Как мы делаем общие библиотеки
Сегодня я хотел поговорить о том, как мы выстраиваем процесс работы с общими библиотеками разработки. Я расскажу о нашем подходе, который позволяет соединить процессы, команды и инструменты в единое целое. Статья будет интересна тем, кто сопровождает, создает или интересуется, как библиотеки появляются на свет.
Мы пишем множество приложений от монолитных до микросервисных, но всегда при разработке возникает потребность писать код, который требуется переиспользовать. Например, работа с Kafka или создание клиентов для сторонних систем. Сначала мы исследуем возможность поиска готовых решений (как среди сторонних, так и своих решений), но не всегда они покрывают потребность или в принципе существуют. Если не найдено такого решения, то разработчик скорее всего начнет писать какие-то утилитарные методы или объекты в проекте, а если таких компонентов несколько, где это требуется, то задумается о возможности создания переиспользуемого компонента. Тогда возникает потребность написать код и вынести его в общее место, доступное внутри компании всем разработчикам.
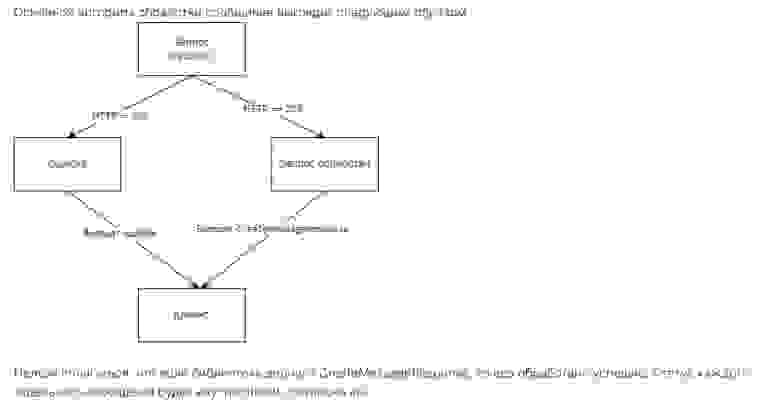
Давайте поговорим на какие уровни можно разбить такие библиотеки в компании. У нас много команд, которые ведут проекты — они могут иметь свои библиотеки на уровне проектов, которые упрощают им создание программ, а на уровне выше — общекомандные библиотеки. Обычно процесс выделения библиотеки происходит снизу вверх. Сначала находится общий функционал, который можно вынести, далее команда формирует свое решение, и если они готовы его вынести во внешнее использование или если есть потребность в нем других команд, то формируется общая библиотека. Иногда процесс может идти сверху сразу с написания общей библиотеки, если есть такая потребность. Как видно из рисунка, мы используем GitLab для хранения исходного кода в связке с Artifactory, где храним уже бинарные артефакты.

Процесс создания библиотеки несколько отличается от написания кода в проекте. Давайте рассмотрим критерии, которых следует придерживаться, когда создаете библиотеку:
Определитесь со стратегией версионирования и глубиной поддержки. Допустим, мы выбираем семантическое версионирование — SemVer. Будем ли мы поддерживать только одну основную актуальную версию? Если да, то тогда нужно обеспечить бесшовный переход между ними, в противном случае — какое количество версий потребуется и до какого момента мы будем их поддерживать?
Важным выглядит вопрос зависимости от сторонних библиотек. Например, вы расширяете функционал, уже существующий в другой библиотеке, — вы становитесь от него зависимыми. Насколько вы будете актуализировать свою библиотеку и как часто?
Ведите changelog версий — что добавилось, удалилось, какие изменения внеслись.
Четко разграничьте ответственности библиотеки. Явно укажите за что она отвечает и для чего предназначена. Опишите примеры, как следует использовать. Как не нужно пользоваться тоже можно поместить, если такие случаи в ходе эксплуатации обнаружатся. Пример описания зоны ответственности из нашей библиотеки:
Продумывайте API. Библиотеки не воробей, выпустишь — не изменишь. Иногда даже в публичных репозиториях происходит изменение уже существующей версии, но это вызовет только непонимание у ваших коллег. Поэтому важно продумать API — сделать его удобным, обкатать у себя на проекте.
Документируйте свое публичное API.
Чем лучше вы выполните предыдущие пункты, тем проще будет коллегам. Но все равно будьте готовы активно помогать разбираться и приходить на помощь своим коллегам.
Пишите тесты. Они помогут понять API и лучше спроектировать библиотеку. Тесты должны быть так же разными — юнит, интегратесты, нагрузочные.
В нашем GitLab есть пространства для библиотек по разным языкам — Java, Python и другим. У нас существуют общие принципы разработки, которые облегчают написание и сопровождение ПО. Поэтому после того, как внесены изменения, проходят как минимум этапы:
Запуск тестов
Статическая проверка кода
Проверка кода в рамках Merge Request«а
Данные проверки позволяют снизить количество ошибок и дать возможность коллегам из других команд ознакомиться с решением.
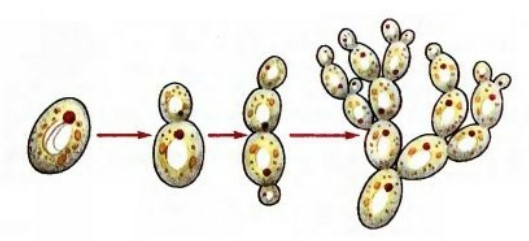
Важно отметить, что после выпуска жизнь библиотеки только начинается. Многие думают, что процесс ее создания занимает большую часть, но, как и другое ПО, она имеет жизненный цикл. Часто такой процесс имеет аналогию в реальной жизни — почкование. Сначала выделяется большая библиотека для всего, дальше она растет, и в какой-то момент команда понимает, что ее нужно разделить — начинаются ответвления и декомпозиция.
У нас на проекте была одна общая библиотека работы, после нескольких месяцев начал выделяться функционал по работе с API, базой данных и т.п. Взглянув на нее после нескольких месяцев работы, мы решили, что пришло время вынести некоторые части в отдельный функционал, который мы презентовали внутри компании и дали возможность другим коллегам переиспользовать протестированный и обкатанный инструментарий.
Дальше встает вопрос о том, кто будет сопровождать и поддерживать библиотеку. У нее должен быть технический владелец (у нас к GitLab привязано как минимум двое), который контролирует процесс развития библиотеки — оценка доработок, проверка изменений и т.п. Для своих задач он может привлекать компетентных сотрудников и контролировать процесс доработки библиотеки, владелец всегда открыт к предложениям и пожеланиям коллег. Такой процесс развивает нашу внутреннюю культуру разработки.
