Как использовать Томита-парсер в своих проектах. Практический курс
Привет, меня зовут Наталья, я работаю в Яндексе разработчиком в группе извлечения фактов. Весной мы рассказали о том, что такое Томита-парсер и для чего он используется в Яндексе. А уже этой осенью исходники парсера будут выложены в открытый доступ.В предыдущем посте мы пообещали рассказать, как пользоваться парсером и о синтаксисе его внутреннего языка. Именно этому и посвящен мой сегодняшний рассказ.

Прочитав этот пост, вы узнаете, как составляются словари и грамматики для Томиты, а также, как извлекать с их помощью факты из текстов на естественном языке. Та же информация доступна в формате небольшого видеокурса.
Грамматика — это набор правил, которые описывают цепочки слов в тексте. Например, если у нас есть предложение «Мне нравится, что вы больны не мной», его можно описать с помощью цепочки [местоимение первого лица, единственного числа], [глагол в настоящем времени и третьем лице], [запятая], [союз] и т.д.
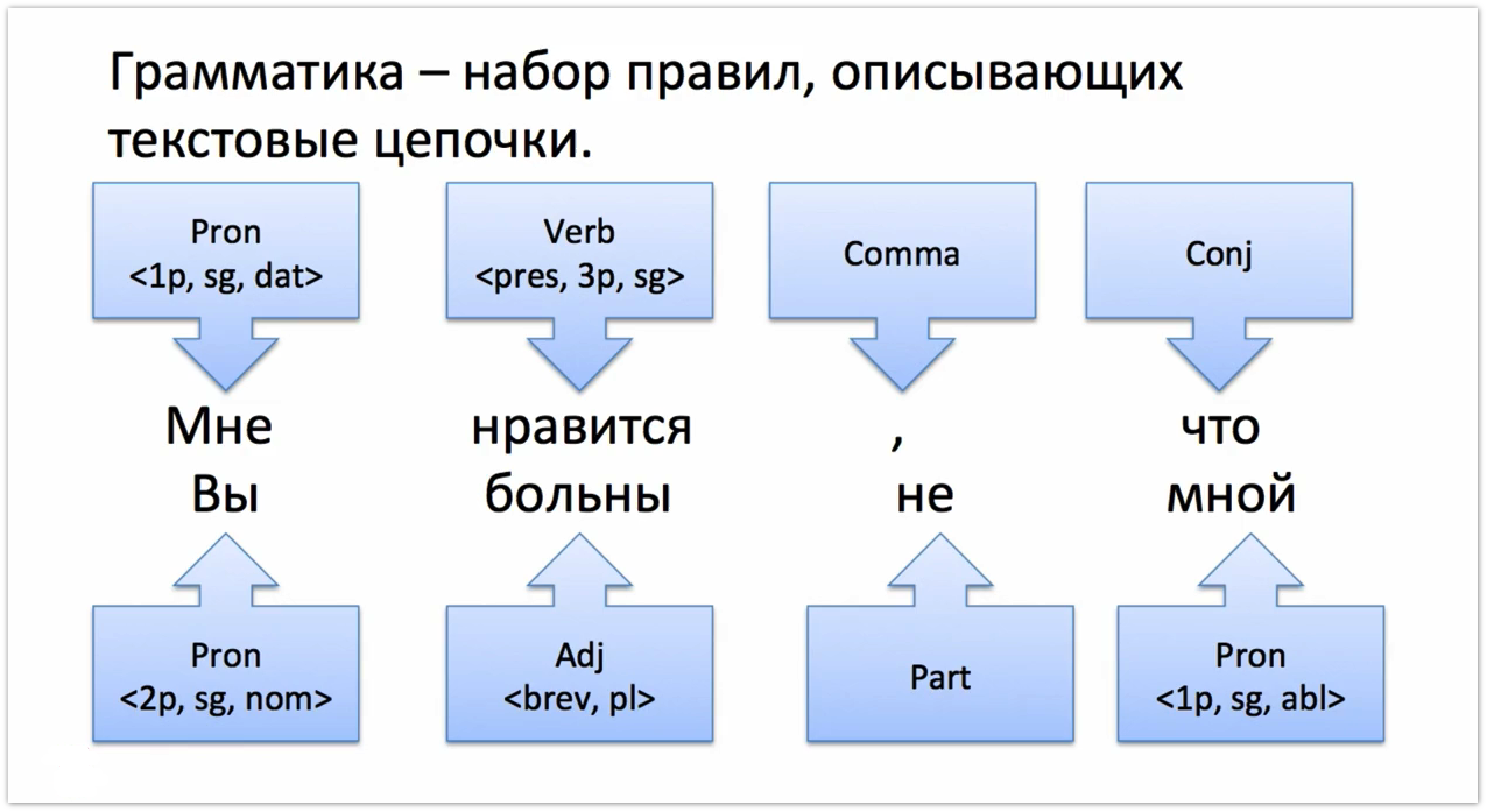
Грамматика пишется на специальном формальном языке. Структурно правило разделяется символом → на левую и правую части. В левой части стоит один нетермиал, а правая состоит как из терминалов, так и нетерминалов. Терминал в данном контексте — это некий объект, имеющий конкретное, неизменяемое значение. Множество терминалов — алфавит языка Томита, из которого выстраиваются все остальные слова. Терминалами в Томите выступают «леммы» — слова в начальной форме, записанные в одинарных кавычках, части речи (Noun, Verb, Adj…), знаки пунктуации (Comma, Punct, Hyphen…) и некоторые другие спецсимволы (Percent, Dollar…). Всего терминалов в Томите около двадцати, полный их список представлен в нашей документации. Нетерминалы составляются из терминалов, и если проводить аналогию с естественными языками, представляют собой нечто вроде слов. Например, нетерминал NounPhrase, состоящий из двух терминалов Adj и Noun, означает цепочку из двух слов: вначале — прилагательное, потом — существительное.
Чтобы составить нашу первую грамматику, нужно создать файл с расширением .cxx, назовем его first_grammar. Сохранить его можно там же, где лежит сам бинарник парсера. В первой строке файла с грамматикой нужно указать кодировку:
#encoding «utf8» Далее можно писать правила. В нашей первой грамматике их будет два: PP → Prep Noun; S → Verb PP; Первое правило описывает нетерминал PP — предложную группу, состоящую из предлога и существительного (Prep Noun). Второе правило — глагол с предложной группой (Verb PP). В данном случае нетерминал S является корневым, потому что он ни разу не упоминается в правой части правила. Такой нетерминал называется верхушкой дерева. Он описывает целиком ту цепочку, которую мы хотим извлечь из текста.Наша первая грамматика готова, но прежде чем запускать парсер, нужно проделать ещё несколько манипуляций. Дело в том, что грамматика взаимодействует с парсером не напрямую, а через корневой словарь — сущность, в которой собирается информация обо всех созданных грамматиках, словарях, дополнительных файлах и т.д. Т.е. корневой словарь — это своего рода агрегатор всего, что создается в рамках проекта. Словари для Томита-парсера пишутся с использованием синтаксиса похожего на Google Protobuf (используется модифицированная версия компилятора Protobuf, с поддержкой наследования). Файлам обычно даётся расширение .gzt. Создадим корневой словарь dic.gzt и в начале также укажем кодировку:
encoding «utf8»; После этого мы импортируем в корневой словарь файлы, содержащие базовые типы, используемые в словарях и грамматиках. Для удобства эти файлы зашиты в бинарник парсера, и мы можем импортировать их напрямую, не прописывая путь к ним: import «base.proto»; import «article_base.proto»; Далее мы создаём статью. Статья словаря описывает способ выделения цепочки слов в тексте. Грамматика — это один из возможных способов. Цепочку можно выделять при помощи списка ключевых слов, встроенного в парсер алгоритма (цепочки ФИО и дат). Другие способы могут быть добавлены на уровне исходного кода парсера (например, статистический named entity recognizer). Статья состоит из типа, названия и содержания. О том, что такое типы статей и для чего они нужны я расскажу ниже, когда мы будем подробнее говорить о словарях. Пока мы будем использовать базовый тип TAuxDicArticle. Название статьи должно быть уникальным, оно указывается в кавычках после типа. Далее в фигурных скобках перечисляются ключи — содержание статьи. В нашем случае в единственном ключе содержится ссылка на написанную нами грамматику. Сначала мы указываем синтаксис файла, на который мы ссылаемся (в случае файла с грамматикой это всегда tomita), и путь к этому файлу, потом в поле type — тип ключа (его необходимо указывать, если ключ содержит в себе ссылку на грамматику). TAuxDicArticle «первая_грамматика» { key = {«tomita: first_grammar.cxx» type=CUSTOM} } Чтобы сообщить парсеру, откуда мы берём исходный текст, куда записываем результат, какие грамматики запускаем, какие факты извлекаем, а также прочую необходимую информацию, создается единый файл конфигурации с расширением .proto. Создадим в папке с парсером файл config.proto. Как обычно, в начале указываем кодировку и переходим к описанию нашей конфигурации.Единственный обязательный параметр конфигурационного файла — это путь к корневому словарю, который записывается в поле Dictionary. Все остальные параметры опциональны. Информация о входном файле находится в поле Input. Помимо текстовых файлов Томите можно подать на вход папку, архив или stdin. В поле Output записывается, куда и в каком формате (text, xml или protobuf) надо сохранить извлечённые факты. Мы отправим на вход файл input.txt. В поле Articles в перечисляются грамматики, которые мы хотим запустить. Обратите внимание, что здесь мы указываем не сам файл с грамматикой, а название статьи из словаря, которая содержит в себе ссылку на этот файл: как мы уже говорили, парсер взаимодействует со всеми файлами проекта опосредованно через корневой словарь.
encoding «utf8»; TTextMinerConfig { Dictionary = «dic.gzt»;
Input = {File = «input.txt»}
Output = {File = «output.txt» Format = text}
Articles = [ { Name = «первая_грамматика» } ] } Теперь, когда файл конфигурации готов, нам осталось положить рядом с бинарником файл с текстом для анализа (вы можете воспользоваться нашим тестовым файлом или взять свой) и можно переходить к запуску грамматики. В терминале перейдем в ту папку, где лежит наш парсер. Парсер запускается с единственным аргументом — именем конфигурационного файла. Соответственно, в *NIX-системах команда для запуска будет выглядеть так: ./tomitaparser config.proto Результаты можно посмотреть в файле output.txt. Однако никаких извлеченных фактов мы там не увидим, потому что в нашей грамматике пока что есть только правила выделения цепочек, а чтобы выделенные цепочки превратились в структурированные факты, надо добавить процедуру интерпретации. О ней мы поговорим чуть ниже. Однако выделенные цепочки мы можем увидеть уже на этом этапе, для этого нужно добавить к файлу конфигурации ещё один параметр — отладочный вывод: PrettyOutput = «pretty.html» Благодаря этому параметру результаты работы парсера будут записываться в html-файл с более наглядным представлением. Теперь, если мы перезапустим грамматику и откроем файл pretty.html, который появился в папке, мы увидим, что у нас извлеклись все цепочки, описанные нами в грамматике — глаголы, после которых идет существительное с предлогом: Результат ехать на перекладных остановиться возле духана остановиться для ночлега подойти к нему ехать в Ставрополь подвигать с помощью взять на водку приехать на Линию деть против горцев считаться в третьем последовать за днем бывать на юге идти в гору оглянуться на долину требовать на водку посмотреть на штабс-капитана наткнуться на корову приютиться у огня быть в Чечне отойти за вал вытащить из чемодана пожалеть о том выйти перед фрунт отдать под суд быть в гостях стоять в крепости поселиться в крепости ходить на кабана надорвать со смеха быть в нем быть на деньги хлопать в ладоши глядеть на эту бегать за хозяином стать в сакле выйти на воздух ложиться на горы Пробираться вдоль забора быть за Тереком ездить с абреками прыгать через пни бежать по следам повиснуть на передних полететь в овраг убиться до смерти тянуться по степи бегать по берегу лететь из-под копыт сиять во мраке зазвенеть об кольчугу удариться об плетень кинуться в конюшню схватиться за ружья вертеться среди толпы деть в чужом заговорить о другом бывать от любви поскакать в аул выехать из крепости перемениться в лице перескочить через ружье скакать на лихом выхватить из чехла повалиться на землю прийти в крепость ускакать на нем отправиться в аул пойти к нему стать в тупик стать в тупик сидеть в углу зачахнуть в неволе заглянуть в окно сидеть на лежанке зайти к нему ударить по рукам мочь в щель грезиться во сне дождаться у дороги быть в сумерки нырнуть из-за куста видеть с пригорка продрогнуть на снегу выйти из сакли гаснуть по мере тронуться в путь выбиваться из сил вести на небо пропадать в облаке отдыхать на вершине хрустеть под ногами приливать в голову отпадать от души взобраться на Гуд-гору слезть с облучка спускаться с Гуд-горы происходить от слова проваливаться под ногами превращаться в лед скрыться в тумане биться о решетку останавливаться в погоду дать на водку разыграться на щеках объявить о смерти подмывать за кабанами выйти за крепостной ходить по комнате сидеть на кровати утащить в горы упасть на постель быть в сентябре походить по крепостному сесть на дерн быть с вала сидеть на углу стоять на месте привстать на стременах вернуться с охоты быть за речкою биться об заклад перемениться к этой проводить на охоте тосковать по родным деть в том выйти из опеки поехать в Америку умереть на дороге бывать в столице происходить от пьянства быть за диковинка шнырять по камышам уйти в камыши собраться в кучу указывать в поле рваться из-под седла поравняться с Печориным приложиться из ружья упасть на колени держать на руках карабкаться на утес соскочить с лошадей литься из раны быть без памяти посадить к нему послать за лекарем выйти из крепости сесть на камень потащить в кусты вскочить на коня сидеть у постели отвернуться к стене хотеться в горы встретиться с душою будет в раю прийти на мысль умереть в той стать на колени пойти на крепостной умереть с горя сесть на землю пробежать по коже похоронить за крепостью уехать в Грузию возвратиться в Россию расстаться с Максимом Извлечённые цепочки парсер пытается нормализовать, приводя главное слово цепочки (по умолчанию — первое) в начальную форму.
Следующий шаг — введение процедуры интерпретации, т.е. преобразование извлеченных цепочек в факты.
Сначала нам нужно создать структуру того факта, который мы хотим извлекать, т.е. описать, из каких полей он состоит. Для этого создадим новый файл fact_types.proto. Снова сделаем импорт файлов с базовыми типами, после чего перейдём к описанию самого факта. После слова message пишется название факта, двоеточие и базовый тип факта, от которого наследуется тип нашего факта. Далее в фигурных скобках мы перечисляем поля нашего факта. В нашем случае поле одно, оно обязательное (required), текстовое (string), называется Field1 и мы присваиваем ему идентификатор 1.
import «base.proto»; import «facttypes_base.proto»; message Fact: NFactType.TFact
{ required string Field1 = 1; } Теперь нужно импортировать созданный нами файл в корневой словарь (dic.gzt): import «fact_types.proto»; Перейдем к грамматике, в которой и происходит процедура интерпретации. Допустим, мы хотим извлечь из текста такой факт: глаголы, которые управляют существительными с предлогом. Для этого в правиле после маркера глагола мы пишем interp, а далее в скобках название факта и через точку название поля, в которое мы хотим положить извлечённую цепочку. S → Verb interp (Fact.Field1) PP; Интерпретация может происходить в любом месте грамматики, но факт извлечётся только в том случае, если интерпретированный символ попадёт в корневой нетерминал.Последняя деталь, необходимая для запуска — указать в файле конфигурации, какие факты мы хотим извлекать при запуске парсера. Синтаксис в данном случае такой же, как и при указании запускаемых грамматик: в поле Facts квадратных скобках перечисляются все необходимые факты. В нашем случае факт пока только один:
Facts = [ { Name = «Fact» } ] Теперь можно снова запускать парсер.Результат ехать остановиться остановиться подойти ехать подвигать взять приехать деть считаться последовать бывать идти оглянуться требовать посмотреть наткнуться приютиться быть отойти вытащить пожалеть выйти отдать быть стоять поселиться ходить надорвать быть быть хлопать глядеть бегать стать выйти ложиться Пробираться быть ездить прыгать бежать повиснуть полететь убиться тянуться бегать лететь сиять зазвенеть удариться кинуться схватиться вертеться деть заговорить бывать поскакать выехать перемениться перескочить скакать выхватить повалиться прийти ускакать отправиться пойти стать стать сидеть зачахнуть заглянуть сидеть зайти ударить мочь грезиться дождаться быть нырнуть видеть продрогнуть выйти гаснуть тронуться выбиваться вести пропадать отдыхать хрустеть приливать отпадать взобраться слезть спускаться происходить проваливаться превращаться скрыться биться останавливаться дать разыграться объявить подмывать выйти ходить сидеть утащить упасть быть походить сесть быть сидеть стоять привстать вернуться быть биться перемениться проводить тосковать деть выйти поехать умереть бывать происходить быть шнырять уйти собраться указывать рваться поравняться приложиться упасть держать карабкаться соскочить литься быть посадить послать выйти сесть потащить вскочить сидеть отвернуться хотеться встретиться будет прийти умереть стать пойти умереть сесть пробежать похоронить уехать возвратиться расстаться Дополнительные возможности грамматик Теперь поставим перед собой более сложную задачу: попробуем написать грамматику, с помощью которой можно извлекать из текста названия улиц. Мы будем искать в тексте дескрипторы (слова улица, шоссе, проспект и т.п.) и анализировать цепочки, которые стоят рядом с ними. Цепочки должны начинаться с заглавной буквы и располагаться слева или справа от дескриптора. Создадим новый файл с грамматикой address.cxx и сохраним его в папке c нашим проектом. Сразу же добавим статью с нашей новой грамматикой в корневой словарь: TAuxDicArticle «адрес» { key = {«tomita: address.cxx» type=CUSTOM} } Теперь добавим в файл fact_types.proto новый факт Street, который мы хотим извлекать. Он будет состоять из двух полей: обязательного (название улицы) и опционального (дескриптор). message Street: NFactType.TFact { required string StreetName = 1; optional string Descr = 2; } Чтобы перейти непосредственно к написанию грамматики, нужно ввести несколько новых понятий, которых мы не касались ранее.Первое понятие — это операторы. Они позволяют получить более удобную сокращенную запись правил грамматики:
* — символ повторяется 0 или более раз; + — символ повторяется 1 или более раз; () — символ входит в правило 0 или 1 раз; | — оператор «или». Перейдём к написанию грамматики. В файле address.cxx напишем два правила — в первом опишем нетерминал StreetW, который будет содержать названия некоторых дескрипторов улиц, а во втором — нетерминал StreetSokr с сокращенными обозначениями. #encoding «utf8»
StreetW → 'проспект' | 'проезд' | 'улица' | 'шоссе'; StreetSokr → 'пр' | 'просп' | 'пр-д' | 'ул' | 'ш'; Далее мы добавим нетерминал StreetDescr, который объединит в себе два предыдущих: StreetDescr → StreetW | StreetSokr; Теперь нам нужно описать цепочки, которые в случае, если они стоят рядом с дескриптором, могут быть названиями улиц. Для этого введём ещё два понятия: пометы-ограничения и согласование.Пометы уточняют свойства терминалов и нетерминалов, т.е. накладывают ограничения на множество цепочек, которое описывает терминал или нетерминал. Они записываются в угловых скобках после терминалов/нетерминалов и, в случае нетерминалов, применяются к синтаксически главному слову группы. Пометы могут быть разнообразными по своей структуре. Некоторые представляют собой унарный оператор, некоторые имеют поле, которое может быть заполнено разными значениями. Перечислим некоторые пометы, которые мы будем использовать в дальнейшем (полный список можно найти в нашей документации):
Морфологическая помета gram — это поле, которое может быть заполнено любой морфологической категорией из словаря: часть речи, род, число, падеж, время, наклонение, залог, лицо и т.д.
По роду, числу и падежу: gnc-agr;
По роду и числу: gn-agr;
По падежу: c-agr.
В правиле обязательно нужно писать идентификатор согласования, который указывает, какой символ с каким согласуется. Например, в следующем правиле символ A согласуется с B по роду, числу и падежу, а с C — по числу и падежу:
S → A
NumberW → NumberW_1 | NumberW_2 | NumberW_3;
Описание цепочек по отдельности потребовалось нам для того, чтобы у нас была возможность согласовывать их с дескриптором улицы и названием-прилагательным, которое стоит за ними. Морфология, к сожалению, не может провести это согласование самостоятельно, т.к. морфологический парсер не знает, какие у этих цепочек грамматические характеристики. Однако в Томите можно задать морфологические характеристики для любой собранной цепочки. Делается это при помощи пометы outgram, которую можно добавить в конце правила перед точкой с запятой. Добавим к нашим правилам грамматические характеристики:
NumberW_1 → AnyWord
Output = {File = «output.txt» Format = text}
Articles = [ { Name = «адрес» } ] Facts = [ { Name = «Street» } ] Запустим парсер и посмотрим, что у нас получилось: Результат Address StreetName Descr 1-я Дубровская ул Нижняя Масловка ул Мира проспект 1-я Владимирская улица Большая Семеновская ул Комсомольский просп Тимура Фрунзе ул Энтузиастов ш Словари Теперь подробнее поговорим о словарях. Файл dic.gzt, который мы создали в самом начале — это словарь, но это некоторая особая сущность, своего рода агрегатор всех файлов в рамках проекта, т.е. скорее служебный файл. Однако словари также могут содержать пользовательские данные. В этом смысле они ближе к словарям в традиционном понимании.Словари в Томите пишутся в формате протобуф. Статья в газеттире описывает множество цепочек, объединённых общим свойством. Это множество может быть задано в явном виде — лексически — когда мы перечисляем все нужные нам цепочки:
TAuxDicArticle «города» { key = «Москва» | «Воронеж» | «Самара»} или функционально, ссылаясь на грамматику: TAuxDicArticle «адрес» { key = {«tomita: address.cxx» type=CUSTOM}} Перейдём к синтаксису газеттира. Как мы уже говорили выше, название статьи указывается в кавычках, а её содержание — в фигурных скобках. Кроме того, как и в грамматиках, в словарных статьях можно при помощи помет накладывать ограничения, касающиеся грамматических характеристик, регистра, согласования и и т.д. TAuxDicArticle «организация» { key = { государственный дума mainword=2 agr=gnc_agr} } В примере выше статья «организация» содержит единственный ключ — цепочку «государственная дума», в которой главное слово второе, и оба слова должны быть согласованы в роде, числе и падеже. Обратите внимание, что все слова в цепочке пишутся в начальной форме.Также в статье можно отдельным полем задать лемму, к которой будут приводиться все ключи данной статьи при нормализации:
TAuxDicArticle «санкт-петербург»
{
key = «санкт-петербург»
key = «спб»
key = «питер»
lemma = «Санкт-Петербург»
}
Мы уже научились ссылаться на грамматики из словаря, теперь разберемся, как ссылаться на словари из грамматики. Делается это при помощи пометы kwtype. Она означает, что слово, которому соответствует данный (не)терминал, должно быть объектом заданного типа, т.е. входить в статью, указанную в поле пометы kwtype. Есть также помета kwset, при помощи которой можно сослаться сразу на несколько статей. Названия статей перечисляются через запятую в квадратных скобках:
Animals → Word
surname «пушкин» { key = «пушкин» }
surname «гагарин» { key = «гагарин» } Файл нужно сохранить и импортировать его в корневой словарь, добавив строку import «surnames.gzt»;. Туда же импортируем файл с описанием новых типов import «kwtypes.proto»;.Теперь, когда у нас есть словарь с фамилиями, мы можем попробовать решить в упрощенном виде одну задачу, которая достаточно часто возникает в Яндексе: выделение конструкций типа «имени кого-то». Создадим файл новой грамматики imeni.cxx. Первое правило у нас будет содержать регулярное выражение, описывающее инициал. Второе правило объединяет два инициала. А третье правило содержит в себе пару инициалов и терминал, который включает в себя все цепочки с типом surname из нашего словаря. Если мы добавим в наш словарь ещё несколько фамилий, то они тоже будут входить в этот терминал. В последнем корневом правиле мы добавили к уже собранной цепочке фамилия + инициалы слово «имени» (в начальной форме).
#encoding «utf8»
Initial → Word
Initials → Initial Initial;
FIO → Initials Word
Imeni →'имя'
#encoding «utf8»
OrgDescr → 'библиотека' | 'театр' | 'музей'; Во втором правиле мы объединим дескриптор и цепочку «имени кого-то». Для этого мы используем помету kwtype, в поле которой укажем статью «имени», ссылающуюся на грамматику imeni.cxx. Парсеру абсолютно безразлично, что находится в статье, на которую мы ссылаемся в помете kwtype — список лемм или ссылка на грамматику. Он трактует их абсолютно одинаково — как список цепочек.Наконец, в корневом правиле добавим интерпретацию.
Org_ → OrgDescr Word
Org → Org_ interp (Org.Name); Добавим нашу новую грамматику в корневой словарь: TAuxDicArticle «организация» { key = {«tomita: org.cxx» type=CUSTOM} } Также нужно добавить новый факт в файл fact_types.proto: message Org: NFactType.TFact { required string Name = 1; } И, наконец, внесём изменения в конфигурационный файл. В этот раз мы запускаем грамматику, которая лежит в статье с названием «организация». Факты мы на сей раз извлекаем, поэтому раскомментируем строки и поменяем название факта на «Org». Articles = [ { Name = «организация» } ]
Facts = [ { Name = «Org» } ] Запустим парсер и посмотрим на результаты в файле pretty.html. У нас извлекся факт «Библиотека имени В.И. Ленина».Что же произошло при включении одной грамматики в другую? Сначала текст «Библиотека им В.И. Ленина» был подан на вход грамматики imeni.cxx. Она превратила его в «Библиотека им_В.И. Ленина», т.е. собрав свою цепочку, она пять токенов превратила в два и в таком виде текст был передан дальше на вход грамматике org.cxx.
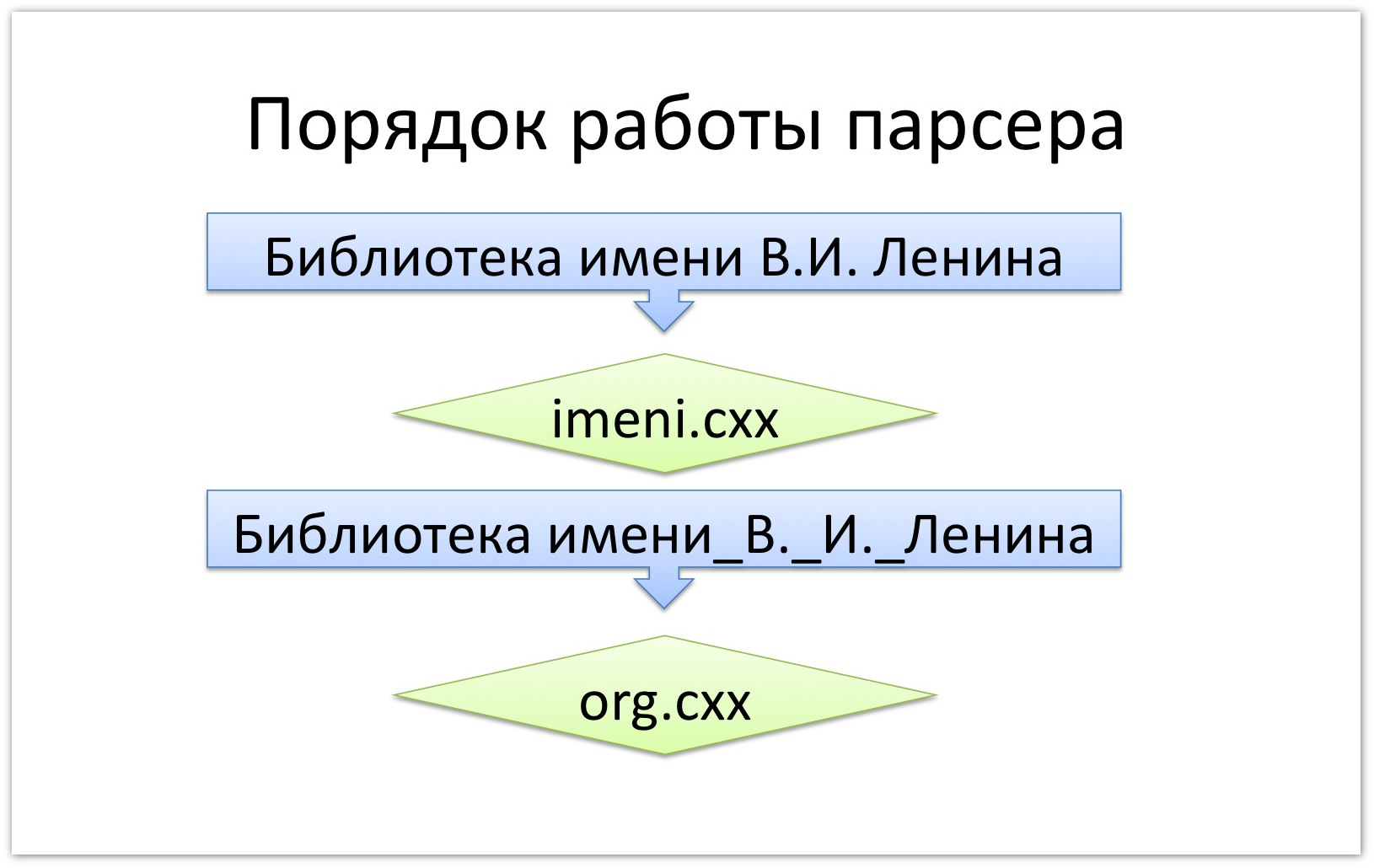
Надо понимать, что так происходит каждый раз, когда грамматика ссылается на статью из словаря (т.е. используется помета kwtype): сначала все цепочки из словаря собираются в так называемые мультитокены, и только потом начинают работать правила грамматики.
Все созданные нами файлы и тексты для анализа доступны в архиве по ссылке. Если у вас остались вопросы, связанные с синтаксисом Томита-парсера, вы можете ознакомиться с подробным его описанием в документации.
