Как мы научили нейросеть разбирать названия товаров в чеках
Год назад мы запустили ПроЧек — приложение для хранения и анализа чеков. Он получает чеки пользователя из ФНС, сортирует их и строит графики расходов. У ПроЧека есть киллерфича он автоматически определяет категорию каждого товара из чека. То есть не просто относит весь чек к одной категории, как делают банковские приложения в своих отчетах. ПроЧек правда разберет чек из Ашана по полочкам яблоки — к продуктам, корм для кота — к питомцам, а стиральный порошок к бытовой химии. За категоризацию отвечает гибридное решение с использованием искусственного интеллекта. Расчетная точность модели — 95%.Меня зовут Александр Бондин, я руководитель направления Разработка в STM Labs и в статье расскажу, как устроен категоризатор, за что отвечает ИИ, а за что — живые люди. Еще поделюсь лайфхаком, как почти бесплатно, без регистрации и СМС разметить пару миллионов объектов для тренировки нейросети.
 Приложение ПроЧек
Приложение ПроЧек
Как мы собираем данные
По закону все чеки о покупках хранятся в налоговой в электронном виде. С разрешения пользователя ПроЧек получает из базы ФНС все его чеки в автоматическом режиме — главное, чтобы к чеку был привязан номер телефона или email. Для этого контакт надо назвать кассиру при покупке. Либо можно добавлять покупки вручную, отсканировав QR-код на бумажном чеке.
Все чеки пользователя в ПроЧеке хранятся в удобном виде, их можно сортировать и анализировать в зависимости от задач. Например, выбирать категории вручную или автоматически, разбирать по тематическим папкам, выгружать отчеты в нужном формате, строить графики расходов.
Категоризатор в приложении автоматически определяет категорию для каждого товара пользователю не нужно тратить время на сортировку покупок, приложение делает это само. А потом строит графики по тратам в разных разрезах.
Чтобы обучить нейросеть категоризации нужен огромный массив данных — чеков, где каждой позиции уже присвоена категория. У нас уже был большой массив чеков, оставшийся от предыдущего проекта. Именно их мы хотели использовать для ML. Но работать с ним оказалось невозможно — выборка была уже обработана, сокращения расшифрованы, ошибки исправлены. Это не было похоже на реальные входные данные.
Поэтому мы стали собирать датасет с органическим данными, поступающими в ПроЧек. Начинали работу всего с 8 тысяч позиций. На момент выхода статьи в датасете уже больше 2 млн позиций. И он продолжает пополняться — каждую неделю в Прочек поступает 25 тысяч чеков, это почти 300 тысяч товарных позиций в месяц. А значит, точность непрерывно растет.
Дисклеймер про безопасность ПДН
Отмечу, что при всех манипуляциях мы используем данные в обезличенном виде. Для обработки берем только информацию о названиях и стоимости товаров. Из датасета невозможно определить, кто и с помощью какой карты совершил покупку.
Первые попытки в NLP
Итак, мы получаем чеки. У каждой позиции в чеке есть название и цена, ну и еще некоторые метаданные, в данном случае они не важны. Помните, как выглядят названия в чеках Максимум сокращений, неведомые коды из цифр и букв.
Поэтому массивная часть задачи — обработать название и разобрать, что такого купил пользователь.
На первый взгляд, здесь должны помочь методы обработки естественного языка (Natural Language Processing). Но с помощью NLP обычно обрабатывают более длинные тексты, чем названия товаров в чеке. Они обычно не длиннее 100 символов, а бывают и наименования всего из нескольких букв — УЗИ или СТО, например. Классические подходы NLP хороши для анализа комментариев на Кинопоиске или постов в Твиттере. Они помогут разобраться, что имел ввиду Л.Н. Толстой, описывая дуб на нескольких страницах. Но найти, чем отличается «Сыр сметанковый» от «Сырка глазированного» — это уже другая задача.
Обычно в NLP берется большой объем текстовой информации и составляется векторное пространство слов — в зависимости от частоты их упоминания и взаимного расположения. В названиях из чеков векторное пространство просто не дает смысловой нагрузки — наименования слишком короткие, часто встречаются ошибки и сокращения, коды и артикулы.
Мы пробовали разные способы предобработки и преобразования данных, разные методы кластерного анализа для разметки, использовали предобученные вектора и мультиязычные модели. Например, работали с bag-of-words и word2vec. Результат был так себе.
В итоге решили взяться за большое и сложное решение — фреймфорк DeepPavlov, в основе которого лежит трансформер BERT. DeepPavlov — это открытая программная библиотека для обработки естественного языка, предобученная на огромном массиве русскоязычной информации. Разработчики обработали всю классическую литературу, часть современной, посты в соцсетях и форумы, статьи википедии.
Вообще DeepPavlov чаще применяют для чатботов и прочих разговорных задач. Но какая разница, если наше новое решение в итоге смогло отличить даже молоко от молочка для тела, не говоря о более очевидных вещах.
Предобработка данных нормализация
Как я уже говорил, данные в чеке сильно отличаются от текстов, с которыми работают методами NLP. И, раз уж мы имеем на входе «very short text», то следует подавать модели максимально смысловую его часть.
Поэтому мы ввели предобработку данных — приводим каждое название к нормализованному виду
переводим все символы в нижний регистр
склеиваем лишние пробелы
удаляем спецсимволы — они минимально влияют на определение товара
удаляем цифры и цифро-буквенные коды — у разных магазинов они разной длины и разного формата.
в определенных позициях цифры меняем на числительные — например, «АИ-95» превращается в «бензин девяносто пятый»
Тем самым мы превращаем множество коротких текстов в один указатель. Это упрощает разметку данных для обучения вместо того, чтобы, условно, сто тысяч раз написать класс, мы один раз размечаем нормализованную позицию. А затем с помощью маппинга нормализованного имени с ненормализованными именами получаем, условно, сто тысяч размеченных позиций. Так, на данный момент мы храним 110+ тысяч строк нормализованных позиций, которые соответствуют 2,3 млн товаров.
Как пришли к таким правилам нормализации
Сначала мы пытались
обрабатывать сокращения с помощью pymorphy2. Но часто случались ошибки — например, «смрз» разворачивалось как саморазвитие, а не саморез.
ввести лемматизацию — приведение всех слов к начальной форме, т.е. именительный падеж, единственное число для существительных и прилагательных или инфинитив для глаголов. В итоге «носки» превращались в слово «носка», а «чай» в глагол «чаять»
использовать стемминг — нахождение основы слова, без учета его окончания.
Искать все подобные исключения и создавать правила для каждого выглядело неподъемной работой. Поэтому от этих методов мы отказались.
Цифры мы везде пытались заменять словами, но числительные — достаточно длинные слова, поэтому они начинали иметь даже больший вес, чем названия, вносили много шумов. В итоге мы просто отказались почти ото всех цифр и цифро-буквенных кодов — кроме, например, того же бензина.
Да, это может вызвать ошибки — например, моделька мерседеса 125 распознается, как автомобиль, а не как игрушка. Но, во-первых, подобных случаев еще не было, а во-вторых, такие расхождения мы планируем в будущем предотвратить, ориентируясь на стоимость товаров.
Примерно на миллионе данных в датасете, мы заметили, что модель верно категоризирует даже странную кучу сокращений в одном наименовании, которую человек без гугла не разберет. Значит, нормализация работает как надо.
ML ожидание и реальность
Весной появились сезонные товары — вроде садового инвентаря и арбузов. Модель стала ошибаться чаще, потому что в органических данных раньше ничего подобного не встречалось. Тогда мы выдали модели вотум недоверия и ввели словарь.
Задача словаря — хранить все нормализованные и размеченные данные позиции. Теперь каждая входящая нормализованная позиция сперва маппится со словарем. Если совпадение обнаружено, то позиции сразу присваивается категория, без использования ИИ. Если же совпадения нет, модель получает шанс определить категорию самостоятельно.
Кроме читерства в определении категории, со словарем удобнее готовить обучающую выборку для модели словарь маппится на весь объем входящих позиций, поэтому получается картина, частотно совпадающая с входным потоком.
На самом деле, мы нашли способ еще больше повысить точность — стали использовать некоторые вспомогательные атрибуты чека, не только названия. Например, подписки вроде ivi или okko определяем по ИНН, а лекарства — по коду маркировки. В этих случаях мы присваиваем покупке категорию на уровне предпроцессоров, еще до парсинга названия, но потом все равно добавляем позицию в словарь и обучающий датасет.
Как разметить данные быстро, без регистрации и СМС
Выходные данные модели состоят из двух частей предполагаемая категория для позиции и % вероятности этой категории — то есть насколько модель уверена в своем решении. Модели разрешено присваивать категорию, только если уверенность выше 95%.
Если процент ниже порога, то в продакшене позиция остается без категории — таких примерно 17%. Эти позиции вместе с предполагаемой категорией отправляется на валидацию к живому дата-инженеру. Он размечает позицию, добавляет в словарь и обучает модель на новых данных.
Входящих данных становилось все больше и дата-инженеры перестали успевать размечать все позиции, с которыми модель не справлялась. Отдавать разметку на аутсорс не хотелось, поэтому мы привлекли собственных коллег из STM Labs.
Мы запустили телеграм-бот, где асессором мог стать любой сотрудник, например, во время перерыва на чашку чая.
Как это работает: Бот присылает пользователю нормализованное наименование позиции с категорией, которую предположила модель. Задача пользователя — оценить, верно ли присвоена категория.
Входной порог для такой разметки низкий — обычный человек почти всегда может распознать, что за товар указан в чеке. Хотя двойную валидацию мы все равно ввели — все данные перепроверял кто-то из команды дата-инженеров. Но даже с учетом этой повторной проверки бот сэкономил нам кучу человеко-часов.
Чтобы ускорить процесс, мы добавили элемент геймификации за каждый ответ выдавали по баллу, а рекордсменам дарили шоперы, термокружки и прочий мерч. Таким образом только за первую неделю добровольные асессоры разметили около 30 тысяч позиций.
Но тут мы столкнулись с проблемой геймификации некоторые люди отмечали какой попало ответ, лишь бы набрать баллы. В общем, скорость разметки сильно выросла, но качество в какой-то момент пострадало. После разъяснений и воспитательных бесед все пришло в норму.
Как это работает сейчас
На данный момент категоризатор работает по такой схеме
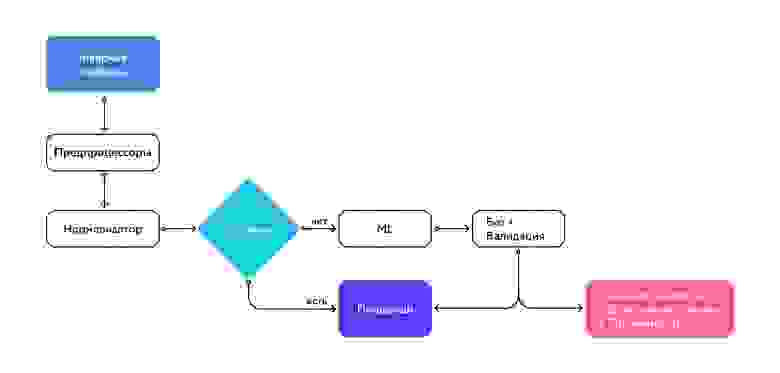 Схема работа категоризатора
Схема работа категоризатора
Категория присваивается позициям мгновенно — чек только что загрузился, а пользователю уже видно, к каким категориям относятся покупки. Задержек нет благодаря микросервисной архитектуре на платформе flexiflow.
flexiflow — это платформа для высоконагруженных приложений, разработанная STM Labs. Она позволяет быстро запускать и легко масштабировать сервисы для работы с BigData.
Категоризатор — один из микросервисов ПроЧека. Он разрабатывался как часть приложения ПроЧек, но может использоваться самостоятельно, для решения отдельных задач. С помощью API категоризатор можно подключить, например, к информационной системе магазина и проверить категории для всех выбитых чеков или разбить каталог товаров на категории.
Выводы и планы
Казалось бы, задача классификации весьма примитивна по своей сути. И использовать BERT для расшифровки чеков — это как стрелять из пушки по воробьям. Но другие методы не сработали, поэтому мы не постеснялись взять такую мощную технологию.
Благодаря качественной обработке естественного языка дальнейший machine learning в этой задаче является довольно простым. После векторизации данных мы обрабатываем их обычной логистической регрессией.
Мы продолжаем работать над точностью нашего гибридного решения со словарем и нейросетью. У нас есть несколько направлений для дальнейшего развития
расширять датасет и переобучать модель на новых данных
научиться распознавать каждый отдельный товар, а не только его категории
использовать все данные из чеков, в том числе теги маркировки и GTIN-штрихкоды
добавить параметры для обучения — например, использовать названия магазинов и время покупки.
Если у вас есть идеи для развития проекта — делитесь в комментариях. На вопросы тоже с удовольствием отвечу в комментариях к статье.
