Как мы искали компромисс между точностью и полнотой в конкретной задаче ML

Я расскажу о практическом примере того, как мы формулировали требования к задаче машинного обучения и выбирали точку на кривой точность/полнота. Разрабатывая систему автоматической модерации контента, мы столкнулись с проблемой выбора компромисса между точностью и полнотой, и решили ее с помощью несложного, но крайне полезного эксперимента по сбору асессорских оценок и вычисления их согласованности.
Мы в HeadHunter используем машинное обучение для создания пользовательских сервисов. ML — это «модно, стильно, молодежно…», но, в конце концов, это лишь один из возможных инструментов решения бизнес-задач, и этим инструментом нужно правильно пользоваться.
Постановка задачи
Если предельно упрощать, то разработка сервиса — это инвестиции денег компании. А разработанный сервис должен приносить прибыль (возможно, косвенно — например, увеличивая лояльность пользователей). Разработчики же моделей машинного обучения, как вы понимаете, оценивают качество своей работы несколько в других терминах (например, accuracy, ROC-AUC и так далее). Соответственно, нужно каким-то образом переводить требования бизнеса, например, в требования к качеству моделей. Это позволяет в том числе не увлекаться улучшением модели там, где «не надо». То есть с точки зрения бухгалтерии — меньше инвестировать, а с точки зрения разработки продукта — делать то, что действительно полезно пользователям. На одной конкретной задаче я расскажу о том, как довольно простым образом мы устанавливали требования к качеству модели.
Одна из частей нашего бизнеса заключается в том, что мы предоставляем пользователям-соискателям набор сервисов для создания электронного резюме, а пользователям-работодателям — удобные (в большинстве своем платные) способы работы с этими резюме. В связи с этим нам крайне важно обеспечивать высокое качество базы резюме именно с точки зрения восприятия менеджерами по персоналу. Например, в базе не просто не должно быть спама, но и всегда должно быть указано последнее место работы. Поэтому у нас есть специальные модераторы, которые проверяют качество каждого резюме. Количество новых резюме непрерывно растет (что, само по себе, нас очень радует), но одновременно растет нагрузка на модераторов. У нас возникла простая идея: накоплены исторические данные, давайте же обучим модель, которая сможет отличать резюме, допустимые к публикации, от резюме, требующих доработки. На всякий случай поясню, что, если резюме «требует доработки», у пользователя ограничены возможности использования данного резюме, он видит причину этого и может все поправить.
Я не буду сейчас описывать увлекательный процесс сбора исходных данных и построения модели. Возможно, те коллеги, кто это делал, рано или поздно поделятся своим опытом. Как бы то ни было, в итоге у нас получилась модель с таким качеством:
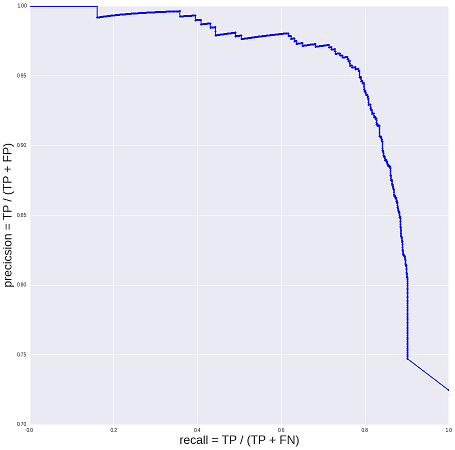
По вертикальной оси отложена точность (precision), или доля верно принимаемых моделью резюме. По горизонтальной оси — соответствующая полнота (recall), или доля принимаемых моделью резюме от общего числа «допустимых к публикации» резюме. Все, что не принимается моделью, принимается людьми. У бизнеса есть две противоположные цели: хорошая база (наименьшая доля «недостаточно хороших» резюме) и стоимость модерации (как можно больше резюме принимать автоматически, при этом чем меньше стоимость разработки — тем лучше).
Хорошая или плохая модель получилась? Нужно ли ее улучшать? А если не нужно, то какой порог (threshold), то есть какую точку на кривой выбрать: какой компромисс между точностью и полнотой устраивает бизнес? Сначала я отвечал на этот вопрос довольно туманными построениями в духе «хотим 98% точности, а 40% полноты — казалось бы, вполне неплохо». Обоснование для подобных «продуктовых требований», конечно, существовало, но настолько зыбкое, что недостойно помещения в печать. И первая версия модели вышла именно в таком виде.
Эксперимент с асессорами
Все довольны и счастливы, и дальше возникает вопрос:, а давайте автоматическая система будет принимать еще больше резюме! Очевидно, этого можно достичь двумя способами: улучшить модель, или, например, выбрать другую точку на вышеприведенной кривой (ухудшить точность в угоду полноте). Что же мы сделали для того, чтобы более осознанным образом сформулировать продуктовые требования?
Мы предположили, что на самом деле люди (модераторы) тоже могут ошибаться, и провели эксперимент. Четверым случайным модераторам было предложено разметить (независимо друг от друга) одну и ту же выборку резюме на тестовом стенде. При этом был полностью воспроизведен рабочий процесс (эксперимент ничем не отличался от обычного рабочего дня). В формировании выборки же была хитрость. Для каждого модератора мы взяли N случайных резюме, уже им обработанных (то есть итоговый размер выборки получился 4N).
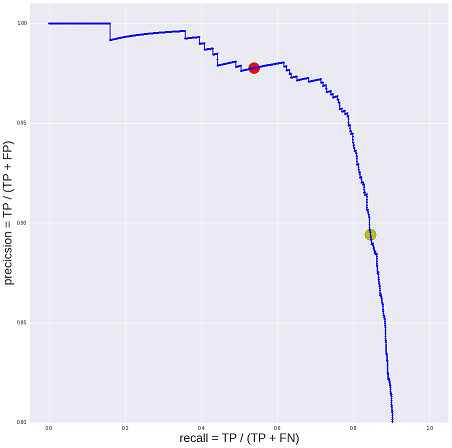
Итак, для каждого резюме мы собрали 4 независимых решения модераторов (0 или 1), решение модели (вещественное число от 0 до 1) и исходное решение одного из этих четверых модераторов (опять же 0 или 1). Первое, что можно сделать — посчитать среднюю «самосогласованность» решений модераторов (она получилась около 90%). Дальше можно более точно оценить «качество» резюме (оценку «опубликовать» или «не публиковать»), например, методом мнения большинства (majority vote). Наши предположения следующие: у нас есть «исходная оценка модератора» и «исходная оценка робота» плюс три оценки независимых модераторов. По трем оценкам всегда будет существовать мнение большинства (если бы оценок было четыре, то при голосовании 2:2 можно было бы выбирать решение случайным образом). В результате мы можем оценить точность «среднего модератора» — она опять же оказывается около 90%. Наносим точку на нашу кривую и видим, что модель обеспечит такую же ожидаемую точность при полноте более 80% (в итоге мы стали автоматически обрабатывать в 2 раза больше резюме при минимальных затратах).
Выводы и спойлер
На самом деле, пока мы думали над тем, как построить процесс приемки качества системы автоматической модерации, мы натолкнулись еще на несколько камней, которые я попробую описать в следующий раз. Пока же на достаточно простом примере, надеюсь, мне удалось проиллюстрировать пользу асессорской разметки и простоту построения таких экспериментов, даже если у вас под рукой нет «Яндекс.Толоки», а также то, насколько неожиданными могут оказаться результаты. В данном конкретном случае мы выяснили, что для решения бизнес-задачи вполне достаточно точности 90%, то есть до того, как улучшать модель, стоит потратить некоторое время на изучение реальных бизнес-процессов.
И в заключение хотел бы выразить свою признательность Роману Поборчему p0b0rchy за консультации нашей команды в ходе работы.
Что почитать:
- Ensuring quality in crowdsourced search relevance evaluation: The effects of training question distribution — пример аналогичной постановки задачи
- Modeling Amazon Mechanical Turk — про систему сбора пользовательских оценок от Amazon
- Maximum Likelihood Estimation of Observer Error-Rates Using the EM algorithm — про итеративные алгоритмы предсказания истинной оценки (в частности, алгоритм имени авторов — алгоритм Dawide-Skene)
