Как автоматически переписать текст другими словами, сохранив смысл? Рассказываем про рерайт-сервис

Часто при работе с текстами мы хотим не только выделить главное из больших отрывков, но и переписать текст, сохранив его смысл. В предыдущем посте мы рассказали, как команда SberDevices делала AI Service суммаризатора. Сегодня давайте поговорим про наш опыт создания не просто парафразера, а именно рерайтера текста. В связке эти инструменты могут быть полезны для множества практических задач. Демо обоих сервисов доступны в маркетплейсе AI Services.
Чем рерайт отличается от парафраз
В широком смысле перефразирование текста означает переписать текст так, чтобы новый текст отличался от старого по написанию, но был идентичен по смыслу. При этом в идеале новый текст должен выглядеть естественно и по стилю не отличаться от оригинала, иначе мы перейдем в задачу style transfer.
Огромное количество работ посвящено непосредственно задаче парафразинга для русского языка на уровне предложений. Есть множество датасетов, таких как:
Paraphraser Plus;
корпус парафраз, собранных Давидом Дале;
корпус парафраз из новостных заголовков, собранный Екатериной Пронозой;
корпус парафраз-заголовков, собранный командой Вадима Гудкова.
И это далеко не весь перечень.
На базе этих корпусов есть также обученные модели в том числе на основе ruT5 и ruGPT3 (например, несколько моделей находятся в библиотеке russian_paraphrases, или например мультитасковая модель). Все эти модели довольно неплохо справляются с задачей перефразирования. Но всё равно есть проблемы с искажением смысла, где-то подобраны антонимы вместо синонимов, бывают некорректные конструкции при генерации и многое другое.
Кажется, что задача перефразирования спокойно переносится с уровня предложения на уровень текстов. Ведь что мешает просто разбить текст по предложениям и запустить парафразер? Рассмотрим пример:
Оригинал: На столе перед девушкой стоит прекрасная бутылка риохи. Она медленно пьет красную жидкость из бокала.
Генерация на уровне предложений (использована модель cointegrated/rut5-base-multitask Давида Далли):
На столе перед девушкой стоит прекрасная бутылка Риохи
В столе перед девушкой стоит прекрасная бутылка риохи
Для девушки перед столом стоит прекрасная бутылка раохи.
Она медленно пьет красную жидкость из бокала
Он медленно пьет красную жидкость из бокала
Она медленно пьет красную пищу из бокала
Генерация на уровне параграфа:
Девушка сидит за столом и с удовольствием пьет красное вино из бокала.
На столе перед девушкой стоит восхитительная бутылка риохи, и девушка медленно пьет ее из бокала.
На столе стоит прекрасная бутылка риохи, она медленно пьет красную жидкость из бокала.
Мы видим, что в рамках одного предложения можно найти корректный парафраз. Однако объединив таким образом предложения, особенно в которых детали переписаны некорректно, связность текста будет утеряна. В то время как генерация на уровне параграфа позволяет объединять предложения или, учитывая контекст, дать понимание модели, что красная жидкость — это вино.
С точки зрения лингвистики происходит переход с уровня семантики на уровень прагматики, когда контекст увеличен и влияет на значение текущего предложения. Парафразер смотрит лишь на лексические и грамматические признаки слов, но обработка текста целиком охватывает помимо чистой семантики такие явления как импликатура, диалоговые акты, релевантность, связи между предложениями. Если мы скармливаем модели текст по кусочкам, мы теряем огромное количество информации и возможность обучить модель учитывать контекст и дискурсивные особенности языка.
Поэтому в работе мы умышленно ставили задачу сделать сервис, который работает с текстами более одного предложения. Наша модель рерайтера умеет переписывать текст другими словами, сохраняет смысл исходного текста и при этом работает с последовательностями разной длины и доменов. Так, нами тестировались тексты новостей, художественной литературы, комментарии из социальных сетей, как совсем короткими (около 10 символов), так и длинными (около 2000 символов).
Как мы обучали и на чём
Для обучения мы специально выбирали тексты как разной длины, так и из разных доменов, так как для качественного работающего сервиса нам необходимо было учитывать различные тексты с прицелом на разнообразие целевых задач (контент сайтов, новости, отзывы, диалоги и многое другое).
Данные для обучения можно разделить на блоки:
Лайфхаки сбора данных для рерайтинга:
Так как мы хотим получить решение для рерайтинга, а не суммаризации или симплификации (упрощение текстов, подробнее для русского можно почитать тут), нам очень важна длина текстов. Хороший хинт в этом случае, это обучать пары (оригинальный текст → целевой текст) в обе стороны! В таком случае модель не обучится всегда делать текст короче или наоборот длиннее. При этом количество примеров в обучении у вас увеличится.
Переводы позволяют получить тексты разных доменов. В простых случаях фильтруются автоматическими метриками.
Очень часто текст всё равно при переводе или какой-либо автоматической обработке текстов искажается. Мы советуем перепроверять разметку, если у вас есть возможность, с помощью краудсорсинга — чтобы потом использовать данные, например для классификатора. Часть данных, особенно парафраз, мы тщательно проверяли на несоответствия. В том числе классические случаи в датасетах типа, «Я съела сыр» → «Я поел сыр», когда меняются род или местоимения, хотя смысл действия по сути тот же.
Всего собранных и отфильтрованных данных — около 7000 примеров. На полученном корпусе с помощью модели ruT5-large мы обучили наш рерайтер.
Классификатор
В процессе сбора данных, экспериментов с парафразами и рерайтом, а также краудсорсинговой оценки пар [оригинальный текст — сгенерированный] мы получили около 11 тысяч примеров для бинарной классификации. Обучив на этих данных Roberta-large, мы получили модель-ранжировщик, которая решает задачу детекта парафраз. Благодаря данной модели в демо-рерайте можно выбрать из множества сгенерированных кандидатов наиболее релевантный вариант.
На тестовом сете из разных текстовых доменов (брались тексты из социальных медиа (SocMedia), литературы (Literature), новостей (News) и отзывов (Reviews), а также отфильтрованные перефразированные предложения) мы замерили сгенерированные рерайтером примеры. Генерировали методом random sampling (параметры генерации top_p=0.90, temperature=0.95, repetition penalty=1.5), из пяти примеров классификатором выбирался лучший.
Для пар [оригинальный текст — сгенерированный текст] мы посчитали автоматические метрики:
Mean Bleu — средняя оценка по всем текстам метрики BLEU (BLEU-1).
Mean Rouge — средняя оценка по всем текстам метрики ROUGE (ROUGE-L).
Bert score — средняя оценка по всем текстам метрики BertScore.
Mean LABSE score — средняя оценка по всем текстам метрики LABSE.
Sentence repeat — процент предложений, схожих с оригинальным текстом.
BERTscore | Rouge-L | Bleu | LABSE | Sentence repeat |
0.77 | 0.42 | 0.15 | 0.852 | 0.019 |
Каким образом производилась человеческая оценка рерайтера?
Для человеческой оценки рерайтера мы просили краудсорсеров оценить следующие параметры текста, получившегося в результате работы модели:
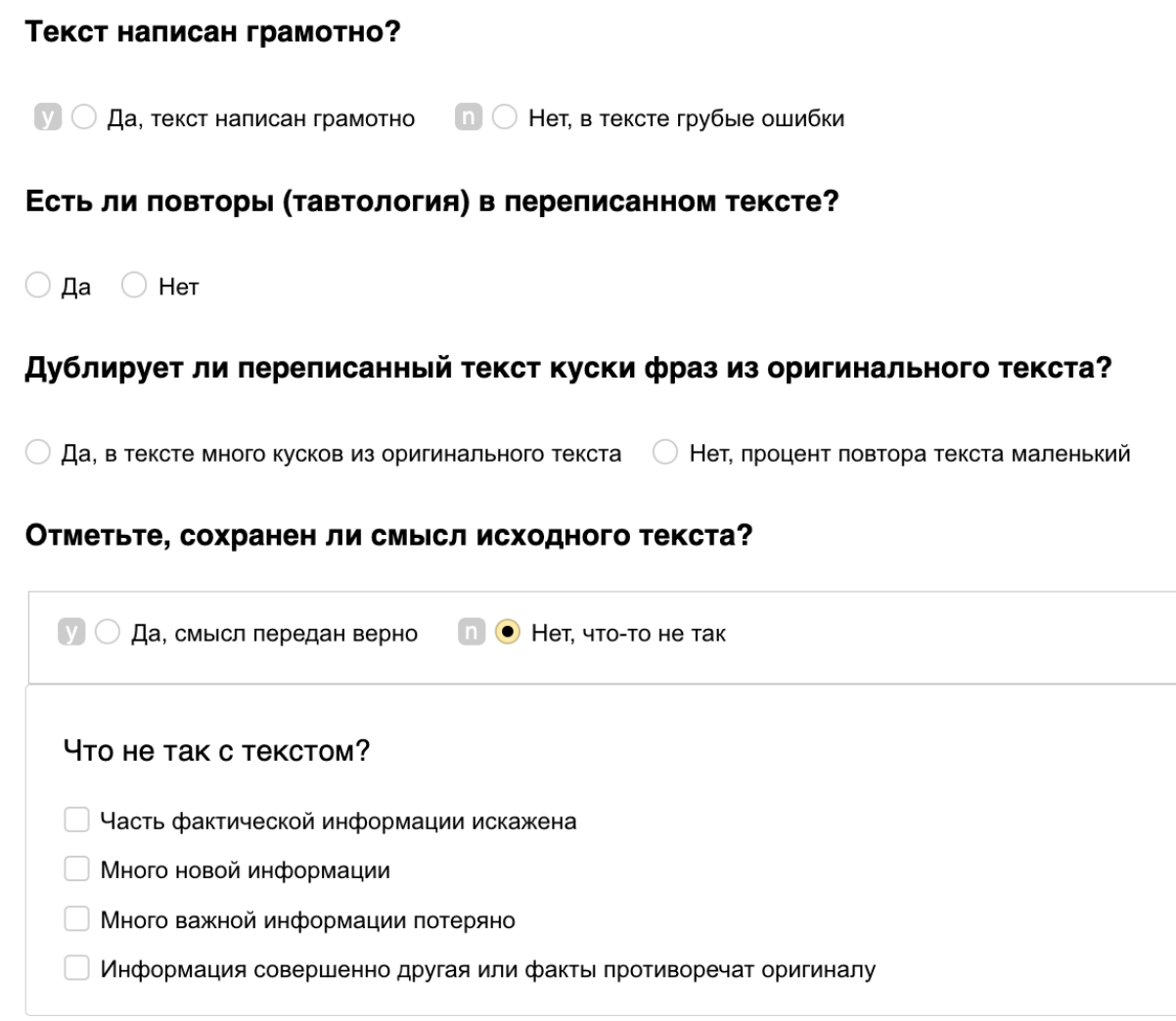 Интерфейс задания для оценки задачи рерайтинга
Интерфейс задания для оценки задачи рерайтинга
Grammar — грамматичность текста с точки зрения правил русского языка (орфография, пунктуация, согласование).
Originality — есть ли повторы в сгенерированном тексте, насколько текст оригинальный по сравнению с исходным.
Meaning — верно ли передан смысл исходного текста, если нет, то почему.
Полученная человеческая оценка модели с разным типом выбора кандидата (среднее по текстам разных доменов):
Метод ранжирования | Grammar | Meaning | Originality |
классификатор | 0.92 | 0.64 | 0.92 |
bertscore | 0.92 | 0.74 | 0.87 |
Оценка по различным доменам (способ ранжирования — bertscore):
Metric | Reviews | Literature | SocMedia | News |
Grammar | 0.94 | 0.81 | 0.95 | 1.0 |
Originality | 0.16 | 0.05 | 0.2 | 0.11 |
Meaning | 0.77 | 0.54 | 0.77 | 0.88 |
Как попробовать рерайтер в действии?
Демо Рерайтера, а также Суммаризатора текстов доступны в виде AI Service — деплоя, развёрнутого на платформе SberCloud ML Space.
Что это значит? Это бесплатные, развёрнутые в открытый доступ демо с привычным интерфейсом SWAGGER и возможностью отправки запросов по REST API.
 Выбор в интерфейсе AI Services сервиса Рерайт.
Выбор в интерфейсе AI Services сервиса Рерайт.
Для использования демо сервисов необходимо перейти в каталог AI Services на cайте SberCloud и выбрать «Рерайтер» или «Суммаризатор» — по кнопке «Подключить» появится доступ в интерфейс Swagger, с которым можно взаимодействовать. Вы также можете получитьтестовый доступ к платформе ML Space для запуска промышленных версий сервисов и всей подборки ruGPT-3 & family, включая эксклюзивные ruDALL-E, ruGPT-3 и ruCLIP, на высокопроизводительной инфраструктуре SberCloud.
Базовое использование модели в AI Service подразумевает работу с уже обученной моделью в режиме инференса. Модель умеет переписывать переданный текст. На вход подаётся оригинальный текст с настраиваемыми параметрами генерации, рерайтер генерирует кандидатов, выбирает лучшего и возвращает финальный результат.
 Чтобы в интерфейсе Swagger попробовать сервис
нажмите на кнопку «Try it out»
Чтобы в интерфейсе Swagger попробовать сервис
нажмите на кнопку «Try it out»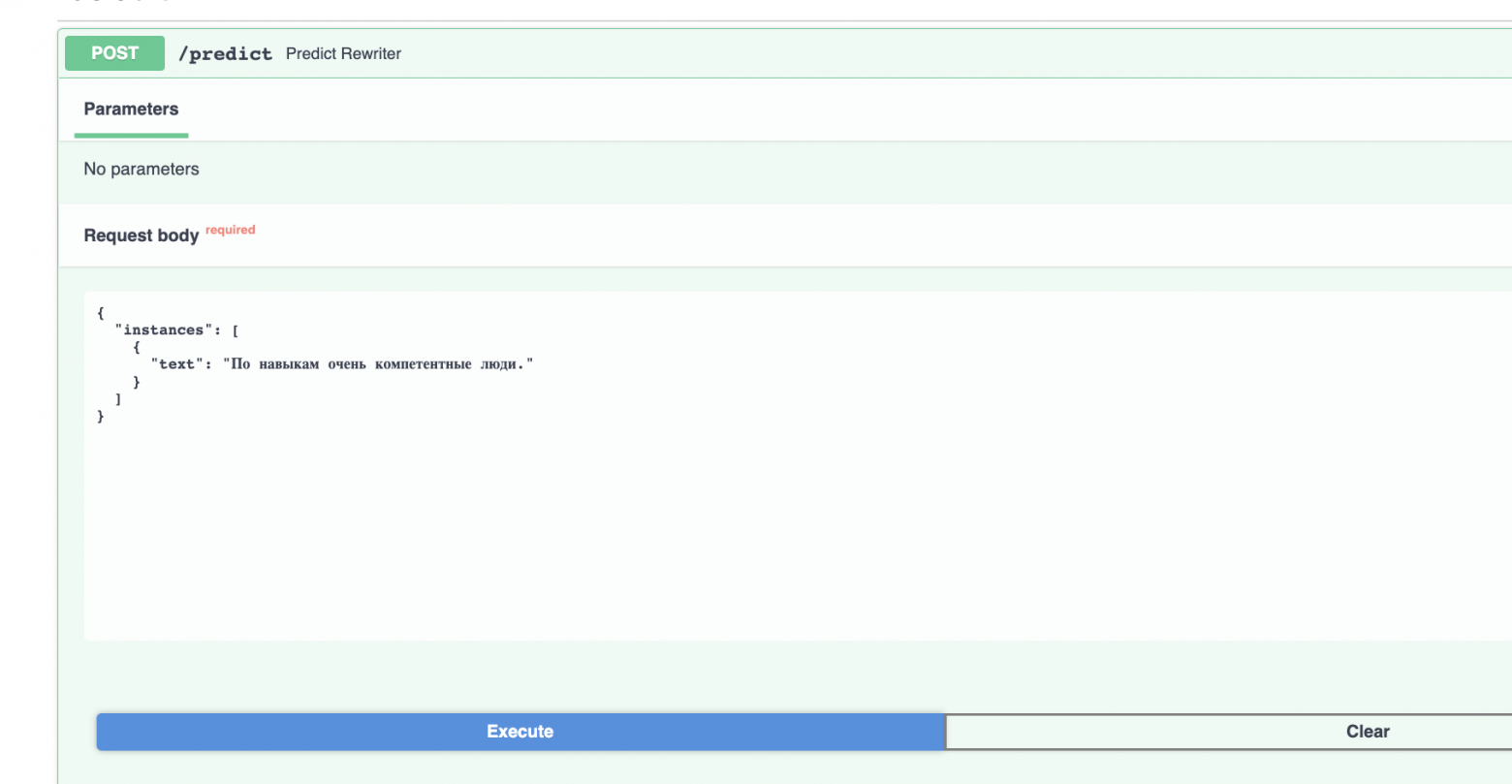 Напишите в открывшемся поле текст. Также можно указать параметры. Далее нажмите Execute.
Напишите в открывшемся поле текст. Также можно указать параметры. Далее нажмите Execute.  Если всё прошло успешно, вы увидите код 200 и результат ниже.
Если всё прошло успешно, вы увидите код 200 и результат ниже.
Входные параметры инференса для рерайтера:
text — оригинальный текст для переписывания; temperature — параметр температуры текста для генерации; top_k — параметр top_k текста для генерации; top_p — параметр top_p текста для генерации; num_return_sequences — количество примеров, из которых выбирается лучший рерайт, по умолчанию 5; range_mode — выбор метода ранжирования.
Для более разнообразных примеров можно варьировать параметры top_p, top_k, temperature. Чем больше примеров вы зададите в параметре num_return_sequences, тем больше шансов, что один из вариантов ранжирования выберет наиболее успешный.
Выходные параметры инференса для рерайтера выглядят следующим образом — возвращается словарь с полями:
predictions_all — все перефразированные варианты текста, которые проходят внутренние проверки; prediction_best — лучший сгенерированный вариант по методам ранжирования (bertscore, классификатор); origin — оригинальный текст.
Примеры рерайта
Запрос:
Текст: «Режим нерабочих дней, по заключениям экспертов, может прервать цепочку заражений коронавирусом.»
Параметры: temperature: 0.9, top_k: 50, top_p: 0.7, range_mode: bertscore
Результат
Все результаты (predictions_all): «По прогнозам экспертов, нерабочие дни могут прервать цепочку заражений коронавирусом.», «Эксперты: Режим нерабочих дней может остановить цепочку заражений коронавирусом.»,
«Власти рассчитывают остановить цепочку заражений коронавирусом в России.», «Эксперт назвал возможные причины отмены режима нерабочих дней.», «Эксперты полагают, что режим нерабочих дней может прервать цепочку заражений коронавирусом.»;
Лучшие результаты (prediction_best): 'bertscore' — 'По прогнозам экспертов, нерабочие дни могут прервать цепочку заражений коронавирусом.'
Запрос:
Текст: «Я так хочу на свою работу, так её люблю!»
Параметры: num_return_sequences: 10
Результат
Все результаты (predictions_all): 'Я так хочу быть на своем месте, такая она мне нравится!', 'Я так хочу работать, люблю!', 'Я так хочу на работу, я её люблю!', 'Я так хочу на работу, я ее люблю!', 'Я так хочу на свою работу, я её люблю!', 'Я так хочу, чтобы моя работа была моей работой ', 'Я так хочу на свою работу, что безумно её люблю!', 'Я так хочу на свою работу, я её очень люблю!', 'Я так хочу на свою работу, что меня это не останавливает!', 'Я так хочу на свою работу, мне её не хватает!';
Лучшие результаты (prediction_best): 'bertscore' — 'Я так хочу на работу, я её люблю!', 'classifier' — 'Я так хочу на свою работу, я её очень люблю!'
В заключение
Мы провели множество экспериментов с нашими генеративными моделями, которые показали, что их можно использовать для решения практических задач.
Напомним про преимущества наших полученных продуктов:
созданы на основе наших последних разработок и экспериментов с генеративными моделями;
сервисы умеют обрабатывать тексты из разных доменов, подходят для разных целевых заказчиков и кейсов;
в период бета-версии демоверсиями сервисов можно пользоваться бесплатно в маркетплейсе AI Services.
Мы будем рады, если вы попробуете использовать наши демо-рерайтер и демо-суммаризатор и вернётесь к нам с фидбеком и предложениями по улучшению.
