увидеть таблицу и в Jupyter блокноте и в конечном отчете.
Для работы с классом реализована функция
def display_pandas_table(*args, **kwargs):
return display(TABLE_LATEX_REPR(*args, **kwargs))Фактически пользователю для вывода таблицы из pd.DataFrame требуется только подать ее и некоторые настройки в эту функцию.
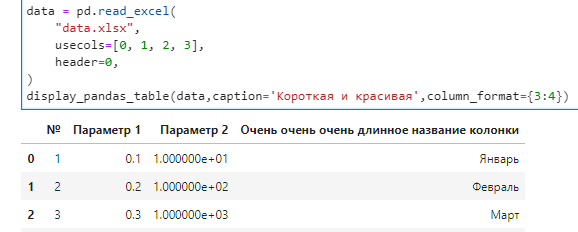
Вызов функции в Jupyter
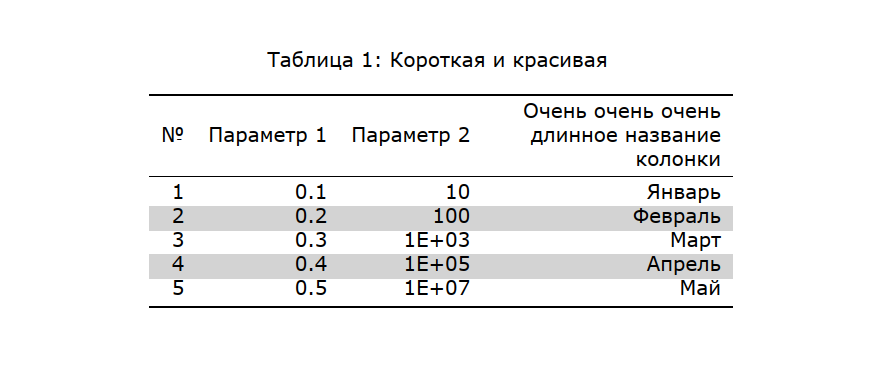
Таблица в выходном отчете
Для того, чтобы таблица выглядела приятно глазу в шаблоне и в коде класса есть выражения, которые добавляют расцветку строчек таблицы и округление чисел до десятичного знака. Для того чтобы пользователю установить ширину столбика, ему надо передать функции dict, с номером столбика и размером столбика в см (например column_format={3:4}). Также можно передать заголовок (например, caption = 'Заголовок'), тогда перед таблицей будет сверстана надпись с номером таблицы и заголовком. Для таблицы используется окружение longtable, поэтому длинные таблицы печатаются с переносом на следующий лист, а также вставляется заголовок таблицы на каждом листе (полезно, но можно убрать).
Вид длинной таблицы с разрывом
Формирование титульного листа с Word
Самая эпичная битва развернулась у меня именно с титульным листом. Нет, если вы хотите сделать обычный титульник, даже пускай с рамкой, LaTeX вам с легкостью предоставит такие возможности. Пример .tex файла с титульником показан здесь. В шаблоне будет достаточно вставить строку \input{titlepage.tex}. Для того, чтобы дать пользователю возможность записывать какую-нибудь информацию в шаблон (например, ФИО составителей, ФИО проверяющих, аннотацию) необходимо будет создать дополнительную функцию annotate_tex(). У функции простая задача — перезаписать LaTeX-переменные для всего текста.
У коллег титульник был не простой. Они хотели, чтобы у них был титульник по ГОСТ 2.105:
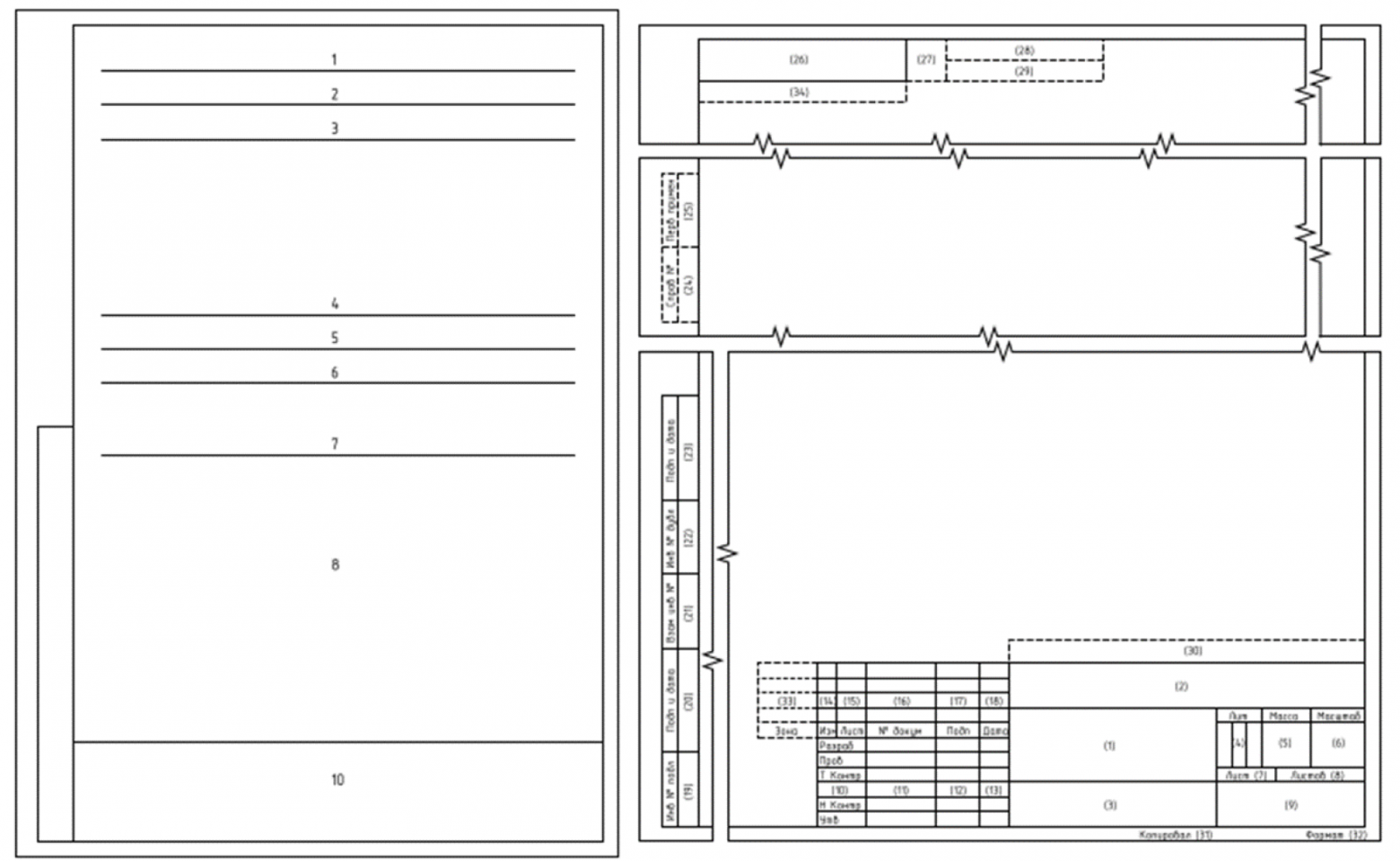
Без рамки по ГОСТу отчет на заводе — не отчет
В LaTex вроде бы есть пакет ESKDX, который создан как раз для того, чтобы отчетная документация соответствовала этому стандарту. Одна беда, заставить его работать у меня никак не получалось. Может быть, потому, что я все делал на XeLaTeX, может быть, потому, что модуль был написан в 2011 году. На форумах советовали забить на пакет ESKDX и самому написать стиль рамки. А это значит, что надо было взять книжку Кнута и наконец-то разобраться в самом сердце LaTeX — языке TeX.

Пример кода из книжки Кнута для создания списка объектов
Мне такая перспектива не улыбалась, поэтому я решил пойти другим путем.
У коллег уже был набран титульник с рамкой и нужным форматированием в Word. Фактически от меня требовалось только прицепить к этому титульнику отчетную часть. Соединить файлы в один документ можно с помощью модуля PyPDF2 после преобразования Word→pdf. При этом, конечно, не удалось бы обеспечить гостовскую рамку по всему документу, но это заказчика не смущало. Они в своих документах и так ее не обеспечивали.
Python может взаимодействовать с Word через модуль python-docx, а также через COM-объекты с помощью модуля Pywin32 или comtypes. Работа через python-docx удобнее, но, к сожалению, модуль не может изменить текстовые составляющие в таблицах, которые еще при этом вставлены в колонтитулы Word. А гостовские рамки, как вы можете догадаться, были сделаны как раз таблицами и именно в колонтитулах. Поэтому пришлось воспользоваться comtypes. Была написана функция annotate_docx(), которая пробегает по всему документу и заменяет отмеченные строки (например, такие — <<). Код функции находится здесь.
Пользователю для замены своих переменных по Word-документу требовалось только составить словарь замены, и подать его функции:
annotation = f"""Текст для аннотации: Здесь вы можете вставить текстовые данные любой длины с любым наполнением.
Так же поддерживаются символы новой строки \n
и есть возможность вставить переменные с помощью {'фигурных скобок'}
"""
replace_dict = {
"product_name": "обозначение изделия",
"analysis_title": "Вставьте свою тему расчета",
"analysis_id": "Вставьте номер расчета",
"annotation_body": annotation
}
annotate_docx("helpers/title.docx", "title.docx", replace_dict)Решение не элегантное, но рабочее. Даже полезное, если ваш расчет — это только небольшая часть текста, и вы хотите, чтобы он был всегда актуальным. Пример находится здесь.
Формирование титульного листа с пакетом ESKDx
Вся система рухнула на моменте организации удаленных расчетов. Завод составил нам удаленный стенд, я приступил к разработке системы удаленных расчетов, которая работала через SSH. На этапе тестов выяснилось, что запуск COM объектов через SSH бойко кладет удаленный стенд.

Я уже затылком чувствовал, что книжка Кнута подбирается ко мне, шелестя страницами. Решил в последний раз пробежаться по форумам в отчаянной попытке возродить модуль ESKDx. И повезло.
Составляющих успеха было две, и сложились они случайно. Первое, я начал пробовать MiKTex вместо TeXLive и он на лету установил какие-то недостающие шрифты. Второе — я набрел на эту ветку, где предложено немного пропатчить основной код автора модуля ESKDx. И это сработало. В одночасье у меня собрался проект, и появились классные рамки по всему тексту, а не только на титульном листе. Фактически существующая система стала выдавать отчетную документацию более высокого качества, чем на Word. Пример работающего проекта здесь.

Пример рамки ESKDx
Для настройки пользовательского текста, реализована функция annotate_docx, которая работает схожим образом как для варианта титульника с Word.
replace_dict = {
"ESKDproduct": "Номер продукта",
"ESKDtitle": "Тема расчета",
"ESKDsignature": "Номер расчета",
"ESKDroleDesignedBy":"Должность",
"ESKDdesignedBy": "Иванов И.И",
}
annotate_eskdx(replace_dict)Делаем кнопку запуска генерации
Ранее для генерации отчета требовалось запустить специальный батник, который отвечал за всю цепочку генерации. Например, для варианта с титульником из Word батник выглядел вот так:
REM Генерация тела отчета в PDF, титульник Word обрабатывается в самом ipynb
call jupyter nbconvert --execute --config=cfg.py --to pdf --no-input Report.ipynb
REM Склейка PDF титульника и тела отчета
call python final_merge.py Report.ipynbТакое решение меня не устраивало, и хотелось кнопку. Нажимаешь и отчет готов.
Кнопку получилось сделать через модуль Jupyter Widgets, пример с кодом находится здесь.
Но если ничего не сделать с ячейкой, то эта кнопка появится в выходном отчете. Для того, чтобы скрыть кнопку, можно присвоить ячейке тег Skip, а в файле cfg.py мы уже определили, что такие ячейки мы не считаем. Будет это выглядеть так:
Вид кнопки в jupyter Notebook

В отчетном документе кнопка не выводится
Хотелось бы, конечно, внедриться в нативный интерфейс Jupyter Notebook, но легкого способа это сделать я не нашел. Если кто-то знает таковой, просьба поделиться в комментариях.
Заключение
Так чем же закончилась история внедрения расчетов Python на заводе? После проработки расчетов совместно с коллегами решили провести показ проделанной работы. Коллеги сами должны были показать своему начальству, как выглядят расчеты и как с ними работается. Начальство сначала было настроено скептически, но коллеги с жаром защищали новый способ работы. В конце показа было решено продолжать развитие расчетов на Python.
Конечно, не все расчетчики перешли на новый способ работы, но те, которые перешли, сейчас переводят легаси код своего подразделения на Python. Есть уже истории успеха, когда один расчетчик передал расчет другому, второй поменял исходные данные, получил отчет и провел все бюрократические процедуры. И все за один день.
С помощью Teamcenter тестируется возможность передачи прав на запись только в файл исходных данных для специалистов других отделов. Так другие отделы могут получить полностью подготовленный отчет, но не имеют возможности испортить основной Jupyter-блокнот расчета.
В целом опыт использования Jupyter Notebook был признан успешным, а я сейчас думаю, как использовать этот же опыт для создания технологии самодокументированных автоматических и оптимизационных расчетов.
Все показанные выше примеры можно обнаружить здесь.
*Статья написана в рамках Хабрачелленджа 0.1, который прошел в ЛАНИТ осенью 2023 года
