Как мы боремся с копированием контента, или первая adversarial attack в проде
Привет.
Вы знали, что платформы для размещения объявлений часто копируют контент у конкурентов, чтобы увеличить количество объявлений у себя? Они делают это так: обзванивают продавцов и предлагают им разместиться на своей платформе. А иногда и вовсе копируют объявления без разрешения пользователей. Авито — популярная площадка, и мы часто сталкиваемся с такой недобросовестной конкуренцией. О том, как мы боремся с этим явлением, читайте под катом.

Копирование контента с Авито на другие платформы существует в нескольких категориях товаров и услуг. В этой статье речь пойдет только про автомобили. В предыдущем посте я рассказал, о том как мы делали автоматическое скрытие номера на автомобилях.

Но получилось (судя по поисковой выдаче других платформ), что мы запустили эту фичу сразу на трёх сайтах объявлений.

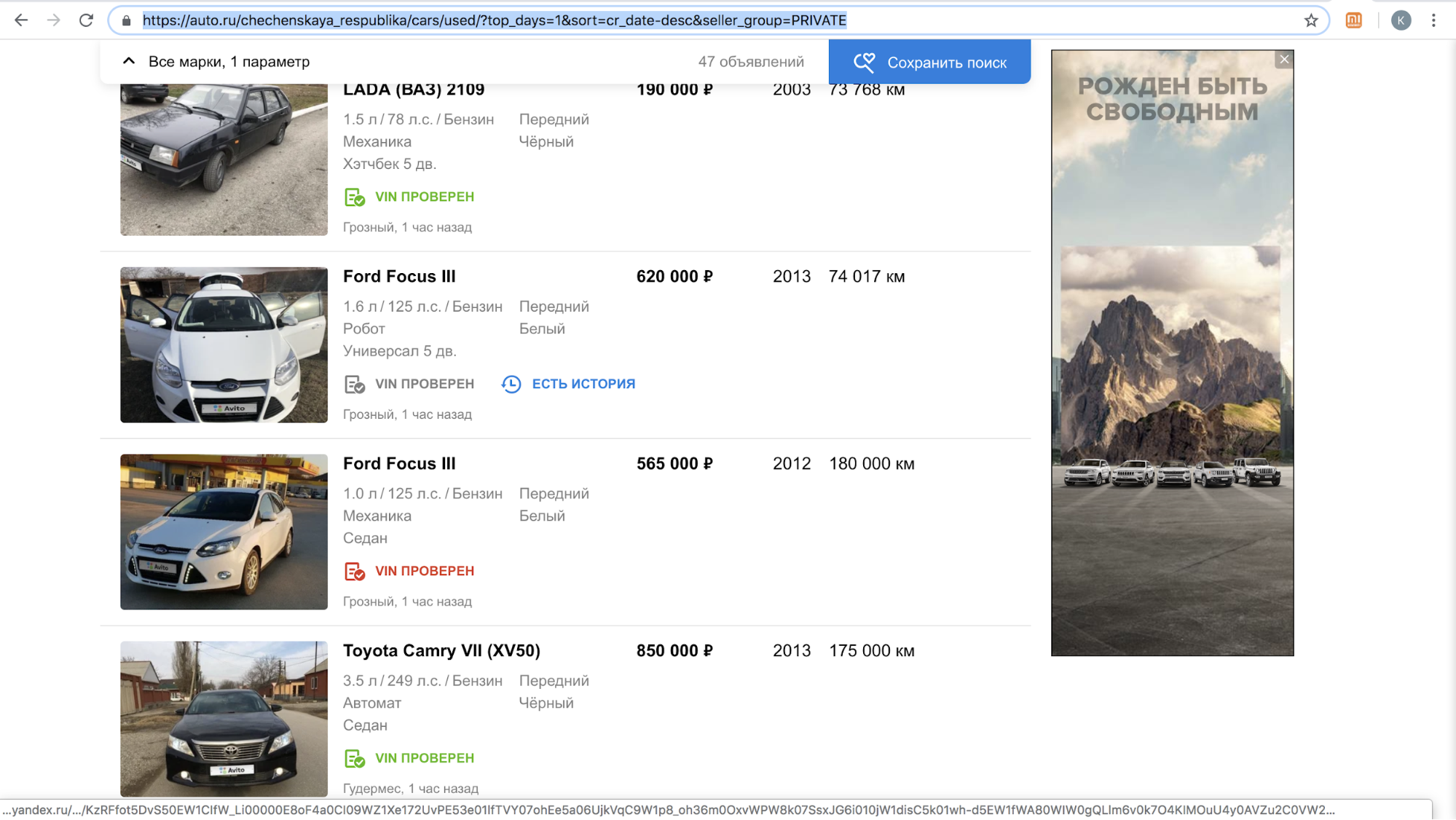
Один из этих сайтов после запуска фичи на время приостановил обзвон наших пользователей с предложениями скопировать объявление на их платформу: контента с логотипом Авито на их площадке стало слишком много, только за ноябрь 2018 года — более 70 000 объявлений. Например, вот так выглядела их поисковая выдача за сутки в Чеченской республике.
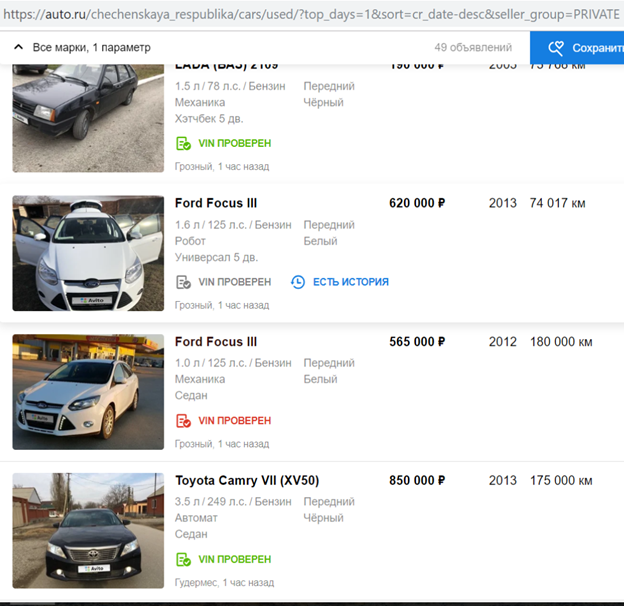
Дообучив свой алгоритм скрытия номерных знаков, чтобы он автоматически детектил и закрывал логотип Авито, они возобновили процесс.

С нашей точки зрения копирование контента конкурентов, использование его в коммерческих целях — неэтично и неприемлемо. Мы получаем жалобы от наших пользователей, которые недовольны этим, в нашу поддержку. А вот пример реакции в одном из сторов.
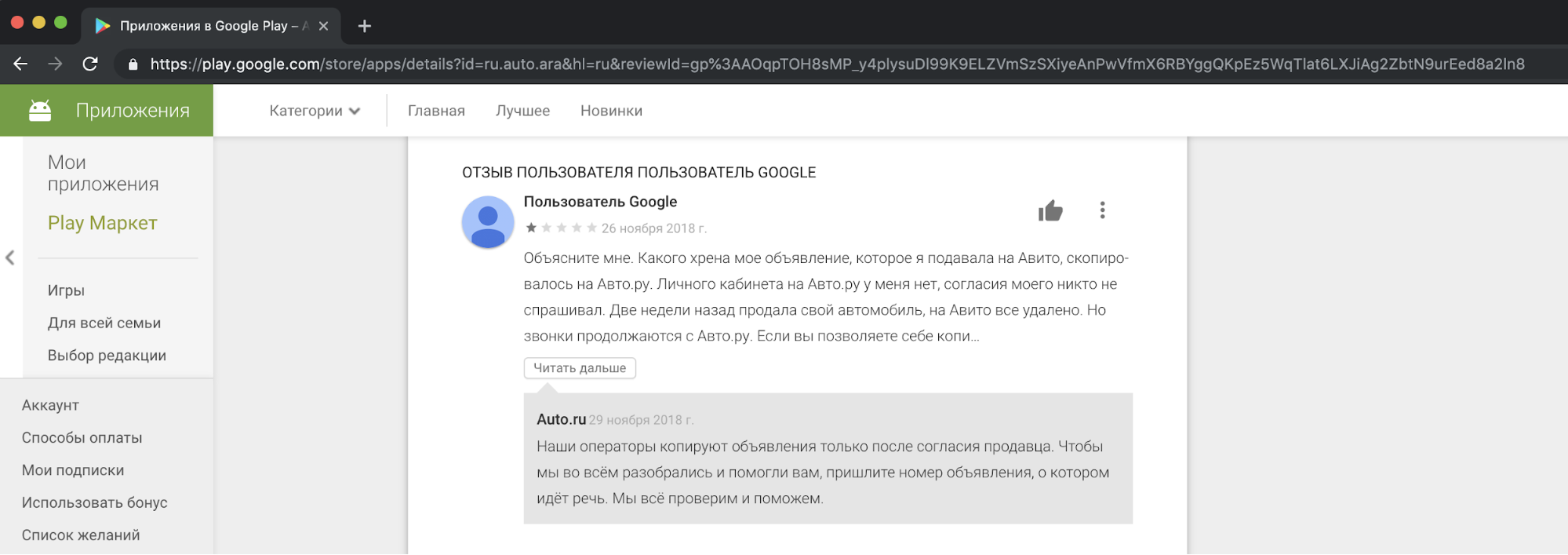
Надо сказать, что запрос согласия людей на копирование объявлений не оправдывает подобные действия. Это нарушение законов «О рекламе» и «О персональных данных», правил Авито, прав на товарные знаки и базу данных объявлений.
Мирно договориться с конкурентом нам не удалось, а оставлять ситуацию как есть мы не хотели.
Первый способ — юридический. Похожие прецеденты уже были в других странах. Например, известный американский классифайд Craigslist отсудил крупные суммы денег у копирующих с него контент сайтов.
Второй способ решения проблемы копирования — добавление большой вотермарки на изображение так, чтобы её нельзя было обрезать.
Третий способ — технологический. Мы можем затруднить процесс копирования нашего контента. Логично предположить, что скрытием логотипа Авито у конкурентов занимается какая-то модель. Также известно, что многие модели подвержены «атакам», которые мешают им работать корректно. В этой статье речь пойдёт как раз про них.

В идеале adversarial example для сети выглядит как шум, неразличимый человеческим глазом, но для классификатора он добавляет достаточный сигнал отсутствующего на картинке класса. В итоге картинка, например, с пандой, с высокой уверенностью классифицируется как гиббон. Создание adversarial шума возможно не только для сетей классификации картинок, но также для сегментации, детекции. Интересный пример — недавняя работа от Keen Labs: они обманули автопилот Tesla точками на асфальте и детектор дождя с помощью отображения как раз такого adversarial шума. Также атаки есть для других доменов, например, звука: известная атака на Amazon Alexa и другие голосовые ассистенты заключалась в проигрывании неразличимых человеческим ухом команд (взломщики предлагали купить что-то на Amazon).
Создание adversarial шума для моделей, анализирующих картинки, возможно благодаря нестандартному использованию градиента, необходимого для обучения модели. Обычно в методе обратного распространения ошибки с помощью вычисляемого градиента целевой функции изменяются только веса слоёв сети, чтобы она меньше ошибалась на обучающем датасете. Так же, как для слоёв сети, можно вычислить градиент целевой функции по входному изображению и изменить его. Изменение входного изображения с помощью градиента применялось для разных известных алгоритмов. Помните Deepdream?

Если мы итеративно вычислим градиент целевой функции по входному изображению и добавим этот градиент к нему, в изображении появится больше информации о превалирующем классе из ImageNet: появляется больше мордочек собак, благодаря чему уменьшится значение лосс функции и модель становится уверенней в классе «собака». Почему в примере именно собаки? Просто в ImageNet из 1000 классов — 120 классов собак. Схожий подход к изменению изображения использовался в алгоритме Style Transfer, известном в основном благодаря приложению Prisma.
Для создания adversarial example тоже можно использовать итеративный метод изменения входного изображения.
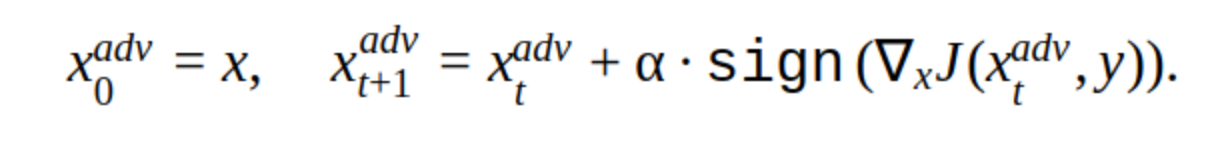
У этого метода существует несколько модификаций, но основная идея проста: исходное изображение итеративно сдвигается в направлении градиента лосс функции классификатора J (потому что используется только знак — sign) с шагом α. «y» — класс, который представлен на изображении, чтобы уменьшить уверенность сети в правильном ответе. Такая атака называется non targeted. Можно подобрать оптимальный шаг и количество итераций, чтобы изменение входного изображения было неотличимо от обычного для человека. Но с точки зрения временных затрат такая атака нам не подходит. 5–10 итераций для одной картинки в проде — это долго.
Альтернативой итеративным методам является метод FGSM.

Это синглшот метод, т.е. для его применения нужно один раз посчитать градиент лосс функции по входному изображению, и adversarial шум для добавления к картинке готов. Такой метод очевидно производительнее. Его можно применить в продакшене.
Начать мы решили с взлома нашей собственной модели.
Так выглядит картинка, которая уменьшает вероятность нахождения номерного знака для нашей модели.

Видно что у этого метода есть недостаток: изменения, которые он добавляет в картинку, заметны глазу. Также этот метод non targeted, но его можно изменить, чтобы сделать направленную атаку. Тогда модель будет предсказывать место для номерного знака в другом месте. Это метод T-FGSM.
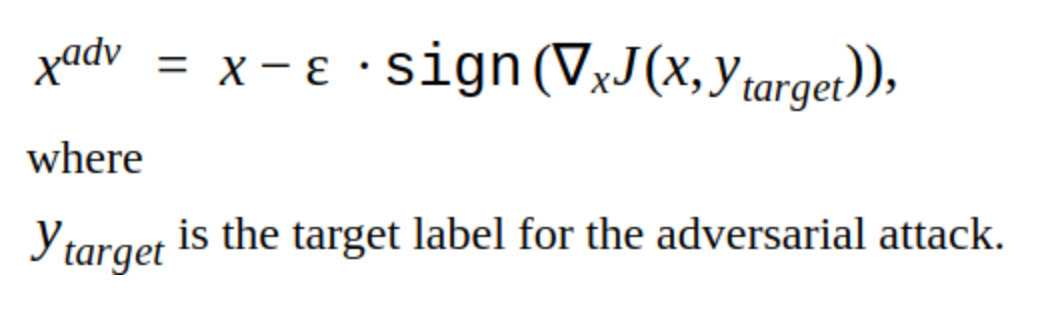
Для того, чтобы этим методом сломать нашу модель, нужно уже чуть заметнее изменить входное изображение.

Пока нельзя сказать, что результаты идеальны, но хотя бы проверена работоспособность методов. Также мы пробовали готовые библиотеки для взлома сетей Foolbox, CleverHans и ART-IBM, но с их помощью не получилось сломать нашу сеть для детекции. Методы, приведенные там, подходят для классификационных сетей лучше. Это общая тенденция во взломе сетей: для object detection сделать атаку сложнее, особенно если речь идёт о сложных моделях, например, Mask RCNN.
Всё, что пока описывалось, не выходило дальше наших внутренних экспериментов, но надо было придумать, как тестировать атаки на детекторах других платформ подачи объявлений.
Оказывается, при подаче объявлений на одну из платформ детекция номерного знака происходит автоматически, так что можно много раз загружать фото и проверять, как алгоритм детекции справляется с новым adversarial example.
Это отлично! Но…
Ни одна из сработавших на нашей модели атак не сработала при тестировании на другой платформе. Почему так произошло? Это следствие различий в моделях и того, насколько плохо обобщаются adversarial attacks на разные архитектуры сетей. Из-за сложности воспроизведения атак их делят на две группы: white box и black box.

Те атаки, которые мы делали на свою модель, — это был white box. То, что нам нужно — это black box с дополнительными ограничениями на инференс: API нет, всё что можно сделать — это вручную загружать фото и проверять атаки. Если бы был API, то можно было сделать substitute model.

Идея заключается в создании датасета входных изображений и ответов black box модели, на которых можно обучить несколько моделей разных архитектур, так чтобы аппроксимировать black box модель. Тогда можно провести white box атаки на эти модели и они с большей вероятностью сработают на black box. В нашем случае это подразумевает много ручной работы, поэтому такой вариант нам не подошёл.
В поисках интересных работ на тему black box атак была найдена статья ShapeShifter: Robust Physical Adversarial Attack on Faster R-CNN Object Detector
Авторы статьи делали атаки на object detection сети self-driving машин с помощью итеративного добавления изображений, отличных от истинного класса, в фон стоп-знака.


Такая атака хороша заметна человеческому глазу, тем не менее, она успешно ломает работу object detection сети, что нам и требуется. Поэтому мы решили пренебречь желаемой невидимостью атаки в угоду работоспособности.
Мы захотели проверить, насколько модель детекции переобучена, использует ли она информацию об автомобиле, или нужна только плашка Авито?
Для этого создали такое изображение:

Загрузили его как машину на платформу объявлений с black box моделью. Получили:

Значит, можно изменять только плашку Авито, остальная информация во входном изображении не является необходимой для детекции модели black box.
После нескольких попыток возникла идея добавления в плашку Авито adversarial шума, полученного методом FGSM, который ломал нашу собственную модель, но с довольно большим коэффициентом ε. Получилось так:

На машине это выглядит так:

Загрузили фото на платформу с black box моделью. Результат оказался успешным.

Применив этот способ к нескольким другим фотографиям, мы выяснили, что он срабатывает не часто. Тогда после нескольких попыток мы решили сосредоточиться на другой самой заметной части номера — границе. Известно, что начальные сверточные слои сети имеют активации на простых объектах вроде линий, углов. «Сломав» линию границы, мы сможем помешать сети корректно обнаружить область номера. Сделать это можно, например, добавив шум в виде белых квадратов случайного размера по всей границе номера.

Загрузив такую картинку на платформу с black box моделью, мы получили успешный adversarial example.

Попробовав этот подход на наборе других картинок, мы выяснили, что black box модель больше не может задетектить плашку Авито (набор собирался вручную, там меньше сотни картинок, и он, разумеется, не репрезентативен, но сделать больше требует много времени). Интересное наблюдение: атака успешна только при комбинировании шума в буквах Avito и рандомных белых квадратов в рамке, использование этих способов по отдельности не даёт успешного результата.
В итоге мы выкатили этот алгоритм в прод, и вот что из этого вышло :)


Что-то посвежее:
Мы даже попали в рекламу платформы:
В итоге у нас получилось сделать adversarial attack, которая в нашей имплементации не увеличивает время обработки изображения. Время, которое мы потратили на создание атаки — две недели перед Новым годом. Если бы не получилось за это время её сделать, то разместили бы вотермарку. Сейчас adversarial номерной знак отключен, потому что теперь конкурент звонит пользователям, предлагает им самим загружать фотографии в объявление или заменяет фото машины на стоковые из интернета.
