Как аудиокапчу ИТ-гиганта «обошли» во второй раз
Инженеры из Мэрилендского университета разработали систему, которая «обходит» reCAPTCHA от Google практически со стопроцентной вероятностью. Она задействует алгоритмы распознавания речи для решения аудиокапчи. Рассказываем, как это работает.

Фото photographymontreal / PD
Предыстория
Впервые разработчики из Мэрилендского университета представили систему для обхода «звуковой» reCAPTCHA (они назвали свое решение unCAPTCHA) в 2017 году. Тогда аудиокапча Google представала собой запись, в которой диктор называл последовательность цифр. Авторы использовали алгоритмы распознавания речи для автоматизации процесса ввода значений. Им удалось достигнуть точности решения капчи в 85%.
Информацию об уязвимости авторы направили в Google. ИТ-гигант обновил reCAPTCHA, в котором заменил последовательность цифр на фразы. Однако в конце прошлого года инженеры из Мэриленда доработали свою нейросеть. Ей удалось обойти обновленную аудиокапчу с точностью в 90%.
Как это работает
Бот заходит на страницу в интернете, защищенную reCAPTCHA, а затем совершает несколько действий, чтобы сымитировать поведение человека. После он кликает на капчу и выбирает вариант её решения с использованием аудиозаписи.
В версии unCAPTCHA от 2017 года аудиофайл разделялся на отрезки. Маркерами служили паузы между цифрами. В результате получалось несколько звукозаписей с отдельными словами. Эти записи программа разработчиков отправляла в облачные сервисы распознавания речи:
Затем unCAPTCHA v1 составляла так называемую фонетическую карту. В неё вносились ответы от разных систем для одного и того же отрывка. Далее, в дело вступала свёрточная нейросеть, которая выделяла из карты слова, которые не обозначали название цифры, исправляла ошибки и выбирала наиболее вероятный вариант ответа для заполнения reCAPTCHA. В целом процесс выглядит следующим образом:
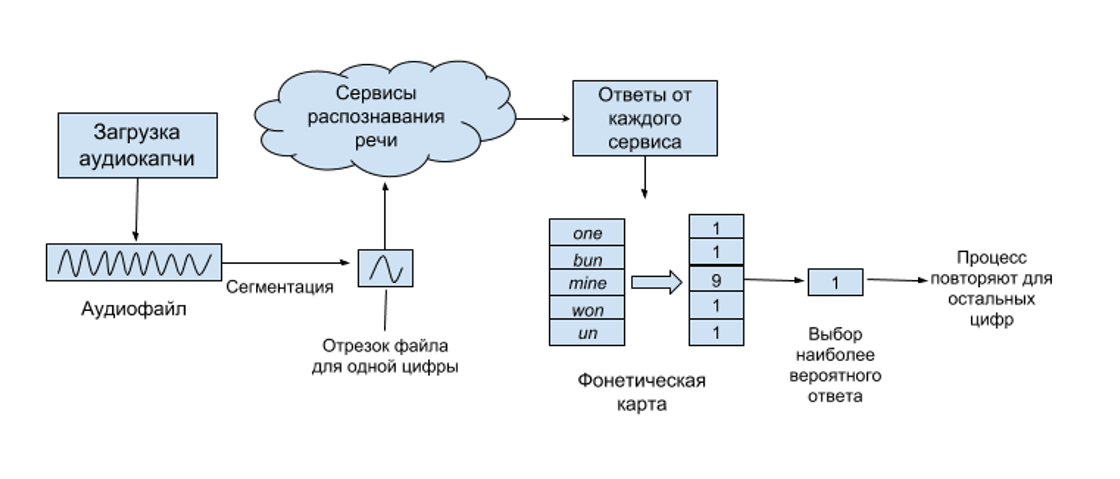
Во второй версии unCAPTCHA (которую представили в декабре) сегментация и фонетическая карта уже не понадобились. Обновленная капча Google использует вместо цифр отдельные фразы, а их облачные сервисы определяют лучше. Поэтому высокой точности распознавания аудиокапчи удалось достигнуть с помощью одного инструмента — Google Speech-to-Text. После анализа бот сразу вводит полученный текст в строку капчи.
Вот так выглядит отправка аудио в облако и ввод ответа (из репозитория на GitHub). Демонстрацию работы программы можно увидеть на этой gif-ке.
Что говорят о технологии
По словам авторов unCAPTCHA, новая версия капчи Google не усложнила, а, наоборот, упростила взлом. Теперь сервису для автоматического ввода не нужно отправлять запросы к разным облачным платформам и обучать отдельную нейронную сеть для оценки результатов.

Фото AdNorrel / CC BY-SA
В защиту reCAPTCHA стоит отметить, что новая версия все же добавила несколько препятствий для хакеров. Первая — имитировать поведение пользователя на странице стало сложнее. В unCAPTCHA v1 регистрация аккаунта была полностью автоматизирована с помощью Selenium. Теперь капча Google распознает, если на странице используется этот сервис и автоматически блокирует доступ. Разработчикам из Мэрилендского университета пришлось вручную прописывать порядок действий «пользователя» и изменять скрипт для каждой новой попытки ввода. Пока инженеры из Мэриленда работали над своим решением, в Google вновь обновили reCAPTCHA, и с ней unCAPTCHA справиться еще не может. Однако многие сайты до сих пор используют старые версии защиты от DDoS. Поэтому уязвимость остается актуальной.
Как ещё взламывали аудиокапчу
В сети можно найти информацию и о других решениях для взлома аудиокапч. Одни из первых систем основывались на ручной классификации аудиофайлов. Аудио разбивали на сегменты с отдельными словами — буквами и цифрами, которые соотносили с их спектрограммами. Например, этот способ взлома предложил проект devoicecaptcha 2006 года. Тогда программа обошла капчу Google с точностью в 33%.
Другие проекты внедряли более сложные алгоритмы, которые полностью автоматизировали процесс решения капчи. Например, для взлома применяли программу Sphinx, которую впервые разработали в конце 1990-х в университете Карнеги — Меллона. Sphinx взламывала капчу на сайте eBay в 75% случаев, но позже её эффективность упала до 25–30%.
В 2012 году авторы проекта Stiltwalker представили нейронную сеть, которая смогла различать частотный «рисунок» отдельных слов, несмотря на фоновые шумы. Как говорят разработчики, система успешно обошла актуальную на тот момент проверку Google в 99% случаев.
Что касается создателей unCAPTCHA, то, вероятно, мы еще услышим об их работе. Есть шанс, что они попробуют аналогичным образом взломать обновленную уже в третий раз reCAPTCHA.
Дополнительное чтение из нашего Telegram-канала и «Мира Hi-Fi»:
 Что такое 8D-аудио — обсуждаем новый трендBluetooth-чип, которому не нужен аккумулятор
Что такое 8D-аудио — обсуждаем новый трендBluetooth-чип, которому не нужен аккумулятор
 Ученые научились передавать звук с помощью лазеров
Ученые научились передавать звук с помощью лазеров
Лейбл KPM оцифровал весь свой каталог
