Как мы кластеризуем подарки
Всем привет! Меня зовут Артур, я аналитик в отделе анализа данных департамента рекламных технологий Mail.Ru Group. И я попробую рассказать о том, как мы используем кластеризацию в своей работе.Чего в этой статье не будет: я не буду рассказывать об алгоритмах кластеризации, об анализе качества или сравнении библиотек. Что будет в этой статье: я покажу на примере конкретной задачи что такое кластеризация (с картинками), как ее делать если данных действительно много (ДЕЙСТВИТЕЛЬНО много) и что получается в результате.
 Итак, задача. У пользователей соц.сети OK.RU, как и во многих других сетях, есть возможность дарить друг другу милые и не очень подарочки. Поскольку такие дарения приносят определенную прибыль — ее хотелось бы максимизировать. Один из очевидных путей максимизации — построить хорошую рекомендательную систему.
Итак, задача. У пользователей соц.сети OK.RU, как и во многих других сетях, есть возможность дарить друг другу милые и не очень подарочки. Поскольку такие дарения приносят определенную прибыль — ее хотелось бы максимизировать. Один из очевидных путей максимизации — построить хорошую рекомендательную систему.
Что это значит в смысле подарков в OK.RU? N различных подарков дарятся M различными пользователями ежедневно, а в праздничные дни количество дарений вырастает в десятки раз. Поскольку N и M, как вы, наверное, догадываетесь, крайне велики — для хранения и обработки этих данных мы используем Hadoop.
Очевидно, что распределение количества дарений на подарок, как и множество подобных распределений, удовлетворяет закону Ципфа и, поэтому, матрица дарений крайне разрежена. В связи с этим, практически невозможно рассматривать для рекомендаций каждый подарок в отдельности, что наводит на мысль о кластеризации. Я не берусь утверждать, что кластеризация лучший или, тем более, единственно верный путь, но надеюсь, что к концу статьи вы поймете почему он мне нравится.
Зачем вообще кластеризовать подарки и как понять насколько подарки похожи? Ответ на первый вопрос примерно таков: когда место отдельного подарка занимает кластер подарков — у нас увеличивается количество дарений каждого объекта и уменьшается количество таких объектов. А значит больше статистики и меньше размерность. Ответов на второй вопрос миллион, но я люблю один конкретный: если пользователь подарил два подарка — они чем-то похожи.

За простотой этой формулировки кроется все, что можно придумать про цветовые предпочтения, персональные интересы, личностные качества и подобные пользовательские характеристики. Конечно, если взять одного конкретного пользователя и два его подарка, то вполне может оказаться, что один он подарил, потому что любит котиков, а второй, в виде черепа, на день рождения знакомого байкера-металлиста. Но, когда у вас миллионы пользователей вероятность такого сочетания сильно падает по сравнению с двумя котиками. По сути, отношение пользователь-подарок образует двудольный граф одну «долю» которого мы и хотим кластеризовать.
Как на этом построить хорошую меру? А все как обычно — за нас давно все придумали, в данном случае это сделал некто Поль Жаккар (англ. Paul Jaccard). Допустим у нас есть A — множество пользователей, подаривших первый подарок и B — второй. Тогда коэффициентом сходства будет формула:
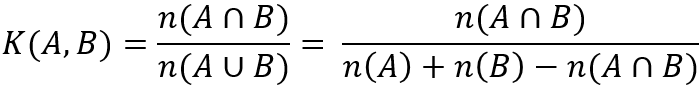
Вообще, распространенных коэффициентов сходства не так мало, но нас вполне устраивает этот. Как только у нас есть «схожесть» — остается выбрать алгоритм кластеризации. Для многих алгоритмов кластеризации необходима пространственная интерпретация объектов. Так, например, простой k-means должен иметь возможность вычислять центроиды. Однако есть алгоритмы, и их достаточно много, которым хватает попарных расстояний или, наоборот, «схожестей» между объектами. К таким алгоритмам относится, например, обобщение k-means — k-medians. В интернете, безусловно, масса статей на тему кластеризации и найти подходящий алгоритм не составляет большого труда.
В нашем случае, одним из требований было наличие готовой библиотеки, позволяющей работать не только с «игрушечными» датасетами. Кроме того, нам не хотелось явно указывать количество кластеров, так как мы не знаем заранее количество «интересов» пользователей OK.RU. В итоге выбор пал на MCL о котором подробнее можно почитать тут. Кратко: MCL получает на вход файл, каждая строка которого содержит два идентификатора подарков и симилярити и пишет в выходной файл кластеры построчно в виде списка идентификаторов.
На сайте библиотеки можно почитать, какие еще форматы входных данных доступны, а также список опций кластеризации. Кроме того, там есть описание самого алгоритма кластеризации и, что немаловажно, описание того, как пользоваться MCL в R.
Итого, решение выглядит примерно так:
Берем много событий вида пользователь U подарил подарок P
Считаем для каждой пары подарков количество пользователей, которые подарили их оба (ничего себе задачка, как вам кажется?). А так же, количество дарений каждого подарка.
Для каждой пары подарков вычисляем коэффициент Жаккара.
Полученные данные скармливаем MCL
…
Profit!!! (не мог удержаться, сори)
А теперь, собственно, картинки! А именно, примеры полученных кластеров на реальных данных. Одна картинка — один кластер: цветы бывают разными


туфли и яйца


с новым годом — пошел нафиг

женщины и дети


и даже подарки с загнутой подписью!
 На мой взгляд, эта простая история одной кластеризации дает поверхностное представление о той мощи, которая скрывается за словами «машинное обучение». Ведь по сути, что у нас есть на входе? Один простой факт о том, что два подарка дарились одним и тем же пользователем. Что у нас есть на выходе? Кластеры подарков с такой семантикой, которую не всякий модератор способен выделить. Область применения этих данных очевидна — это и банальные рекомендации пользователям, и автоматическое тегирование, и материал для статьи на Хабр. И, позволю себе побыть немного в роли Капитана Очевидность, подарки можно заменить: доменами, поисковыми фразами, покупками в магазине или странами туристических путешествий. Если есть данные, главное — не бояться экспериментировать.
На мой взгляд, эта простая история одной кластеризации дает поверхностное представление о той мощи, которая скрывается за словами «машинное обучение». Ведь по сути, что у нас есть на входе? Один простой факт о том, что два подарка дарились одним и тем же пользователем. Что у нас есть на выходе? Кластеры подарков с такой семантикой, которую не всякий модератор способен выделить. Область применения этих данных очевидна — это и банальные рекомендации пользователям, и автоматическое тегирование, и материал для статьи на Хабр. И, позволю себе побыть немного в роли Капитана Очевидность, подарки можно заменить: доменами, поисковыми фразами, покупками в магазине или странами туристических путешествий. Если есть данные, главное — не бояться экспериментировать.
