Как масштабировать дата-центры. Доклад Яндекса
Мы разработали дизайн сети дата-центров, который позволяет разворачивать вычислительные кластеры размером больше 100 тысяч серверов с пиковой полосой бисекции (bisection bandwidth) свыше одного петабайта в секунду.
Из доклада Дмитрия Афанасьева вы узнаете об основных принципах нового дизайна, масштабировании топологий, возникающих при этом проблемах, вариантах их решения, об особенностях маршрутизации и масштабирования функций forwarding plane современных сетевых устройств в «плотных» (densely connected) топологиях с большим числом ECMP-маршрутов. Кроме того, Дима коротко рассказал об организации внешней связности, физическом уровне, кабельной системе и способах дальнейшего увеличения емкости.

— Всем добрый день! Меня зовут Дмитрий Афанасьев, я сетевой архитектор Яндекса и занимаюсь преимущественно дизайном сетей дата-центров.
Мой рассказ будет об обновленной сети дата-центров Яндекса. Это в значительной степени эволюция дизайна, который у нас был, но в то же время есть и некоторые новые элементы. Это обзорная презентация, поскольку нужно было уместить достаточно много информации в небольшое время. Мы начнем с выбора логической топологии. Затем будет обзор control plane и проблем с масштабируемостью data plane, выбор того, что будет происходить на физическом уровне, посмотрим на некоторые особенности устройств. Немного затронем и происходящее в дата-центре с MPLS, про который мы говорили некоторое время назад.

Итак, что же такое Яндекс с точки зрения нагрузок и сервисов? Яндекс — типичный гиперскейлер. Если смотреть в сторону пользователей, у нас происходит в первую очередь обработка пользовательских запросов. Также различные стриминг-сервисы и отдача данных, потому что storage-сервисы у нас тоже есть. Если ближе к бэкенду, то там появляются инфраструктурные нагрузки и сервисы, такие как распределенные объектные хранилища, репликация данных и, конечно же, persistent queues. Один из основных типов нагрузок — MapReduce и тому подобные системы, потоковая обработка, machine learning и т. д.

Как устроена инфраструктура, поверх которой это все происходит? Опять же, мы вполне типичный гиперскейлер, хотя, возможно, находимся немножко ближе к той стороне спектра, где находятся гиперскейлеры поменьше. Но у нас есть все атрибуты. Мы используем commodity hardware и горизонтальное масштабирование везде, где можно. У нас в полный рост присутствует пулинг ресурсов: мы не работаем с отдельными машинами, отдельными стойками, а объединяем их в большой пул взаимозаменяемых ресурсов с какими-то дополнительными сервисами, которые занимаются планированием и аллокацией, и работаем со всем этим пулом.
Так у нас возникает следующий уровень — операционной системы уровня вычислительного кластера. Очень важно, что мы полностью контролируем стек технологий, который у нас используется. Мы контролируем энд-поинты (хосты), сеть и программный стек.
У нас есть несколько крупных дата-центров в России и за рубежом. Их объединяет backbone, использующий технологию MPLS. Наша внутренняя инфраструктура практически полностью построена на IPv6, но поскольку нам нужно обслуживать внешний трафик, все еще поступающий в основном по IPv4, мы должны как-то доставлять запросы, приходящие по IPv4, до фронтенд-серверов, и немножко еще ходить во внешний IPv4-интернет — например, для индексирования.
Последние несколько итераций дизайна сетей дата-центров используют многоуровневые Clos-топологии, и в них применяется только L3. Мы ушли от L2 некоторое время назад и вздохнули с облегчением. Наконец, наша инфраструктура включает сотни тысяч вычислительных (серверных) инстансов. Максимальный размер кластера некоторое время назад был порядка 10 тыс. серверов. Это обусловлено в значительной степени тем, как могут работать те самые операционные системы уровня кластера, планировщики, аллокация ресурсов и т. п. Поскольку на стороне инфраструктурного софта случился прогресс, то сейчас целевым является размер порядка 100 тыс. серверов в одном вычислительном кластере, и у нас возникла задача — уметь строить сетевые фабрики, которые позволяют эффективно осуществлять пулинг ресурсов в таком кластере.

Что же мы хотим от сети дата-центра? В первую очередь — много дешевой и достаточно однородно распределенной полосы пропускания. Потому что сеть — это та подложка, за счет которой мы можем делать пулинг ресурсов. Новый целевой размер — порядка 100 тыс. серверов в одном кластере.
Также нам, конечно, хочется масштабируемый и стабильный control plane, потому что на такой большой инфраструктуре достаточно много головной боли возникает даже от просто случайных событий, и мы не хотим, чтобы нам приносил головную боль еще и control plane. При этом мы хотим минимизировать состояние в нем. Чем меньше состояние, тем лучше и стабильнее все работает, проще диагностировать.
Конечно, нам нужна автоматизация, потому что вручную управлять такой инфраструктурой невозможно, и невозможно было уже некоторое время назад. Нам нужна по возможности поддержка операционной деятельности и поддержка CI/CD, насколько это можно обеспечить.
При таких размерах дата-центров и кластеров уже достаточно остро встала задача поддержки инкрементального развертывания и расширения без перерыва сервиса. Если на кластерах размером в тысячу машин, возможно, близко к десятку тысяч машин, их еще можно было выкатывать как одну операцию — то есть мы планируем расширение инфраструктуры, и несколько тысяч машин добавляются как одна операция, то кластер размером под сто тысяч машине не возникает сразу таким, он строится в течение некоторого времени. И желательно, чтобы все это время то, что уже выкачено, та инфраструктура, которая развернута, была доступна.
И одно требование, которое у нас было и ушло: это поддержка multitenancy, то есть виртуализации или сегментирования сети. Теперь нам не нужно это делать на уровне сетевой фабрики, потому что сегментирование ушло на хосты, и это нам очень облегчило масштабирование. Благодаря IPv6 и большому адресному пространству нам не нужно было во внутренней инфраструктуре использовать дублирующиеся адреса, вся адресация была и так уникальная. А благодаря тому, что мы фильтрацию и сегментирование сети унесли на хосты, нам не нужно создавать какие-то виртуальные сетевые сущности в датацентровых сетях.

Очень немаловажная вещь — это то, что нам не нужно. Если какие-то функции можно убрать из сети, это сильно облегчает жизнь, и, как правило, расширяет выбор доступного оборудования и программного обеспечения, очень упрощает диагностику.
Итак, что же нам не нужно, от чего мы смогли отказаться, не всегда с радостью в момент, когда это происходило, но с большим облегчением, когда процесс завершался?
В первую очередь, отказ от L2. Нам не нужен L2 ни реальный, ни эмулированный. Не используется в значительной степени благодаря тому, что мы контролируем стек приложений. Наши приложения горизонтально масштабируются, они работают с L3 адресацией, они не очень беспокоятся, что какой-то отдельный инстанс погас, просто выкатывают новый, ему не нужно выкатываться на старом адресе, потому что есть отдельный уровень service discovery и мониторинга машин, находящихся в кластере. Мы не перекладываем эту задачу на сеть. Задача сети — доставлять пакеты из точки А в точку Б.
Также у нас нет ситуаций, когда адреса передвигаются внутри сети, и это нужно отслеживать. Во многих дизайнах это, как правило, нужно, чтобы поддерживать VM mobility. Мы не используем мобильность виртуальных машин во внутренней инфраструктуре именно большого Яндекса, и, кроме того, считаем, что, даже если это делается, это не должно происходить с поддержкой сети. Если очень нужно сделать, это нужно делать на уровне хостов, и загонять адреса, которые могут мигрировать, в оверлеи, чтобы не трогать и не вносить слишком много динамических изменений в систему маршрутизации собственно underlay (транспортной сети).
Еще одна технология, которую мы не используем — это мультикаст. Желающим могу подробно рассказать, почему. Это сильно облегчает жизнь, потому что, если кто-то имел с ним дело и смотрел, как выглядит именно control plane мультикаста — во всех инсталляциях, кроме самых простых, это большая головная боль. И более того, трудно найти хорошо работающую открытую реализацию, например.
И наконец, мы проектируем наши сети так, чтобы в них не происходило слишком много изменений. Мы можем рассчитывать на то, что поток внешних событий в системе маршрутизации невелик.

Какие возникают проблемы и какие ограничения надо учитывать, когда мы разрабатываем сеть дата-центра? Стоимость, конечно. Масштабируемость, то, до какого уровня мы хотим расти. Необходимость расширения без остановки сервиса. Полоса пропускания, доступность. Видимость того, что происходит в сети, для систем мониторинга, для операционных команд. Поддержка автоматизации — опять же, настолько, насколько это возможно, поскольку разные задачи могут решаться на разных уровнях, в том числе введением дополнительных прослоек. Ну и не-[по-возможности]-зависимость от вендоров. Хотя в разные исторические периоды, в зависимости от того, на какой срез смотреть, эта независимость была легче или труднее достижима. Если возьмем срез чипов сетевых устройств, то до последнего времени говорить о независимости от вендоров, если мы хотели еще и чипы с большой пропускной способностью, можно было очень условно.

По какой же логической топологии мы будем строить нашу сеть? Это будет многоуровневый Clos. На самом деле, реальных альтернатив на настоящий момент нет. И Clos-топология достаточно хороша, даже если ее сравнивать с различными продвинутыми топологиями, которые больше сейчас находятся в сфере академического интереса, если у нас есть коммутаторы с большим радиксом.
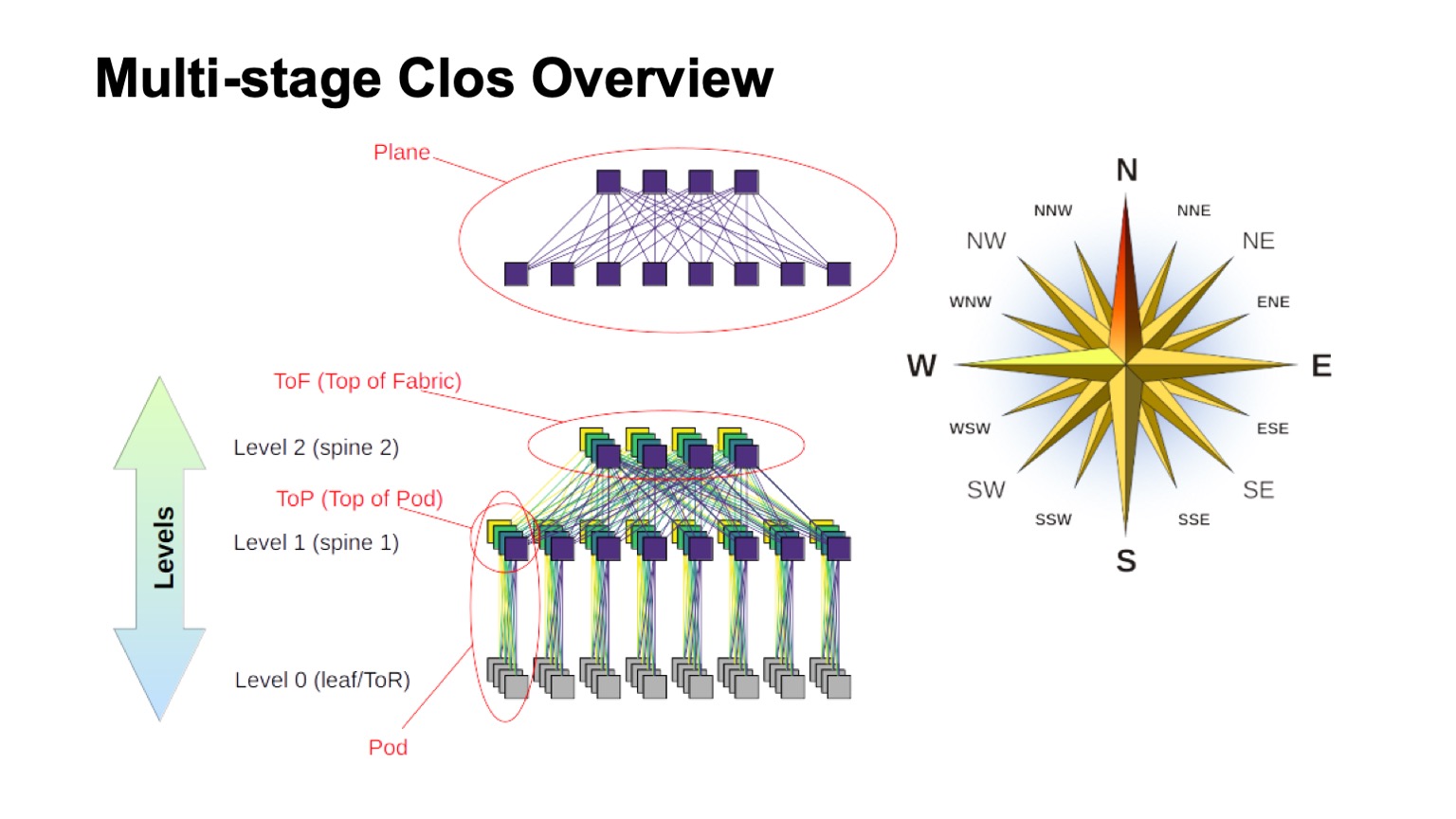
Как примерно устроена многоуровневая Clos-сеть и как в ней называются различные элементы? В первую очередь, роза ветров, чтобы сориентироваться, где север, где юг, где восток, где запад. Сети такого типа обычно строят те, у кого очень большой трафик запад — восток. Что касается остальных элементов, вверху изображен виртуальный коммутатор, собранный из коммутаторов поменьше. Это основная идея рекурсивного построения Clos-сетей. Мы берем элементы с каким-то радиксом и соединяем их так, чтобы то, что получилось, можно было рассматривать как коммутатор с радиксом побольше. Если нужно еще больше, процедуру можно повторить.
В случаях, например, с двухуровневыми Clos, когда можно четко выделить компоненты, которые на моей схеме вертикальные, их принято называть плоскостями. Если бы мы строили Clos-с тремя уровнями спайн-свитчей (все, которые не граничные и не ToR-свитчи и которые используются только для транзита), то плоскости выглядели бы сложнее, двухуровневые выглядят именно так. Блок ToR- или leaf-свитчей и ассоциированные с ними спайн-свитчи первого уровня мы называем Pod. Спайн-свитчи уровня спайн-1 вверху Pod — это top of Pod, вершина Pod. Свитчи, которые располагаются вверху всей фабрики — это верхний слой фабрики, Top of fabric.

Конечно, возникает вопрос: Clos-сети строятся уже некоторое время, сама идея вообще происходит из времен классической телефонии, TDM-сетей. Может, появилось что-то получше, может, можно как-то получше сделать? И да, и нет. Теоретически да, на практике в ближайшее время точно нет. Потому что есть некоторое количество интересных топологий, часть из них даже используется в продакшене, например, Dragonfly используется в HPC-приложениях; есть также интересные топологии типа Xpander, FatClique, Jellyfish. Если посмотреть доклады на конференциях типа SIGCOMM или NSDI за последнее время, можно обнаружить довольно большое количество работ по альтернативным топологиям, обладающим лучшими свойствами (теми или иными), чем Clos.
Но у всех этих топологий есть одно интересное свойство. Оно препятствует их внедрению в сетях дата-центров, которые мы пытаемся строить на commodity hardware и которые стоят достаточно разумных денег. Во всех этих альтернативных топологиях большая часть полосы, к сожалению, доступна не по кратчайшим путям. Поэтому мы сразу лишаемся возможности использовать традиционный control plane.
Теоретически решение задачи известно. Это, например, модификации link state с использованием k-shortest path, но, опять же, нет таких протоколов, которые были бы реализованы в продакшене и массово доступны на оборудовании.
Более того, поскольку большая часть емкости доступна не по кратчайшим путям, нам нужно модифицировать не только control plane, чтобы он выбирал все эти пути (и, кстати, это значительно большее состояние в control plane). Нам еще нужно модифицировать forwarding plane, и, как правило, требуется как минимум две дополнительных фичи. Это возможность принимать все решения о форвардинге пакетов разово, например, на хосте. Фактически это source routing, иногда в литературе по interconnection networks это называется all-at-once forwarding decisions. И еще adaptive routing — это уже функция, нужная нам на сетевых элементах, сводящаяся, например, к тому, что мы выбираем следующий хоп, исходя из информации о наименьшей загрузке очереди. Как пример, возможны другие варианты.
Таким образом, направление интересное, но, увы, прямо сейчас применить не можем.

Окей, остановились на логической топологии Clos. Как мы ее будем масштабировать? Давайте посмотрим, как она устроена и что можно сделать.

В Clos-сети есть два основных параметра, которые мы можем как-то варьировать и получать те или иные результаты: radix элементов и количество уровней в сети. У меня схематически изображено, как то и другое влияет на размер. В идеале комбинируем и то, и другое.
Видно, что итоговая ширина Clos-сети — это произведение по всем уровням спайн-свитчей южного радикса, то, сколько линков у нас есть вниз, как она ветвится. Вот как мы масштабируем размер сети.
Что касается емкости, особенно на ToR-свитчах, тут два варианта масштабирования. Либо можем, сохраняя общую топологию, использовать более скоростные линки, либо можем добавлять большее количество плоскостей.
Если посмотеть на развернутый вариант Clos-сети (в правом нижнем углу) и вернуться к этой картинке с Clos-сетью внизу…
… то это ровно одна и та же топология, но на этом слайде она схлопнута более компактно и плоскости фабрики наложены друг на друга. Это одно и то же.

Как выглядит масштабирование Clos-сети в числах? Здесь у меня приводятся данные, какой максимальной ширины можно получить сеть, какое максимальное количество стоек, ToR-свитчей или leaf-свитчей, если они не находятся в стойках, мы можем получить в зависимости от того, какой у нас радикс свитчей, используемых для спайн-уровней, и сколько уровней мы используем.
Тут приведено, сколько у нас может быть стоек, сколько серверов и примерно сколько это все может потреблять из расчета 20 кВт на стойку. Немного раньше я упоминал, что мы целимся в размер кластера порядка 100 тыс. серверов.
Видно, что во всей этой конструкции интерес представляют два с половиной варианта. Есть вариант с двумя слоями спайнов и 64-портовыми свитчами, который немного недотягивает. Потом отлично вписывающиеся варианты для 128-портовых (с радиксом 128) спайн-свитчей с двумя уровнями, либо свитчи с радиксом 32 с тремя уровнями. И во всех случаях, где больше радикс и больше уровней, можно сделать очень большую сеть, но если вы посмотрите на ожидаемое потребление, как правило, там гигаватты. Кабель проложить можно, а столько электричества на одной площадке мы вряд ли получим. Если посмотреть статистику, публичные данные по дата-центрам — очень мало можно найти дата-центров на расчетную мощность больше 150 МВт. То что больше — как правило, дата-центровые кампусы, несколько крупных дата-центров, расположенных достаточно близко друг к другу.
Есть еще важный параметр. Если посмотрите на левую колонку, там указан usable bandwidth. Нетрудно заметить, что в Clos-сети заметная часть портов уходит на то, чтобы соединять коммутаторы друг с другом. Usable bandwidth, полезная полоса, — это то, что можно отдать наружу, в сторону серверов. Естественно, я говорю об условных портах и именно о полосе. Как правило, линки внутри сети побыстрее, чем линки в сторону серверов, но на единицу полосы, насколько мы ее можем выдать наружу к нашему серверному оборудованию, приходится еще сколько-то полосы внутри самой сети. И чем больше уровней мы делаем, тем больше удельные расходы на то, чтобы предоставить эту полосу наружу.
Более того, даже эта дополнительная полоса не совсем одинаковая. Пока пролеты короткие, мы можем использовать что-нибудь типа DAC (direct attach copper, то есть twinax-кабели), или multimode оптики, которые еще более-менее разумных денег стоят. Как только мы переходим на пролеты подлиннее — как правило, это single mode оптика, и стоимость этой дополнительной полосы заметно возрастает.
И опять же, возвращаясь на предыдущий слайд, если мы делаем Clos-сеть без переподписки, то нетрудно посмотреть на схему, посмотреть, как строится сеть — добавляя каждый уровень спайн-свитчей, мы повторяем всю ту полосу, которая была внизу. Плюс уровень — плюс вся та же полоса, еще столько же, сколько было на предыдущем уровне, портов на коммутаторах, еще столько же трансиверов. Поэтому количество уровней спайн-свитчей очень желательно минимизировать.
Исходя из этой картинки, видно, что нам очень хочется строиться на чем-то типа свитчей с радиксом 128.

Здесь в принципе все то же самое, что я сейчас рассказал, это слайд скорее для рассмотрения потом.

Какие есть варианты, что мы можем выбрать в качестве таких коммутаторов? Очень приятное для нас известие, что сейчас такие сети наконец-то стало можно строить на одночиповых коммутаторах. И это очень здорово, у них масса приятных особенностей. Например, у них почти отсутствует внутренняя структура. Это значит, что они проще ломаются. Они ломаются, куда без этого, но ломаются, по счастью, целиком. В модульных устройствах есть большое количество неисправностей (очень неприятных), когда с точки зрения соседей и control plane оно вроде бы работает, но, например, у него ушла часть фабрики, и оно работает не на полную емкость. А трафик на него балансируется исходя из того, что оно полностью функциональное, и мы можем получить перегрузку.
Или, например, возникают проблемы с бэкплейном, потому что внутри модульного устройства тоже есть высокоскоростные SerDes-ы — оно по-настоящему сложно внутри устроено. Или у него синхронизируются или не синхронизируются таблички между forwarding элементами. В общем, любое производительное модульное устройство, состоящее из большого количества элементов, внутри себя, как правило, содержит все ту же Clos-сеть, только которую очень трудно диагностировать. Зачастую даже самому вендору трудно диагностировать.
И оно имеет большое количество сценариев сбоев, при которых устройство деградирует, но не выпадает из топологии полностью. Поскольку у нас сеть большая, активно используется балансировка между идентичными элементами, сеть очень регулярная, то есть один путь, на котором все в порядке, ничем не отличается от другого пути, нам выгоднее просто потерять часть устройств из топологии, чем попадать на ситуацию, когда некоторые из них вроде бы работают, а вроде нет.

Следующая приятная особенность одночиповых устройств — они лучше эволюционируют, быстрее. Также они, как правило, имеют лучшую емкость. Если брать большие собранные конструкции, которые у нас есть, на круг, то емкость на рэк-юнит по портам той же скорости получается почти в два раза лучше, чем у модульных устройств. Устройства, построенные вокруг одного чипа, получаются заметно дешевле, чем модульные, и потребляют меньше энергии.
Но, конечно же, это все не просто так, есть и недостатки. Во-первых, практически всегда меньший радикс, чем у модульных устройств. Если мы можем устройство, вокруг одного чипа построенное, получить на 128 портов, то модульное мы можем получить на несколько сотен портов сейчас уже без особых проблем.
Это заметно меньший размер форвардинг таблиц и, как правило, всего, что касается масштабируемости data plane. Неглубокие буфера. И, как правило, довольно ограниченная функциональность. Но выясняется, что если знать эти ограничения и вовремя позаботиться о том, чтобы их обойти или просто учесть, то это не так страшно. То, что радикс меньше, на появившихся недавно, наконец, устройствах с радиксом 128 проблемой уже не является, мы можем построиться в два слоя спайнов. А меньше двух ничего интересного для нас размера построить все равно нельзя. С одним уровнем совсем мелкие кластеры получаются. Даже предыдущие наши дизайны и требования все равно их превышали.
На самом деле, если вдруг решение где-то на грани, есть еще способ смасштабироваться. Поскольку последний (или первый), самый нижний уровень, куда подключаются сервера — ToR-свитчи или leaf-свитчи, мы не обязаны подключать к ним одну стойку. Поэтому если решение недотягивает где-то в два раза, можно подумать о том, чтобы просто использовать коммутатор с большим радиксом на нижнем уровне и подключать, например, две-три стойки в один коммутатор. Это тоже вариант, у него есть свои издержки, но он вполне работает и может оказаться неплохим решением, когда нужно дотянуть где-то в два раза размер.

Резюмируя, мы строимся по топологии с двумя уровнями спайнов, с восемью слоями фабрики.

Что же будет с физикой? Очень простые расчеты. Если у нас есть два уровня спайнов, значит у нас всего три уровня свитчей, и мы ожидаем, что в сети будет три кабельных сегмента: от серверов к leaf-свитчам, к спайну 1, к спайну 2. Варианты, которые мы можем использовать — это twinax, multimode, single mode. И здесь нужно учитывать, какая полоса доступна, сколько это будет стоить, каковы физические размеры, какие пролеты можем пройти, и как мы будем апгрейдиться.
По стоимости все можно выстроить в линейку. Твинаксы стоят ощутимо дешевле, чем активная оптика, дешевле чем multimode трансиверы, если брать за пролет с конца, несколько дешевле, чем 100-гигабитный порт свитча. И он, внимание, стоит дешевле, чем single mode оптика, потому что на пролетах, где требуется single mode, в дата-центрах по ряду причин осмысленно использовать CWDM, с параллельным single mode (PSM) работать не очень удобно, получаются очень большие пачки волокна, и если остановиться на этих технологиях, получается примерно такая иерархия по ценам.
Еще одно замечание: к сожалению, не очень получается использовать разобранные 100 к 4×25 мультимодные порты. В силу особенностей конструкции трансиверов SFP28 стоит не намного дешевле, чем QSFP28 на 100 Гбит. И эта разборка для multimode не очень работает.
Еще некоторое ограничение -это то, что из-за размера вычислительных кластеров, из-за количества серверов наши дата-центры получаются физически большими. Это значит, что хотя бы один пролет придется делать с синглмодом. Опять же, из-за физического размера Pods не получится пройти два пролета twinax-ми (медными кабелями).
В итоге, если оптимизировать по цене и учитывать геометрию этой конструкции, мы получаем один пролет твинаксом, один пролет мультимодом и один пролет синглмодом с использованием CWDM. Это учитывает возможные пути апгрейда.
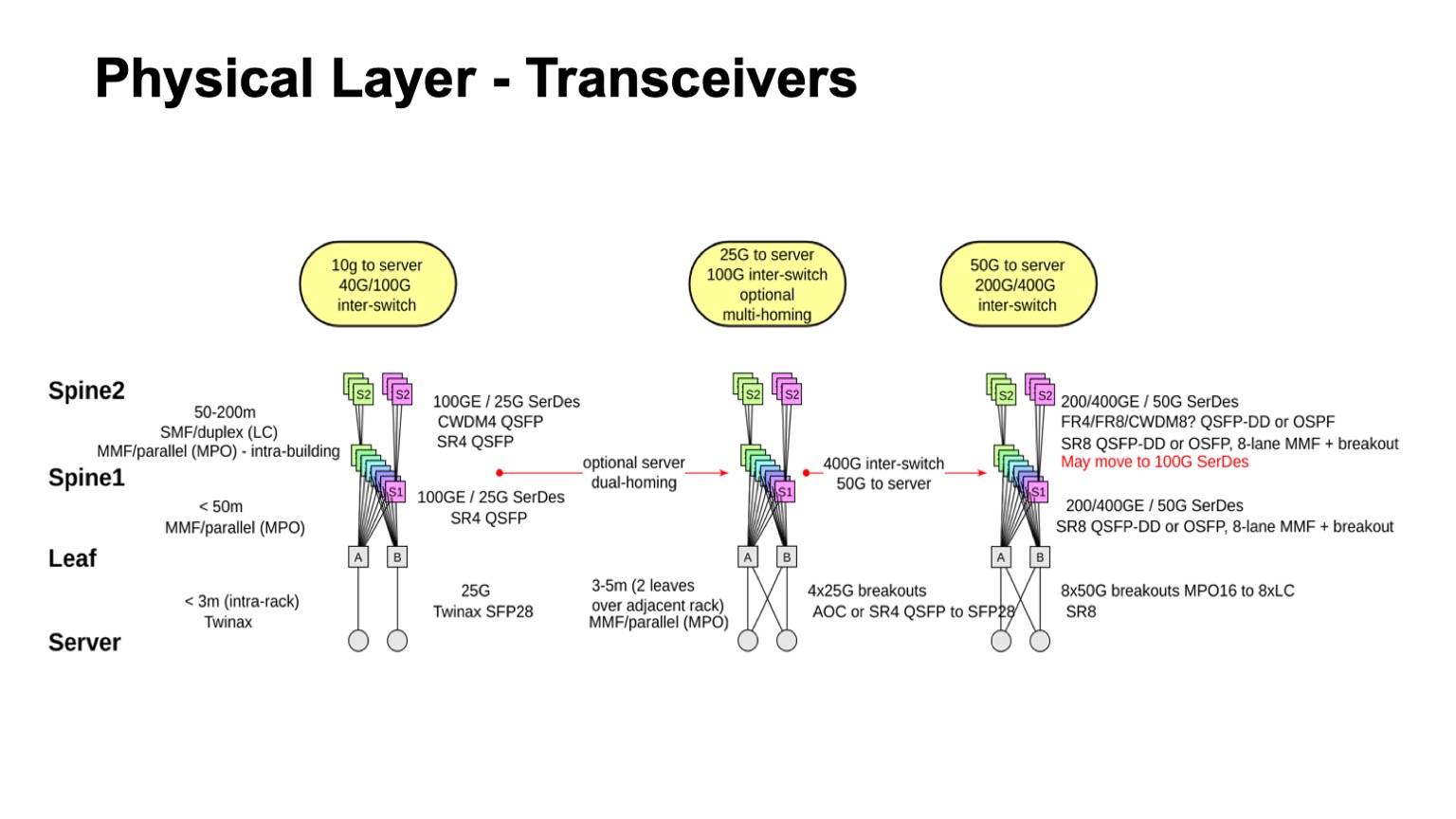
Примерно так выглядит, что было недавно, куда мы движемся и что возможно. Понятно, по крайней мере, как двигаться в сторону до 50-гигабитных SerDes и для мультимода и для синглмода. Более того, если посмотреть то, что есть в синглмод трансиверах сейчас и на перспективу для 400G, там зачастую даже когда приходят 50G SerDes-ы с электрической стороны, то в оптику могут уходить уже 100 Gbps per lane. Поэтому вполне возможно, что вместо перехода на 50 случится переход на 100-гигабитные SerDes и 100 Gbps per lane, потому что по обещаниям многих вендоров их доступность ожидается достаточно скоро. Период, когда 50G SerDes были самыми быстрыми, кажется, будет не очень продолжительным, потому что 100G SerDes выкатываются чуть ли не в следующем году первые экземпляры. И через какое-то время после этого они, возможно, будут стоить разумных денег.
Еще один нюанс насчет выбора физики. В принципе, уже сейчас мы можем применять 400- или 200-гигабитные порты с использованием 50G SerDes. Но выясняется, что в этом нет особого смысла, потому что, как я рассказывал ранее, нам хочется достаточно большого радикса на коммутаторах, в пределах разумного, конечно. Нам хочется 128. А если у нас емкость чипа ограничена и мы наращиваем скорость линка, то радикс, естественно, понижается, чудес нет.
А общую емкость мы можем нарастить за счет плоскостей, и при этом особых издержек нет, можно добавить количество плоскостей. А если мы потеряем радикс, нам придется вводить дополнительный уровень, поэтому при текущих раскладах, при текущей максимально доступной емкости на один чип, выясняется, что эффективнее использовать 100-гигабитные порты, потому что они позволяют получить больший радикс.

Следующий вопрос — как организована физика, но уже с точки зрения кабельной инфраструктуры. Выясняется, что она организована довольно забавно. Кейблинг между leaf-свитчами и спайнами первого уровня — там не так много линков, там все строится относительно просто. А вот если мы возьмем одну плоскость, то, что происходит внутри — там нужно соединить все спайны первого уровня со всеми спайнами второго уровня.
Плюс, как правило, есть некоторые пожелания к тому, как это должно выглядеть внутри дата-центра. Yапример, нам очень хотелось объединять кабели в бандл и тянуть их так, чтобы одна патч-панель высокой плотности уходила целиком в одну патч-панель, чтобы не было зоопарка по длинам. Нам удалось решить эту задачу. Если исходно посмотреть на логическую топологию, то видно, что плоскости независимые, каждая плоскость может строиться сама по себе. Но когда мы добавляем такой бандлинг и хотим тащить полностью патч-панель в патч-панель, то приходится внутри одного бандла смешивать разные плоскости и вводить промежуточную конструкцию в виде оптических кросс-коннектов, чтобы перепаковывать их от того, как они были собраны на одном сегменте, в то, как они будут собраны на другом сегменте. Благодаря этому мы получаем приятную особенность: вся сложная коммутация не выходит за пределы стоек. Когда нужно что-то очень сильно переплести, «развернуть плоскости», как это иногда называют в Clos-сетях, это все сосредоточено внутри одной стойки. У нас нет сильно разобранных, вплоть до индивидуальных линков, коммутаций между стойками.
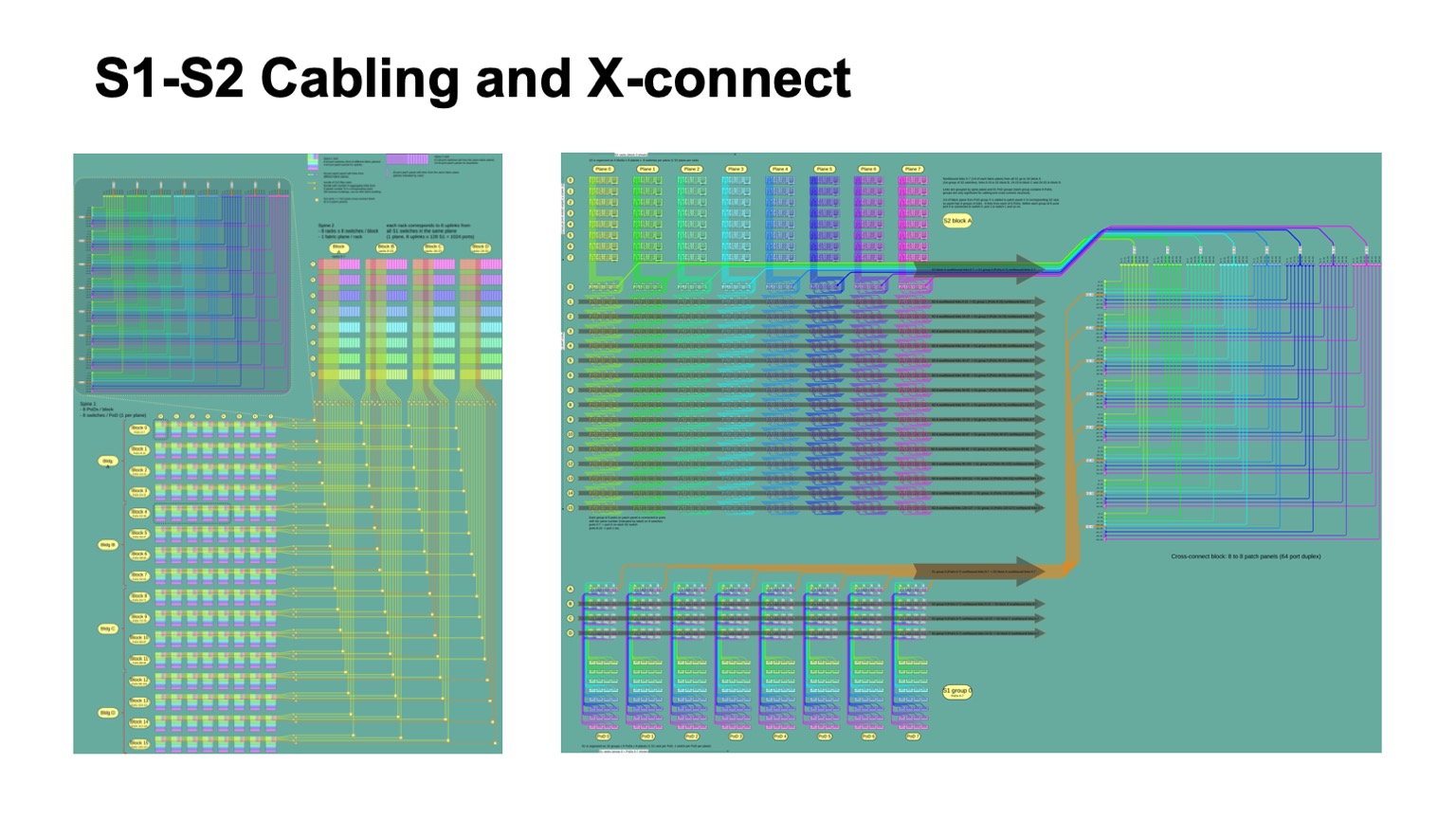
Так это выглядит с точки зрения логической организации кабельной инфраструктуры. На картинке слева разноцветные блоки изображают блоки спайн-свитчей первого уровня, по восемь штук, и идущие от них четыре бандла кабелей, которые идут и пересекаются с бандлами, идущими от блоков спайн-2-свитчей.
Маленькие квадратики обозначают пересечения. Вверху слева дана развертка каждого такого пересечения, это на самом деле модуль кросс-коннекта 512 на 512 портов, которые перепаковывает кабели так, чтобы приходить полностью в одну стойку, где только одна плоскость спайн-2. И справа развертка этой картинки чуть более детальная применительно к нескольким Pods на уровне спайн-1, и как это упаковывается в кросс-коннекте, как это приходит на уровень спайн-2.

Вот как это выглядит. Не полностью еще собранная стойка спайн-2 (слева) и стойка кросс-коннекта. К сожалению, там не очень много что видно. Вся эта конструкция развертывается прямо сейчас в одном из наших больших дата-центров, который расширяется. Это работа в процессе, будет выглядеть красивее, будет заполнено лучше.

Немаловажный вопрос: выбрали логическую топологию, построили физику. Что будет с control plane-ом? Достаточно хорошо известно из опыта эксплуатации, есть какое-то количество выступлений, что link state протоколы хороши, с ними приятно работать, но, к сожалению, на плотно провязанной топологии они плохо масштабируются. И есть один основной фактор, который этому препятствует — это то, как работает флудинг в link state протоколах. Если просто взять алгоритм флединга, посмотреть на то, как устроена наша сеть, видно, что будет на каждом шаге очень большой fanout, и будет просто заливать control plane апдейтами. Конкретно такие топологии конкретно с традиционным алгоритмом флудинга в link state протоколах смешивается очень плохо.
Выбор — использовать BGP. Как его правильно готовить, описано в RFC 7938 про использование BGP в больших дата-центрах. Базовые идеи простые: минимальное количество префиксов на хост и вообще минимальное количество префиксов в сети, использовать агрегацию, если это возможно, и подавлять path hunting. Мы хотим очень аккуратного, очень контролируемого распространения апдейтов, то, что называется valley free. Мы хотим, чтобы апдейты, проходя по сети, разворачивались ровно один раз. Если они оригинируются внизу, они идут вверх, разворачиваются не более одного раза. Не должно быть зигзагов. Зигзаги очень плохи.
Чтобы это сделать, мы используем достаточно простую схему, чтобы использовать базовые механизмы BGP. То есть у нас используется eBGP, работающий на link local, и автономные системы присваиваются следующим образом: автономная система на ToR, автономная система на весь блок спайн-1-свитчей одного Pod, и общая автономная система на весь Top of Fabric. Нетрудно посмотреть и убедиться в том, что при этом даже нормальное поведение BGP дает нам то распространение апдейтов, которого нам хочется.

Естественно, приходится дизайнить адресацию и агрегацию адресов так, чтобы это было совместимо с тем, как построена маршрутизация, чтобы это обеспечивало стабильность control plane. L3 адресация в транспорте привязана к топологии, потому что без этого нельзя добиться агрегации, без этого индивидуальные адреса будут пролезать в систему маршрутизации. И еще одна вещь — это то, что агрегация, к сожалению, не очень хорошо смешивается с multi-path, потому что когда у нас есть multi-path и есть агрегация, все хорошо, когда вся сеть работоспособна, в ней нет сбоев. К сожалению, как только в сети появляются сбои и симметрия топологии теряется, мы можем прийти в точку, из которой анонсировался агрегат, из которой нельзя дальше пройти туда, куда нам нужно. Поэтому агрегировать лучше всего там, где дальше нет multi-path, в нашем случае это ToR-свитчи.

На самом деле, агрегировать можно, но осторожно. Если мы можем сделать контролируемую дезагрегацию при появлении сбоев в сети. Но это достаточно сложная задача, мы даже прикидывали, получится ли это сделать, можно ли навесить дополнительную автоматику, и конечные автоматы, которые будут правильно пинать BGP, чтобы получить нужное поведение. К сожалению, обработка corner cases очень неочевидна и сложна, и путем присоединения к BGP внешнего навесного оборудования эта задача хорошо не решается.
Очень интересная работа в этом плане сделана в рамках протокола RIFT, о котором будет рассказано на следующем докладе.

Еще одна важная вещь — это то, как масштабируются data plane в плотных топологиях, где у нас есть большое количество альтернативных путей. При этом используется несколько дополнительных структур данных: ECMP группы, которые описывают в свою очередь группы Next Hop.
В нормально работающей сети, без сбоев, когда мы идем по Clos-топологии вверх, достаточно использовать только одну группу, потому что все, что не локально, описывается дефолтом, можно идти вверх. Когда мы идем сверху вниз на юг, то все пути не ECMP, это single path-пути. Все хорошо. Беда в том, и особенность Clos-топологии классической в том, что если мы смотрим на Top of fabric, на любой элемент, до любого элемента внизу у него один путь. Если вдоль этого пути происходят сбои, то конкретно этот элемент наверху фабрики становится невалидным именно для тех префиксов, которые лежат за поломанным путем. А для остальных он валиден, и нам приходится разбирать ECMP группы и вводить новый state.
Как выглядит мастштабируемость data plane на современных устройствах? Если мы делаем LPM (longest prefix match), все достаточно хорош
