Как и зачем мы начали искать бизнес-инсайты в отзывах клиентов с помощью машинного обучения
Естественный источник обратной связи для любой компании — отзывы их клиентов. И Альфа-Банк не исключение: за год мы собираем больше 100 млн оценок по различным каналам и продуктам. Но среди этих оценок очень мало содержательных текстовых комментариев, а самый популярных среди них (за 2021 год) — «Вопрос не решен!»
Чтобы решить эту проблему, Альфа-Банк собирает дополнительно до 500 тысяч отзывов в год. Этим занимается команда по сохранению лояльности клиентов: обзванивает клиентов, которые поставили негативную оценку, подробно их опрашивает, и старается решить проблему клиента на звонке, формируя свой экспертный отзыв.
Накапливаемые данные практически невозможно анализировать в ручном режиме в полном объеме, но можно сократить объем труда за счет машинного обучения. О том, как мы помогли оптимизировать процесс вычитки с помощью суммаризации на основе тематических моделей и будет эта статья.

Как собираем обратную связь
Для начала опишу подробно процесс сбора обратной связи (ОС). Этот процесс называется VoC (voice of client, голос клиента) — сбор ОС в едином формате для всех каналов обслуживания и продуктов.
Например, когда вы обратитесь в отделение банка, чтобы оформить кредитную карту, заполните все документы и, довольные (или не очень), выйдете из отделения, то получите push или sms-уведомление с просьбой оценить качество обслуживания. Такое же уведомление получают все клиенты, обратившиеся в отделение в тот день.
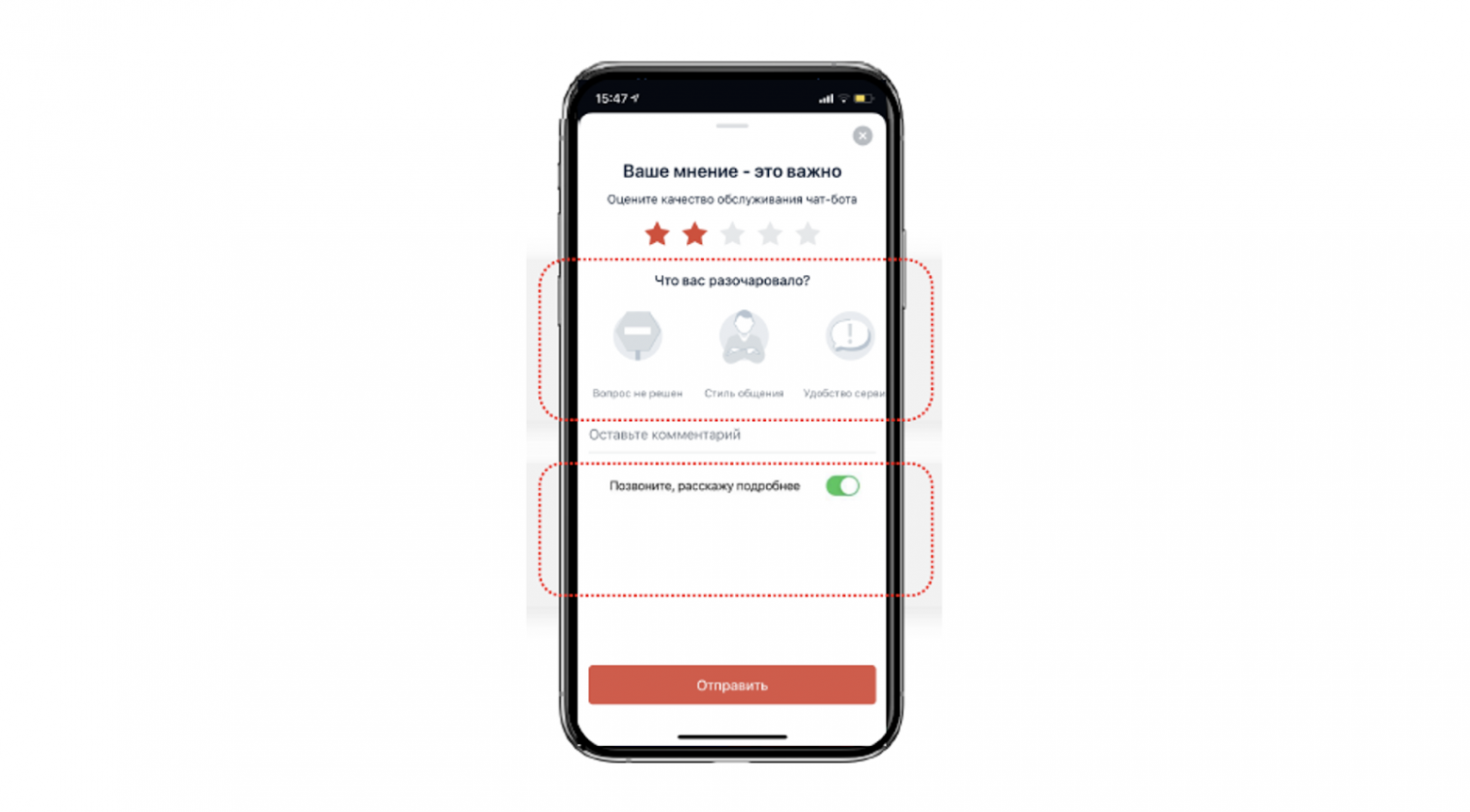 Пример push-уведомления для сбора ОС
Пример push-уведомления для сбора ОС
Клиенту предлагается выбрать категорию негатива, оставить комментарий, и оценить обслуживание по шкале от 1 до 5. Оценки от 1 до 3 считаются негативными и отдельно обрабатываются экспертами, о чем я расскажу подробнее в следующей главе. Также у пользователя есть возможность задействовать функцию «Call me back», которая гарантирует, что этот самый эксперт вам позвонит.
Таким способом за 2021 год удалось:
получить 105 млн оценок;
из которых 2,2 млн — негативные;
обзвонить 515 тысяч клиентов;
затронуть 36 различных каналов.
Но всего 12% клиентов оставили какой-либо комментарий, причем большинство из них — эмоционально негативные высказывание без конкретики и структуры.
Как работаем с негативными отзывами
Как уже упоминал, в этот момент дополнительно подключаются те самые эксперты — команда по сохранению лояльности клиентов (ОСЛК). Они транслируют боль клиента в структурированный вид, формируя экспертизу. Также в их задачи входит:
Помощь клиенту во время звонка.
Верификация — исключение случайных оценок.
Классификация сформированной экспертизы на категории негатива.
Выглядит получившаяся экспертизы следующим образом, на примере выдачи кредитной карты (КК):
Причина обращения в канал: получение КК.
Почему клиент поставил низкую оценку (негатив): сотрудник при получении КК выдал вторую на 60 дней без согласия клиента.
Какой нерешенный вопрос или недовольство продуктом/процессом остались у клиента: совпадает с пунктом 2.
Независимое экспертное заключение ОСЛК по кейсу: клиент закрыл вторую КК. На ОС предоставлены комментарии по вопросу клиента. Рекомендации сотруднику: уточнять у клиента, нужна ли ему вторая КК. Некорректные действия сотрудника.
Как видите, экспертиза получается структурированной и достаточно детализированной. Эксперт прежде всего выделят причину, с которой вы обратились в канал, а также фиксирует, что пошло в самом канале не так. В качестве заключения описывается возможное решение проблемы клиента.
Пока что я только рассказывал о том, как формируется обратная связь, но не как она анализируется. Для этого в банке сформирована команда управления клиентского опыта (УКО), задача которой состоит в поиске инсайтов в сформированных экспертизах для улучшения непосредственно бизнес-процессов.
Пайплайн работы с экспертизами до оптимизации выглядел следующим образом. Первым делом происходила ручная вычитка экспертиз. Она заключалась в том, что выбирался случайный сэмпл объемом 1,5–2 тысячи из общего списка экспертиз по самому популярному каналу. Дальше сформированный список тщательно вычитывают одновременно восемь сотрудников клиентского опыта. В качестве артефакта образовывались те самые бизнес инсайты, которые передавались продуктовым командам.
Весь процесс занимал около 15 дней, что наводило на мысль о зонах роста.
Мы можем вычитывать все экспертизы, а не ограниченное число, также, как и все каналы, тем самым увеличив количество находимых инсайтов.
Мы можем сократить количество сотрудников, необходимых для вычитки.
Ускорить саму вычитку на N дней.
Соответственно, перед нами — командой Лаборатории Машинного Обучения, стояла задача решить эти проблемы.
Тематическое моделирование
Говоря более формально, необходимо провести семантический анализ большой коллекции неразмеченных текстов.
Нужно понять, какими темами можно описать датасет, состоящий из экспертиз, а также подобрать оптимально число тематик, покрывающих всю коллекцию. Помимо этого, сформированные темы должны быть интерпретируемыми, чтобы посмотрев на её содержимое, сходу понять о чём она — о комиссии или кэшбэке.
С большинством подсвеченных требований помогает справиться тематическое моделирование.
Тематическая модель коллекции текстовых документов определяет, к каким темам относится каждый документ, и какие слова образуют каждую тематику.
Для этого каждая тема описывается дискретным распределением вероятностей слов, а каждый документ — дискретным распределением вероятностей тем.
В целом, тематическое моделирование похоже на кластеризацию документов. Отличие в том, что при кластеризации документ целиком относится к одному кластеру, тогда как тематическая модель осуществляет мягкую кластеризацию, разделяя документ между несколькими кластерами (темами).
Так как же тематическая модель всё же работает?
В основе модели лежит предположение, что существует конечное множество тем t, и каждое употребление термина w в каждом документе d, связано с некоторой темой.
Поэтому коллекцию документов мы можем рассматривать как случайную и независимую выборку троек из дискретного распределения, где слова и документы — это наблюдаемые переменные, а темы не известны — скрытые переменные.
Задача тематического моделирования — по заданной коллекции документов найти такое распределение слов в темах и тем в документах, которое наилучшим образом приближает известное нам распределение слов в документах.
Примечание: Цель статьи не погрузить в математический аппарат тематического моделирования, а рассказать, как оно помогло оптимизировать бизнес. Подробно почитать про математику можно в этом прекрасном туторе о вероятностном математическом моделировании.
В качестве примера можно посмотреть на распределение тем в сказке «О рыбаке и рыбке». Заметно, что тематическая модель выделяет такие тематика как: морская, бытовая и о старике и старухе. При этом каждая тематика описывается специфичной для неё лексикой.
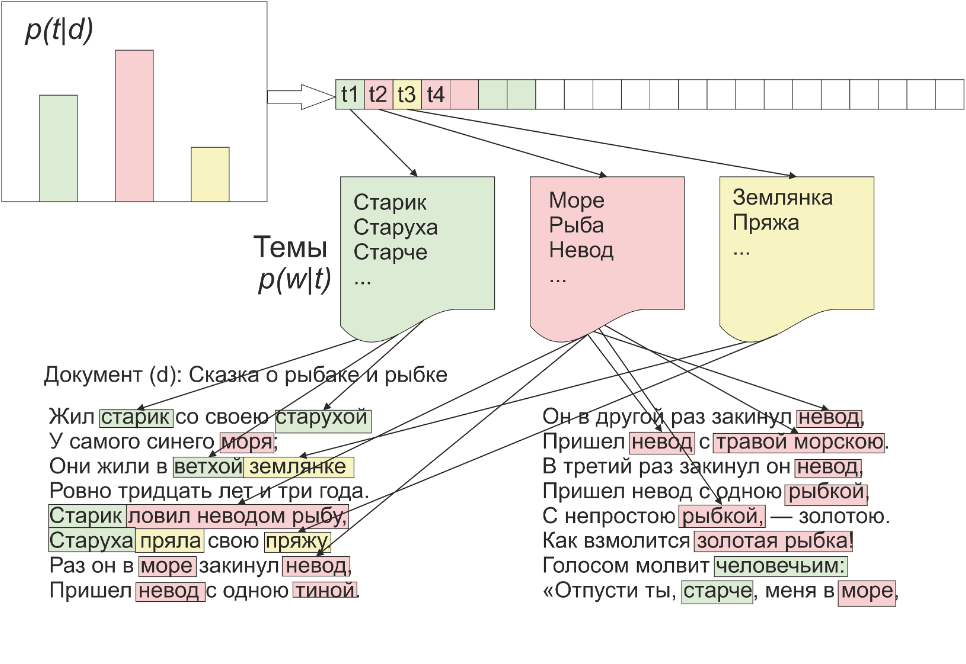 Пример формирования распределений тематической модели
Пример формирования распределений тематической модели
BigARTM
Первый шаг в любом проекте — выбор правильных библиотек и инструментов.
Наш выбор остановился на BigARTM. И на это есть ряд причин.
Первое — BigARTM покрывает все классические подходы тематического моделирования — PLSA и LDA.
Второе — позволяет использовать различные регуляризаторы, дополняющие модель полезными свойствами. Немного поподробнее расскажу про самые популярные:
Регуляризатор сглаженности/разреженности позволяет сделать все топики модели либо предметными, либо фоновыми. Фоновые темы содержат лексику, характерную для всей коллекции. Предметные, в свою очередь, содержат специфичную для темы лексику.
Декоррелятор повышает различность тем, удаляя дублирующие и похожие тематики.
Частичное обучение позволяет строить темы вокруг определенных термов, повышая интерпретируемость самой темы. Эти термы задаются самим пользователем.
Третье — в BigARTM реализован механизм разбиения коллекции на батчи, что позволяет не хранить её целиком в памяти, и производить параллельное обучение.
Алгоритм применения библиотеки
Перед обучением тематических моделей, важно правильно предобработать данные, потому что мы работаем с мешком слов.
В нашем случае мы прибегаем к:
лемматизации: одинаковые слова в разной форме — одни и те же слова;
удалению стоп-слов: предлоги, союзы, местоимения, числительные, ссылки, ФИО;
удалению низко/высоко частотных слов, характерных для всей коллекции, а также редких слов, которые вносят лишний шум при построении модели.
Обучение в BigARTM сильно похоже на обучение классических моделей машинного обучения. Первым делом нужно подобрать значения гиперпараметров: количество проходов по документу и коллекции, а также значения используемых регуляризаторов. После просмотра результатов обучения — графики обучения, график распределения тем в коллекции, значение perplexity, — принимается решение о подборе нового набора гиперпараметров, и повторного обучения или сохранении получившейся модели и анализе сформировавшихся тематик.
В качестве результатов мы можем посмотреть на распределение слов в теме, распределение тем в документах и на сами сформировавшиеся тематики.
Интерпретация тем
Пока что мы затронули лишь вопрос формирования тематик, но не их интерпретацию. Это было одним из основных требований к результатам моделирования, потому что мы имеем дело с обучением без учителя.
Первый и самый очевидный способ — описать тематику набором топ слов, слов, принадлежащих теме с наибольшей вероятностью.
Пример интерпретации на основе топ-слов:
«кэшбэк, акция, друг, начисление, начислять, месяц»
Но так мы получим достаточно слабую интерпретацию, как и не сможем посмотреть на содержимое. Перейдя к биграммам, мы сможем улучшить интерпретацию, но всё также не будем иметь представления о экспертизах, попавших тему.
Пример интерпретации на основе биграмм:
«кэшбэк_начислять, акция_друг, начисление_кэшбэк, месяц_начислять, кэшбэк_неначислять»
Логичное решение добиться максимальной интерпретации и раскрыть содержимое — взять топ n экспертиз из темы. Но в таком случае мы сталкиваемся с проблемой долгой вычитки, от которой так хотим избавиться (экспертизы содержат в среднем 150 слов). А также не сможем раскрыть весь спектр темы — возможно топ n экспертиз будут затрагивать лишь малую часть проблематик.
Поэтому мы решили использовать следующий подход, предложенный К. Воронцовым для одной из дипломных работ:
Разбиваем экспертизу на предложения по точкам. Получившиеся предложения прогоняем в предобученной модели BigARTM, и выкидываем предложения, которые принадлежат к теме с малой вероятностью.
Строим мешок слов на получившихся предложениях, на основе которого формируем матрицу схожести, используя расстояние по жаккарду, потому что хотим оценить расстояние между предложениями по мешку слов, и прогоняем её через алгоритм кластеризации Affinity Propagation. Такой подход позволяет нам не задумываться о количестве необходимых кластеров для каждой тематики, а также построить схожесть экспертиз на основе пересечения слов.
Выбираем предложения, являющиеся центрами кластеров и наиболее близкие к ним. Тем самым, создаём семантические ядра, и формируем тот самый спектр, покрывающий всю тематику.
Выбрасываем из получившейся суммаризации технические предложения, если такие попались.
Пример суммаризации по теме: «Выплаты по акциям и кэшбэк».
Клиент поставил оценку 1, потому что не получил кэшбэк по акции «Получайте призы за покупки кредитной картой Visa Альфа-Банка», так как кэшбэк ограничен и не может быть начислен всем участникам акции из-за её высокой популярности. Хочет расторгать договор по КК.
Клиент хотел узнать, какую сумму нужно потратить в июле, чтобы получить повышенный кэшбэк. Оператор ответил не по теме вопроса. Также клиент пожаловался, что из приложения убрали данную информацию и теперь сложно разобраться в тратах.
Уточнить срок выплаты кэшбэка по акции «Кэшбэк по кредитной карте 100 дней без процентов». Не получил ответ на вопрос; сотрудник ответил шаблоном, стал предлагать кредит.
Клиент обратился для уточнения информации по выплате «Получайте призы за покупки картой Visa Альфа-Банка». Клиент один из первых начал участие в акции, но выплаты не было, хотя со стороны клиента условия были выполнены.
Заметно, что суммаризация получилась достаточно интерпретируемой: изначально не зная, что тема о кэшбэке и акциях, это можно легко и быстро понять.
Установка доверия к модели
Не так сложно построить модель, как убедить бизнес, начать ею пользоваться, поменяв устоявшиеся процессы. Тем более для тематических моделей не существует таких объективных метрик качества, как условный f1 score для классификации.
Мы можем посчитать coherence score для каждой тематики — метрика, согласно научным статьям, наилучшем образом коррелирующая с интерпретируемость. Но на практике в нашем случае оказалось, что она не так точно отражает действительность, как хотелось бы. Тем более нам хочется также проверить темы на консистентность и гранулярность.
Поэтому мы придумали следующие три метрики качества:
Точность — суммаризующие предложения для каждой темы должны совпадать с названием темы. Означая, что, например, в тему о выплатах по кэшбэку не должны просачиваться предложения о проблемах с комиссией.
Полнота — тематическая модель должна отыскать все проблематики, которые до этого выделил эксперт. А в идеале ещё и найти новые.
Дельта — доли тематик в суммаризации должны совпадать с долями этих же самых тематик в изначальной коллекции: с той коллекцией, которую уже вычитал эксперт.
Средняя точность у нас получилась 82%, полнота больше 100% — мы смогли найти больше проблематик чем эксперт, а дельта сохранилась в районе +/- 8%.
Результаты
Было | Стало | |
Продолжительность | 15 дней | 3 дня |
Количество сотрудников | 8 человек | 3 человека |
Объем экспертиз | 1.5 — 2 тысячи | Без ограничений |
Каналы и продукты | С низкой оценкой | Без ограничений |
Как видно из таблицы, используя выше описанный алгоритм, мы смогли ускорить вычитку и сократить количество сотрудников, необходимых для неё. А также теперь мы может анализировать неограниченный набор экспертиз, как и любой канал.
Веб-интерфейс
Но на этом мы решили не останавливаться и разработать веб-сервис для тематического моделирования с суммаризацией, уйдя в сторону от Jupyter тетрадок.
Что же послужило нам основной мотивацией это сделать?
Любая даже самая интересная задача со временем может стать рутинной. Можно провести аналогию с соревнованиями по машинному обучению. По началу очень интересно копаться в данных, выстраивать пайплайны с нуля, пробуя различные методы.
Но, как правило, ближе к концу идеи заканчиваются (особенно если вы участвуете один) и начинается борьба за тысячные посредством ансамблей и тюнинга всевозможных гиперпараметров. Это может немного утомить. Рутинна и цикличность послужили первой причиной отойти от jupyter тетрадок.
Дальше мы захотели сделать аналитиков клиентского опыта независимыми от нас. Другими словами, разработать такой инструмент, который бы позволил анализировать коллекции экспертиз в любой момент времени, при этом не требуя специфичных знаний о тематическом моделировании.
Также мы решили избавиться от перебросок экселек по почте и хранить все данные и результаты в одном месте.
Интерфейс получился достаточно простым и интуитивно понятным. Backend мы реализовал на Flask, а frontend на HTML/CSS/AJAX. Пример работы можете посмотреть на видео:
На странице с инструкцией приведен подробный мануал как запускать модель на обучение, правильно подбирать гиперпараметры и интерпретировать результаты. У пользователя есть возможность загрузить файл как вручную, так и из таблиц Hadoop, который можно выбрать при запуске модели.
На главной странице происходит подбор гиперпараметров и запуск модели на обучение, а также предоставлена возможность воспользоваться функцией частичного обучения и просмотра, редактирования и загрузки стоп-слов.
В качестве результатов выводятся графики обучения, график распределения тем в документах, а также топ-слова тем и суммаризация тематик. У пользователя также есть возможность изменить названия сформированных топиков онлайн и выгрузить результаты себе на компьютер.
Обученные модели можно запустить в режиме инференса, получая сформированную ранее суммаризацию, или, используя модель на новых датасетах, предварительно не обучая её.
Аналитики из команды клиентского опыта уже активно пользуются разработанным инструментов, не прибегая к нашей помощи, пройдя перед этим небольшое обучение.
BertTopic
По мере развития интерфейса мы также интегрировали BertTopic подход к тематическому моделированию, который использует предобученные sentence transformers для формирования тематик, а именно:
Используем обученный берт в инференс режиме, для каждого документа генерируя уникальный эмбеддинг.
Снижаем размерность сформированных эмбеддингов с помощью UMAP, который сохраняет одновременно больше и локальных и глобальных признаков чем PCA и t-SNE.
Эмбеддинги низкой размерности кластеризуем с помощью HDBSCAN, отфильтровывая аутлаеры, и, формируя для них отдельную тематику, что позволяет повысить репрезентативность топиков.
Описываем сформированные топики наиболее релевантными термами из документов, которые получаются с помощью TF-IDF.
На практике оказалось, что BertTopic лучше справляется с анализов коротких и слабо структурированных текстов (свободные комментарии клиентов, переписка клиентов с оператором, транскрибация ivr), чем классическое тематическое моделирование.
Заключение
Хоть статья и получилась относительно небольшая, путь от постановки бизнес-задачи до разработки и внедрения веб-приложения получился значительным — примерно 7–8 месяцев.
За это время:
мы убедили бизнес-заказчика в эффективности подхода;
застали смену руководителя проектов;
проанализировали всевозможные подходы к тематическому моделированию;
своими силами проссуммаризовали десятки файлов с экспертизами по различным каналам и продуктам;
освоили Flask;
а также успели переиспользовать построенный пайплайн для анализа описаний транзакций клиентов А-Клуба (private banking Альфа-Банка) и комментариев операторов ВЭД (внешнеэкономическая деятельность).
Сейчас сервисом, помимо команды клиентского опыта, активно пользуется команда КЦ для поиска новых интентов в IVR и анализа чатов с оператором, что доказывает его универсальность.
Вместо выводов хочется пожелать, оставаться настойчивым и не опускать руки, если у вас что-то не вышло с первого или второго раза.
Ресурсы
Разбор BigARTM и классических тематических моделей
Документация BigARTM
Лекция по BigARTM
BertTopic
