Как Data Science помогает разрабатывать лекарства
На протяжении более чем десяти лет я профессионально занимаюсь анализом медицинских данных и участвую в разработке инновационных препаратов. Не скрою, меня приятно удивляет, что в данный момент наука о данных (Data Science) привлекает все больше внимания и захватывает умы максимально широкой аудитории. Тем не менее, меня как ученого несколько расстраивает тот факт, что воображение коллективного разума видит это направление как работу волшебных «black-box» алгоритмов, почти магическим образом заменяющих труд ученых и врачей в поисках панацеи. После моих докладов на различных мероприятиях я все чаще слышу вопросы: зачем все так усложнять? почему бы не накинуть нейросеточку на эти данные? Такие ситуации и подтолкнули меня написать эту статью о методах Data Science, которые действительно востребованы при разработке лекарственных препаратов.
Поиск виновных
Стоит сказать, что разработка инновационных препаратов — долгий, дорогой и очень сложный процесс. Так, из 10 000 молекул, предложенных химиками, для тестирования на людях отберут не более 10, из которых лишь одна дойдет до пациентов. Средняя стоимость разработки препарата составит более двух миллиардов долларов, а весь процесс займет не менее 15 лет. За это время накопится огромное количество разнородной информации, которую фармкомпании будут использовать для принятия самых разных решений. Давайте посмотрим, что это за информация, как и какие решения она помогает принимать, начиная с разработки фундаментальной идеи и вплоть до этапа реальной помощи пациенту.
О факте болезни мы зачастую узнаем по симптомам, однако за симптомами скрываются сложные процессы, происходящие в нашем организме иногда на протяжении долгих лет, именно их и принято называть патогенезом заболевания. Чтобы разработать лекарство, нам нужно в первую очередь найти мишени, то есть тех участников патогенеза (например, клетки или их компоненты, сигнальные молекулы), воздействие на которые может предотвратить или замедлить развитие болезни, а в идеале полностью вылечить пациента.
Дело осложняется тем, что к появлению схожих симптомов могут приводить совершенно разные механизмы. В таком случае терапия, показавшая высокую эффективность для одного пациента, может оказаться совершенно бесполезной для другого. Избежать нерационального использования препаратов помогает персонализированный подход, предполагающий назначение лечения исходя из индивидуальных особенностей течения болезни, установленных на основе измерений уровня тех или иных участников патогенеза, именуемых биомаркерами. Для таких комплексных заболеваний, как, например, астма, разнообразие мишеней и связанных с ними биомаркеров может исчисляться десятками и представлять собой запутанную сеть взаимодействий (рис. 1).
![Рисунок 1. Мишени и компоненты патогенеза астмы [Gandhi F., S.-P. N. Haydée, G.-S. Lizbeth et al., Neuroimmune Pathophysiology in Asthma. Front Cell Dev Biol. 2021; 9: 663535].](https://habrastorage.org/r/w780q1/getpro/habr/upload_files/1b1/e5c/2c5/1b1e5c2c5e799fa935998545c2874ee7.jpg)
Рисунок 1. Мишени и компоненты патогенеза астмы [Gandhi F., S.-P.N. Haydée, G.-S. Lizbeth et al., Neuroimmune Pathophysiology in Asthma. Front Cell Dev Biol. 2021; 9: 663535].
Распутывать подобные сети патогенеза и находить биомаркеры нам помогают такие научные дисциплины, как биоинформатика и системная биология, объединяющие широкую группу разнообразных методов анализа данных генома, протеома, метаболома и других »-омов». Инструментами могут выступать алгоритмы машинного обучения, помогающие извлекать из последовательностей нуклеотидных оснований или аминокислот различную информацию для реконструкции сигнальных путей и метаболических каскадов.
Отбор кандидатов
Представим, что мы выбрали наиболее перспективную мишень и теперь нужно создать молекулу, которая взаимодействует с ней определенным образом. В этой нелегкой задаче нам могут помочь структурное моделирование и хемоинформатика. Данное направление позволяет на основе строения молекул оценить их связывание с мишенью и стабильность в организме и тем самым помочь химикам-синтетикам создать наиболее перспективных кандидатов.
Экспериментальная проверка результатов структурного моделирования проходит с помощью исследований в пробирке (in vitro), которые позволяют оценить потенциал отобранных молекул и выбрать наиболее перспективные из них для дальнейшего тестирования на живых организмах (in vivo). В in vitro исследованиях изучают активность и некоторые показатели токсичности, добавляя различные концентрации препарата к тем или иным клеткам или ферментам. Например, известно, что онкологические препараты действуют как на раковые, так и на здоровые клетки. Наш идеальный кандидат — тот, который в малых концентрациях подавляет рост раковых клеток, а токсическое действие на здоровые клетки проявляет только при очень больших концентрациях. Как говорил великий Парацельс, «все есть яд и все — лекарство; то и другое определяет доза», и даже дистиллированная вода может убить, как в случае с Дженифер Стрендж.
На этом этапе у нас еще очень мало информации, но мы уже можем количественно оценить некоторые параметры активности и токсичности препаратов, например, при помощи Emax модели.

Где Cdrug — концентрация препарата, Fmax и EC50 параметры уравнения.
Данное уравнение мы можем использовать, чтобы количественно охарактеризовать рабочий диапазон концентраций молекул и за счет этого выбрать лучшего кандидата (рис. 2).
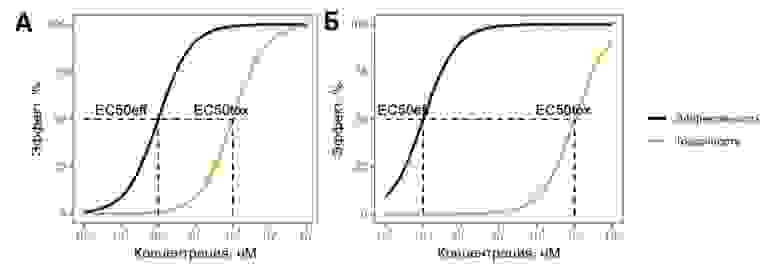
Рисунок 2. Пример изменения показателей эффективности и токсичности при увеличении концентрации двух препаратов, рассчитанного на основании Emax модели. Препарат Б является лучшим кандидатом, так как концентрации, обеспечивающие максимальный эффект, не оказывают токсического действия.
Казалось бы, все очень просто… но, к сожалению, то, что мы можем увидеть в пробирке, зачастую очень далеко от реальной практики… Именно поэтому после in vitro экспериментов мы должны перейти к доклиническим исследованиям наших веществ-кандидатов на лабораторных животных, чтобы определить те же показатели стабильности, активности и токсичности, но уже в условиях живого организма. Стоит сказать, что поддерживать постоянную концентрацию лекарства в теле значительно сложнее, чем в пробирке, ведь оно пытается избавиться от чужеродной субстанции всеми возможными способами. Поэтому препараты, как правило, даются с определенной периодичностью, например, раз в день или неделю. Доклинический этап в общей сложности включает в себя десятки in vivo экспериментов и проводится как минимум на трех видах животных. Токсикологические исследования включают оценку канцерогенного и тератогенного потенциалов, органоспецифической токсичности и различных лабораторных тестов. Полученные в процессе экспериментов данные можно разделить на две группы: фармакокинетику — изменения концентрации препарата в плазме крови (а при необходимости и в других органах, где препарат должен действовать) и фармакодинамику — желательные и побочные ответы организма на препарат.
На этом этапе у исследователей возникает множество вопросов — как часто и в каких дозах давать препарат, чтобы обеспечить рабочий диапазон концентраций? При какой дозе мы достигаем максимального эффекта? У какой из выбранных молекул оптимальный набор свойств? Какие факторы могут оказывать влияние на эффективность лечения? А на вероятность возникновения побочных эффектов? Количество вопросов столь велико, что для экспериментального ответа на каждый из них может не хватить ни времени, ни лабораторных животных… Здесь нам помогает фармакометрика — дисциплина, которая позволяет количественно описать взаимосвязь между дозой препарата, его концентрацией в организме и биологическими эффектами. Одним из ее базовых инструментов являются математические модели фармакокинетики и фармакодинамики (ФК-ФД модели), которые при помощи систем, состоящих из 3–4 уравнений, описывают динамику изменения концентрации препарата в крови и связывают ее с фармакодинамическими эффектами (рис. 3).
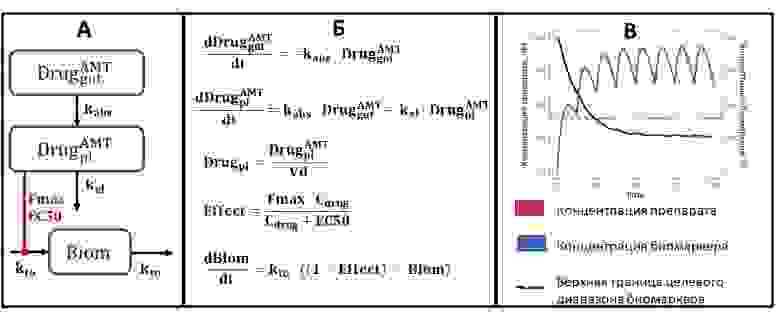
Рисунок 3. Пример математической модели фармакокинетики и фармакодинамики. А. Схема модели; Б. Система обыкновенных дифференциальных уравнений (ОДУ); В. Результаты расчетов — мы подобрали режим терапии (дозу и частоту введения препарата), обеспечивающий целевое снижение биомаркера.
Однако такой простой математики не хватит, чтобы ответить на все интересующие разработчиков вопросы. Например, чтобы лучше понять, что происходит с молекулой в отдельных тканях и спрогнозировать то, как она поведет себя в человеческом организме, используется физиологически-обоснованное моделирование фармакокинетики (от анг. PBPK, physiologically-based pharmacokinetic modeling). PBPK модели могут включать сотни уравнений, подробно описывающих процессы высвобождения действующего вещества из таблеток/патчей/капсул (что может быть важно для выбора оптимальной лекарственной формы), распределения и метаболизма препарата в органах и тканях (мы хотим быть уверены, что препарат проникает туда, куда надо, и не накапливается там, где не надо) или его метаболизм в печени (индивидуальные особенности работы ферментов печени могут сильно влиять на выведение препаратов). Разработать такую модель с нуля непросто, однако существуют готовые решения, где уже описаны типовые фармакокинетические процессы.
С другой стороны, более детальное описание эффекта препаратов на компоненты патогенеза заболевания обеспечивают системно-фармакологические модели (от анг. QSP, quantitative systems pharmacology modeling), позволяющие ученым прогнозировать эффективность комбинированного лечения, проводить поиск предиктивных биомаркеров и лучше понимать механизмы действия лекарств. Как можно предположить, создание таких моделей — очень наукоемкий процесс, требующий анализа и интерпретации большого количества медицинской и биологической информации. Здесь, в отличие от PBPK, разработка готовых решений сложнее, так как процессов, происходящих с препаратом в организме, ограниченное количество, а вот процессов, которые могут поломаться и привести к болезни, невообразимо много, поэтому такие модели, как правило, разрабатываются отдельно для каждого заболевания или группы заболеваний со схожим патогенезом. Значения параметров PBPK и QSP моделей можно извлечь из опубликованных источников (например, данных о продолжительности жизни клеточных популяций, плотности рецепторов и т. д.) после чего «потренировать» модель на наших данных. Такой подход позволяет интегрировать множество разнородной экспериментальной информации в единое математическое описание, представляющее собой четкое теоретическое представление о патологическом процессе.
![Рисунок 4. Пример системно-фармакологической модели, описывающей действие комбинации радио- и иммунотерапии на динамику роста опухоли. А. Структура модели; Б. Расчеты активности различных режимов комбинированной терапии [Kosinsky Y, Dovedi SJ, Peskov K, et al., Radiation and PD-(L)1 treatment combinations: immune response and dose optimization via a predictive systems model. Journal for ImmunoTherapy of Cancer 2018;6:17. doi: 10.1186/s40425-018-0327-9].](https://habrastorage.org/r/w780q1/getpro/habr/upload_files/61f/894/f55/61f894f551e2e805c625200590fbb4f9.jpg)
Рисунок 4. Пример системно-фармакологической модели, описывающей действие комбинации радио- и иммунотерапии на динамику роста опухоли. А. Структура модели; Б. Расчеты активности различных режимов комбинированной терапии [Kosinsky Y, Dovedi SJ, Peskov K, et al., Radiation and PD-(L)1 treatment combinations: immune response and dose optimization via a predictive systems model. Journal for ImmunoTherapy of Cancer 2018;6:17. doi: 10.1186/s40425–018–0327–9].
Вперед к людям!
Ура! Наш препарат показал хорошие результаты в доклинических исследованиях — он лечит больных животных и при этом относительно безопасен, а это значит, что мы можем начинать клинические исследования, то есть тестировать препарат на людях. В первой фазе исследований, как правило, принимают участие десятки здоровых добровольцев, которым дают возрастающие однократные и многократные дозы препарата. Надо сказать, что выбор диапазона доз для первой фазы — ответственный и зачастую очень рискованный шаг, в чем ученые удостоверились после инцидента с молекулой TGN1412, где неправильные расчеты сделали инвалидами несколько участников исследований. Провести предварительную оценку фармакокинетических параметров и обосновать режим терапии для человека на основании доклинической информации ученым помогают представленные выше PBPK модели.
В процессе испытаний первой фазы мы получаем фармакокинетические данные, на основании которых с помощью некомпартментного анализа можем рассчитать некоторые важные характеристики — системную экспозицию, период полувыведения и максимальную концентрацию препарата. Это простой и доступный метод анализа данных, однако он является строго описательным, достаточно требователен к данным и применим для ограниченного числа случаев. В силу этого разработчики лекарств и здесь прибегают к помощи фармакометрики и активно применяют математические модели.
В случае, если наш препарат не вызвал серьезных токсических эффектов у здоровых добровольцев, мы можем переходить ко второй фазе и изучать эффективность различных режимов терапии у сотен пациентов с определенным заболеванием. В процессе исследований, в дополнение к фармакокинетическим показателям и оценке токсичности, мы будем измерять множество показателей, связанных с эффективностью терапии. И здесь выбор диапазона доз критически важен, ведь если дать слишком мало, то эффекта не будет…. Здесь нам могут помочь QSP модели, основанные на доклинической информации и данных препаратов-конкурентов.
Допустим, мы собрали данные по эффективности и должны выбрать максимально эффективную и в то же время переносимую дозу. Наиболее простым подходом к анализу дозозависимых терапевтических и токсических эффектов терапии, наблюдаемых во второй фазе, является оценка зависимости между дозой или интегральными характеристиками индивидуальных фармакокинетических профилей пациентов (например, максимальных концентраций) и показателями эффективности и токсичности посредством различных функциональных зависимостей (например, Emax моделей в случае непрерывной величины, логистической регрессии в случае дихотомического исхода, моделей пропорциональных рисков Кокса или Joint моделей, если речь идет о данных выживаемости). Такой подход именуют анализом зависимости доза/экспозиция-ответ (анг. dose/exposure-response analysis).
На этом этапе я хочу обратить внимание на один крайне важный момент: все люди разные и по-разному могут реагировать на лечение. Разработчикам необходимо понимать, какие особенности организма влияют на фармакокинетику и фармакодинамику препарата, а также оценивать вариабельность этих показателей. В решении этой задачи на помощь приходят нелинейные ФК-ФД модели со смешанными эффектами, в которых те или иные параметры предполагаются различными у пациентов и зависят от индивидуальных особенностей их организма. Перед аналитиком в данном случае стоит очень сложная задача, ведь надо выбрать не только оптимальную структуру уравнений, но и перебрать сотни статистических моделей. Но игра стоит свеч, ведь без соответствующих расчетов минздравы разных стран просто не выпустят препарат на рынок.
На завершающей, третьей, стадии клинических исследований эффективность выбранной дозы препарата подтверждается уже на тысячах пациентов. Ставки при этом очень высоки, потому бюджет подобных испытаний может превышать сотню миллионов долларов и провал этой стадии может обернуться банкротством для фармацевтической компании. Здесь нам важно доказать, что наш препарат не просто работает — он значительно лучше существующих стандартов лечения. В выборе рационального дизайна подобных исследований нам помогут мета-анализ и мета-регрессия — методики, позволяющие максимально точно учесть всю необходимую для дизайна исследования историческую информацию. Например, мы можем собрать опубликованные результаты второй и третьей фаз по препаратам-конкурентам и оценить наши шансы превзойти их на основе данных второй фазы для нашей молекулы. По своему опыту могу сказать, что в отечественной медицине почему-то принято сводить мета-анализ к расчету взвешенного среднего результата нескольких выбранных на усмотрение ученого исследований, хотя на самом деле существует множество продвинутых методологий, таких как сетевой и байесовский мета-анализы, позволяющие извлечь из данных действительно уникальные инсайты, критически важные как для дизайна отдельного испытания, так и для общей оценки эффекта внедрения новой терапии в систему здравоохранения.
![Рисунок 5. Использование различных видов моделирования в разработке лекарственных препаратов. Адаптировано из [Helmlinger G, Al-Huniti N, Aksenov S et al., Drug-disease modeling in the pharmaceutical industry - where mechanistic systems pharmacology and statistical pharmacometrics meet. Eur J Pharm Sci. 2017 Nov 15;109S:S39-S46].](https://habrastorage.org/r/w780q1/getpro/habr/upload_files/697/2e2/a85/6972e2a8516afae740bb3662f4bc8a6a.jpg)
Рисунок 5. Использование различных видов моделирования в разработке лекарственных препаратов. Адаптировано из [Helmlinger G, Al-Huniti N, Aksenov S et al., Drug-disease modeling in the pharmaceutical industry — where mechanistic systems pharmacology and statistical pharmacometrics meet. Eur J Pharm Sci. 2017 Nov 15;109S: S39-S46].
Вот вроде бы и все, но к чему весь этот лонгрид? В нем я нисколько не умоляю роли нейронных сетей, но хочу расширить кругозор читателя и показать, что анализ данных в медицине требует многогранной экспертизы в профильных областях, которая позволяет интерпретировать расчеты в контексте текущих биологических знаний, вести диалог в кросс-функциональных командах и осознавать применимость той или иной аналитики в каждом конкретном случае. Даже если нам удастся написать волшебную «нейронку», способную вобрать в себя все существующие медицинские знания и найти панацею от всех болезней, мы как ученые все равно не можем ей слепо доверять и должны изучать множество аспектов, связанных с воздействием лекарств на организм, ведь ценой неправильных расчетов могут стать человеческие жизни.
Знакомы ли вы с какими-либо из этих методов?
Хотели бы узнать про какой-либо из них поподробнее?
