Как использовать корутины в проде и спокойно спать по ночам
Корутины — мощный инструмент для асинхронного исполнения кода. Они работают параллельно, общаются друг с другом и потребляют мало ресурсов. Казалось бы, без страха можно внедрять корутины в продакшен. Но страхи есть и они мешают.
Доклад Владимира Иванова на AppsConf как раз о том, что не так страшен чёрт и что можно прямо сегодня применять корутины:
О спикере: Владимир Иванов (dzigoro) — ведущий Android-разработчик в компании EPAM с 7-летним опытом, увлекается Solution Architecture, React Native и разработкой под iOS, а еще имеет сертификат Google Cloud Architect.
Все, что вы прочтете — это продукт продакшн опыта и различных исследований, поэтому воспринимайте как есть, без каких-либо гарантий.
Корутины, Kotlin и RxJava
Для информации: текущий статус корутин — в релизе, вышли из Беты. Kotlin 1.3 вышел в релиз, корутины объявлены стабильными и наступил мир во всем мире.

Недавно я проводил опрос в Twitter, что у людей с использованием корутин:
- У 13%корутины в проде. Все хорошо;
- 25% пробует их в pet project;
- 24% — What«s Kotlin?
- У основной массы в 38% RxJava везде.
Статистика не радует. Я считаю, что RxJava слишком сложный инструмент для задач, в которых он обычно используется разработчиками. Корутины больше подходят для управления асинхронной работой.
В своих предыдущих докладах я рассказывал как рефакторить с RxJava на корутины в Kotlin, поэтому не буду на этом подробно останавливаться, а только напомню основные моменты.
Почему мы используем корутины?
Потому что если мы используем RxJava, то обычные примеры реализации выглядят так:
interface ApiClientRx {
fun login(auth: Authorization)
: Single
fun getRepositories
(reposUrl: String, auth: Authorization)
: Single>
}
//RxJava 2 implementation
У нас есть интерфейс, например, мы пишем клиент GitHub и хотим для него выполнить пару операций:
- Залогинить пользователя.
- Получить список репозиториев GitHub.
В обоих случаях функции будут возвращать Single бизнес-объектов: GitHubUser или список GitHubRepository.
Код реализации такого интерфейса выглядит следующим образом:
private fun attemptLoginRx () {
showProgress(true)
compositeDisposable.add(apiClient.login(auth)
.flatMap {
user -> apiClient.getRepositories(user.repos_url, auth)
}
.map {
list -> list.map { it.full_name }
}
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.doFinally { showProgress(false) }
.subscribe(
{ list -> showRepositories(this, list) },
{ error -> Log.e("TAG", "Failed to show repos", error) }
))
}
— Берем compositeDisposable, чтобы не было memory leak.
— Добавляем вызов первого метода.
— Используем удобные операторы, чтобы получить пользователя, например flatMap.
— Получаем список его репозиториев.
— Пишем Boilerplate, чтобы это выполнялось на нужных потоках.
— Когда все готово — показываем список репозиториев для залогиненного пользователя.
Трудности кода RxJava:
- Сложность. На мой взгляд код слишком сложный для простой задачи двух сетевых вызовов и отображения чего-то на UI.
- Несвязанные stack traces. Stack traces почти не связаны с кодом, который вы напишете.
- Перерасход ресурсов. RxJava генерирует много объектов под капотом и производительность может снижаться.
Каким будет тот же код с корутинами до версии 0.26?
В 0.26 поменялся API, а мы с вами говорим о продакшн. Никто еще не успел применить 0.26 в прод, но мы работаем над этим.
С корутинами наш интерфейс изменится достаточно существенно. Функции перестанут возвращать какие-либо Singles и другие вспомогательные объекты. Они сразу будут возвращать бизнес-объекты: GitHubUser и список GitHubRepository. У функций GitHubUser и GitHubRepository появятся модификаторы suspend. Это хорошо, потому что suspend нас почти ни к чему не обязывает:
interface ApiClient {
suspend fun login(auth: Authorization) : GithubUser
suspend fun getRepositories
(reposUrl: String, auth: Authorization)
: List
}
//Base interface
Если посмотреть на код, который использует реализацию уже этого интерфейса, то он значительно изменится по сравнению с RxJava:
private fun attemptLogin () {
launch(UI) {
val auth = BasicAuthorization(login, pass)
try {
showProgress(true)
val userlnfo = async { apiClient.login(auth) }.await()
val repoUrl = userlnfo.repos_url
val list = async { apiClient.getRepositories(repoUrl, auth) }.await()
showRepositories(
this,
list.map { it -> it.full_name }
)
} catch (e: RuntimeException) {
showToast("Oops!")
} finally {
showProgress(false)
}
}
}
— Основное действие происходит там, где мы вызываем coroutine builder async, дожидаемся ответа и получаем userlnfo.
— Используем данные из этого объекта.
— Производим еще один вызов async и вызываем await.
Все выглядит так, будто никакой асинхронной работы не происходит, а мы просто пишем в столбик команды и они выполняются. В конце выполняем то, что нужно выполнить на UI.
Почему корутины лучше?
- Этот код проще читать. Он написан так, будто он последовательный.
- Скорее всего производительность этого кода лучше, чем на RxJava.
- Очень просто писать тесты, но до них дойдем чуть позже.
2 шага в сторону
Немного отвлечемся, есть пара вещей, о которых еще нужно поговорить.
Шаг 1. withContext vs launch/async
Кроме coroutine builder async существует coroutine builder withContext.
Launch или async создают новый Coroutine context, что не всегда нужно. Если у вас есть Coroutine context, который вы хотите использовать во всем приложении, то не нужно заново его создавать. Можно просто переиспользовать уже существующий. Для этого понадобится coroutine builder withContext. Он просто переиспользует уже имеющийся Coroutine context. Это будет в 2–3 раза быстрее, но сейчас это непринципиальный вопрос. Если интересны точные цифры, то вот вопрос на stackoverflow с бенчмарками и подробностями.
Общее правило: Используйте withContext без сомнений там, где он семантически подходит. Но если вам нужна параллельная загрузка, например нескольких картинок или частей данных, то async/await — ваш выбор.
Шаг 2. Рефакторинг
Что, если вы рефакторите действительно сложную цепочку RxJava? Я столкнулся с такой в продакшне:
observable1.getSubject().zipWith(observable2.getSubject(), (t1, t2) -> {
// side effects
return true;
}).doOnError {
// handle errors
}
.zipWith(observable3.getSubject(), (t3, t4) -> {
// side effects
return true;
}).doOnComplete {
// gather data
}
.subscribe()
У меня была сложная цепочка с public subject, с zip и побочными эффектами в каждом zipper, которые еще что-то отправляли на event bus. Задачей минимум было избавиться от event bus. Я просидел день, но не смог отрефакторить код, чтобы решить задачу. Правильным решением оказалось выкинуть все и за 4 часа переписать код на coroutine.
Код ниже очень похож на то, что у меня получилось:
try {
val firstChunkJob = async { call1 }
val secondChunkJob = async { call2 }
val thirdChunkJob = async { call3 }
return Result(
firstChunkJob.await(),
secondChunkJob.await(),
thirdChunkJob.await())
} catch (e: Exception) {
// handle errors
}
— Делаем async для одной задачи, для второй и третьей.
— Ждем результат и все это складываем в объект.
— Готово!
Если у вас сложные цепочки и есть корутины, то просто рефакторите. Это реально быстро.
Что мешает разработчикам применять корутины в проде?
На мой взгляд, нам, как разработчикам, сейчас мешает использовать корутины только страх чего-то нового:
- Мы не знаем, что делать с lifecycle, с activity и жизненным циклом фрагментов. Как работать с корутинами в этих случаях?
- Нет опыта решения ежедневных сложных задач в продакшн с помощью корутин.
- Не хватает инструментов. Для RxJava написано куча библиотек и функций. Например RxFCM. В самой RxJava много операторов, что хорошо, но как насчет корутин?
- Не очень понимаем, как тестировать корутины.
Если мы избавимся от этих четырех страхов, то сможем спокойно спать по ночам и использовать корутины в продакшн.
Давайте по пунктам.
1. Lifecycle management
- Корутины могут утекать как disposable или AsyncTask. Эту проблему нужно решать вручную.
- Чтобы не было рандомных Null Pointer Exception корутины нужно останавливать.
Остановка
Вам знаком метод Thread.stop ()? Если вы его и использовали, то недолго. В JDK 1.1 метод сразу объявили устаревшим, так как невозможно брать и останавливать определенный кусок кода и нет никаких гарантий, что он завершится корректно. Скорее всего вы получите только memory corruption.
Поэтому Thread.stop () не работает. Вам нужно, чтобы отмена была кооперативно, то есть чтобы код на той стороне знал, что вы его отменяете.
Как мы применяем остановки с RxJava:
private val compositeDisposable = CompositeDisposable()
fun requestSmth() {
compositeDisposable.add(
apiClientRx.requestSomething()
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(result -> {})
}
override fun onDestroy() {
compositeDisposable.dispose()
}
В RxJava мы используем CompositeDisposable.
— Добавляем переменную compositeDisposable в activity во фрагменте или в презентере, там где используем RxJava.
— В onDestroy добавляем Dispose и все exceptions уходят сами собой.
Примерно тот же принцип с корутинами:
private val job: Job? = null
fun requestSmth() {
job = launch(UI) {
val user = apiClient.requestSomething()
…
}
}
override fun onDestroy() {
job?.cancel()
}
Рассмотрим на примере простой задачи.
Обычно coroutine builders возвращают job, а в некоторых случаях Deferred.
— Мы можем запоминать этот job.
— Даем команду «launch» coroutine builder. Процесс запускается, что-то происходит, результат выполнения запоминается.
— Если больше ничего не передаем, то «launch» запускает функцию и возвращает нам ссылку на job.
— Job запоминаем, а в onDestroy говорим «cancel» и все хорошо работает.
В чем проблема подхода? Для каждого job нужен field. Нужно поддерживать список jobs, чтобы их все вместе отменять. Подход приводит к дублированию кода, не делайте так.
Хорошая новость в том, что у нас есть альтернативы: CompositeJob и Lifecycle-aware job.
CompositeJob — это аналог compositeDisposable. Выглядит примерно так:
private val job: CompositeJob = CompositeJob()
fun requestSmth() {
job.add(launch(UI) {
val user = apiClient.requestSomething()
...
})
}
override fun onDestroy() {
job.cancel()
}
— На один фрагмент заводим один job.
— Все job«s складываем в CompositeJob и даем команду: «job.cancel () для всех!».
Подход легко имплементируется в 4 строчки, не считая объявления класса:
Class CompositeJob {
private val map = hashMapOf()
fun add(job: Job, key: String = job.hashCode().toString())
= map.put(key, job)?.cancel()
fun cancel(key: String) = map[key]?.cancel()
fun cancel() = map.forEach { _ ,u -> u.cancel() }
}
Вам понадобится:
— map со строковым ключом,
— метод add, в который вы будете добавлять job,
— опциональный параметр key.
Если захотите использовать один и тот же ключ для одного и того же job — пожалуйста. Если нет, то hashCode решит нашу проблему. Складываем job в map, который мы передали, и отменяем предыдущий с таким же ключом. Если перевыполняем задачу, то предыдущий результат нас не интересует. Отменяем его и прогоняем заново.
Cancel простой: получаем job по ключу и отменяем. Второй cancel для всей map все отменяет. Весь код пишется за полчаса в четыре строки и он работает. Если не хотите писать — возьмите пример выше.
Lifecycle-aware job
Пользовались ли вы Android Lifecycle, Lifecycle owner или observer? 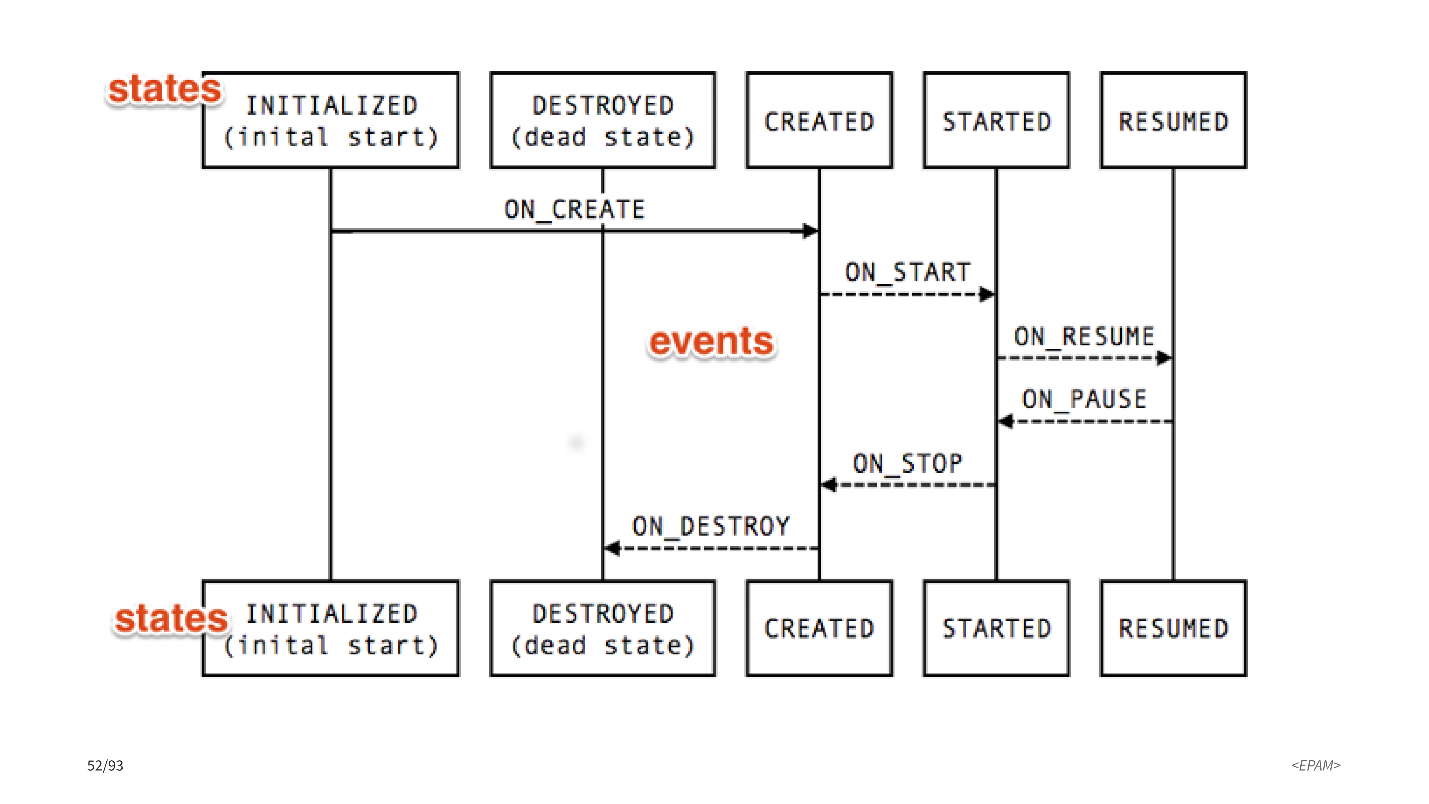
У наших activity и fragments есть определенные состояния. Самые интересные: created, started и resumed. Между состояниями есть разные переходы. LifecycleObserver позволяет подписываться на эти переходы и что-то делать, когда какой-то из переходов случается.
Выглядит это достаточно просто:
public class MyObserver implements LifecycleObserver {
@OnLifecycleEvent(Lifecycle.Event.ON_RESUME)
public void connectListener() {
...
}
@OnLifecycleEvent(Lifecycle.Event.ON_PAUSE)
public void disconnectListener() {
…
}
}
Вешаете аннотацию с каким-то параметром на метод, и он вызывается с соответствующим переходом. Достаточно просто использовать этот подход для корутин:
class AndroidJob(lifecycle: Lifecycle) : Job by Job(), LifecycleObserver {
init {
lifecycle.addObserver(this)
}
@OnLifecycleEvent(Lifecycle.Event.ON_DESTROY)
fun destroy() {
Log.d("AndroidJob", "Cancelling a coroutine")
cancel()
}
}
— Можно написать базовый класс AndroidJob.
— В класс будем передавать Lifecycle.
— Интерфейс LifecycleObserver будет реализовывать job.
Всё, что нам нужно:
— В конструкторе добавиться в Lifecycle в качестве Observer.
— Подписаться на ON_DESTROY или на что-нибудь еще, что нам интересно.
— Сделать cancel в ON_DESTROY.
— Завести один parentJob в вашем фрагменте.
— Вызвать конструктором Joy jobs или lifecycle«ом вашего фрагмента activity. Без разницы.
— Передать этот parentJob в качестве parent.
Готовый код выглядит так:
private var parentJob = AndroidJob(lifecycle)
fun do() {
job = launch(UI, parent = parentJob) {
// code
}
}
Когда вы отменяете parent, отменяются все дочерние корутины и вам больше не нужно ничего писать в фрагменте. Все происходит автоматически, больше никаких ON_DESTROY. Главное не забывайте передавать parent = parentJob.
Если будете использовать, можете написать простой lint rule, который будет вам подсвечивать: «О, ты родителя забыл!»
СLifecycle management разобрались. У нас есть пара инструментов, которые позволяют делать это все легко и комфортно.
Что на счет сложных сценариев и нетривиальных задач в продакшн?
2. Complex use-cases
Сложные сценарии и нетривиальные задачи это:
— Operators — сложные операторы в RxJava: flatMap, debounce и т.п.
— Error-handling — сложная обработка ошибок. Не простой try…catch, а например, вложенный.
— Caching — нетривиальная задача. В продакшне мы столкнулись с кэшем и захотели получить инструмент, чтобы легко решать задачу кэширования с корутинами.
Repeat
Когда мы думали над операторами для корутин, то первым вариантом был repeatWhen ().
Если что-то пошло не так и корутина не смогла достучаться до сервера внутри себя, то мы хотим повторить попытку несколько раз с каким-нибудь экспоненциальным fallback. Возможно причина в плохом соединении и мы получим нужный результат повторив операцию несколько раз.
С корутинами эта задача легко имплементируется:
suspend fun retryDeferredWithDelay(
deferred: () -> Deferred,
tries: Int = 3,
timeDelay: Long = 1000L
): T {
for (i in 1..tries) {
try {
return deferred().await()
} catch (e: Exception) {
if (i < tries) delay(timeDelay) else throw e
}
}
throw UnsupportedOperationException()
}
Реализация оператора:
— Он принимает Deferred.
— Вам понадобится вызывать async, чтобы получить этот объект.
— Вместо Deferred можно передавать и suspend блок и вообще любую suspend-функцию.
— Цикл for — вы дожидаетесь результата своей корутины. Если что-то происходит и счетчик повторения не исчерпан — пытаетесь еще раз через Delay. Если нет, то нет.
Функцию можно легко кастомизировать: поставить экспоненциальный Delay или передавать лямбда-функцию, которая будет рассчитывать Delay в зависимости от обстоятельств.
Пользуйтесь, это работает!
Zips
Также часто с ними сталкиваемся. Здесь опять все просто:
suspend fun zip(
source1: Deferred,
source2: Deferred,
zipper: BiFunction): R {
return zipper.apply(sourcel.await(), source2.await())
}
suspend fun Deferred.zipWith(
other: Deferred,
zipper: BiFunction): R {
return zip(this, other, zipper)
}
— Применяйте zipper и вызывайте await на свои Deferred.
— Вместо Deferred можно использовать suspend-функцию и coroutine builder с withContext. Будете передавать необходимый вам контекст.
Это опять же работает и надеюсь, что этот страх я снял.
Cache
Есть ли у вас реализация сache в продакшн с RxJava? Мы используем RxCache.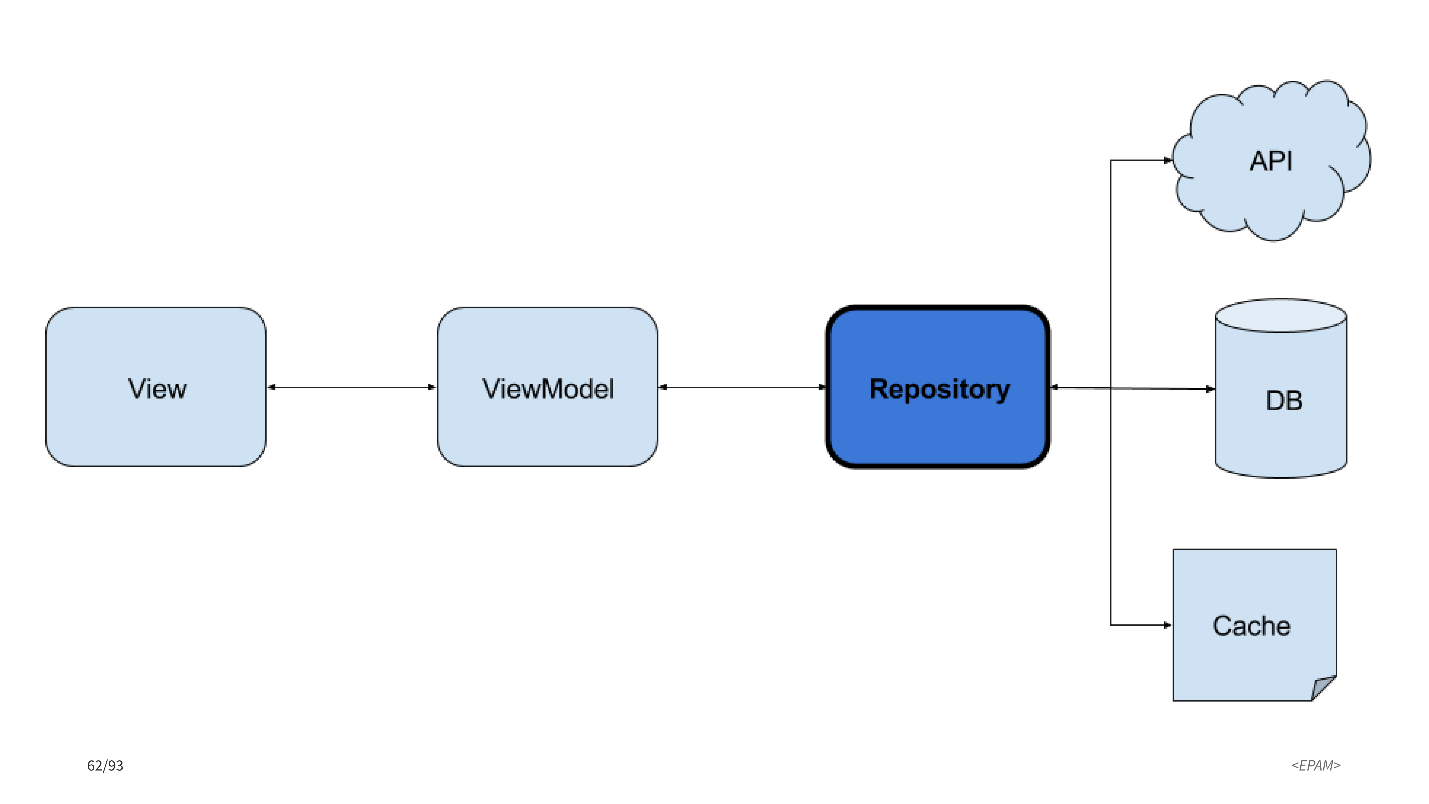
На схеме слева: View и ViewModel. Справа — источники данных: сетевые вызовы и база данных.
Если мы хотим, чтобы что-то кэшировалось, то сache станет еще одним источником данных.
Виды кэша:
- Network Source для сетевых вызовов.
- In-memory cache.
- Persistent cache with expiration для хранения на диске, чтобы кэш переживал перезапуск приложения.
Напишем простой и примитивный cache для третьего случая. На помощь снова приходит Coroutine builder withContext.
launch(UI) {
var data = withContext(dispatcher) { persistence.getData() }
if (data == null) {
data = withContext(dispatcher) { memory.getData() }
if (data == null) {
data = withContext(dispatcher) { network.getData() }
memory.cache(url, data)
persistence.cache(url, data)
}
}
}
— Вы исполняете каждую операцию с withContext и смотрите — приходят ли какие-то данные.
— Если данные из persistence не приходят, то вы пытаетесь получить их из memory.cache.
— Если в memory.cache тоже нет, то обращаетесь в network source и получаете свои данные. Не забывайте, конечно, во все кэши положить.
Это достаточно примитивная реализация и здесь много вопросов, но метод работает, если вам кэш нужен в одном месте. Для продакшн-задач этого кэша не хватает. Нужно что-то более сложное.
Rx has RxCache
Для тех, кто до сих пор использует RxJava, можно использовать RxCache. Мы тоже все еще его используем. RxCache — специальная библиотека. Позволяет кэшировать данные и управлять их жизненным циклом.
Например, вы хотите сказать, что эти данные устареют через 15 минут: «Пожалуйста, через этот промежуток времени из кэша не отдавай данные, а отправь мне свежие».
Библиотека прекрасна тем, что декларативно поддержит команду. Декларация очень похожа на то, что вы делаете с Retrofit«ом:
public interface FeatureConfigCacheProvider {
@ProviderKey("features")
@LifeCache(duration = 15, timeUnit = TimeUnit.MINUTES)
fun getFeatures(
result: Observable,
cacheName: DynamicKey
): Observable>
}
— Вы говорите, что у вас есть CacheProvider.
— Заводите метод и говорите, что время жизни LifeCache 15 минут. Ключ, по которому он будет доступен — это Features.
— Возвращается Observable
Использование достаточно простое:
val restObservable = configServiceRestApi.getFeatures()
val features =
featureConfigCacheProvider.getFeatures(
restObservable,
DynamicKey(CACHE_KEY)
)
— С Rx-кэша обращаетесь к RestApi.
— Обращаетесь к CacheProvider.
— Скармливаете ему Observable.
— Библиотека сама разберется, что делать: сходить в cache или нет, если кончилось время, обратиться к Observable и выполнить другую операцию.
Использовать библиотеку очень удобно и хотелось бы получить подобную для корутин.
Coroutine Cache в разработке
Внутри EPAM мы пишем библиотеку Coroutine Cache, которая будет исполнять все функции RxCache. Мы написали первую версию и обкатываем ее внутри компании. Как только выйдет первый релиз, я с удовольствием напишу об этом в своем Twitter. Выглядеть это будет следующим образом:
val restFunction = configServiceRestApi.getFeatures()
val features = withCache(CACHE_KEY) { restFunction() }
У нас будет suspend-функция getFeatures. Функцию будем передавать в качестве блока в специальную функцию высшего порядка withCache, которая будет сама разбираться, что нужно сделать.
Возможно, мы сделаем такой же интерфейс, чтобы поддерживать декларативные функции.
Обработка ошибок

Простая обработка ошибок часто встречается разработчикам и обычно решается достаточно просто. Если у вас нет сложных вещей, то в catch вы ловите exсeption и смотрите, что там произошло, пишете в лог или показывайте ошибку пользователю. На UI вы легко можете это сделать.
В простых случаях все ожидаемо несложно — обработка ошибок с корутинами проводится через try-catch-finally.
В продакшне кроме простых случаев бывают:
— Вложенные try-catch,
— Много разных видов exсeptions,
— Ошибки в сети или в бизнес-логике,
— Ошибки пользователя. Он опять сделал что-то не так и во всем виноват.
Мы должны быть к этому готовы.
Есть 2 варианты решения: CoroutineExceptionHandler и подход с Result classes.
Coroutine Exception Handler
Это специальный класс для обработки сложных случаев возникновения ошибок. ExceptionHandler позволяет принять в качестве аргумента ваш Exception как ошибку и обработать его.
Как мы обычно обрабатываем сложные ошибки?
Пользователь что-то нажал, кнопка не сработала. Ему нужно сказать, что пошло не так и направить на определенное действие: проверить интернет, Wi-Fi, попробовать позже или удалить приложение и никогда больше не пользоваться. Cказать об это пользователю можно достаточно просто:
val handler = CoroutineExceptionHandler(handler = { , error ->
hideProgressDialog()
val defaultErrorMsg = "Something went wrong"
val errorMsg = when (error) {
is ConnectionException ->
userFriendlyErrorMessage(error, defaultErrorMsg)
is HttpResponseException ->
userFriendlyErrorMessage(Endpoint.EndpointType.ENDPOINT_SYNCPLICITY, error)
is EncodingException ->
"Failed to decode data, please try again"
else -> defaultErrorMsg
}
Toast.makeText(context, errorMsg, Toast.LENGTH_SHORT).show()
})
— Заведем дефолтное сообщение: «Что-то пошло не так!» и проанализируем exception.
— Если это ConnectionException, то берем из ресурсов локализованное сообщение: «Человек, включи Wi-Fi и твои проблемы уйдут. Я гарантирую это».
— Если сервер что-то сказал неправильно, то нужно сообщить клиенту: «Выйди и зайди заново», или «Не делай этого в Москве, сделай это в другой стране», или «Извини, товарищ. Все, что я могу — просто сказать, что что-то пошло не так».
— Если это абсолютно другая ошибка, например out of memory, мы говорим: «Что-то пошло не так, извини».
— Все сообщения выводим.
То, что вы пишите в CoroutineExceptionHandler, будет выполняться на том же Dispatcher, на котором вы запускаете корутину. Поэтому если вы даете команду «launch» UI, то все происходит на UI. Вам не нужен отдельный dispatching, что очень удобно.
Использовать просто:
launch(uiDispatcher + handler) {
...
}
Есть оператор plus. В Coroutine context добавляете handler и все работает, что очень удобно. Мы какое-то время этим пользовались.
Result classes
Позже мы поняли, что CoroutineExceptionHandler может не хватать. Результат, который формируется работой корутины, может состоять из нескольких данных, из разных частей или обрабатывать несколько ситуаций.
С этой проблемой помогает справиться подход Result classes:
sealed class Result {
data class Success(val payload: String)
: Result()
data class Error(val exception: Exception)
: Result()
}
— В вашей бизнес-логике вы заводите Result class.
— Отметьте как sealed.
— От класса наследуете два других data classes: Success и Error.
— В Success передаете свои данные, формирующиеся в результате выполнения корутины.
— В Error складываете exception.
Дальше вы можете реализовывать бизнес-логику следующим образом:
override suspend fun doTask(): Result = withContext(CommonPool) {
if ( !isSessionValidForTask() ) {
return@withContext Result.Error(Exception())
}
…
try {
Result.Success(restApi.call())
} catch (e: Exception) {
Result.Error(e)
}
}
Вызываете Coroutine context — Coroutine builder withContex и можно обрабатывать разные ситуации.
Например, незалогиненный пользователь:
— Выходим и говорим, что это error. Пусть логика повыше её обрабатывает.
— Можно вызвать RestApi или другую бизнес-логику.
— Если все хорошо, то возвращается Result.Success.
— Если случается исключение, то Result.Error.
Подход позволяет делегировать обработку ошибок куда-то дальше, хотя ExceptionHandler тоже так делает.
Result classes работает, тесты писать удобно. Мы используем Result classes, но вы можете использовать и ExceptionHandler и try-catch.
3. Тестирование
Последнее, что нас волнует и мешает хорошо спать. Если вы пишете unit-тесты, то вы уверены, что все работает правильно. С корутинами нам тоже хочется писать unit-тесты.
Посмотрим, как это делать. Глобально для того, чтобы писать unit-тесты, нам нужно решить 2 задачи:
- Replacing context. Уметь подменять контекст, на котором все происходит;
- Mocking coroutines. Уметь мокировать корутины.
Replacing context
Так выглядит presenter:
val login() {
launch(UI) {
…
}
}
Например, если в методе login вы запускаете вашу корутину, то она явно использует UI-контекст. Это не очень хорошо для тестов, так как один из принципов тестирования приложений говорит, что все зависимости должны явно передаваться в метод или в класс . Здесь принцип не соблюдается, поэтому код нужно улучшить, чтобы написать unit-тест.
Улучшение достаточно простое:
val login (val coroutineContext = UI) {
launch(coroutineContext) {
...
}
}
— В метод login настроить передачу coroutineContext. Понятно, что в коде вашего приложения вы не хотите везде передавать это явно. В Kotlin можно просто написать, что это должен быть UI по умолчанию.
— Вызываете свой Coroutine builder с тем Coroutine Contex, что передаете в метод.
В unit-тесте можно сделать следующее:
fun testLogin() {
val presenter = LoginPresenter ()
presenter.login(Unconfined)
}
— Можно завести свой LoginPresenter и метод login вызывать с каким-то контекстом, например, с Unconfined.
— Unconfined сообщает, что корутина будет запущена на потоке, который её и запускает. Это позволяет одной строкой писать тесты и проверять результат.
Mocking coroutines
Следующий вопрос — мокирование корутин. Я рекомендую использовать Mockk для unit-тестов. Это легковесный фреймворк для unit-тестирования специально написанный на Kotlin, в котором легко работать с корутинами. Можно suspend-функцию или корутину подменить с помощью специальной функции coEvery и вместо вызова корутины возвращать интересный вам бизнес-объект.
Здесь вызов login вместо корутины возвращает просто githubUser:
coEvery {
apiClient.login(any())
} returns githubUser
Если у вас Mockito-kotlin, то все немного сложнее — придется плясать с бубном. Возможно, есть более аккуратный способ, но сейчас мы пользуемся таким:
given {
runBlocking {
apiClient.login(any())
}
}.willReturn (githubUser)
Мы используем просто runBlocking. С given-блоком делаем то же самое, что в предыдущем примере.
Мы можем написать полный тест на наш Presenter:
fun testLogin() {
val githubUser = GithubUser('login')
val presenter = LoginPresenter(mockApi)
presenter.login (Unconfined)
assertEquals(githubUser, presenter.user())
}
— Подготовить свои бизнес-данные, например, GitHubUser.
— В LoginPresenter явно передать зависимость на наш API, но теперь он будет замокирован. Как вы его мокируете решать вам.
— Дальше вызывать presenter.login с Unconfined контекстом и проверять, что в Presenter сформировались все нужные данные, которые мы ожидаем.
И все! Тестировать корутины реально просто.
Подведем итоги
- Рефакторить Rx-код на корутины просто. Я постоянно вижу это на практике. Обычно рефакторить с корутинами даже проще, чем RxJava на RxJava. Если завтра вам понадобиться что-то рефакторить — подумайте о том, чтобы использовать корутины.
- Легко покрывать код тестами. Когда используете корутины, то можете легко покрыть ваш код тестами. Unit-тест — это залог качества и в наших интересах, как разработчиков, и в интересах наших пользователей, чтобы приложения были качественными. Поэтому — welcome!
- Корутины не создают ошибки. Наш опыт говорит, что корутины, фреймворк и библиотеки, которые мы используем, сами по себе не создают проблем. Ничего не мешает внедрить корутины в продакшен.
Полезные ссылки
- Если вы только знакомитесь с корутинами, то обратите внимание на статью Android GDE Дмитро Данилюка Android Coroutine Recipes. В ней расписано практически все, что вам нужно знать для начала: lifeCircle, coroutineContexts, разница между Coroutine builders и все остальное.
- Гид по корутинам на GitHub.
- Ресурсы обучающие работе с Android или Kotlin, начинают использовать корутины в своих примерах, поэтому советую Codelab .
- Я тоже пытаюсь вносить свой вклад в продвижение корутин как могу. В Twitter часто пишу про мобильную разработку и архитектуру. На Medium выпустил серию статей о «внутренностях» инструментов для фоновой работы в Android, начиная с async-тасков и заканчивая корутинами.
Новости
30 ноября совместно с Mail.ru мы проводим открытый митап исключительно по теме тестирования мобильных приложений. Мероприятие бесплатное, но нужно обязательно зарегистрироваться.
Следующая конференция для разработчиков мобильных приложений AppsConf запланирована на апрель, уже пора подавать заявки и задумывать о бронировании билетов по привлекательной цене.
Подпишитесь на рассылку, и мы напишем, когда появятся новости о программе будущей конференции, и будем иногда присылать сводку полезных материалов.
Здесь и на youtube-канале скоро опубликуем еще несколько лучших докладов AppsConf 2018 — оставайтесь с нами :)
