Как монорепозиторий изменил жизнь разработчиков «Лаборатории Касперского»?
Некоторое время назад «Лаборатория Касперского» решила перенести свои проекты по разработке в монорепозиторий с общей инфраструктурой. Мы решили поделиться опытом и рассказать, с какими проблемами сталкиваются разработчики в выбранном подходе, и как мы научились их решать.

Почему мы переехали в монорепозиторий?
Ранее «Лаборатория Касперского» выбрала модель разработки со множеством репозиториев. У каждой команды был собственный репозиторий. Многие репозитории имели различные системы контроля версий (например, Perforce, Git, TFS и другие). Чтобы внести изменения в код соседней команды, разработчику приходилось подстраиваться под непривычную систему контроля версий и иные конвенции, что вызывало у него трудности.
Помимо того, что команды жили в своих репозиториях с различными системами контроля версий, многие из них поддерживали собственную сборочную и тестовую инфраструктуры. На это тратились ресурсы каждой команды, а также разработчику, вносящему изменения в чужой репозиторий, приходилось приспосабливаться к другой инфраструктуре.
Количество связей между командами постоянно росло, увеличивалось число взаимных коммитов между репозиториями и одновременных коммитов в несколько репозиториев. Чтобы сократить расходы на поддержку таких связей, мы решили перенести все проекты в общий git-репозиторий и выбрали модель разработки trunk-based development.
Помимо переезда в общий репозиторий, мы решили, что для работы с ним и ради сокращения накладных расходов на поддержку собственной инфраструктуры в командах мы будем делать общую инфраструктуру в проекте Monorepo.
Что из себя представляет Monorepo?
Размер репозитория — около 50 Гб. В него ежедневно делается около 350 пулл-реквестов. А число уникальных контрибьюторов в день — около 150. Эти показатели постоянно увеличиваются, потому что все больше команд переезжает в Monorepo.
Инфраструктура Monorepo — это:
— общий сборочный конвейер Asgard, который компилирует около 75 млн единиц трансляции в день на 7000 процессорных ядер в составе 250 серверов;
— система для запуска тестов Hive, производящая около 13 млн тестовых результатов в день на 8000 виртуальных машин;
— распределенное хранилище артефактов AIR;
— системы для автоматического и ручного анализа результатов тестов Dashboard.
Кроме этого, у нас используется система управления репозиторием и пайплайнами Azure DevOps и есть единая команда поддержки всей этой инфраструктуры.
Также наши разработчики адаптируют сборочную систему bazel для описания сборок.
Как мы организовали разработку в монорепозитории?
При внесении изменений в код разработчик создает пулл-реквест, в нем запускается валидационный билд для проверки его изменений. В этом билде по зависимостям сначала собирается код общих базовых компонентов под различные платформы, а потом под них собираются и тестируются основные продукты компании. При внесении изменений в конкретный продукт система зависимостей не запустит пересборку кода базовых компонентов. Валидационный билд с максимальным путем занимает сейчас приблизительно 2,5 часа.
В нашем представлении сборка или запуск тестов под одну платформу — это одна уникальная задача. Таких задач в валидационном билде — около 150.
С какими проблемами сталкивается разработчик?
Так как многие наши инфраструктурные подсистемы находятся в процессе разработки, в них всплывают различные проблемы, которые вызывают нестабильность валидационного билда. Помимо этого, проблемы возникают и в пользовательском коде — в сборочных скриптах и тестах. Каждая из подсистем инфраструктуры и пользовательский код могут привносить в билд небольшой процент нестабильности, однако суммарно для разработчика это может превратиться в большую нестабильность билда в рамках пулл-реквеста и, как следствие, затруднения при внесении изменений в код.
Как понять, почему упал билд?
Мы хотим, чтобы разработчик решал минимум проблем, которые не связаны с его изменениями. Поэтому мы начали думать о том, чтобы выявлять эти проблемы как можно раньше.
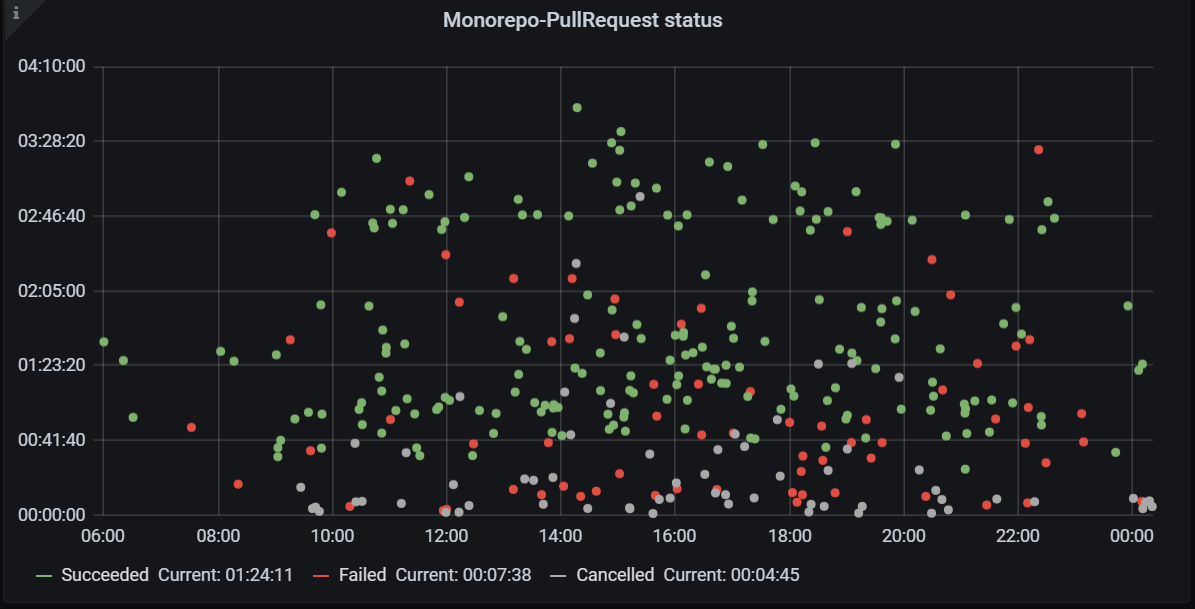 Валидационные билды пулл-реквестов. По вертикали — продолжительность валидационных билдов, по горизонтали — время. Зеленым отмечены успешные билды, красным — неуспешные, серым — отмененные
Валидационные билды пулл-реквестов. По вертикали — продолжительность валидационных билдов, по горизонтали — время. Зеленым отмечены успешные билды, красным — неуспешные, серым — отмененные Мы начали смотреть на валидационные билды, которые запускаются в пулл-реквесте. При большом количестве красных точек, как на графике выше, сложно определить, привнесена ли проблема изменениями, сделанными в пулл-реквесте, не посмотрев логи и не разобравшись в проблеме.
Чтобы отделить проблемы, привнесенные в пулл-реквестах, от ломающих и нестабильных проблем валидационного билда, мы решили запускать валидационный билд пулл-реквеста каждый час по ветке master. В идеальном случае, если нет никаких ломающих и нестабильных проблем, такой билд должен быть всегда зеленым. Однако оказалось, что это не всегда так.
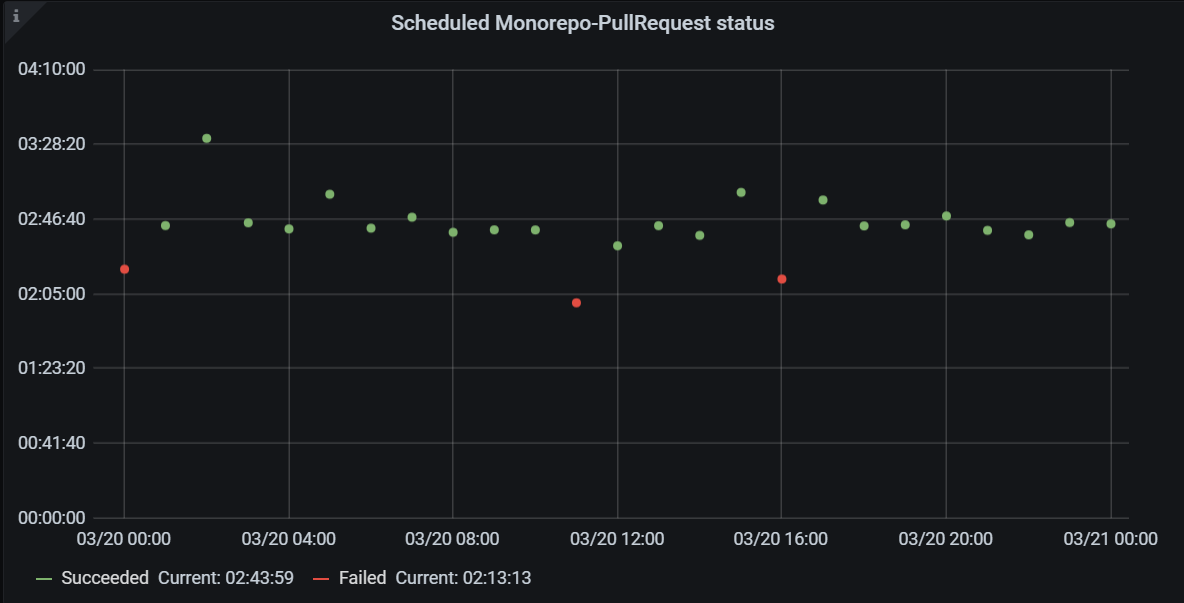 Запуски валидационного билда по расписанию. По вертикали — продолжительность валидационных билдов, по горизонтали — время. Зеленым отмечены успешные билды, красным — неуспешные
Запуски валидационного билда по расписанию. По вертикали — продолжительность валидационных билдов, по горизонтали — время. Зеленым отмечены успешные билды, красным — неуспешныеТаким образом мы поняли, что билд по расписанию — это «показатель здоровья» Monorepo. Во-первых, он помогает предотвратить проблемы на ранней стадии: мы видим проблему не в пулл-реквестах разработчиков, а на синтетической метрике, заводим инцидент и разбираемся с ним. Во-вторых, такой билд легко мониторить, потому что не нужно разбираться, связано ли это с изменениями в пулл-реквесте разработчика, поэтому по ошибке данного билда легко найти ответственных. Кроме того, видны глобальные проблемы на билде по расписанию: если падает несколько билдов с одной и той же проблемой — вероятнее всего, возникла глобальная проблема. Наконец, для каждой ошибки такого валидационного билда у нас есть инцидент — баг.
Как мы систематизируем проблемы?
Валидационные билды по master’у у нас запускаются каждый час. Если билд покраснел, мы заводим инцидент. Далее мы разбираемся, почему упал тот или иной билд, и за каждый красный билд пулл-реквеста по master’у мы находим ответственного — подсистему, из-за которой возникло падение.
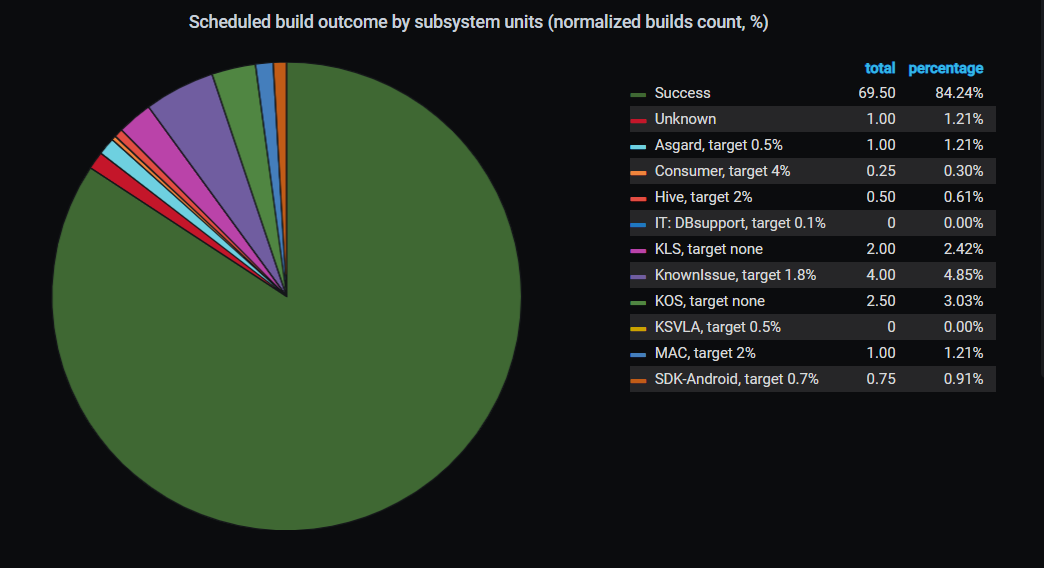 Статистика распределения падений билда по расписанию по подсистемам
Статистика распределения падений билда по расписанию по подсистемамБлагодаря тому, что мы научились искать ответственных за падение валидационных билдов пулл-реквеста по расписанию, мы смогли строить различные статистики. Например, мы можем увидеть, кто больше виноват в падениях валидационного билда и над какими подсистемами сейчас нужно работать.
В итоге с момента введения этой метрики в октябре 2019 года мы добились того, что к февралю 2021 года количество проходящих билдов по расписанию увеличилось с 55.31% до 81.1%. А значит, увеличилась и стабильность валидационного билда в пулл-реквесте.
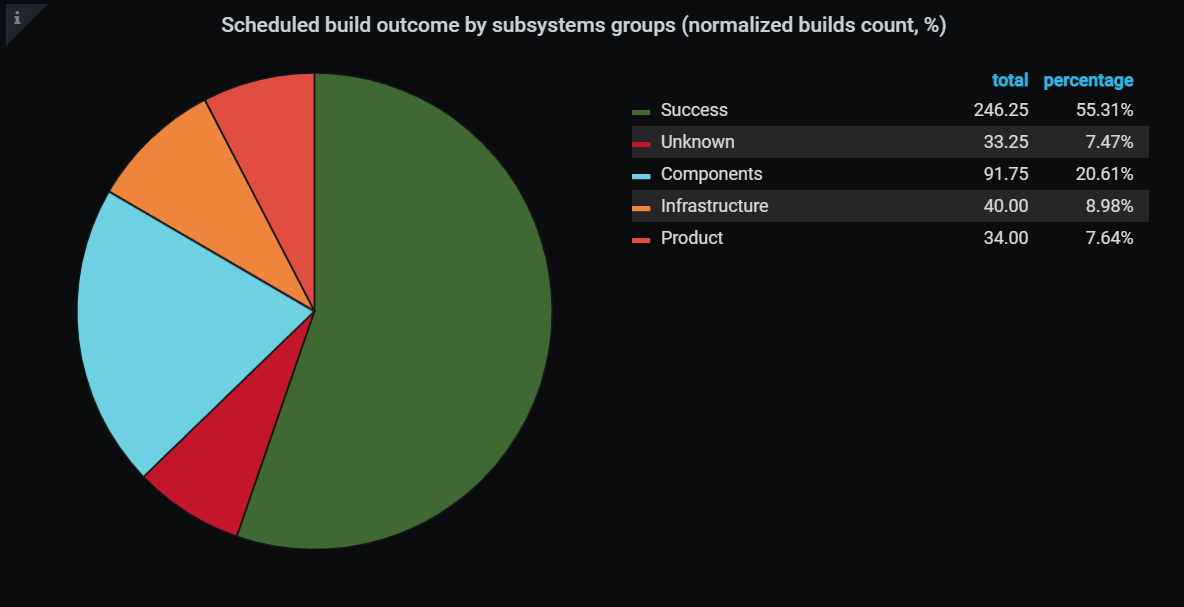 Доля успешных билдов по расписанию в октябре 2019 года была 55.31%
Доля успешных билдов по расписанию в октябре 2019 года была 55.31%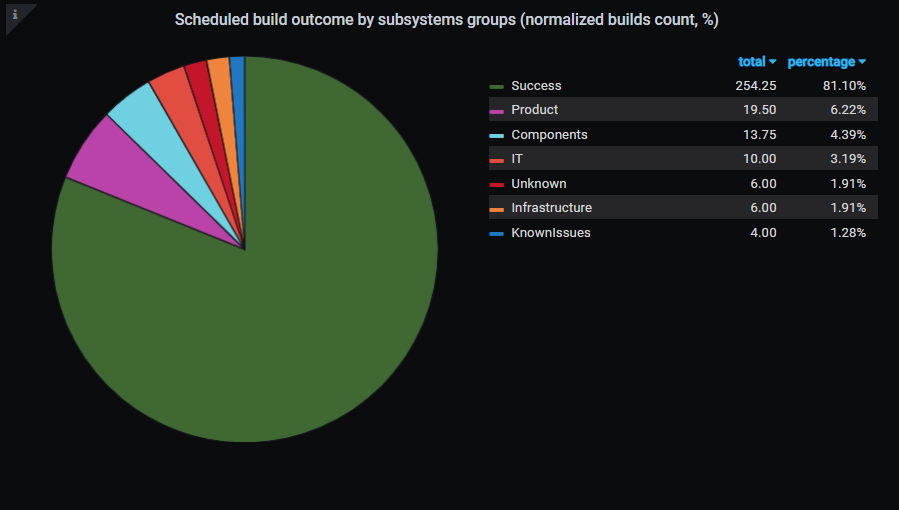 Доля успешных билдов по расписани в мае 2021 достигала 81.1%
Доля успешных билдов по расписани в мае 2021 достигала 81.1%Как разработчик узнает, из-за чего упал билд?
Помимо того, что мы научились мониторить проблемы на синтетическом билде, нам необходимо уведомить разработчика о существовании проблемы, обозначить статус решения проблемы, ускорить перезапуск билда. Для этих целей нами был создан робот Thor — хранитель пулл-реквеста.
Thor умеет отслеживать глобальные проблемы — те, которые не решатся даже при перезапуске валидационного билда (например, если в репозитории появились несовместимые коммиты или проблема возникла из-за обновления инфраструктуры). Когда Thor видит глобальные проблемы, он ставит на паузу валидационный билд, сообщает в каждом пулл-реквесте разработчиков, что билд находится на паузе, и прилагает ссылку на инцидент. В результате каждый разработчик может посмотреть, кто разбирается с проблемой, и увидеть прогноз по срокам решения. Когда проблема решена, инцидент закрывается, билд снимается с паузы и Thor планомерно перезапускает упавшие билды.
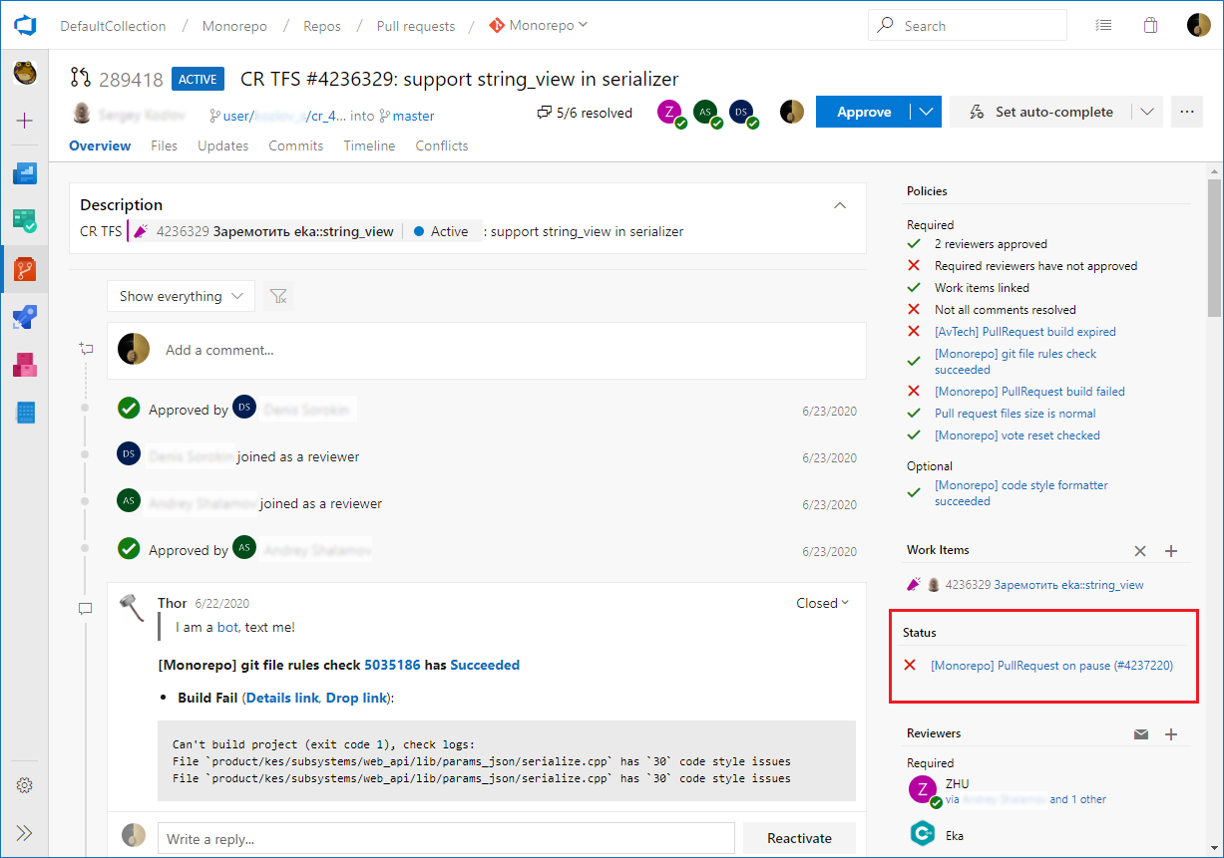 Пример пулл-реквеста разработчика, в котором валидационный билд стоит на паузе
Пример пулл-реквеста разработчика, в котором валидационный билд стоит на паузеThor также умеет обрабатывать нестабильности — проблемы, которые решаются перезапуском валидационного билда (например, гонки в сборочной процедуре, флакающие тесты, нестабильности в инфраструктуре). Если одна и та же проблема воспроизводится на нескольких независимых пулл-реквестах разработчиков, то мы заводим на это инцидент и начинаем решать проблему. При каждом падении валидационного билда в пулл-реквесте разработчика Thor проверяет, заведен ли инцидент по этой проблеме, и дает под текстом ошибки валидационного билда в пулл-реквесте разработчика ссылку на инцидент, сообщая, когда он перезапустит валидационный билд. Благодаря этой функции разработчик может не тратить свое время на анализ этих проблем и перезапуск билда. Таким образом, около 69% билдов, упавших по причине нестабильности, мы перезапускаем автоматически.
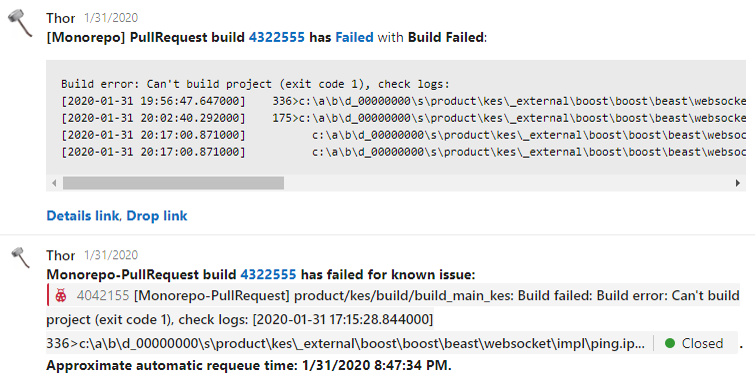 Пример сообщения о перезапуске билда
Пример сообщения о перезапуске билдаКроме того, Thor еще и бот. Его можно призвать в пулл-реквест на помощь, запустить расширенные сборки и тесты. Разработчики могут воспользоваться еще рядом мелких возможностей.
Помимо обработки ошибок, Thor помогает разработчикам разбираться с проблемами, которые они привнесли, делая изменения в своем пулл-реквесте. При падении валидационного билда робот сообщает непосредственно в пулл-реквест, какая произошла ошибка, и дает прямую ссылку на артефакты. Кликнув на эту ссылку, разработчик может сразу начать разбираться с проблемой и не тратить время на ее поиск.
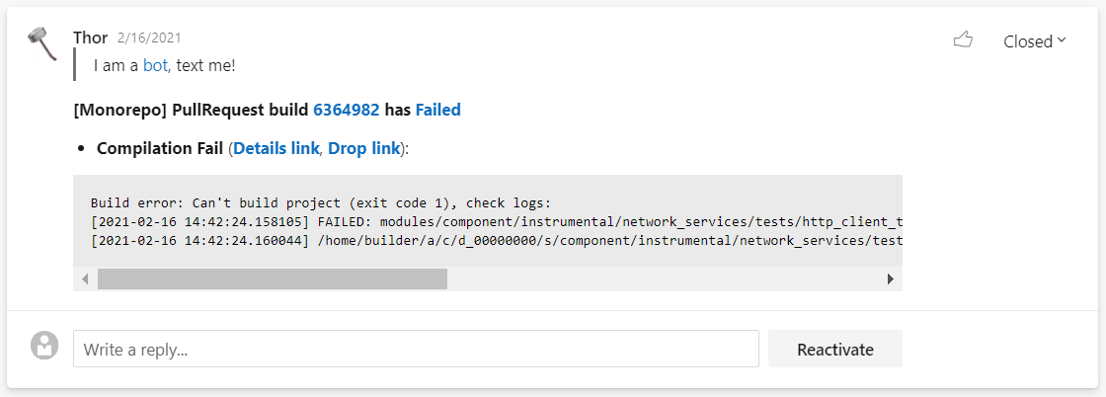 Пример сообщения об ошибке в пулл-реквесте
Пример сообщения об ошибке в пулл-реквестеМелочь, а приятно!
Для наших разработчиков мы стали автоматически перезапускать expired-билды. Сейчас в нашем репозитории время экспирации билда составляет 24 часа: даже если билд был успешным, но разработчик не успел закомплитить пулл-реквест за 24 часа, то билд экспайрится. То есть если разработчик делает пулл-реквеста в пятницу, то в понедельник его придется перезапускать и ждать, пока билд пройдет. Мы автоматизировали этот процесс и стали перезапускать протухшие билды разработчиков в выходные.
Как мы повышаем стабильность валидационного билда
Мы боремся с нестабильностью тестов в пулл-реквестах, тем самым повышая стабильность валидационного билда. Под нестабильностью тестов мы понимаем различные результаты теста при запуске по одной сборке.
У нас есть механизм flaky-тестов. Любой тест можно пометить как flaky, при этом к тесту линкуется инцидент, в рамках которого проблему с тестом будут решать. Если при запуске билда в нем упадет flaky-тест, то билд все равно будет считаться успешным. После решения инцидента, в рамках которого разбирались с нестабильностью этого теста, flaky снимается, и тест переходит в блокирующий режим.
 Пример тестов, помеченных как flaky
Пример тестов, помеченных как flakyПометку flaky можно сделать как вручную, так и автоматически. Если в различных пулл-реквестах разработчиков тест падает по одной и той же проблеме, то этот тест мы считаем нестабильным, и он автоматически помечается как flaky. Благодаря тому, что часть тестов помечена как flaky, около 4% от всех билдов проходят успешно.
Таймлайн для удобства разработчиков
Чтобы было удобно отследить весь жизненный цикл пулл-реквеста, мы сделали таймлайн. В нем видны перезапуски валидационных билдов, причины падения, какие были паузы за время, пока длился пулл-реквест, сколько длилось код-ревью. Каждый разработчик может посмотреть и разобраться, почему его пулл-реквест долго заходил и какие проблемы с ним возникали.
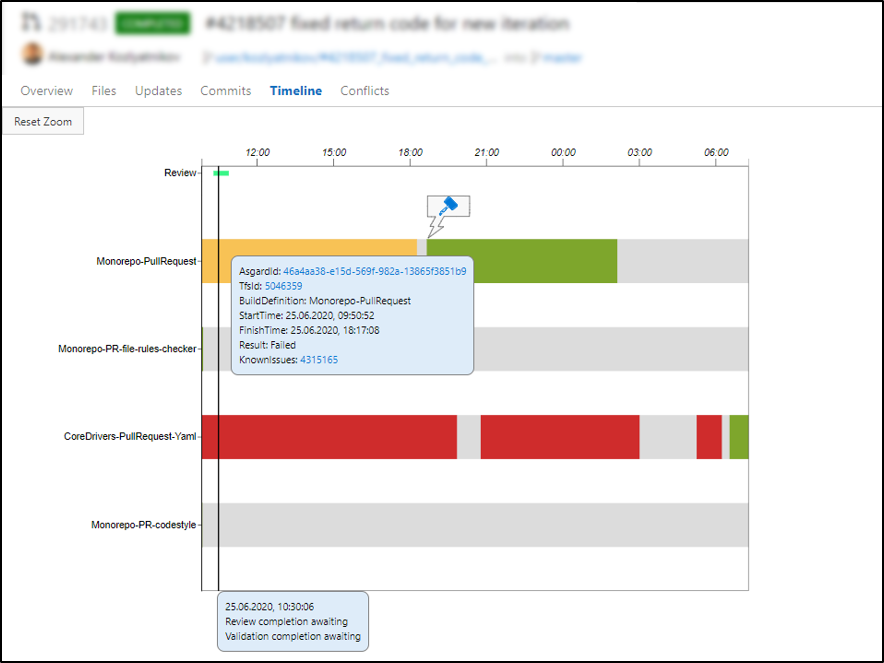 Таймлайн пулл-реквеста
Таймлайн пулл-реквеста Как измерить удовлетворенность разработчиков?
Мы все измеряем и принимаем решения на основе данных. В том числе измеряем и удовлетворенность разработчика. Мы считаем количество перезапусков валидационных билдов после последнего коммита в ветку пулл-реквеста до его завершения.
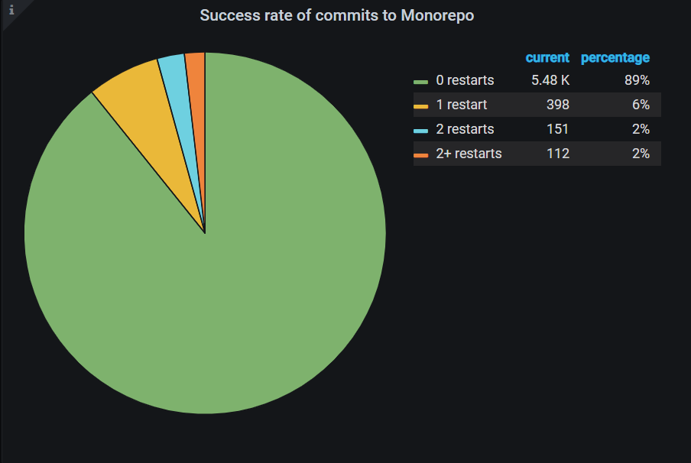 Статистика удовлетворенности разработчиков. Доля коммитов без перезапусков билда достигла 89%
Статистика удовлетворенности разработчиков. Доля коммитов без перезапусков билда достигла 89%В идеальном случае, когда разработчик делает последний апдейт в своем пулл-реквесте, у него запускается валидационный билд, который должен стать зеленым с первого раза. Однако если после последнего апдейта валидационный билд сначала был красным, а после какого-то количества ретраев стал зеленым без изменения кода, то в подобном случае с большой вероятностью красные валидационные билды упали из-за нестабильности. В статистике отражены процент пулл-реквестов, завершенных без ретраев, с одним ретраем, с двумя и более после последнего апдейта. Мы считаем, что чем больше пулл-реквестов, зашедших без ретраев, тем больше удовлетворены разработчики.
Мы продолжим развивать наши инструменты и инфраструктуру, а значит, улучшать удовлетворенность разработчиков и сохранять их спокойствие.
О проекте Monorepo
