Как мы научили робота чувству юмора

В IT-кругах ходит такая шутка, что машинное обучение (machine learning, ML) — это как секс в среде подростков: все об этом говорят, все делают вид, что этим занимаются, но, на самом деле, мало у кого это получается. У FunCorp получилось внедрить ML в главную механику своего продукта и добиться радикального (почти на 40%!) улучшения ключевых метрик. Интересно? Добро пожаловать под кат.
Немного предыстории
Для тех, кто читает блог FunCorp нерегулярно, напомню, что самый успешный наш продукт — UGC-приложение iFunny c элементами социальной сети для любителей мемов. Пользователи (а это каждый четвёртый представитель молодого поколения в США) закачивают или создают прямо в приложении новые картинки или видео, а умный алгоритм выбирает (или, как мы говорим, «фичерит», от слова «featured») лучшие из них и формирует каждый день 7 выпусков по 30–60 единиц контента в отдельную ленту, с которой взаимодействует 99% аудитории. В результате, заходя в приложение, каждый пользователь видит топовые мемы, видео и смешные картинки. Если заходить часто, то лента быстро пролистывается и пользователь ждёт следующего выпуска через несколько часов. Однако если заходить реже, featured-контент накапливается, а лента за несколько дней может вырасти до 1000 элементов.
Соответственно, встала задача: показывать каждому пользователю наиболее релевантный для него контент, сгруппировав интересные лично ему мемы в начале ленты.
За 9 с небольшим лет существования iFunny было несколько подходов к этой задаче.
Сначала попробовали очевидный способ сортировки ленты по количеству смайлов (наш аналог «лайков») — Smile rate. Это было лучше, чем сортировка в хронологическом порядке, но в то же время привело к эффекту «средней температуры по больнице»: мало какой юмор нравится вообще всем, и всегда будут те, кому не интересны (и даже откровенно раздражают) популярные на сегодня темы. А ведь хочется ещё и все новые прикольные шутки из своего любимого мультика увидеть.
В следующем эксперименте попытались учесть интересы отдельных микросообществ: любителей аниме, спорта, мемов с котиками и пёсиками, и т.п. Для этого стали формировать несколько тематических featured-лент и предлагать пользователям выбирать интересующие их тематики, используя тэги и распознанный на картинках текст. Стало в чём-то лучше, но потерялся эффект соцсети: стало меньше комментариев к featured-контенту, которые играли большую роль в вовлечённости (engagement) пользователей. Да ещё по пути к сегментированным лентам растеряли много действительно топовых общепопулярных мемов. «Любимый мультик» посмотрели, а шутки о «последних Мстителях» не увидели.
Поскольку мы уже начали внедрять в наш продукт алгоритмы машинного обучения, о чём делали доклад на нашем собственном митапе, очередной подход захотели сделать с использованием этой технологии.
Решено было попробовать построить рекомендательную систему на основе принципа коллаборативной фильтрации. Этот принцип хорош в случаях, когда у приложения есть очень мало данных о пользователях: немногие указывают при регистрации свой возраст или пол, и лишь по IP-адресу можно предположить их географическое местоположение (хотя и без гадалок известно, что подавляющее большинство пользователей iFunny — резиденты Соединённых Штатов), а по модели телефона — уровень доходов. На этом, в общем-то, всё. Коллаборативная фильтрация работает так: берётся история положительных оценок контента пользователя, находятся другие пользователи с похожими оценками, далее ему рекомендуется то, что уже ранее понравилось тем самым пользователям (с похожими оценками).
Особенности задачи
Мемы — достаточно специфический контент. Во-первых, он весьма подвержен быстро сменяющимся трендам. То содержание и та форма, которые выходили в топ и заставляли улыбаться 80% аудитории ещё неделю назад, сегодня могут вызывать раздражение своей вторичностью и неактуальностью.
Во-вторых, очень нелинейная и ситуационная интерпретация смысла мема. В подборке новостей можно зацепиться за известные фамилии, тематики, которые достаточно стабильно заходят у конкретного пользователя. В подборке кинофильмов можно зацепиться за актёрский состав, жанр и многое другое. Да, за всё это можно зацепиться и в подборке персональных мемов. Но как обидно будет упустить настоящий шедевр юмора, который использует образы или лексику, совершенно не ложащиеся на смысловое содержание!

Наконец, очень большое количество динамически создаваемого контента. В iFunny ежедневно пользователи создают десятки тысяч постов. Весь этот контент необходимо «разгребать» максимально быстро, а в случае персонализированной рекомендательной системы не только отыскивать «бриллианты», но и уметь предсказывать оценку контента самыми разными представителями социума.
Что эти особенности значат для разработки модели машинного обучения? В первую очередь то, что модель постоянно должна быть натренирована на самых свежих данных. На самом старте погружения в разработку рекомендательной системы ещё не совсем понятно, идёт ли речь о десятках минут или о паре часов. Но и то, и другое означает необходимость постоянного ретрейнинга модели, а ещё лучше — онлайн-обучение на непрерывном потоке данных. Всё это — не самые простые задачи с точки зрения поиска подходящей архитектуры модели и подбора её гиперпараметров: таких, которые бы гарантировали, что через пару-тройку недель метрики не начнут уверенно деградировать.
Отдельную сложность составляет необходимость следовать протоколу а/б-тестирования, принятому у нас. Мы никогда не внедряем ничего без предварительной проверки на части пользователей, сравнивая результаты с контрольной группой.
После долгих прикидок было решено стартовать MVP со следующими характеристиками: используем только информацию о взаимодействии пользователей с контентом, обучение модели проводим в реальном времени, прямо на сервере, оснащённом большим объёмом памяти, позволяющим хранить всю историю взаимодействия тестовой группы пользователей за достаточно длинный срок. Время обучения решили ограничить 15–20 минутами, чтобы поддерживать эффект новизны, а также успеть использовать самые свежие данные от пользователей, массово приходящих в приложение во время выпусков.
Модель
Сначала принялись крутить самую классическую коллаборативную фильтрацию с разложением матрицы и обучением на ALS (alternating least square) или SGD (stochastic gradient descent). Но достаточно быстро надумали:, а почему бы сразу не стартовать с простейшей нейронной сети? С простой однослойной сетки, в которой только один линейный embedding-слой, и отсутствует накрутка скрытых слоёв, чтобы не закопаться в неделях подбора её гиперпараметров. Немного за гранью MVP? Возможно. Но натренировать такую сетку едва ли сложнее, чем более классическую архитектуру, если имеется оборудование, снаряжённое хорошим GPU (пришлось на него раскошелиться).
Изначально было понятно, что есть только два варианта развития событий: либо разработка даст значимый результат в продуктовых метриках, тогда потребуется копать дальше в параметры пользователей и контента, в дообучение на новом контенте и новых пользователях, в глубокие нейросетки, либо персонализированное ранжирование контента не принесёт ощутимой прибавки и «лавочку» можно прикрывать. Если случится первый вариант, то всё перечисленное придётся докручивать к стартовому Embedding-слою.
Решили остановить свой выбор на Neural Factorization Machine. Принцип её работы следующий: каждый пользователь и каждый контент кодируются векторами фиксированной одинаковой длины — эмбеддингами, которые в дальнейшем обучаются на наборе известных взаимодействий между пользователем и контентом.
В обучающем наборе задействованы все факты просмотра контента пользователями. За положительный фидбек о контенте кроме смайлов было решено считать нажатия на кнопки «поделиться» или «сохранить», а также написание комментария. При его наличии взаимодействие размечается 1 (единицей). Если же после просмотра пользователь не оставил положительного фидбека, взаимодействие размечается 0 (нулём). Таким образом, даже в отсутствии явной шкалы оценок используется explicit-модель (модель с явной оценкой от пользователя), а не implicit, которая учитывала бы только положительные действия.
Implicit-модель тоже попробовали, но она сходу не заработала, поэтому сосредоточились на explicit модели. Возможно, для implicit-модели нужно использовать более хитрые, чем простая бинарная кросс-энтропия, ранжирующие лосс-функции.
Отличие Neural Matrix Factorization от стандартного Neural Collaborative Filtering в наличие так называемого Bi-Interaction Pooling слоя вместо обычного полносвязного слоя, который бы просто соединял эмбеддинг-векторы пользователя и контента. Bi-Interaction слой конвертирует набор эмбеддинг-векторов (в iFunny всего 2 вектора: пользователя и контента) в один вектор путём их поэлементного умножения.
В отсутствии дополнительных скрытых слоёв поверх Bi-Interaction получаем скалярное произведение этих векторов и, добавляя bias пользователя и bias контента, обворачиваем в сигмоиду. Это и есть оценка вероятности положительного фидбека от пользователя после просмотра данного контента. Именно согласно этой оценке ранжируем имеющийся контент перед демонстрацией его на конкретном девайсе.
Таким образом, задача обучения — сделать так, чтобы эмбеддинги пользователя и контента, по которым есть положительное взаимодействие, были близки друг к другу (имели максимальное скалярное произведение), а эмбеддинги пользователя и контента, по которым есть отрицательное взаимодействие, — далеки друг от друга (минимальное скалярное произведение).
В результате такого обучения эмбеддинги пользователей, которые смайлили одно и то же, становятся близки друг к другу сами собой. А это удобное математическое описание пользователей, которое может быть использовано во множестве других задач. Но это уже другая история.
Итак, пользователь заходит в ленту и начинает смотреть контент. При каждом просмотре, смайле, расшаривании и т.п. клиент отправляет статистику в наше аналитическое хранилище (о котором, если интересно, мы писали ранее в статье Переход с Redshift на Clickhouse). По дороге мы отбираем интересующие нас события и отправляем их на ML-сервер, где они сохраняются в памяти.
Раз в 15 минут на сервере запускается переобучение модели, после завершения которого новая статистика пользователя начинает учитываться в рекомендациях.
Клиент запрашивает очередную страницу ленты, она формируется стандартным образом, но по дороге список контента отправляется в ML-сервис, который сортирует его согласно весам, выданным обученной моделью для данного конкретного пользователя.
В результате пользователь видит сначала те картинки и видео, которые, по мнению модели, ему будут наиболее предпочтительны.
Внутренняя архитектура сервиса
Сервис работает по HTTP. В качестве HTTP-сервера используется Flask в связке с Gunicorn. Он обрабатывает два запроса: add_event и get_rates.
add_event запрос добавляет новое взаимодействие между пользователем и контентом. Оно складывается во внутреннюю очередь и затем обрабатывается в отдельном процессе (в пике до 1600 rps).
get_rates запрос рассчитывает веса для user_id и списка content_id согласно модели (в пике порядка сотни rps).
Основной внутренний процесс — Dispatcher. Он написан на asyncio и реализует основную логику:
- обрабатывает очередь add_event запросов и сохраняет их в огромном хешмапе (за неделю 200М событий);
- пересчитывает модель по кругу;
- раз в полчаса сохраняет новые события на диск, при этом удаляет из хешмапа события старше недели.

Обученная модель помещается в shared memory, откуда её вычитывают HTTP-воркеры.
Результаты
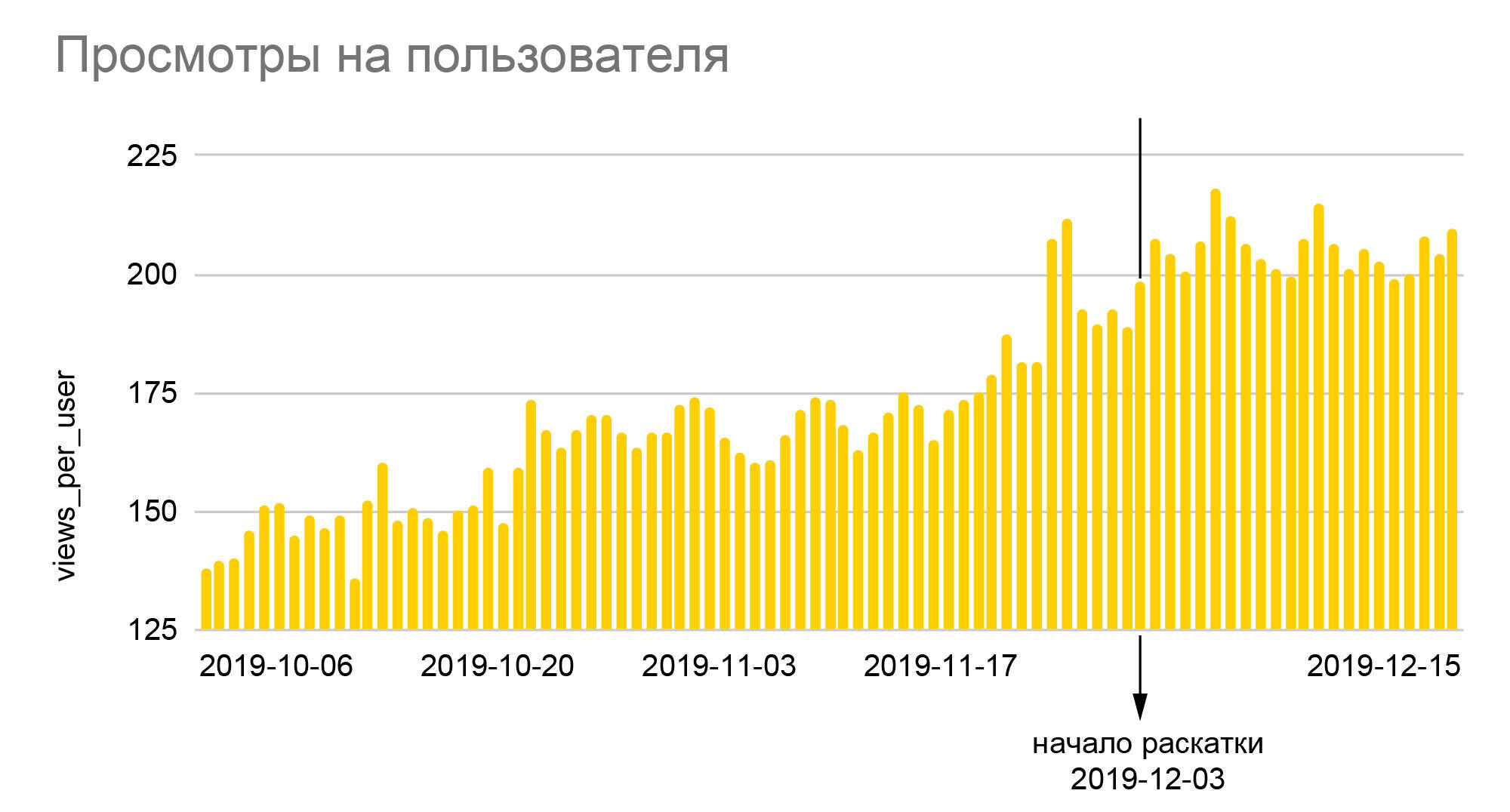

Графики говорят сами за себя. 25%-ный рост относительного числа смайлов и почти 40%-ный — глубины просмотров, который мы видим на них — это результат раскатки нового алгоритма на всю аудитории по окончании А/Б-теста 50/50, то есть реальный прирост относительно базовых величин был ещё почти вдвое больше. Поскольку iFunny зарабатывает на рекламе, то рост глубины означает пропорциональный рост доходов, который, в свою очередь, позволил нам достаточно спокойно пережить кризисные месяцы 2020 года. Рост числа смайлов переходит в большую лояльность, а значит, — меньшую вероятность отказа от приложения в будущем; лояльные пользователи начинают заходить в другие секции приложения, оставлять комментарии, общаться между собой. А главное, мы не только создалинадёжную основу для улучшения качества рекомендаций, но и заложили фундамент для создания новых функций, основанных на колоссальном количестве анонимных поведенческих данных, накопленных нами за годы работы приложения.
Заключение
Сервис ML Content Rate — результат большого количества мелких доработок и улучшений.
Во-первых, в обучении стали учитывать и незарегистрированных пользователей. Изначально по ним были вопросы, так как они априори не могли оставлять смайлы — наиболее частый фидбек после просмотра контента. Но вскоре стало понятно, что эти опасения были напрасны и закрывали очень большую точку роста. Много экспериментов делается с конфигурацией обучающей выборки: помещать в неё бОльшую долю аудитории или расширять временной интервал учитываемых взаимодействий. В ходе этих экспериментов выяснилось, что не только количество данных играет значительную для продуктовых метрик роль, но и время обновления модели. Зачастую прирост качества ранжирования тонул в лишних 10–20 минутах на пересчёт модели, из-за чего приходилось отказываться от новшеств.
Многие, даже самые небольшие доработки, дали результаты: либо улучшили качество обучения, либо ускорили процесс обучения, либо экономили память. Например, была проблема с тем, что взаимодействия не влезали в память, — пришлось их оптимизировать. Кроме того, код модифицировался и появилась возможность засунуть в него, например, больше взаимодействий на пересчёт. Также это привело к улучшению стабильности сервиса.
Сейчас ведётся работа над тем, чтобы эффективно использовать известные параметры пользователя и контента, сделать инкрементную быстро дообучаемую модель, а также появляются всё новые гипотезы для будущих улучшений.
Если вам интересно узнать о том, как мы развивали этот сервис и какие ещё улучшения сумели внедрить — пишите в комментарии, через некоторое время мы будем готовы написать вторую часть:)
Об авторах
К сожалению, Хабр не позволяет указать несколько авторов у статьи. Хотя статья опубликована от моего аккаунта, бóльшая её часть написана ведущим разработчиком ML-сервисов FunCorp — Гришей Кузовниковым (PhoenixMSTU), а также аналитиком и дата-сайентистом — Димой Земцовым. Перу вашего непокорного слуги принадлежат, в основном, шуточки про подростковый секс, введение и секция про результаты, плюс редакторская работа. И, конечно, все эти достижения были бы невозможны без помощи команд разработки бэкэнда, QA, аналитиков и продуктовой команды, всё это придумавшей и потратившей несколько месяцев на проведение и корректировку А/Б-экспериментов.
