Как мы используем item2vec для рекомендаций похожих товаров
Привет, меня зовут Вася Рубцов, я занимаюсь разработкой рекомендательных систем в Авито.
Основная цель площадки для размещения объявлений — помочь продавцам найти покупателей, а покупателям — товары, которые они ищут. В отличие от интернет-магазинов факт продажи происходит за пределами нашей платформы, и мы не можем это отследить. Поэтому ключевой метрикой у нас является «контакт» — это событие нажатия кнопки «показать телефон» на карточке товара, либо начало диалога в мессенджере с продавцом. Из этой метрики мы получаем «байеров» — количество уникальных пользователей в день, которые сделали по крайней мере один контакт.
Два основных продукта, которым занимается отдел рекомендаций в Авито, — это рекомендации для пользователя на главной странице или user2item и блок похожих объявлений на карточке товара или item2item. Треть всех просмотров объявлений и четверть всех контактов происходит с рекомендаций, поэтому рекомендательные движки играют важную роль в Авито.
В статье я расскажу, как мы улучшили наши item2item рекомендации за счёт item2vec и как это повлияло на user2item рекомендации.
Как было раньше
Раньше для поиска похожих объявлений мы использовали линейную модель на фичах, полученных для пары объявлений: количество совпавших слов в заголовке и описании объявления, совпадение локации, параметров, близость по гео. Коэффициенты в этой модели подбирались многорукими бандитами. Мы рассказывали это в отдельной статье.
Такая модель в большинстве случаев справлялась с тем, чтобы находить и ранжировать похожие объявления, но имела и недостатки. Например, объявления с такими заголовками как «Миниатюрная wifi камера» и «SQ11» имели низкую схожесть, потому что заголовки не пересекались по словам, однако, это практически синонимы. Другой пример — вакансии «Комплектовщик в ночь», «Грузчик с ежедневной оплатой», «Продавец-консультант» и «Менеджер отдела продаж». Старая модель не будет считать такие объявления похожими, да и в общем смысле они не очень похожи, но пользователи Авито часто смотрят их вместе. Всех их можно описать словом «подработка» и лучше к вакансии грузчика показать объявление о поиске продавца из того же города, чем грузчика из соседнего.
Исправить такие недостатки и увеличить точность модели поможет векторное представление объявлений, полученное моделью, которая обучалась на пользовательских действиях. Идейным вдохновителем для нас была статья норвежского классифайда finn.no «Deep neural network marketplace recommenders in online experiments».
Идея item2vec
Идея item2vec заключается в том, что мы отображаем объявление в вектор в некотором многомерном пространстве таким образом, что похожие объявления имеют близкие векторы в этом пространстве.
Когда мы думаем о близости, то обычно представляем классическое евклидово расстояние. Однако на практике чаще используют косинусное расстояние или скалярное произведение.

Если посмотреть на изолинии этих трёх метрик для некоторого вектора, то кажется, что они совершенно не похожи друг на друга. Однако есть вырожденный случай, при котором все три метрики инвариантны — когда нормы всех векторов одинаковые. Тогда все векторы лежат на многомерной сфере, и вектор, который ближе по евклидову расстоянию, также будет ближе и по косинусному расстоянию, и по скалярному произведению. Почему этот случай важен для нас? При обучении мы используем скалярное произведение, и вот как выглядит распределение норм векторов после обучения:
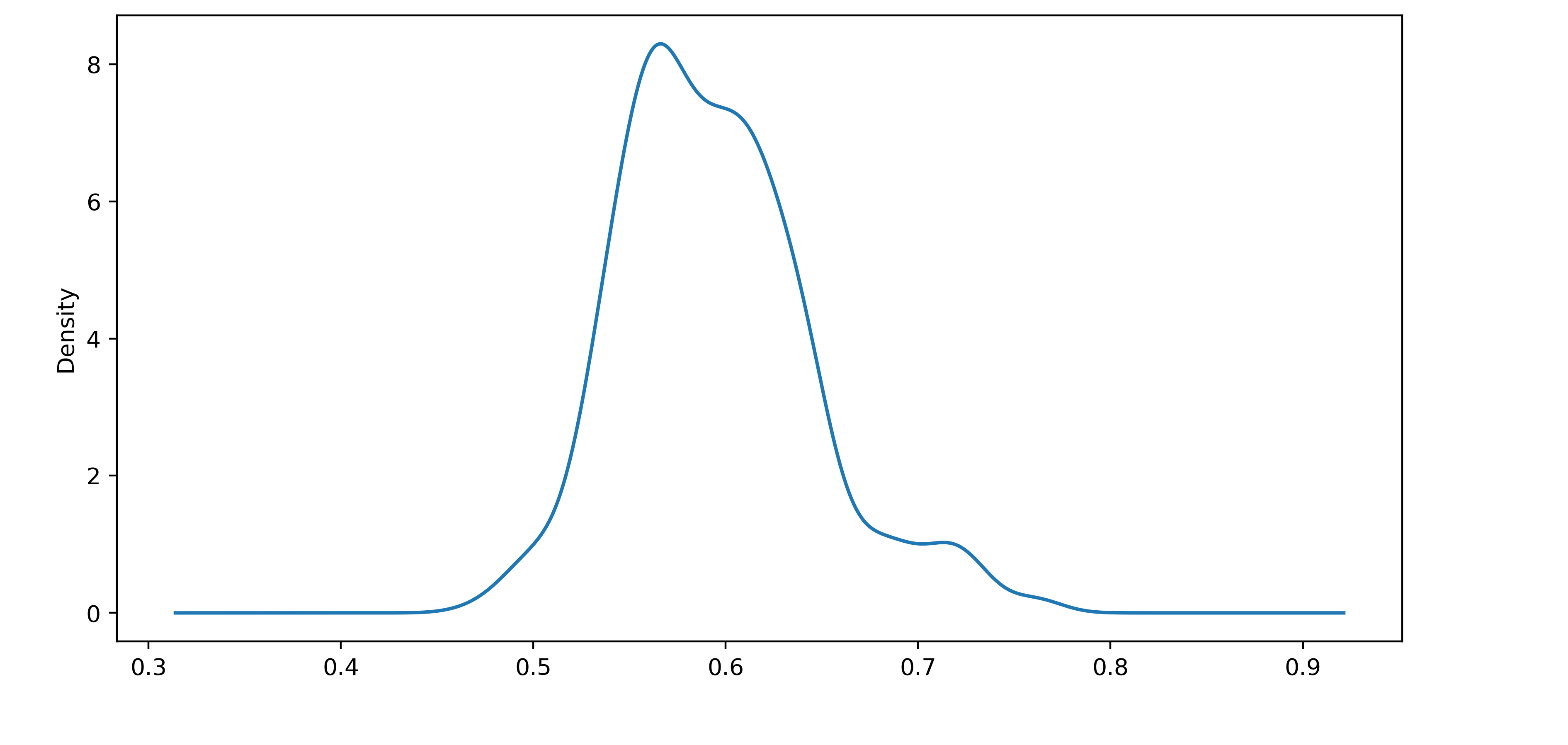
На картинке видно, что векторы имеют норму 0.6 ± 0.1. Для наглядности изобразим случайные векторы в двумерном пространстве с точно таким же распределением норм.

Они практически лежат на сфере. В случае, когда векторы имеют примерно одинаковую норму, в формуле скалярного произведения ключевым является именно угол между векторами. Но зачем тогда векторам иметь разную длину?
Предположим, что к дешёвым айфонам мы хотим рекомендовать дешёвые, а к дорогим — тоже дешёвые, потому что знаем, что вероятность контакта на них больше. Тогда мы могли бы сделать так, чтобы все айфоны были сонаправлены, но при этом дешёвые имели норму больше. В таком случае мы всегда будем рекомендовать именно их. На практике мы не проверяли, какие именно объявления и почему имеют большую или маленькую норму. Но мы знаем, что у модели есть дополнительная свобода в несимметричности при ранжировании, и что если мы явно отнормируем векторы после обучения, то снизятся оффлайн-метрики.
Данные для обучения
В качестве данных мы собираем пары похожих объявлений. Похожими считаем объявления, которые были последовательно законтачены пользователем, если время между событиями было меньше 8 часов. Для обучения мы брали контакты за последние 3 года.
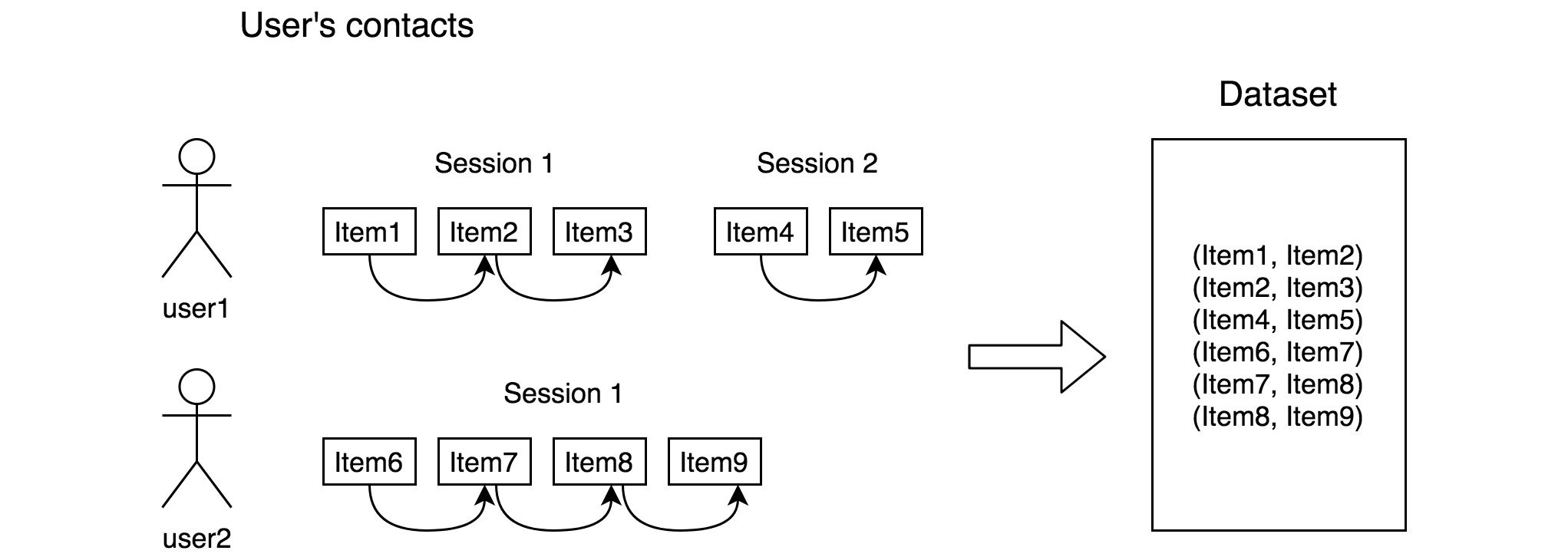
Контакты мы выбрали, потому что кажется, что это наилучший сигнал о схожести объявлений. Кроме того, брали контакты только с desktop и у залогированных пользователей. Не залогиненные не улучшали качество, а контакты с app — ухудшали.
Всего для обучения было 540 млн контактов и 180 млн объявлений.
Нейроночка
Для каждой категории объявлений мы обучаем отдельную модель — всего 14 штук. Разделили мы их, потому что у разных категорий отличаются фичи, на которых обучаем. Например, в категориях «Авто» и «Недвижимость» заголовок формируется автоматически из параметров. Поэтому там нужны параметры. В других категориях самое главное — это заголовок и его обработка.
Архитектура нейронки для одной из категорий выглядит так:
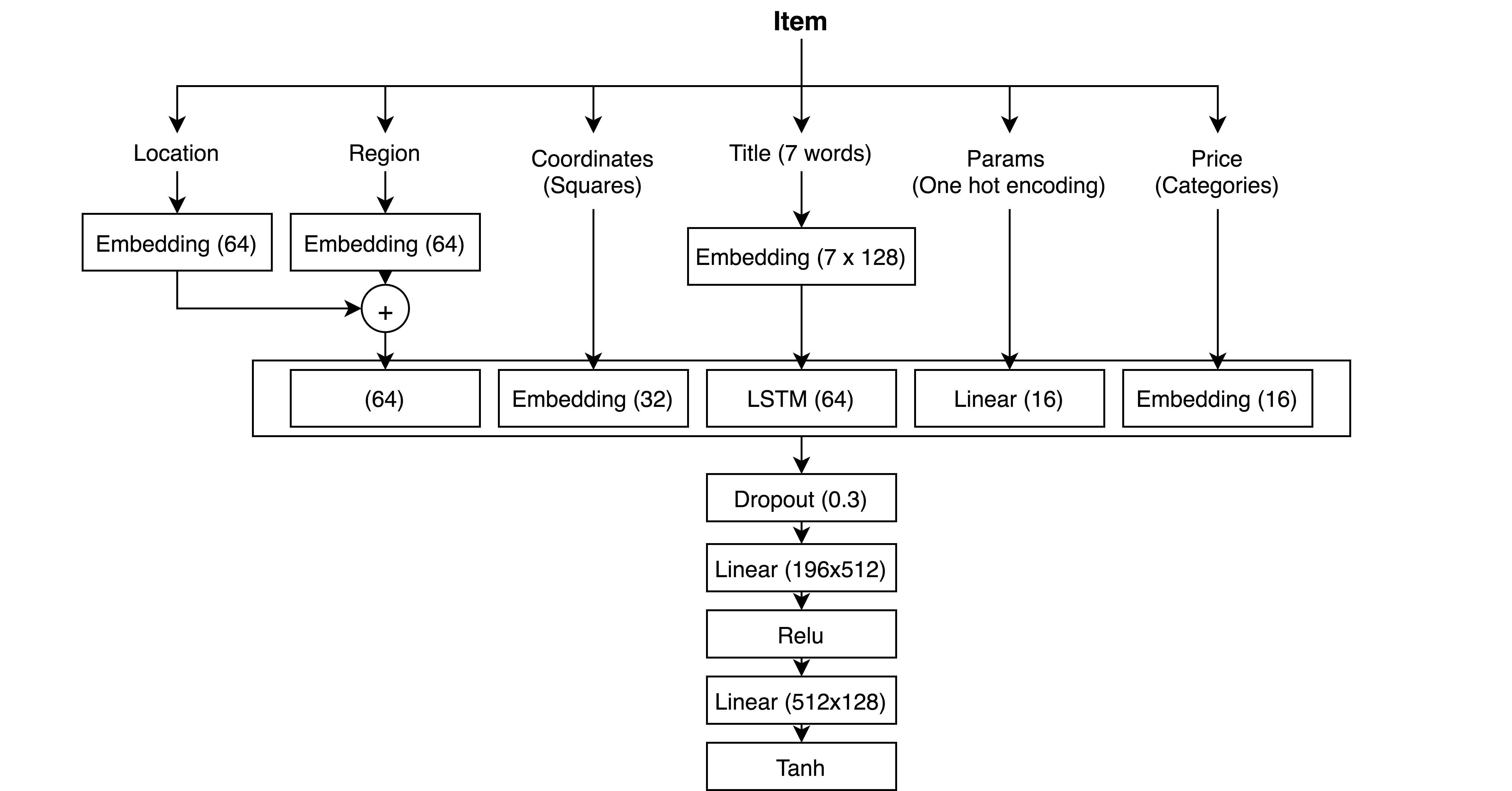
Почти все данные — это категориальные признаки, для которых мы используем embedding слой: регион, локация, координаты (разбиваем на квадраты, и считаем каждый квадрат отдельной категорией) и цена (разбиваем на квантили). Слова из title мы также кодируем и навешиваем embedding слой, а поверх — lstm. Для параметров — one-hot и линейный слой. Затем все конкатенируем и навешиваем пару полносвязных слоев и на выходе — гиперболический тангенс.
Обработка title сейчас, наверное, имеет самый большой потенциал для улучшений. Мы пробовали навешивать на эмбеддинги слов просто полносвязный слой, свёрточные и рекуррентные слои. Последние оказались в сильном выигрыше. Причем чем сложнее, тем лучше — lstm лучше GRU и лучше стандартного рекуррентного слоя. Однако сейчас появились новые архитектуры для работы с текстом, которые стоит попробовать.
Эмбеддинги региона и локации мы складываем. Предполагается, что вектор региона представляет собой общее направление для гео. А вектор локации — это надбавка над вектором региона. Так немного лучше, чем просто конкатенировать векторы. Эмбеддинг координат мы просто конкатенируем — если складывать, получается хуже.
На выходе — гиперболический тангенс. Навесили мы его для того, чтобы получить числа от -1 до 1. Это нужно, чтобы потом умножить на 128, округлить до целого и сохранить в int8 для экономии памяти.
На качество тангенс никак не повлиял. Также, как и округление до int8.
При обучении все данные влезают в память GPU, так как все признаки категориальные и для одного объявления нужно хранить просто около 20 чисел. Таким образом мы не теряем время на копирование данных с CPU на GPU для каждого батча.
Кроме того, при обучении мы не используем id айтема как фичу. Модель генерирует вектор только из контента, и это позволяет долгое время не переобучать модель.
Обучение модели
Обучаем модель, используя пары из выборки для обучения, выбирая для каждого негативные примеры. Вот как это можно описать для одной пары:
Шаг 1. Выбираем случайную пару из датасета.

Шаг 2. Выбираем 4000 негативных примеров (больше — лучше, просто не влезает в память GPU) из всех объявлений. Причём выбираем вероятностно пропорционально квадратному корню из количества контактов, которое было совершенно на эти айтемы в месяц события контакта пары, которую мы достали из датасета.
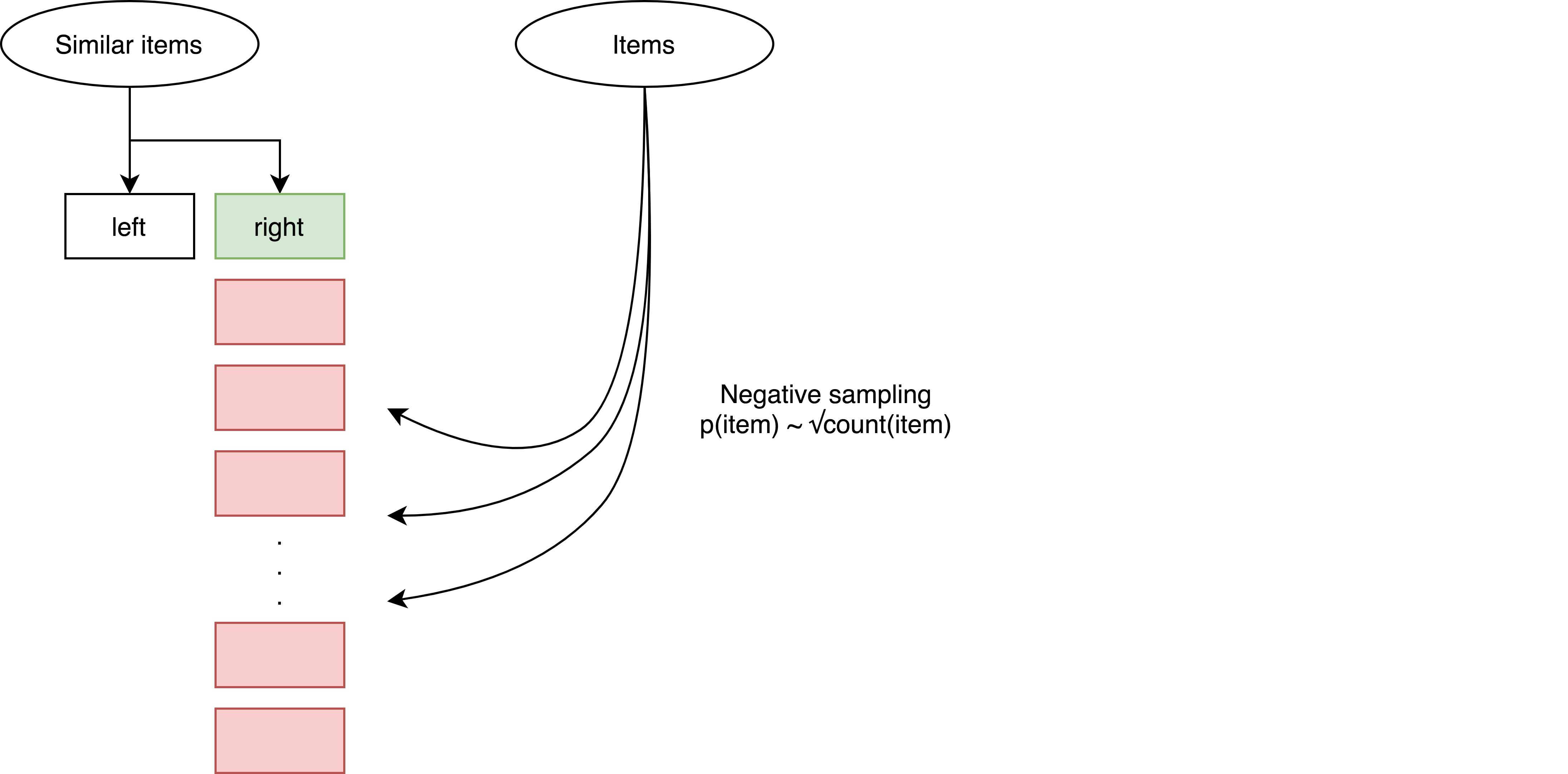
Шаг 3. Считаем скор, полученный произведением левого айтема на правый и негативные примеры. Выбираем 100 негативных с самым большим скором, то есть 100 самых похожих из них.

Шаг 4. Считаем функцию потерь — cross entropy loss — и апдейтим веса.
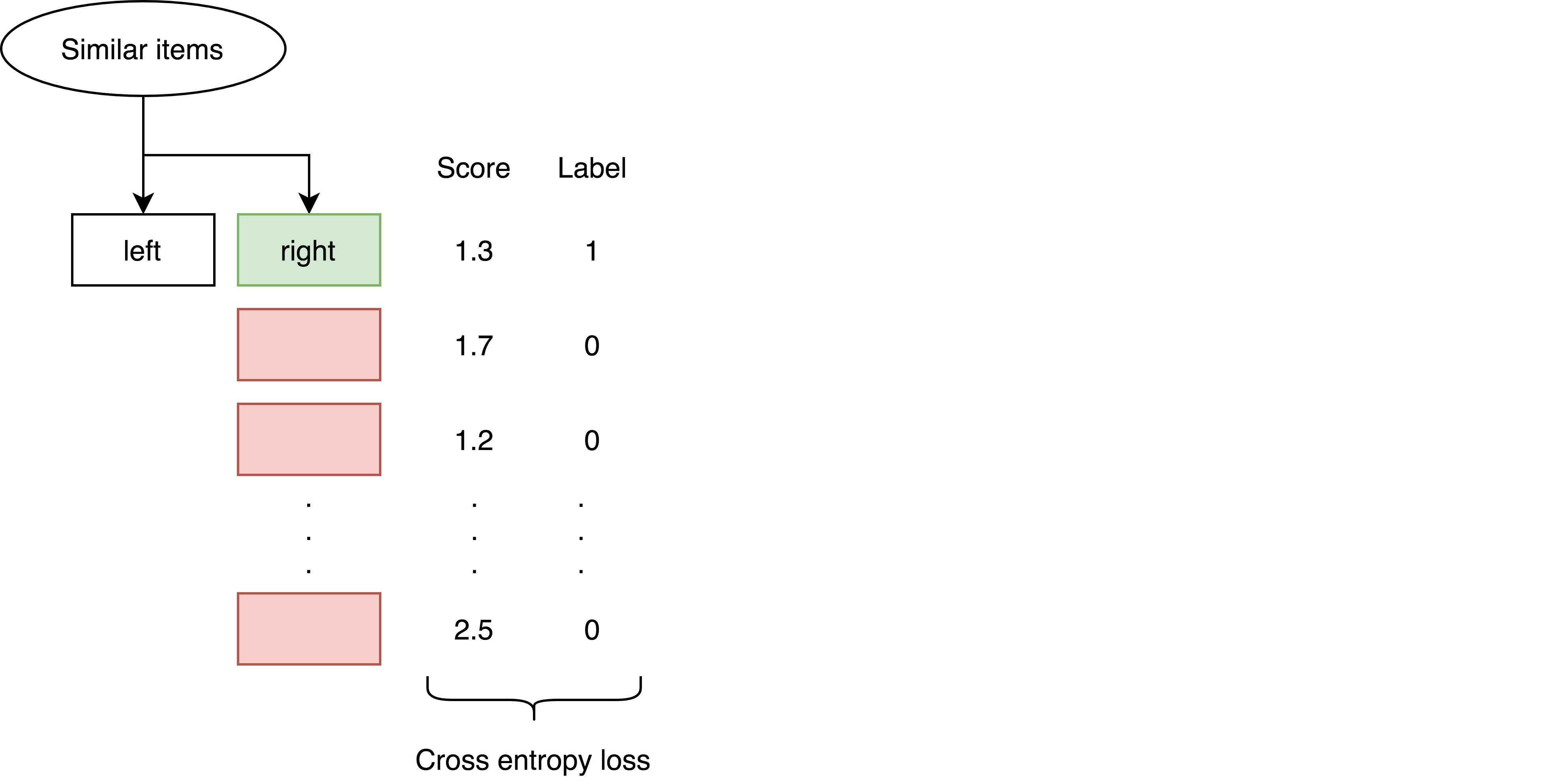
За счёт того, что мы делаем forward на 4001 паре, а backward — на 101, экономим время на обучение, не теряя в качестве.
В процессе обучения через нейроночку было прогнано 500 000 000 (кликстрим) × 4 000 (негативных примеров) × 5 (эпох) = 10 ^ 13 объявлений. Процесс обучения занял 2 недели на 4 x Tesla P40.
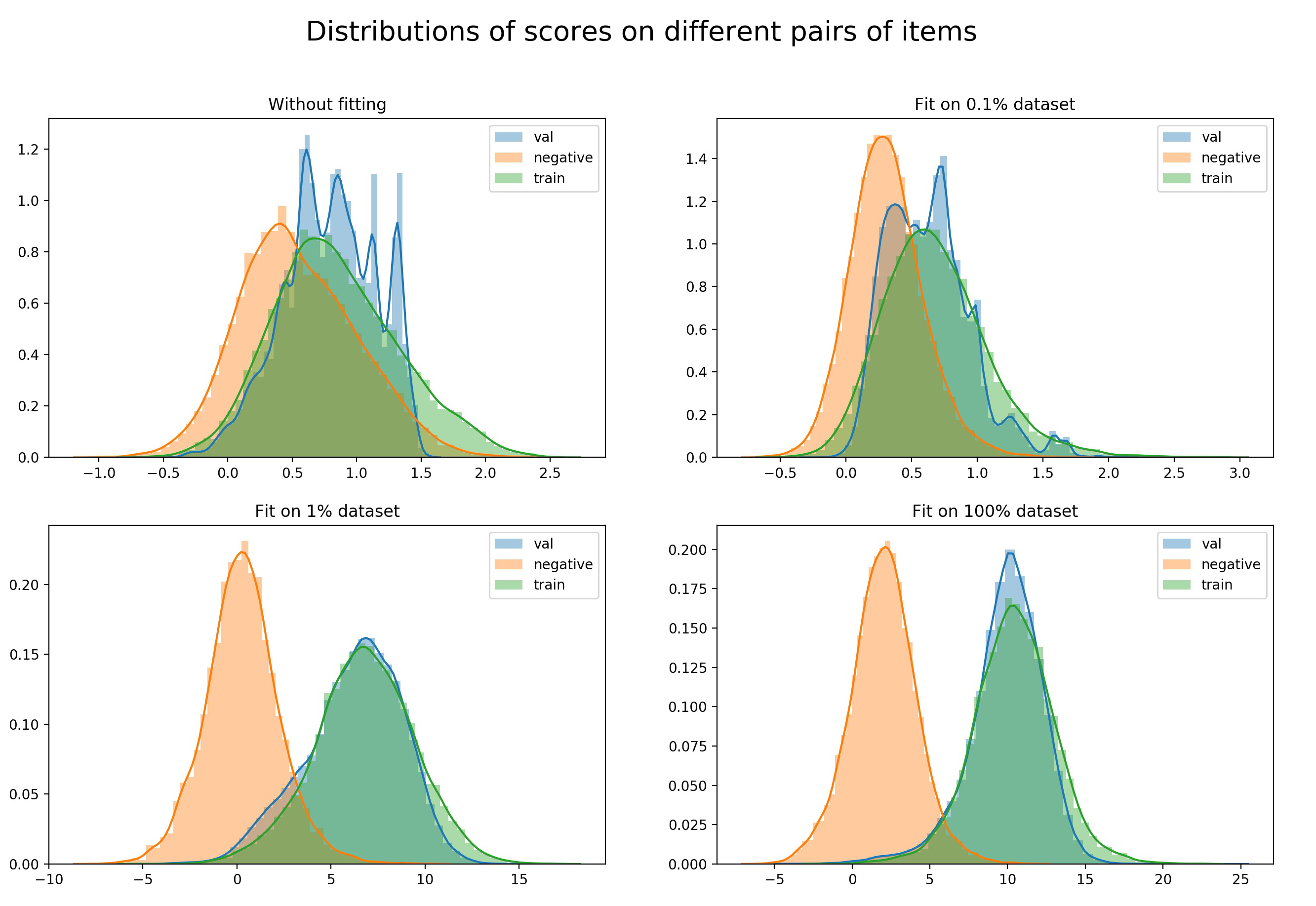
Вот как выглядит изменение распределений позитивных и негативных скоров в процессе обучения:
Валидация
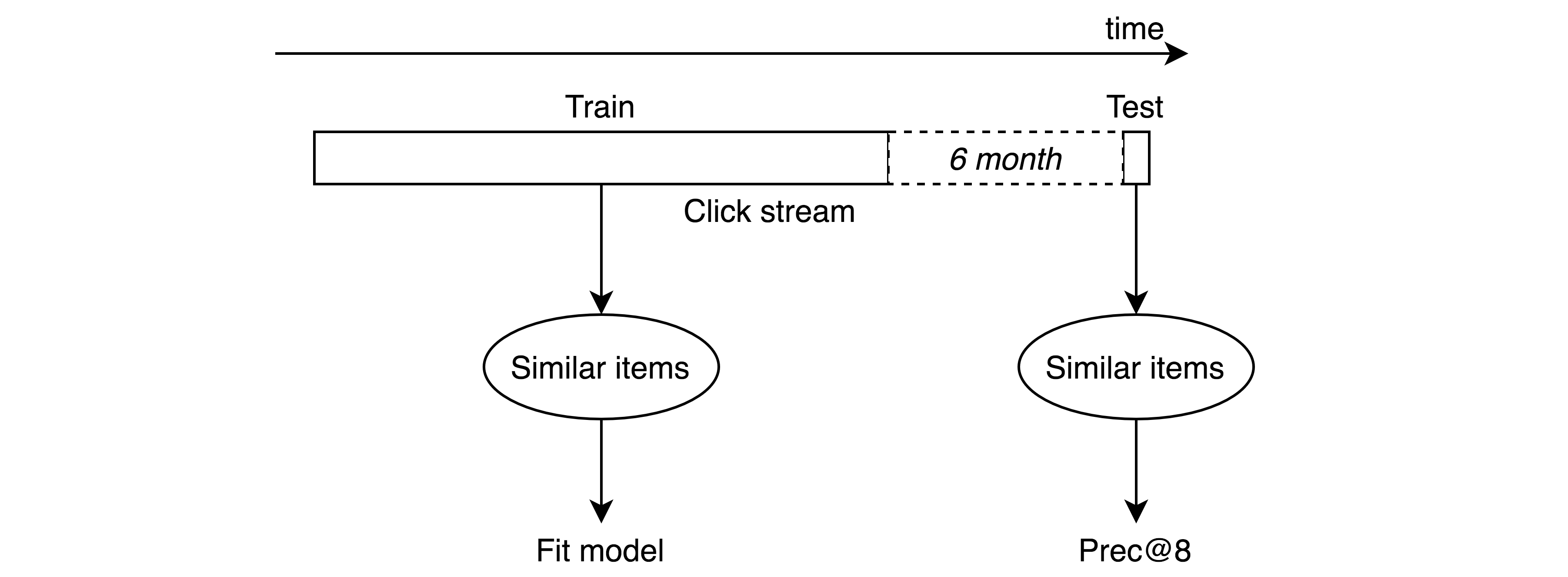
При подборе гиперпараметров мы использовали следующее разбиение: брали последние 7 дней для тестовой выборки, 6 месяцев до этого выкидывали, а всё остальное добавляли в выборку для обучения. Предполагается, что мы будем переобучать модель раз в полгода и поэтому хотим быть уверены, что после этого времени качество будет хорошим. На тестовой выборке считаем prec@8.
Добавление картинки
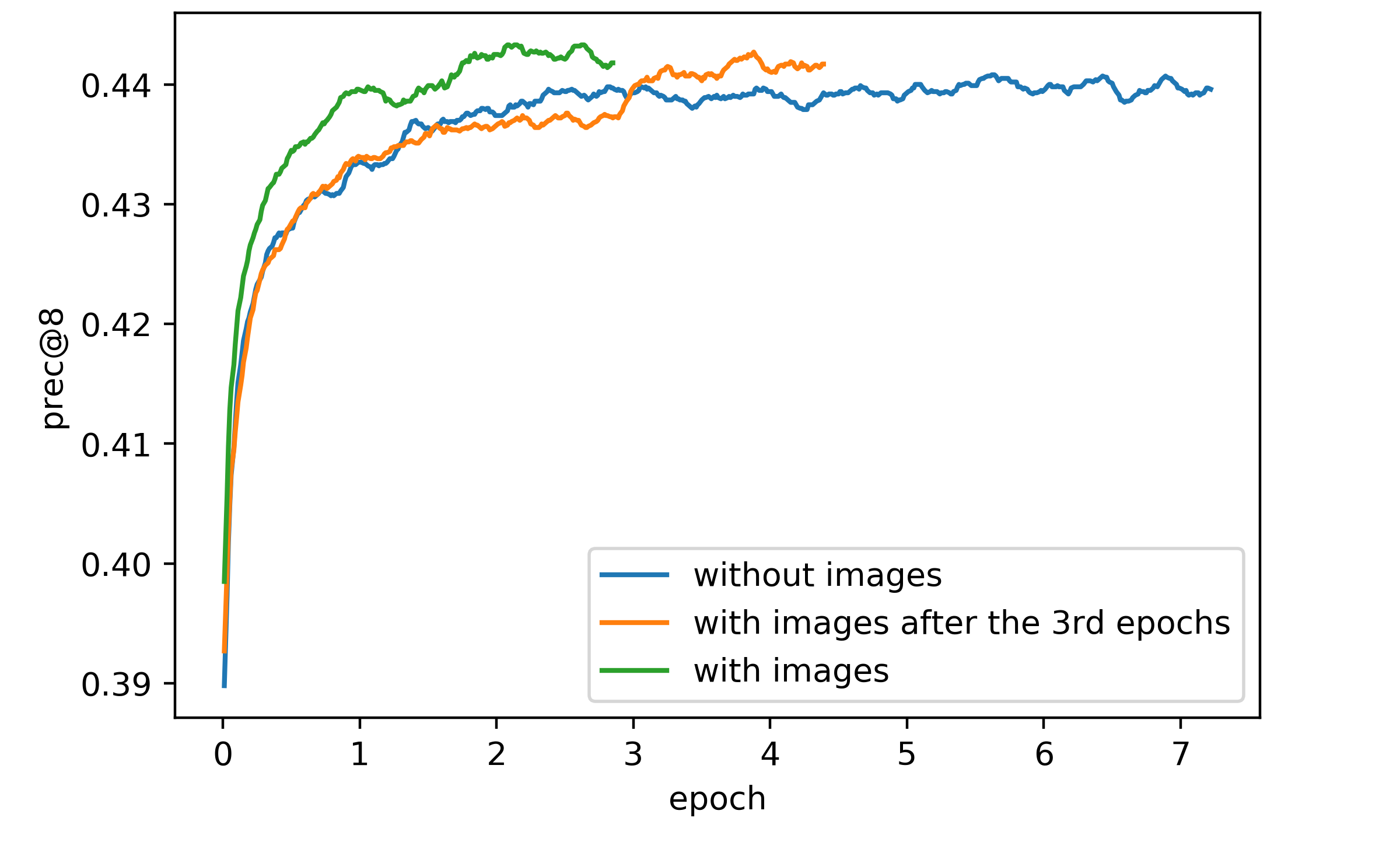
Мы пробовали добавить вектор картинки на вход item2vec в категории «Личные вещи». В качестве вектора использовали предпоследний слой нейронки обученной на AvitoNet. AvitoNet — это датасет, состоящий из объявлений Авито. Нейронка обучалась на предсказании вида товара по картинке. Подробнее про это можно посмотреть на нашем ютуб-канале.
Без вектра картинки модель обучается 3 эпохи в течение 6 часов. В то время как с картинкой — 62 часа. Это связано с тем, что размерность вектора картинки — 2048, поэтому сразу все векторы не влезают в память GPU, а копирование с CPU сильно увеличило время. Пробовали такую схему: обучать как с картинкой, только на вход вместо неё — нулевой вектор, обучить 3 эпохи, а затем уже добавить изображение. Эта идея зашла, таким образом можно сократить время обучения. Однако в итоге получилось, что с картинкой качество улучшается не настолько, чтобы её использовать. Prec@8 увеличился примерно на 0,4%, что слишком мало для того, чтобы заморачиваться.
Примеры рекомендаций
Возьмём объявление из категории «Детская одежда и обувь»:
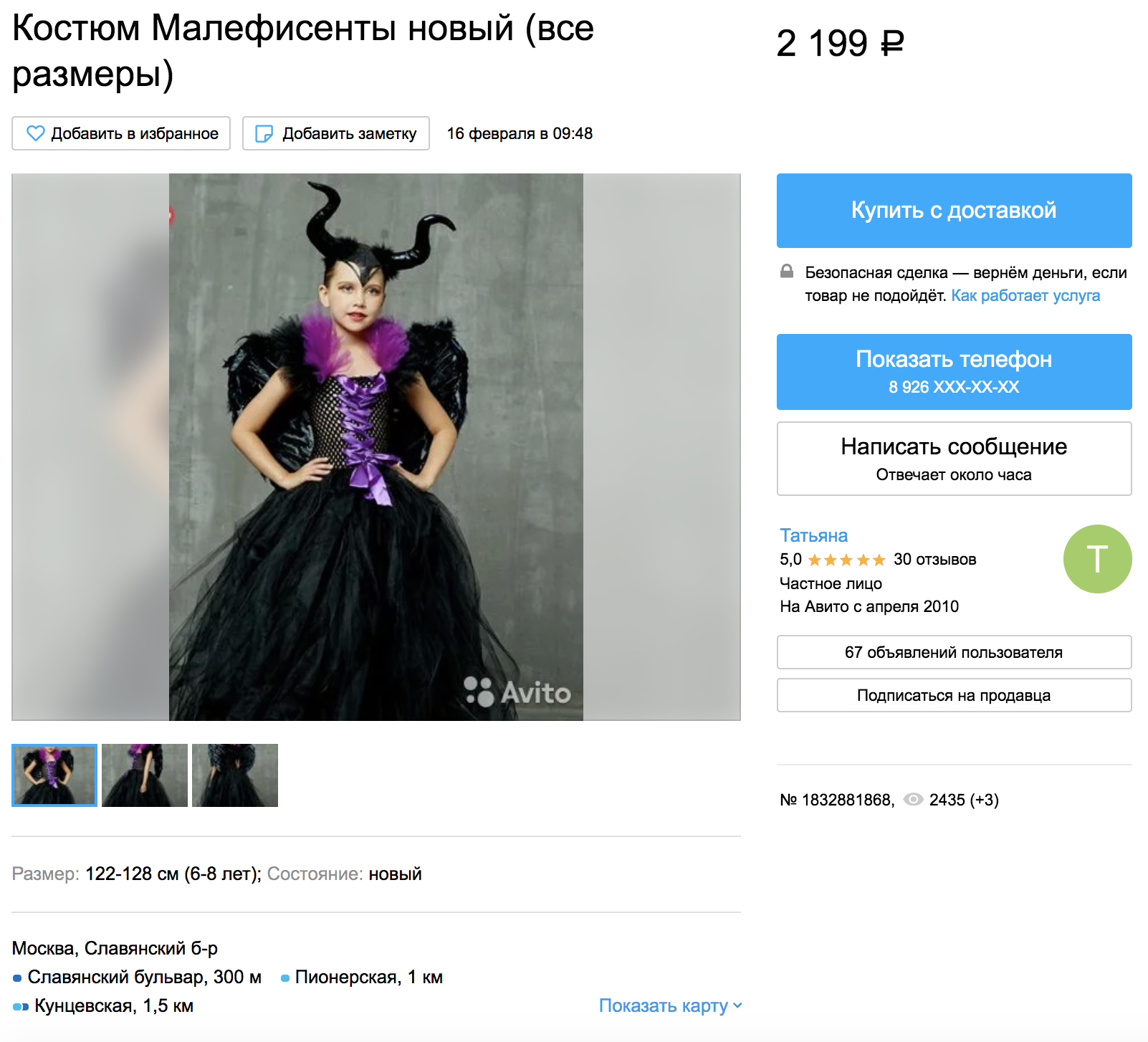
Объявление расположено в микрокатегории «Для девочек/Платья и юбки/122—128 см (6—8 лет)». Вот как будут выглядеть рекомендации по старой модели:
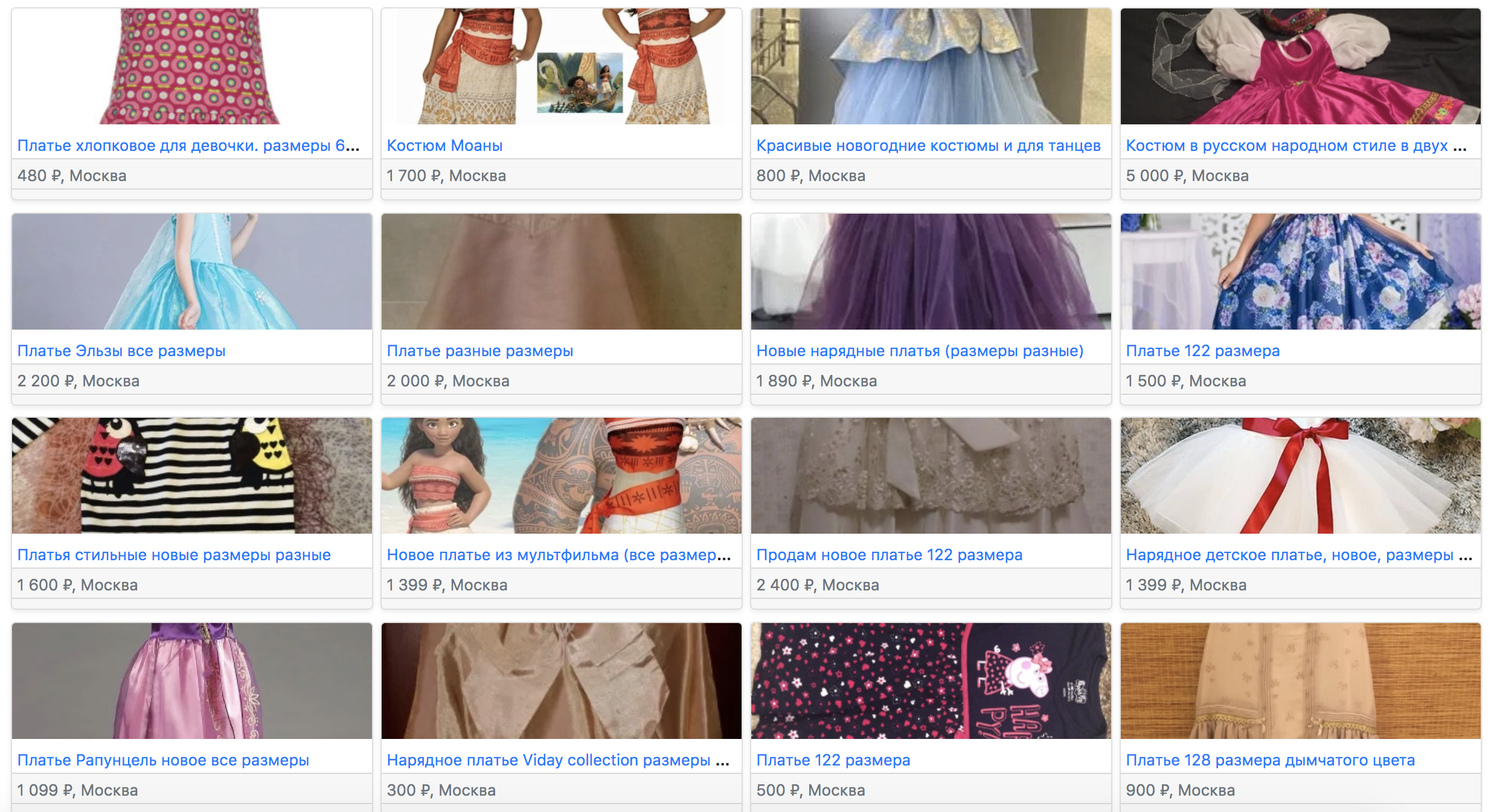
Здесь объявления из той же микрокатегории, где первыми идут варианты, в заголовке которых есть слова «костюм» или «размеры».
По item2vec похожие объявления такие:
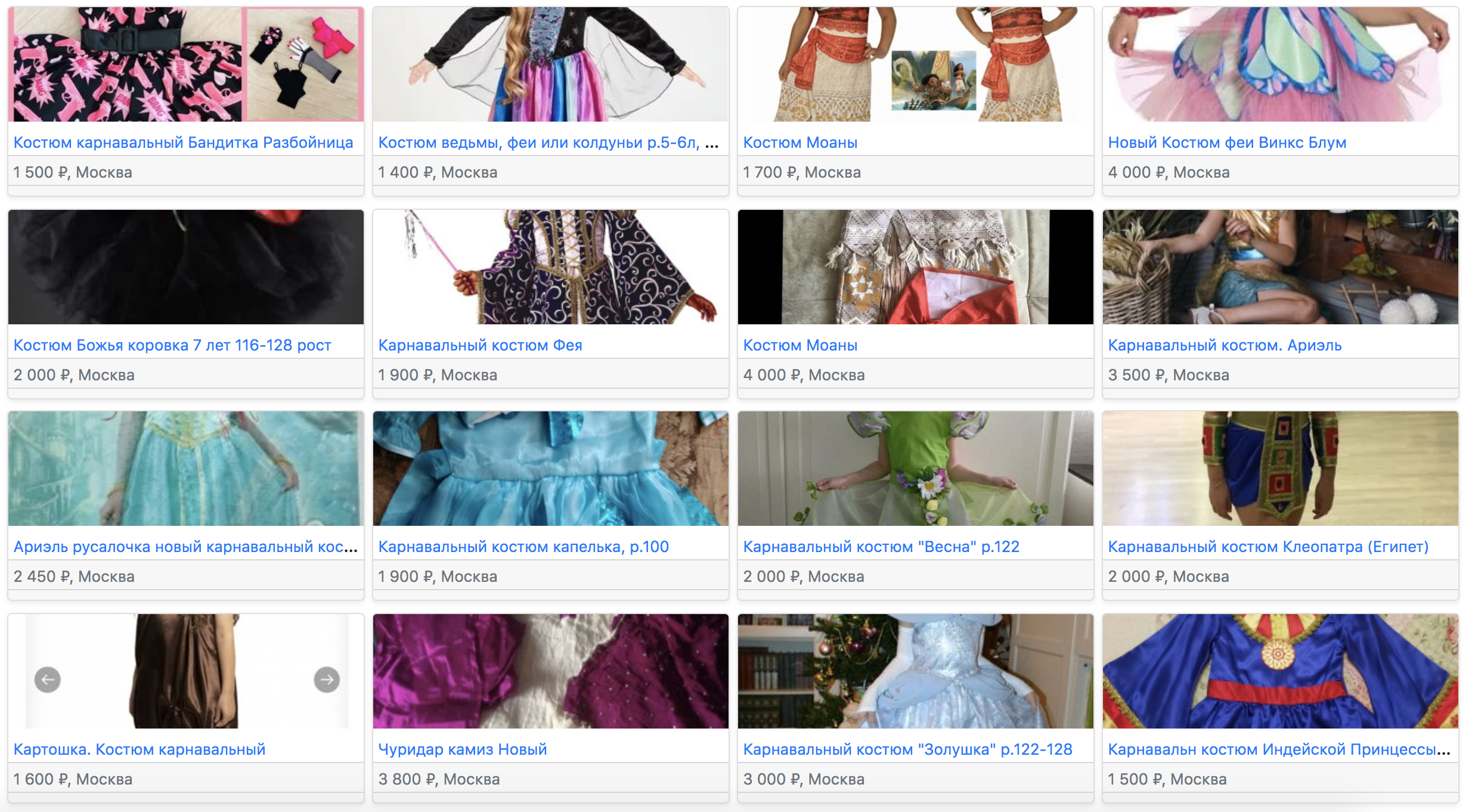
Здесь первым идёт «Костюм карнавальный Бандитка Разбойница». По-видимому, Малефисента как-то синонимирует со словами «бандитка» или «разбойница». На втором, четвёртом и шестом местах идут костюмы, в названии присутствуют слово «фея». Что очень круто, так как Малефисента — фея!
Ещё один пример — «Рога косули» из Новокузнецка.

Среди похожих по item2vec — рога косули и других животных из Кемеровской области, но после них идут чучела животных. Из этого сразу видно, что такие объявления смотрят вместе. Если пойти ещё дальше, в рекомендациях будут «Подарочный набор для шашлыка» и «Охотничьи лыжи».

Инференс
Самым большим вызовом при работе с уже существующей базой векторов является поиск top-n ближайших. Мы для этого используем поисковой движок sphinx. Он позволяет нам перемножать векторы и искать похожие полным перебором с фильтром на категорию, регион и иногда параметры. Сервис отвечает за 200ms (p99) при нагрузке 200K rpm.
Похожие с доставкой
С недавних пор на Авито можно пользоваться доставкой товаров. И объявления с возможностью доставки можно рекомендовать без учета гео-данных. Для этого мы генерируем ещё один вектор по объявлению, используя уже обученную модель, но на вход не подаём гео-фичи — локацию, регион и координаты. Так можно искать похожие без учёта географии.
Блок похожих с доставкой располагается под блоком похожих на карточке товара.
Учёт времени жизни объявлений
При поиске похожих мы хотим учитывать то, как давно объявление размещено на сайте. Сейчас мы используем для этого следующую формулу:
sim(i, j) =
Здесь схожесть объявлений i и j — это скалярное произведение векторов этих объявлений умноженное на коэффициент, зависящий от времени жизни объявления j (t_j = now — start_time_j).
Устроено это таким образом, что новые объявления, но менее похожие, могут быть выше в выдаче, чем старые и более похожие. Влияние времени на спуск старых объявлений в выдаче в каждой категории свое. Коэффициент, регулирующий важность времени жизни объявления в категории c — a_c. Например, в услугах этот коэффициент равен 0, и в итоге время жизни никак не влияет на выдачу. Это логично, так как большинство объявлений пользователей в этой категории — регулярные. А в бытовой электронике всё наоборот. Время жизни сильно влияет на результат, ведь если товар давно не покупают, то объявление непривлекательное или с ним что-то не так. Это сигнал нам, что товар не стоит рекомендовать.
Результаты
Улучшая модель похожих, мы делаем лучше наши персональные рекомендации.
Сейчас лента персональных рекомендаций — это смешение двух моделей, одна из которых берет похожие на те, что пользователь смотрел, и ранжирует их.
Переход на item2vec увеличил на 30% контакты с похожих, на 20% контакты с ленты персональных рекомендаций и значимо прирастил байеров на Авито.
