Как мы делали свой Typeform с тотализатором, но без куртизанок, а ещё случайно изобрели велосипед

Всем привет. Меня зовут Дима, и пока мой конструктор опросников не захватил рынок, лишив три сотни испанцев из Typeform работы, средств к существованию и крыши над головой, придется самому немного рассказать о том, что такое WebAsk, почему я решил создать именно такой проект и что тут можно делать уже сейчас. Настраивайтесь на технический лонгрид с моими лирическими комментариями.
История создания
Любой уважающий себя программист должен построить с нуля звездный репозиторий, посадить зрение и вырастить пет-проект. И если со зрением у меня пока всё в порядке, то над остальными пунктами я давно работаю.
По сути, наш проект это Typeform, каким я всегда его хотел видеть, без раздражающих минусов и по доступной цене.
Что внутри
Что было проще жить, проект организован довольно незамысловато: у нас есть три git-репозитория — backend, frontend и renderer. Таким образом, разработка API для конструктора и SPA на React происходит параллельно и независимо друг от друга.
В основу бэкэнда лег Laravel. Почему именно он? Во-первых, требовалась большая скорость разработки и внедрение идей в кратчайшие сроки. Ха-ха, говорю я сейчас, спустя полтора года, но, о выборе не жалею. Во-вторых, проекту необходимы стабильность и надежность, чтобы его можно было с легкостью поддерживать, развивать и масштабировать в соответствии с потребностями пользователей.
Разрабатывать что-то с нуля и экспериментировать в нашем случае было глупо, поскольку из коробки Laravel содержит всё необходимое для разработки: встроенный orm, кэширование, защиту от sql-инъекций и csrf, маршрутизацию, сессии, логирование, миграции и кучу всего остального.
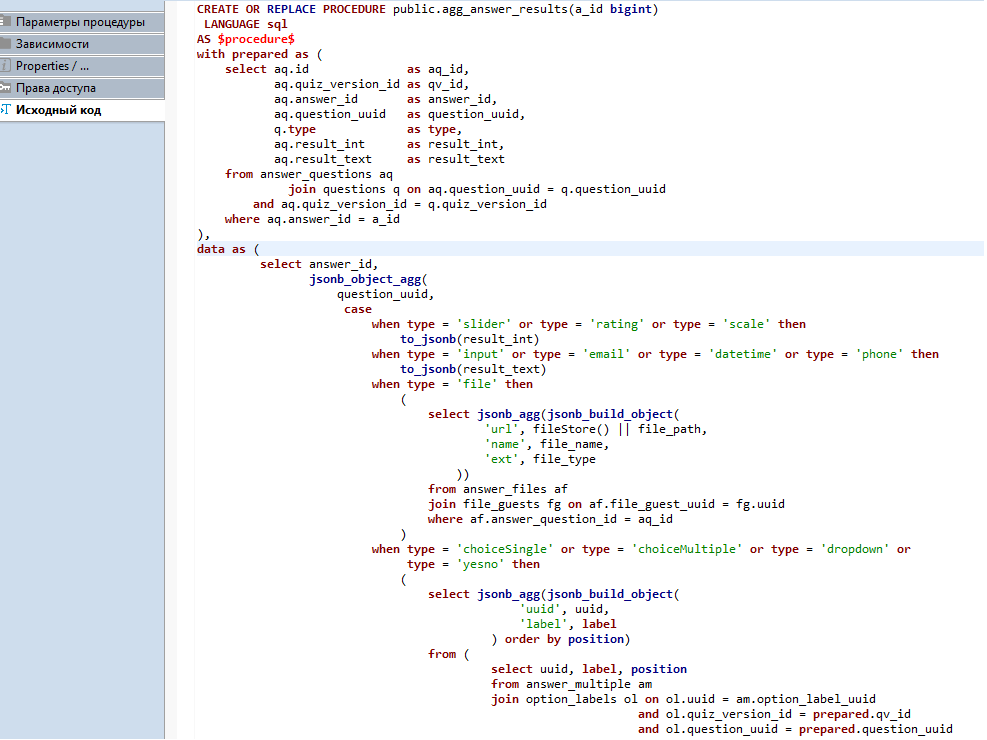
В качестве системы хранения данных мы используем PostgreSQL. Благодаря объектно-реляционной модели, у PostgreSQL есть ряд преимуществ по сравнению с другими SQL-базами. В первую очередь, здесь есть гибкая поддержка json и jsonb типов данных, что было крайне важным, поскольку для хранения некоторых данных используется schema-less.

Например, для ответов или списка виджетов опроса. Кроме того, у PostgreSQL есть и другие приятные полезности вроде uuid, транзакции, ссылочной целостности, пользовательских типов и т.д.
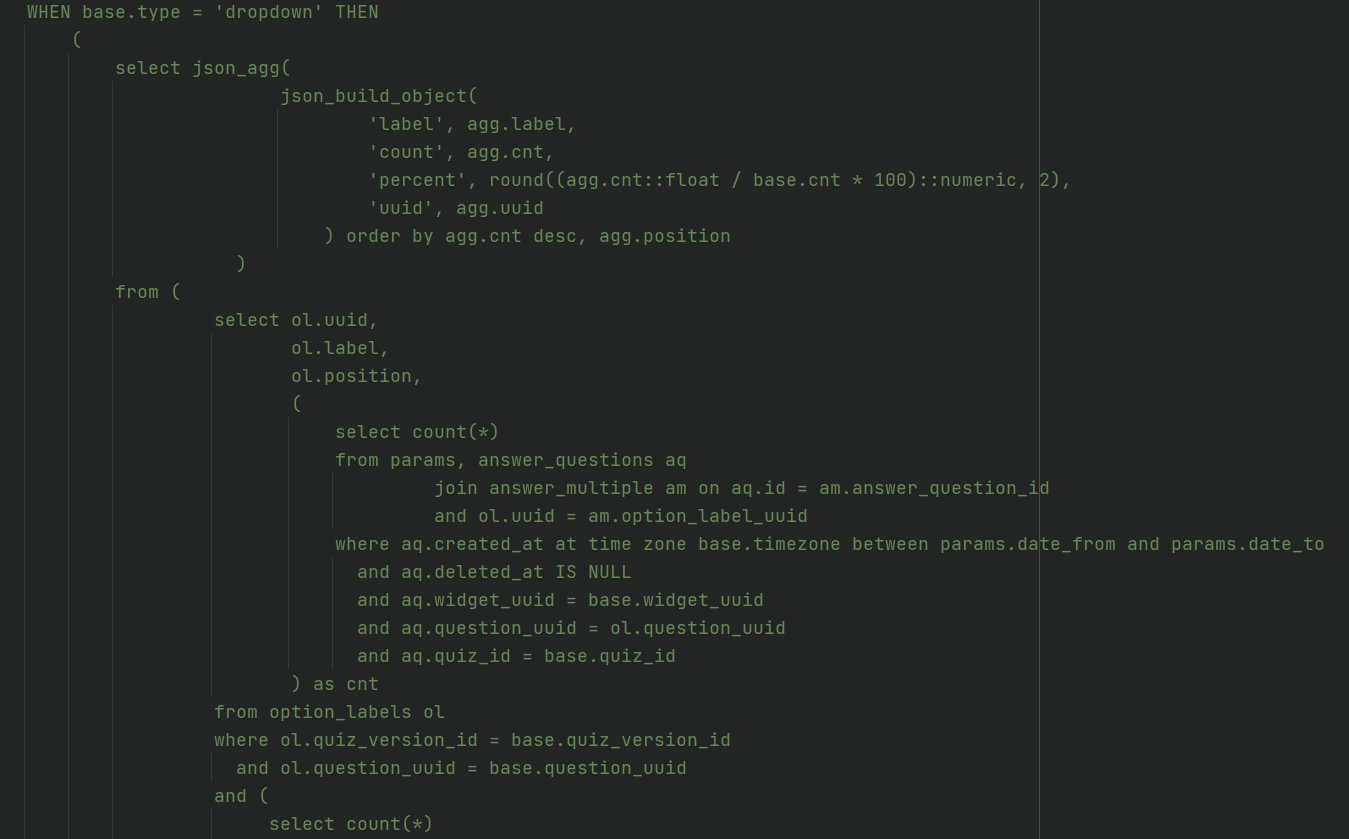
Значительная часть логики конструктора перенесена в базу данных в виде хранимых процедур, триггеров и генерируемых полей. В более-менее сложных моментах ORM не используется, отправляются только прямые запросы к БД, чтобы увеличить производительность.
Как и в любом крупном проекте, в WebAsk остро встал вопрос о том, как хранить большое количество файлов пользователей. У нас это различные медиа: изображения, видео, документы и прочие файлы, которые загружаются в конструкторе, а вдобавок могут отправляться вместе с ответами опроса. Появилась необходимость продумать организацию хранения файлов. Мы сделали выбор в пользу Yandex Storage. Был собран мини прокси-сервер на Node.js (поддерживается запущенным с помощью менеджера процессов pm2), который в сочетании с nginx получает файлы из хранилища и имитирует расположение на доменах WebAsk.
Чтобы расширить возможности платформы, был разработан раздел интеграций, где пользователь может подключить сторонние сервисы к своему опросу. Можно, например, подключить аналитику для сбора детальной статистики респондентов, отправлять ответы прямиком в Телеграм или даже в Google Таблицы. Для чего-то нестандартного можно настроить отправку ответов на вебхуки.
Отправка ответов респондента не происходит сразу же, а построена на базе очередей. Архитектура интеграций представлена паттерном Factory, облегчающим нам жизнь. Все интеграции поделены на классы, реализующие единый интерфейс, где определены методы для активации, деактивации, удаления, получения и сохранения настроек.
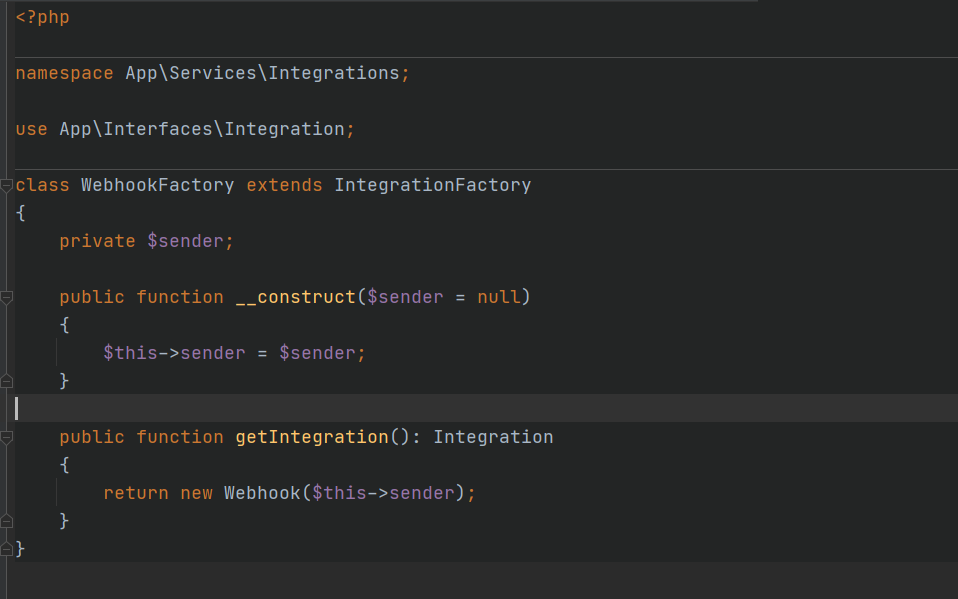
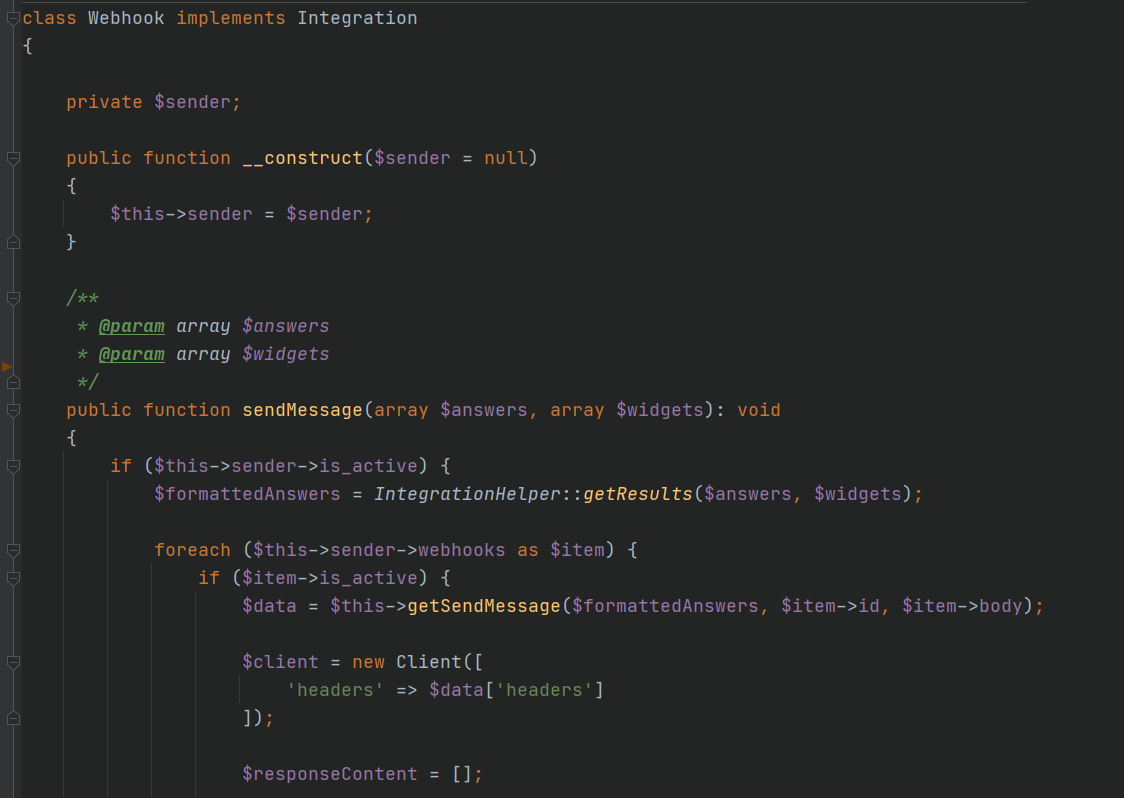
Логики отправки нотификаций тоже разнесены по разным классам, потому что отправляемое сообщение формируется для каждой интеграции по-разному. К примеру, для Телеграм это текстовое сообщение с набором разрешенных тегов, для вебхуков это json, для email-нотификаций — полноценное html-сообщение.
Помимо стандартного логирования Laravel для отладки WebAsk использует Telescope. Это приятный удобный интерфейс для отслеживания в режиме реального времени запросов к БД, заданий в очереди, уведомлений, запланированных задач и многого другого
Его величество хаос

Тут цветочки заканчиваются, начинаются ягодки! Эта часть статьи почти целиком переведена на русский с матерного, потому что рендер колючий.
Изначально у нас был один файл и 5000 строк кода в процедурном стиле, никакой сборки или линтера. Была лишь минификация при билде, однако весь код был написан при помощи var и прочего старого барахла, так как у нас не было транспайлера, чтобы превратить всё это в доступный всем старым браузерам код. Всё это вкупе с тем огромным файлом, в котором был весь код проекта, создавало определенные сложности, особенно на этапе дебага.
С каждым появившимся багом приходилось очень долго разбираться, так как весь код напоминал чан со спагетти, где ты просто по 15 минут скроллишь от одной функции к другой, чтобы понять, в чем проблема. Вся логика работы приложения отталкивалась от состояний и классов элементов в DOM, а не строилась на актуальном состоянии данных. Первым делом мы настроили Webpack для нормальной разработки и преобразования файлов. Постарались наш огромный JS-файл разбить на определенные сущности так, чтобы каждая из них занималась именно тем, что ей предписали, а не всем подряд. Изменили принцип работы приложения — именно данные стали нашей отправной точкой, от которой уже отталкивалась наша view-шка, а не наоборот. Это значительно облегчило фиксинг багов, больше не нужно было ходить по тысяче функций и пытаться понять, какая же из них сломала тот или иной элемент, или почему один класс, который повесили на div где-нибудь в совершенно далеком месте, ломает логику работы приложения.
Теперь о фронтенде. Как уже говорил ранее, наше приложение разделено на две составляющие: это конструктор, где мы создаем и модифицируем опрос, и рендерер, где мы отображаем и проходим опрос.
Технологии, при помощи которых реализованы эти сервисы, разительно отличаются. Если говорить о конструкторе, то это современный стек React/Redux/Redux-Saga. Кто-то может сказать, что Redux это уже не так уж и современно, но для нашего приложения Redux со всей своей простотой, прозрачностью, а главное своими классными девтулзами подошел просто идеально. В качестве middleware выбор пал на Redux/Saga.
Всё общение с сервером посредством Rest- запросов мы старались производить именно из саг, оставив в компонентах лишь логику представлений, стараясь максимально освободить их от бизнес-логики.
С чем же мы имели дело во время разработки конструктора?
Как и в каждой песочнице, мы реализовали автосохранение опроса. При изменении каких-либо параметров наша сага реагирует и отправляет на сервер ваши данные. Главная проблема такого автосохранения в том, что надо передавать множество данных, поэтому данный процесс был максимально подвергнут мемоизации и обернут в дебаунс-декоратор. В будущем хотим иначе реализовать этот процесс, исключив нынешние отрицательные моменты, но это уже совсем другая история.
Учитывая то, что наш опрос имеет множество настроек, виджетов (которые тоже, к слову, имеют множество настроек), а также других данных, мы не могли отказать себе в удовольствии сделать главные разделы ленивыми (спасибо Webpack). Тем самым сильно упростили себе жизнь в плане ожидания/получения данных, которые на самом деле могут даже не понадобиться юзеру.
Теперь хотелось бы рассказать о некоторых интересных фичах, которые мы реализовали.
Главным камнем преткновения здесь снова стало то, что в конструкторе ооочень много данных, которые необходимо в удобном виде хранить, к тому же формат таких данных в конструкторе и в рендере не может быть одинаковым. В итоге в конструкторе мы использовали удобный для нас формат данных с разделением условий на группы условий, на текущие для нынешнего виджета, на модицируемые и так далее, а при сохранении условий мы просто перегоняли формат в удобный для рендера. Не путать с автосохранением — сохранение условий происходит по кнопке, то есть значительно реже.
Есть у нас также такие разделы как дизайн и выбор мультимедиа, где мы напрямую взаимодействуем с рендером из конструктора. Чтобы понимать, что к чему стоит ещё и рассказать немного про рендерер.
Рендерер — это сервис, построенный из таких технологий как Vanilla JS, jQuery, Blade для серверного рендеринга и Mobx (об этом чуть позже). Напрямую эти два сервиса взаимодействовали не так часто, поэтому мы решили разделить их, а в случае их общего взаимодействия пользовались iframe. То есть, мы просто вставляли наш рендерер в iframe внутри конструктора и отправляли определенные postMessage внутрь него для каких-то модификаций. Так как общение всегда было однонаправленным — то есть команды идут с конструктора на рендерер, исключая обратное направление, такой подход показался нам достаточно простым и действенным, а главное, наши проекты оставались минимально связанными друг с другом какой-либо логикой.
Раз уж начали говорить про взаимодействие с рендерером, давайте остановимся на нем поподробнее. Как в этот классический список затесался Mobx, учитывая, что в основном он используется именно в связке с React, которого у нас не было?
Мы много думали над тем, как реализовать переключение виджетов один за другим «автоматическим путем», ведь при каждом выборе ответа, снятии или изменении глобального хранилища ответов нам в большинстве случаев надо было автоматически скроллить к следующему виджету. Примерно в половине случаев авто-скролл блокируется, так как есть множество факторов, которые на это влияют.
Тут-то мы подумали о реактивности и о том, как классно было-бы всего лишь менять данные, а наша вьюшка тем временем бы просто правильно реагировала на эти изменения. Решили попробовать Mobx в качестве реактивного обзервера, потому что он отлично закрывал все наши потребности:
он быстрый
сравнительно легкий по весу
у него удобный интерфейс даже без React-окружения
Эксперимент показался нам удачным, поэтому для нашей реактивности, которой нам надо было относительно немного, мы начали использовать Mobx и пока ещё ни разу не пожалели. Он начал разруливать практически все автоматические скроллинги после ответов на вопросы.
А вот ещё одна офигительная история, уже точно почти всё! С одним из обновлений мы сделали каждый виджет единственно-обозримым по всей высоте монитора. При скролле вниз или вверх надо было чекать, может ли юзер идти дальше (зависит от многих условий, — например, обязательный вопрос или нет, есть ли ответ на вопрос или нет). Ещё добавилась логика переходов между виджетами в зависимости от ответа респондента (проще говоря, логические ветвления). Самым неочевидным и сложным в этом деле было научиться правильно определять, как каждый юзер скроллит страницу. Ведь могут быть большие виджеты, внутри которых возможен нативный скролл, и тогда только при достижении окончательного верха/низа блока нужно уже переходить к другому виджету. Я уж молчу о том, что разные мыши, тачпады, устройства по-разному генерируют на события скролла и прокрутки.
Чтобы как-то побороть всю эту дичь, мы воспользовались простым, но действенным хаком, который считает время между повторяющимися событиями и в зависимости от этого сообщает нам о том, какое это событие — инерционно созданное мышью или реальное событие, созданное юзером.
Немного про mentions
Мы обновили slate.js, чтобы юзать такие фичи как mentions и link.
Процесс миграции был в целом нормальный, мы перескочили с классов на функциональные компоненты и переписали всё на современный лад (хуки-хуюки и вот это всё). С обратной совместимостью никаких проблем не возникло, то есть наши данные, сохраненные на сервер ещё с помощью старого slate, без проблем распарсились новой версией редактора.
Прикольной фичей стала возможность ссылаться на компоненты, стоящие выше по порядку. То есть прямо в тайтле вы можете выбрать один из вышестоящих виджетов, тем самым добавив ответ на его вопрос прямо себе в заголовок. Чтобы было понятнее: сначала ты спрашиваешь имя респондента, а затем юзаешь его имя далее в других виджетах.
Хочется, чтобы красиво, а чтобы некрасиво — не хочется
Ещё одно неочевидное для нас решение, с которыми пришлось столкнуться в разработке.
Начну с того, что каждый вопрос мы обернули в красивый тег
Свайп один, а действий несколько:
если вопрос высокий, добраться до конца вопроса;
если мы уже в конце, и пройдена валидация, нужно плавно перейти на следующий вопрос.
В js нет события swipe, поэтому мы положились на привычный scroll.
На мобильных устройствах это событие зависит от силы свайпа и долго угасает. Таким образом, если виджет высокий, а мы хотим остановить свайп в конце вопроса, приходится после каждого scroll возвращать пользователя в конец текущего вопроса. На старых девайсах скачки формы обеспечены.
Провели брейншторм, порисовали фломастерами на доске и пришли к другому решению: чтобы ничего не скакало, скролл должен упираться в конец блока.

Каждый вопрос должен быть развернут на весь экран. Когда контента будет много — сможем скроллить внутри
По аналогии работает возвращение к предыдущему вопросу. Пока такое решение нам нравится.
Инсайд, где же ты был раньше?
Пока готовил этот пост, в голову пришла мысль о том, что мы могли сами создать событие swipe, посчитав разницу в пикселях и времени между событиями touchstart и touchend. Да и готовая библиотека в природе существует
Необычное применение сервиса
Как-то раз наши знакомые устроили онлайн-баттл между фронтами и верстальщиками. Цель — сверстать лендинг на скорость, при этом выполнить все технические моменты а-ля анимация и т.д. Организовали всё как полагается — стрим, ведущие, профайлы участников. Когда углубились в представление каждого бойца, появилась шальная идея добавить действу красок за счет своего тотализатора.
Аудитория стрима была небольшая — собирали её по телеграм-чатикам и среди знакомых, однако принимать прогнозы руками было не прикольно.
Мы решили смастерить свой ОдинИксБет через WebAsk, ведь фактически формат опросника для этого подходит, оставалось лишь прикрутить туда динамический коэффициент.

Результат генерируется сразу:
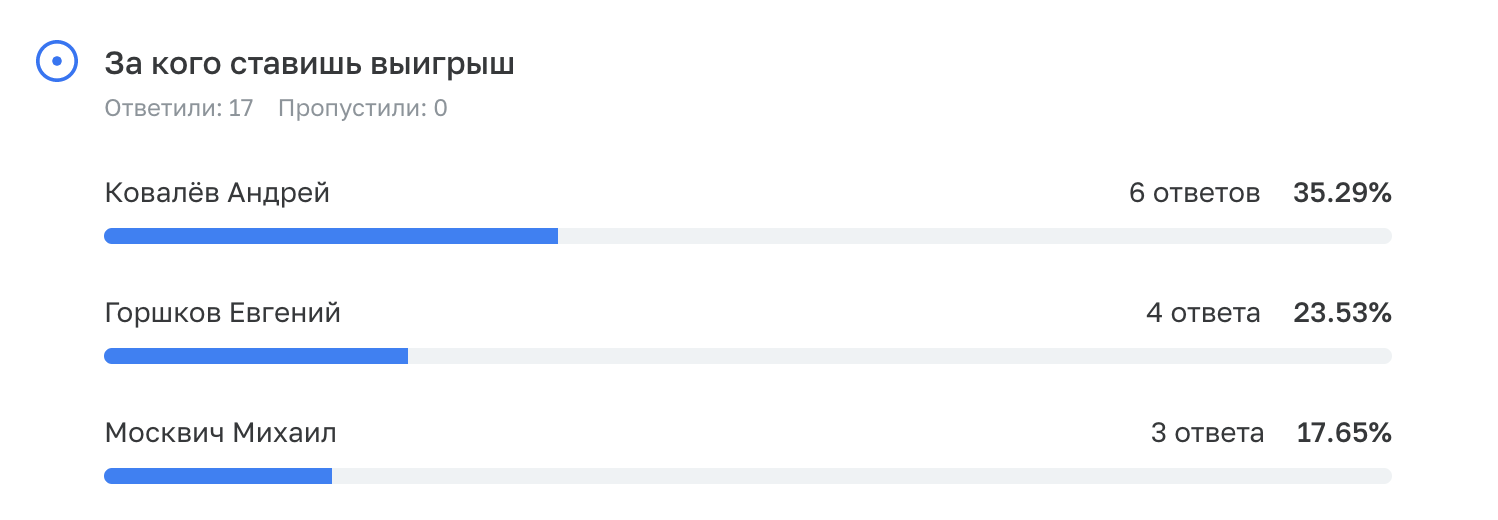
Дали каждому зрителю одну условную единицу — его голос. Чтобы добавить коэффициенты, написали небольшой скрипт и вставили его в конец
.Такая возможность тоже базово уже была в WebAsk:

Чтобы всё получилось, нам пришлось сделать GET-запрос на страницу с отчетом, распарсить html и достать из него актуальные голоса. Далее коэффициент посчитали примерно так:
const all_votes = 19; // количество голосов всего
const current_votes = 9; // количество голосов за этого участника
const coef = (all_votes + 1) / (current_votes + 1); // 2
Итого в интерфейсе голосующий не видит точное количество отданных ранее голосов, но система знает, что, условно, всего есть 19 голосов, а за участника №1 проголосовали 9 раз. Таким образом, голосующий может отдать за него свой голос, и в случае успеха получит обратно 2.
Кстати, баттл стартовал в обед, а решение устроить тотализатор появилось в день баттла с утра. Так что схемка выше — это собранное на коленке решение.
Не обошлось без магии
У нас бы ничего не вышло, поскольку изначально страница отчета в WebAsk не кастомизировалась. Впопыхах выкатили обновление на продакшн сервер, где было заложено уникальное условие только для этого отчета — для него мы вместо стандартных счетчиков рассчитали коэффициенты.
Дальнейшие планы
Планов у нас много, но среди всего многообразия хотелось бы отдельно выделить следующие фичи:
скорринг (для создания тестов)
e-mail приглашения (массовая рассылка)
фильтрация ответов
карта для логики (для визуализации результата логической цепочки)
системы оплат Stripe, ЮMoney
популярные CRM-системы
Будем рады, если перейдете по ссылке и потестируете сервис и скажете ваши «фи» или наоборот похвалите. Респект всем, кто дочитал!
