Как мы делали свой поиск в Ozon: эволюция архитектуры от SQL до O2
Привет, Хабр! Меня зовут Сергей, я руководитель команды поиска в Ozon. Сегодня я расскажу об эволюции наших поисковых систем: как всё начиналось более 20 лет назад с обычных SQL-запросов, как мы осваивали Sphinx и Elasticsearch, и как сейчас наш собственный поисковый движок O2 на базе Apache Lucene выдерживает нагрузку в десятки тысяч RPS в сезон распродаж. Исторические хроники восстанавливались по воспоминаниям современников и представлены для полноты картины. Новейшая история описана на основе собственного опыта, поэтому подробностей будет на порядок больше. Поехали!

Древний мир, 1998—2011 гг.
 Главная страница Ozon в 2001 году
Главная страница Ozon в 2001 году
Ozon был основан в далёком 1998 году. В то время большинство IT-систем представляли собой связку из монолитного приложения, отвечающего за бизнес-логику, и СУБД для хранения данных. Нередко бизнес-логика размещалась не только в приложении, но и в СУБД — с использованием процедур и триггеров. Сервисно-ориентированная архитектура только начинала набирать популярность, а до появления микросервисов было ещё целое десятилетие. Техническая начинка Ozon на старте была довольно простой: по словам создателей, на запуск первой версии проекта ушло всего четыре месяца. Сайт работал на базе самописной CMS, что для небольшого интернет-магазина выглядело вполне разумным решением.
На скриншоте от 2001 года представлена главная страница: обзор новинок, справочная информация и ссылки на основные разделы сайта. Покупатели чаще пользовались товарным каталогом, чем поиском: просто переходили в конкретную товарную категорию и видели на экране весь имеющийся ассортимент. Для сужения выдачи можно было использовать фильтры, например ограничить товары неким диапазоном цен. Поиск и фильтрация были реализованы обычными SQL-запросами, которые работали с таблицей товаров. Примечательно, что единственный сервер базы данных обрабатывал все виды запросов с сайта: и просмотры товаров, и поисковые запросы, и создание заказов. Архитектура была предельно простой, зафиксируем её в качестве отправной точки:
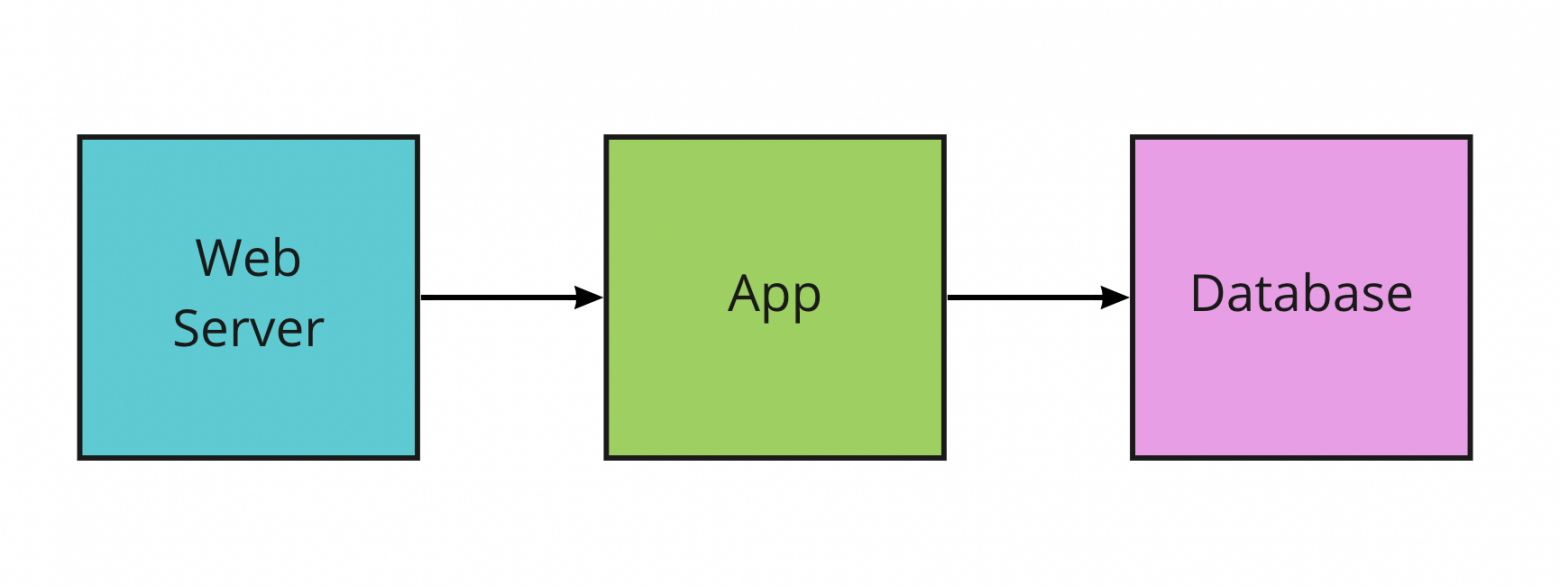 Типичная архитектура монолитного веб приложения
Типичная архитектура монолитного веб приложения
Прогресс в области полнотекстового поиска не стоял на месте — в 1999 году состоялся первый релиз Apache Lucene, самой популярной опенсорс-библиотеки в этой сфере. Примерно в это же время поддержка FTS (full-text search) начала появляться в популярных СУБД — Microsoft SQL Server 7.0 и Oracle 8i. Основные преимущества FTS над SQL-запросами вида select ... where title like "%apple%" — это эффективность выполнения запроса и поддержка стемминга (учёт окончаний и других изменений слов).
Первая версия полнотекстового поиска в Ozon была реализована с помощью Microsoft SQL Server FTS. Поисковая система позволяла искать товары с использованием фильтрации по категориям, геодоступности, ценам и рейтингу. В 2009 году для поиска подняли собственный Microsoft SQL Server-кластер, состоящий из одного мастера и четырёх реплик, — таким образом разграничили нагрузку от поиска и остальной функциональности сайта.
Средние века, 2011—2017 гг.
 Главная страница Ozon в 2011 году
Главная страница Ozon в 2011 году
С появлением новых товарных категорий росла и вариативность товарных атрибутов. В товарах из категории «Книги» продавцы стали указывать автора, жанр и издательство, из категории «Смартфоны» — бренд, цвет, объём оперативной памяти и количество ядер. Появился запрос на так называемый «фасетный поиск», то есть возможности показывать пользователю весь спектр значений фильтров и фильтровать поисковую выдачу по выбранным значениям. Такие задачи легко решаются специализированными поисковыми движками. Предстояло обзавестись одним из них.
На дворе стоял 2011 год. Популярные сегодня поисковые движки — Elasticsearch (первый публичный релиз был в 2014 году) и Apache Solr (первый релиз SolrCloud был в 2012-м) — в то время ещё не были стандартами в своей области. Выбор пал на подающую надежды отечественную разработку Sphinx, которая была на пороге выпуска второй мажорной версии движка. Команда съездила на митап по Sphinx, заручилась поддержкой основателя и начала готовиться к миграции. За несколько месяцев удалось собрать пилотную версию, на базе которой запустили новый каталог обуви. Эксперимент был признан успешным — и в течение следующих шести месяцев команда мигрировала на новую технологию остальные товарные категории.
При переходе со встроенного FTS-модуля на внешний поисковый движок возникли новые обязательства: было необходимо реализовать загрузку данных для индексации в этот самый движок, настроить доставку изменений атрибутов в реальном времени, а также обеспечивать балансировку и отказоустойчивость нового компонента системы. Архитектурная схема заметно усложнилась:
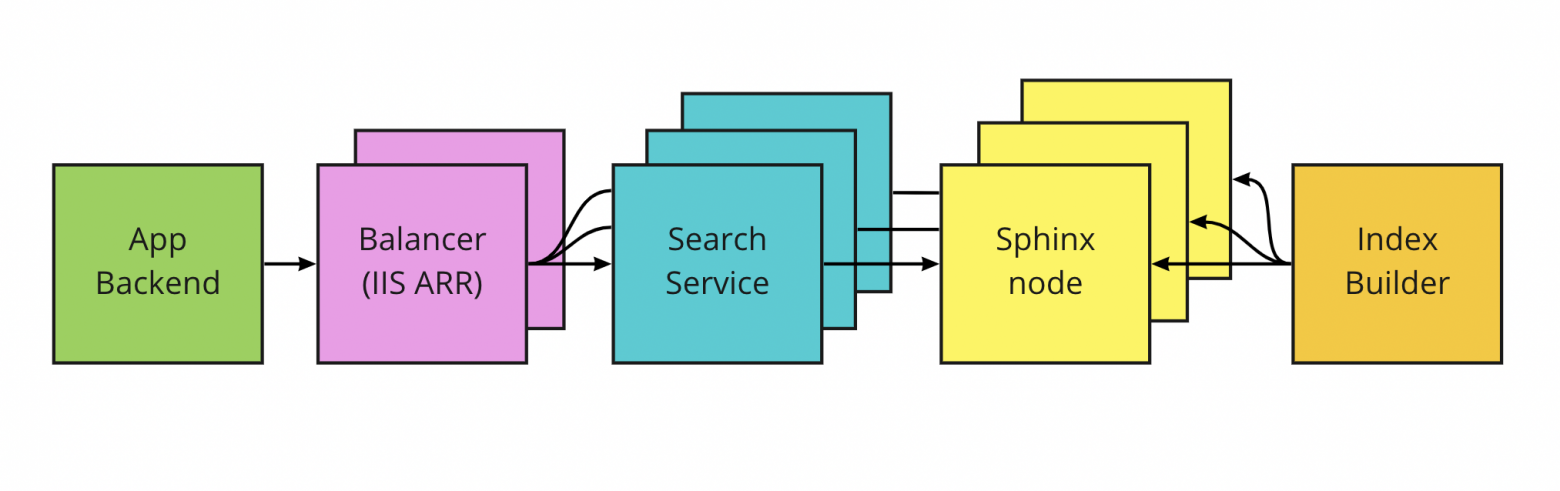 Архитектура поиска Ozon во времена Sphinx
Архитектура поиска Ozon во времена Sphinx
Появились выделенные бэкенды поиска, которые превращали HTTP-запросы от бэкенда сайта в формат, который понимал Sphinx. Каждому бэкенду соответствовал свой узел Sphinx, а сами они стояли за балансировщиками нагрузки — модулями Application Request Routing в IIS. Поисковый индекс собирался на отдельном сервере и доставлялся на рабочие машины через mounted NFS directory. Также появилась простая админка для управления узлами поисковой системы, работы с индексами и метаинформацией.
Одна из основных проблем того времени — доставка обновлений до поискового индекса. Цены, скидки, наличие товаров на складах и отзывы часто обновляются, отчего генерируется большой поток изменённых записей. Обновления индекса в Sphinx накатывались дельтами, и в нормальных условиях этот процесс происходил каждые пять минут. Но иногда всё шло не по плану. Например, массовое изменение цен могло создать слишком большое количество обновлений, пятиминутные дельты становились гигантскими — и Sphinx просто не мог их обработать. В таких ситуациях спасала только полная реиндексация, то есть сборка нового индекса с нуля и замена им предыдущей версии.
Поисковая система на базе Sphinx просуществовала шесть лет, после чего на смену ему пришёл Elasticsearch.
Новое время, 2017—2020 гг.
 Главная страница Ozon в 2017 году
Главная страница Ozon в 2017 году
Переезд со Sphinx на Elasticsearch происходил в 2017 году. Мотивация была предельно проста — уменьшить уровень боли:
Манипуляции с накаткой дельт индекса выполнялись через консольные утилиты, поддержки API не было.
Процесс построения индекса не удавалось распараллелить. В теории Sphinx поддерживал партиции, которые можно было индексировать параллельно. Партиции объединялись в один виртуальный индекс. Такая конструкция приводила к N запросам вместо одного с последующей агрегацией результатов, из-за чего возникали проблемы с производительностью. В итоге решение не взлетело.
Для реализации собственной логики ранжирования товаров нужно было писать свою библиотеку на С.
После перехода на Elasticsearch появились все необходимые элементы для распределённого поискового движка:
узлы для индексации документов с поддержкой high availability,
горизонтально масштабируемые реплики,
возможность шардировать индекс,
возможность писать свои плагины для ранжирования.
В Ozon в тот момент уже активно внедрялись микросервисы (преимущественно на .NET и Go). Архитектура поиска на базе Elasticsearch выглядела следующим образом:
 Архитектура поиска Ozon во времена Elasticsearch
Архитектура поиска Ozon во времена Elasticsearch
Новейшая история, с 2020 г.
 Главная страница Ozon в 2022 году
Главная страница Ozon в 2022 году
Разработка собственного поискового движка
В 2020 году был взят курс на создание собственного поискового движка, который должен был заменить Elasticsearch. Примерно в это время я и присоединился к команде поиска, поэтому дальше будет более глубокое погружение в проблематику и технические решения.
При создании своего решения мы преследовали следующие цели:
разделение рантайма поиска и ранжирования с целью их независимого масштабирования,
полный контроль над процессом ранжирования,
полный контроль над процессами построения и репликации индекса,
доступ к низкоуровневым оптимизациям на стадии поиска и фильтрации.
У нас было два пути: написать с нуля абсолютно всё (так в своё время сделали Google, Facebook и Яндекс) либо переиспользовать готовые решения. Первый вариант привлекал возможностями кастомизации, но предполагал «speed run» двадцати лет развития технологий полнотекстового поиска. Второй подход привязывал нас ко всем особенностям и недостаткам используемых технологий, но избавлял от повторения чужих ошибок. Взвесив все за и против, мы выбрали его — взяли опенсорс-библиотеку Apache Lucene и построили на базе неё свой поисковый движок с блек-джеком и куртизанками.
В качестве языка программирования выбрали Java, в первую очередь из-за желания работать с оригинальным кодом Lucene. JVM платформа даёт все необходимые инструменты для построения highload-систем, а обилие фреймворков и библиотек избавляет от необходимости заниматься велосипедостроением.
Концептуально наш поисковый движок состоит из трёх частей:
Мастер индексации отвечает за построение Lucene-индекса — он получает на вход документы вида «ключ — значение» в формате JSON, а на выходе выгружает сегменты. Сегмент в терминах Lucene — это иммутабельный кусочек индекса, содержащий подмножество документов. Мастер использует стандартный API библиотеки Lucene при работе с индексом, например IndexWriter.
Базовый поиск — это слой для выполнения поисковых запросов. Каждый узел закачивает в себя поисковый индекс, после чего он готов к работе. Помимо задач поиска и фильтрации найденных товаров, эта часть движка отвечает за первый уровень ранжирования (L1 Ranking). На этом уровне абсолютно все найденные документы сортируются по лёгкой формуле, учитывающей текстовую релевантность (tf-idf, BM25) и простые эвристики. Базовый поиск можно горизонтально масштабировать.
Средний поиск — это слой для роутинга запросов и ранжирования (L2 Ranking) поисковой выдачи. Мы сразу закладывали в архитектуру шардирование поискового индекса, поэтому над слоем базового поиска требовалось расположить сервис, отвечающий за роутинг запросов по шардам и формирование финального результата из нескольких частичных ответов. В этом же слое находится рантайм ранжирования, который сортирует результаты с помощью ML-моделей. Средний поиск тоже можно горизонтально масштабировать.
 Концепт поискового движка о2
Концепт поискового движка о2
Примерно через полгода интенсивной работы была готова первая полноценная версия поискового движка. Мы подняли небольшой кластер с настоящим индексом и начали зеркалировать в него часть реального трафика, чтобы собирать логи и измерять качество. Ещё несколько месяцев ушло на то, чтобы отладить расчёты текстовой релевантности с помощью офлайн-оценки ранжирования, устранить проблемы с перформансом при помощи нагрузочного тестирования и доделать всё, что связано с high availability.
Как работает офлайн-оценка ранжирования
Офлайн-оценка ранжирования — это методика оценки качества поисковой выдачи при помощи асессоров. Делается примерно так: по заранее подготовленным поисковым запросам скачиваются результаты поисковой выдачи (к примеру, вся первая страница товаров), а затем создаются задания на оценку (пары вида «поисковый запрос + товар»). Задача асессора — оценить по определённой шкале, насколько товар релевантен поисковому запросу.
Имея оценку товаров, находившихся на разных позициях поисковой выдачи, можно при помощи нехитрой математики получить итоговый score ранжирования. Идеальным считается такое ранжирование, где все товары в выдаче имеют самые высокие баллы. Фактический результат оценивается относительно этого идеала. Формула должна учитывать как баллы, так и позицию товара в выдаче, то есть нерелевантные товары в самом начале выдачи «штрафуются» сильнее, чем если бы они были в конце. В базовом виде такая методика подсчёта называется nDCG, при этом подход можно кастомизировать под свои целевые метрики.
Офлайн-тестирование позволяет оценить качество поисковой выдачи без выкатки новой версии ранжирования на реальных пользователей. У такого подхода множество плюсов:
возможность экспериментировать с ранжированием, не теряя деньги в случае неудачи;
обратная связь в среднем приходит на порядок быстрее, так как результаты разметки можно переиспользовать;
нет ограничений мощности трафика, и не нужно ждать очереди для запуска, как иногда бывает при проведении А/B-экспериментов;
не требуется разворачивать полноценную инфраструктуру поиска в продакшене — можно в спокойном темпе подготовить задания, имея единственный сервер поиска в стейджинг-окружении.
Минусы, конечно, тоже есть: хорошие результаты офлайн-тестирования не гарантируют успех при запуске нового ранжирования на реальных пользователях.
Летом 2021 года мы постепенно перевели весь пользовательский трафик на новый поисковый движок. Он получил название O2 («о два», то есть кислород). Релиз получился фантастически успешным: в несколько раз снизилась latency и увеличился throughput. Архитектурная схема поиска на момент релиза O2:
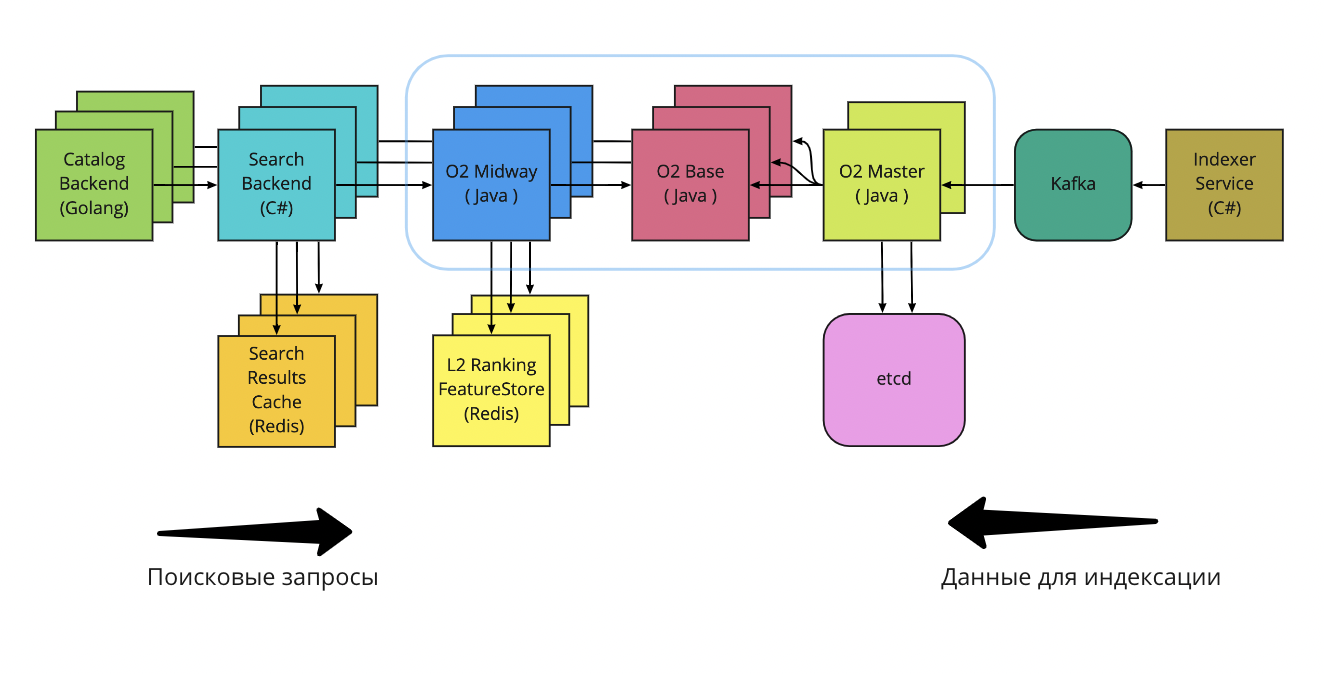 Архитектура поиска на момент релиза о2
Архитектура поиска на момент релиза о2
Давайте рассмотрим отличия от прошлой версии на базе Elasticsearch и поговорим о технических нюансах.
Балансировка трафика
Раньше поисковые бэкенды ходили в Elasticsearch через Nginx-балансировщик, который одновременно служил слоем для кеширования. Клиенты использовали доменное имя, которое по DNS резолвилось в несколько IP-адресов Nginx-серверов. Если с Nginx-сервером случалось что-то нехорошее, можно было поднять рядом ещё один сервер и перевесить на него IP-адрес.
Собственный поисковый движок дал возможность использовать клиентскую балансировку — подход, при котором клиенты хранят у себя список актуальных IP-адресов бэкендов для сервисов, с которыми они взаимодействуют. Для реализации такого подхода нужен Service Registry, который знает, где какие сервисы задеплоены и как конфигурация меняется со временем. В Ozon его функцию выполняет платформенный сервис Warden. Он интегрирован с Kubernetes и знает, на каких серверах/IP-адресах можно найти инстансы нужных сервисов. Таким образом мы избавились от Nginx-прослойки и связали Search Backend и o2-midway напрямую. Это немного улучшило latency в высоких квантилях и дало возможность использовать subsetting и реализовывать кастомные алгоритмы балансировки. Например, сейчас мы тестируем p2c на базе EWMA response time.
Разделение фаз поиска
Два слоя поиска, o2-midway и о2-base, реализованы в виде отдельных сервисов.
Нижний уровень o2-base деплоится как StatefulSet — вид ресурса в Kubernetes, которым можно привязать pod к персистентному хранилищу. В нашем случае это жёсткий диск, на котором хранится поисковый индекс. Без StatefulSet при любом рестарте пода приходилось бы с нуля закачивать на него весь поисковый индекс, который весит пару сотен гигабайт. Учитывая размеры нашей системы (сотни серверов), это приводило бы либо к чересчур долгому ожиданию, либо к высокой утилизации сетевого канала.
После запуска сервиса по мере выполнения поисковых запросов значимая часть поискового индекса подгружается в оперативную память (page cache). Чтение производится с помощью mmap, из-за чего существенно уменьшаются накладные расходы на получение данных. Только так можно получить приемлемое время ответа. На этом уровне оно складывается преимущественно из времени, затрачиваемого на обход постинг-листов в обратном индексе, вычисление текстовых скоров кандидатов для L1-ранжирования и извлечение DocValues-полей, необходимых для реализации последующей бизнес-логики. Ещё раз подчеркну, что базовый поиск ранжирует все товары, которые удалось найти, — потенциально миллионы записей. Подробнее об устройстве поискового индекса и его внутренних структурах данных можно почитать в этой статье моего коллеги из команды поискового рантайма.
Средний уровень o2-midway является обычным stateless-сервисом в Kubernetes. Через него проходят все поисковые запросы: сначала они идут в базовый поиск для получения первых (наиболее релевантных) N тысяч товаров, затем происходит переранжирование этой выборки (L2 Ranking) при помощи машинного обучения. Для ранжирования требуется подгрузить фичи для найденных товаров — они служат входными параметрами для ML-модели. Конкретный набор фич находится под NDA, но ни для кого не будет откровением, что мы, как и любая другая e-com платформа, учитываем факторы вроде цены товара, популярности, скорости доставки и отзывов. Таким образом, для каждого товара нужно хранить в быстром доступе предрассчитанные значения этих характеристик. Модели поискового ранжирования также требуются парные фичи — статистика товара по конкретным запросам. В сумме получаются сотни миллионов пар «ключ — значение», где ключ — это товар либо запрос и товар, а значение — float-массив со значениями фич. Мы храним эту информацию в Redis Cluster — он даёт возможности шардирования и репликации из коробки.
Как упоминалось ранее, разделение слоёв позволяет масштабировать их независимо. К примеру, при внедрении более тяжёлых ML-вычислений в o2-midway мы можем просто поскейлить средний слой поиска, не меняя нижний.
Eventual consistency
Поисковые системы, основанные на обратном индексе, обычно имеют сложности с поддержкой быстрых обновлений. Минимальная часть индекса — это иммутабельный сегмент, поэтому возможность in-place редактирования документов отсутствует. Единственный способ обновления заключается в выпуске (commit) нового сегмента, содержащего все новые и изменённые документы (при этом старые версии документов помечаются tumbstone маркерами). С каждым новым сегментом индекса ухудшается latency поиска (приходится делать больше работы), поэтому для сохранения быстрого времени ответа выгоднее реже делать коммиты. Для этого нужно накапливать побольше документов перед коммитом, тем самым откладывая момент, когда изменения доедут до поисковых узлов и станут видны пользователям. Иными словами, мы имеем trade-off между актуальностью данных и временем ответа поиска. В поисковом движке EarlyBird (форк Lucene) инженеры Twitter решали проблему задержки обновлений с помощью in-memory поиска в ещё не выпущенном сегменте. У нашей команды пока не дошли руки до повторения этих подвигов.
Узлы базового поиска закачивают в себя новые сегменты с разной скоростью, поэтому в один момент времени разные узлы кластера могут иметь разное состояние индекса. Из-за этого один и тот же поисковый запрос может вернуть немного разные результаты при повторном исполнении, а также может возникнуть неконсистентность при пагинации (на практике ничего из этого не происходит, потому что у нас есть кеши). Мы сознательно не стали реализовывать на старте sticky sessions, так как последствия данной проблемы не приносят большого вреда.
Улучшения перформанса
Владение кодом поискового движка дало возможность самостоятельно улучшать перформанс в соответствии с нашими нуждами. Мы сразу же заменили последовательную обработку сегментов при выполнении запроса (так делал Elasticsearch, по крайней мере до версии 6.6) на параллельную: разбиваем сегменты на группы жадным алгоритмом так, чтобы в каждой было примерно одинаковое число документов, и отправляем каждую группу в thread pool. В итоге происходит очередной trade-off: ухудшение throughput (из-за дополнительных расходов на многопоточность) на улучшение latency. Нам это выгодно, так как добавить серверов и нарастить throughput не составляет труда, а с latency такой трюк не проходит. Elasticsearch предлагает решать данную задачу путём шардирования индекса и увеличения числа реплик, однако такой подход требует больше вычислительных ресурсов, чем параллелизация внутри одного сервера.
Жизнь после релиза
После перевода трафика с Elasticsearch на O2 развитие поиска не остановилось, а, наоборот, ускорилось.
Больше дата-центров
С самого начала 2021 года Ozon занялся переходом на MultiDC-архитектуру. Больше всех этим проектом занимались разработчики платформы и инфраструктуры: настраивали новые дата-центры, адаптировали базовые сервисы (etcd, Kafka, Ceph, Redis, PostgreSQL, Hadoop) и CI/CD. Меньше всего это затронуло владельцев stateless-сервисов: требовалось сделать число реплик кратным трём и обновиться до последних версий CI/CD-пайплайнов. Команда поиска в этом вопросе оказалась где-то посередине из-за использования StatefulSet в базовом поиске (и ряда других вещей, которые мы оставим за скобками). Переход на MultiDC у нас совпал по времени с внедрением О2, поэтому движок проектировали с учётом новой схемы.
Мы приняли решение разворачивать три независимых кластера базового поиска, по одному в каждом ДЦ. Первая версия o2-master имела ограничение по количеству узлов o2-base в кластере, и мы физически не могли сделать один огромный кластер в трёх ДЦ. Как вы уже могли догадаться, узким местом был сетевой канал o2-master — он полностью утилизировался, когда узлы o2-base закачивали в себя индекс. Подробнее об этом я расскажу в следующем пункте.
Независимые кластеры в Kubernetes реализовались как независимые сервисы: o2-base-dc1, o2-base-dc2, o2-base-dc3, каждый со своим CI/CD-пайплайном и мониторингом. Эта конструкция создала нам проблемы с балансировкой: o2-midway был единым «растянутым на три ДЦ» stateless-сервисом, а кластеров o2-base стало несколько. Как в такой ситуации роутить запросы из o2-midway в o2-base? Для платформенной балансировки это был нестандартный сценарий, поэтому нам пришлось прикрутить свою балансировку на базе Ribbon: инстанс o2-midway сначала выбирал кластер o2-base (с вероятностью, пропорциональной размеру кластера), а затем выбирал сервер внутри кластера.
Забегая вперёд, скажу, что схема с независимыми кластерами O2 себя полностью оправдала. Во-первых, она позволяет быстро снять трафик с кластера во время инцидента, если с ним обнаруживаются какие-то проблемы. Во-вторых, можно обновлять кластеры по отдельности, что очень актуально при рискованных релизах.
MultiDC-архитектура поиска выглядит примерно следующим образом:
Stateless-сервисы общаются друг с другом только в рамках одного ДЦ: catalog → search, search → o2-midway. Это достигается при помощи упоминавшегося ранее платформенного сервиса Warden: по умолчанию он отдаёт клиенту только IP бэкендов из локального ДЦ.
Кеши поисковой выдачи распределены по всем ДЦ. Так мы получаем больше эффективного пространства. В случае отказа ДЦ мы потеряем треть от всех записей в кеше и, как следствие, треть его хит-рейта. Катастрофы при этом не произойдёт, так как мы планируем свои мощности без учёта кешей.
В каждом ДЦ есть своё хранилище для ML-фичей. Здесь мы не можем позволить себе потерять треть данных из-за инцидента, поэтому их приходится дуплицировать.
Балансировка между o2-midway и o2-base происходит в два этапа: сначала — выбор ДЦ, затем — выбор сервера.
MultiDC-архитектура платформенных сервисов (etcd, Kafka) для клиентов незаметна, за что отдельное спасибо команде платформы.
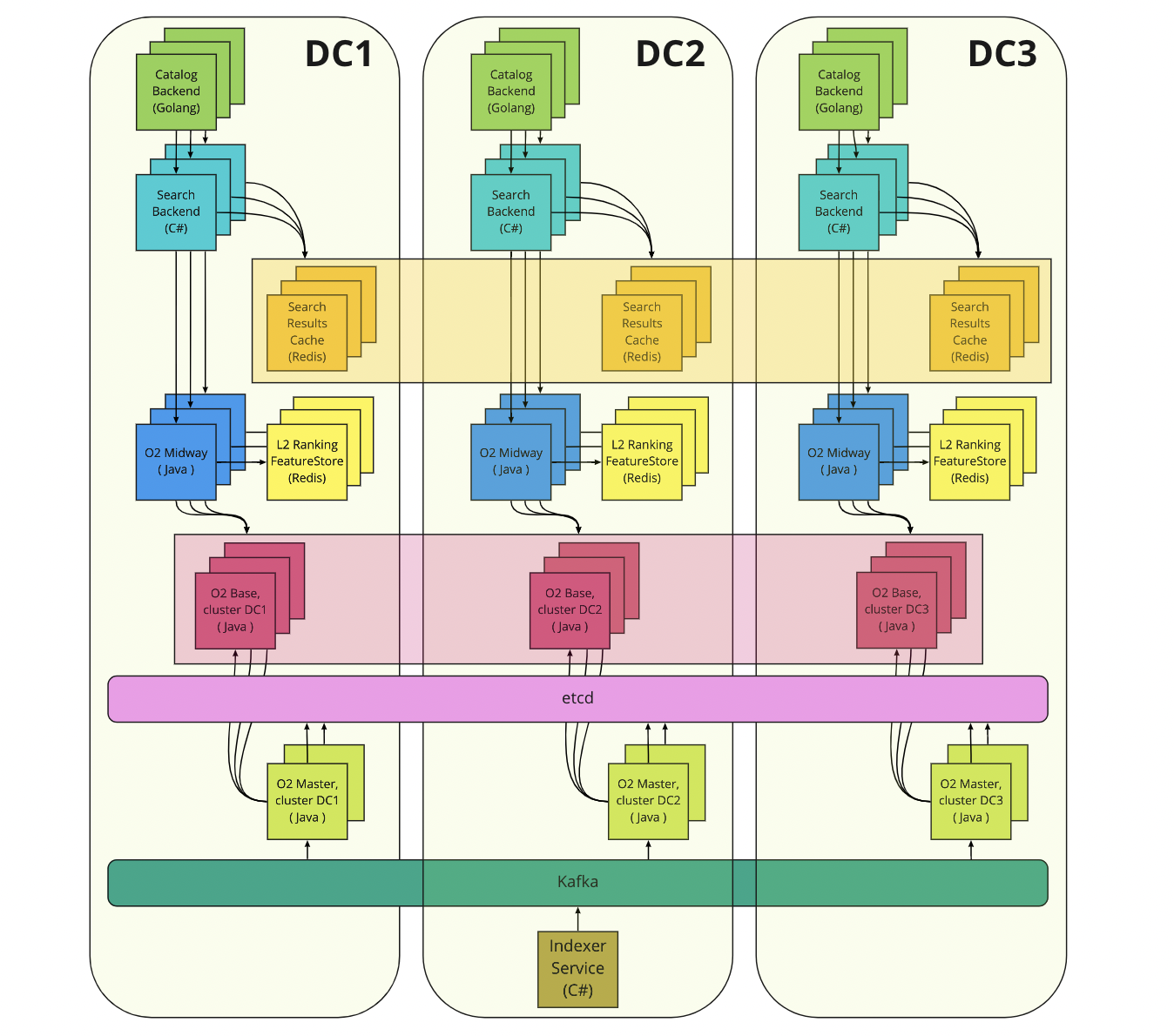 MultiDC архитектура поиска
MultiDC архитектура поиска
Разгружаем мастер
Выше была упомянута проблема пропускной способности o2-master: скорость сетевого канала определяет максимальное количество узлов o2-base, которые могут без задержек закачивать обновления индекса. Для примера: если мастер выпускает сегменты размером 10 Гб каждые пять минут, то канал с пропускной способностью 10 Гбит/с будет полностью утилизирован 37-ю узлами (на одно скачивание нужно восемь секунд, за пять минут можно скачать сегмент 37,5 раза). На деле число будет меньше, так как соединение иногда обрывается и утилизация канала неидеальна. Нам удалось устранить фактор ухудшения throughput из-за конкуренции узлов o2-base установкой distributed-семафора перед o2-master, но ситуация требовала фундаментального решения.
Было очевидно, что функции построения и раздачи индекса нужно разделять, поскольку первая требовала singleton-подхода, а вторая — горизонтального масштабирования. Мы переписали код таким образом, чтобы o2-master загружал готовые индексы в S3-хранилище (Ceph), а узлы базового поиска скачивали их оттуда. Ещё на этапе проектирования мы осознали, что такое решение имеет тот же недостаток: точки взаимодействия с Ceph (в нашем случае это Rados Gateway) будут перегружены. В мире большого интернета задачу раздачи контента решают с помощью CDN, поэтому мы пошли тем же путём: подняли слой с Nginx-серверами перед Ceph. Узлы базового поиска стали обращаться за индексом к Nginx, который сперва проверяет наличие локальной копии и только в случае её отсутствия единственный раз выкачивает данные из Ceph (реализуется через proxy cache lock в Nginx). В итоге на сотню серверов o2-base нам требуется около восьми CDN-серверов. Мы хотели пойти дальше и применить bonding сетевых карт, дабы увеличить сетевой throughput на Nginx-серверах, но NOC-инженеры не захотели поддерживать такое решение.
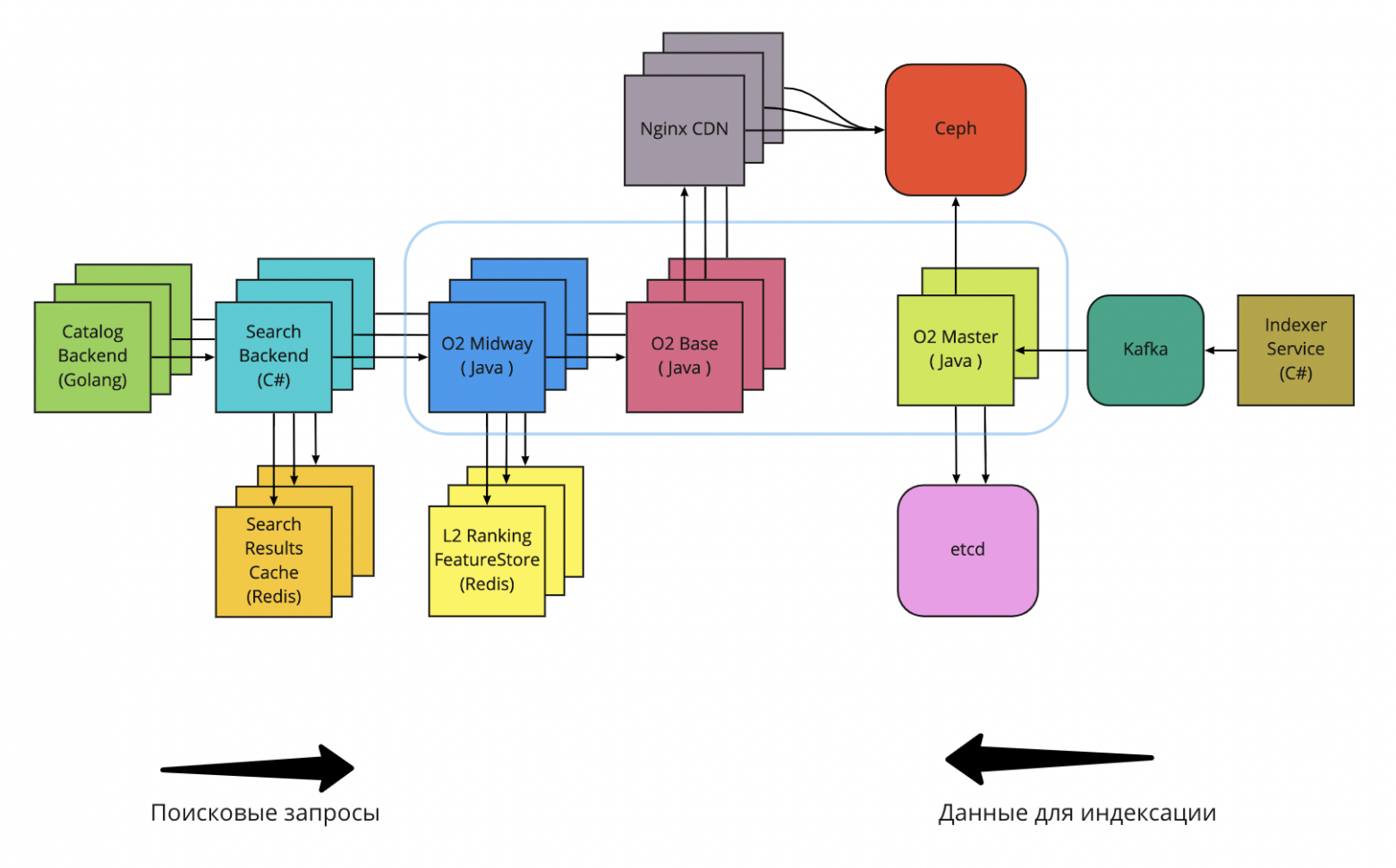 Архитектура поиска с появлением CDN
Архитектура поиска с появлением CDN
Примерно через полгода после перехода на CDN мы внедрили сжатие индекса при помощи zstd, тем самым уменьшив передаваемый объём данных в два раза. На текущий момент это последний штрих в оптимизации раздачи поискового индекса. Спустя время мы, скорее всего, вернёмся к этому вопросу и возьмёмся за реализацию P2P-репликации.
Персонализация
В борьбе за качество поисковой выдачи мы пришли к тому, что хотим учитывать персональные предпочтения пользователей. Какое отношение это имеет к поисковому движку? Самое прямое: если раньше мы могли закешировать поисковую выдачу по запросу «микроволновка» для жителей Москвы, то теперь не можем. Иван Иванович тяготеет к технике марки Bosch, а Татьяна Семёновна всю жизнь покупает Electrolux. Соответственно, ранжирование становится уникальным для покупателя, поэтому нельзя кешировать финальную страницу выдачи и возвращать её остальным.
Совсем отказываться от кеширования мы не хотели, поэтому переместили кеши под слой o2-midway, в котором происходит ML-ранжирование. Теперь мы кешируем только результаты базовой выдачи, а ML-ранжирование честно выполняется при каждом запросе. Разумеется, мы немного потеряли в latency, но зато выиграли в качестве ранжирования от внедрения персонализации. Неплохая сделка!
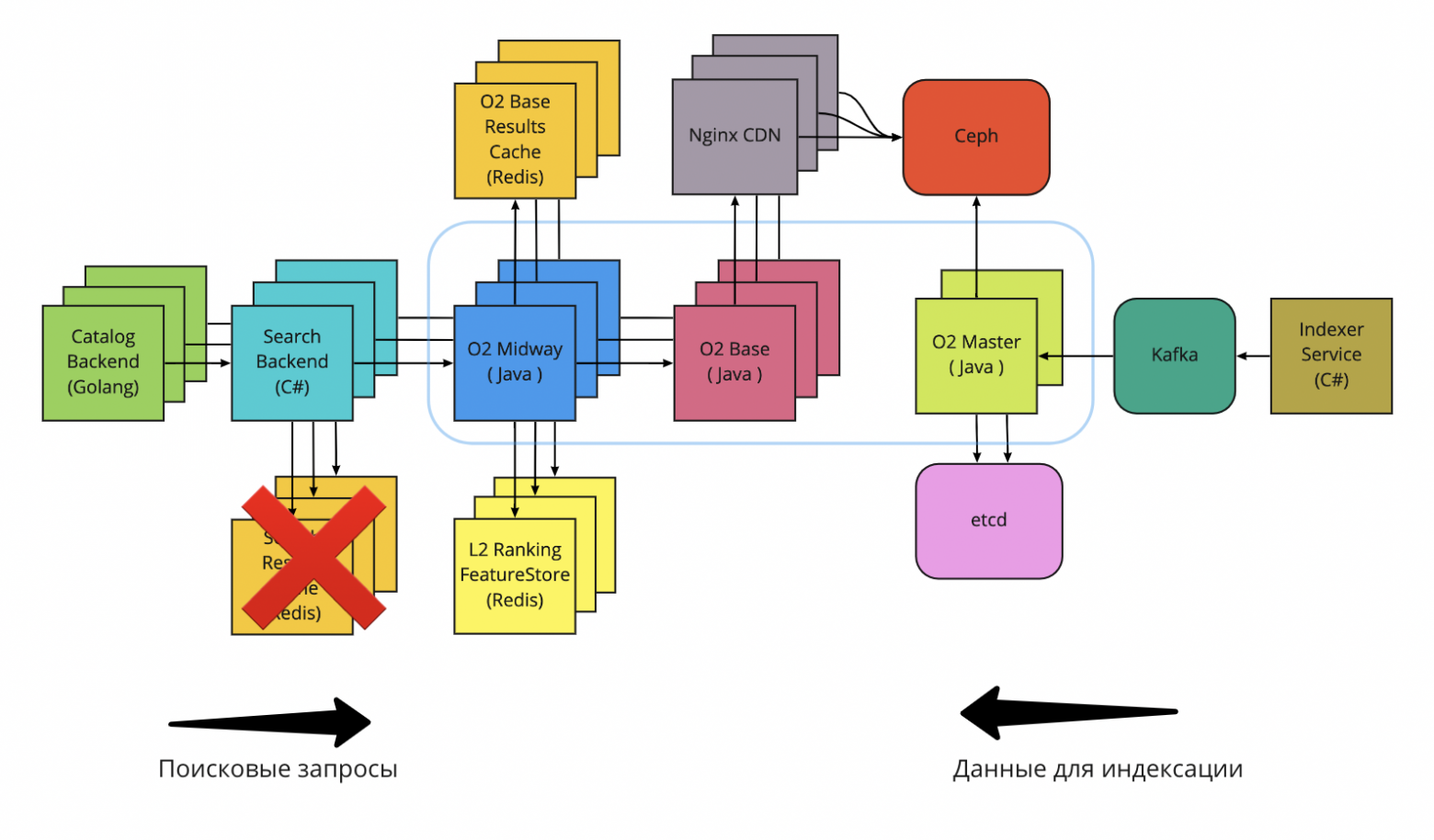 Архитектура поиска после переноса кешей на уровень o2-midway
Архитектура поиска после переноса кешей на уровень o2-midway
Эпилог
Таким непростым был путь поиска в Ozon за последние 20 лет. Понимаю, что получился лонгрид, из-за этого мне даже пришлось умолчать про устройство индексации, DSSM, query enrichment и архитектуру рекламы в поиске.
Однако архитектура — это далеко не всё, чем занимается команда поиска. Мы постоянно улучшаем продукт и UX, вкладываем много сил в развитие ML-ранжирования, закапываемся в аналитику и проводим множество A/B-экспериментов. У нас немало задач, в которых используются интересные структуры данных и алгоритмы, например Bloom-фильтры, LRU, Trie, HyperLogLog и RingBuffers. Помимо основных задач поиска и ранжирования товаров, есть много сопутствующих: исправление опечаток, поисковые подсказки (suggests), предсказание товарной категории для поисковых запросов и другие элементы NLP. Если какие-то из этих тем звучат интересно, отпишитесь в комментариях — и мы расскажем об этом в следующий раз. До встречи!
