Как Яндекс научил машину самостоятельно создавать переводы для редких языков
Яндекс работает над технологией машинного перевода с 2011 года, и сегодня я расскажу о нашем новом подходе, благодаря которому становится возможным создать переводчик для тех языков, для которых ранее это было сделать затруднительно.

Правила против статистики
Машинный перевод, то есть автоматический перевод с одного человеческого языка на другой, зародился в середине прошлого века. Точкой отсчета принято считать Джорджтаунский эксперимент, проведенный 7 января 1954 года, в рамках которого более 60 фраз на русском языке были переведены компьютером на английский. По сути, это был вовсе и не эксперимент, а хорошо спланированная демонстрация: словарь включал не более 250 записей и работал с учетом лишь 6 правил. Тем не менее результаты впечатлили публику и подстегнули развитие машинного перевода.
В основе таких систем лежали словари и правила, которые и определяли качество перевода. Профессиональные лингвисты годами работали над тем, чтобы вывести всё более подробные и всеохватывающие ручные правила (по сути, регулярные выражения). Работа эта была столь трудоемкой, что серьезное внимание уделялось лишь наиболее популярным парам языков, но даже в рамках них машины справлялись плохо. Живой язык — очень сложная система, которая плохо подчиняется правилам, постоянно развивается и практически каждый день обогащается новыми словами или конструкциями. Ещё сложнее описать правилами соответствия двух языков. Одни и те же слова могут иметь совершенно разные переводы в зависимости от контекста. Да и целые фразы могут иметь свой устойчивый перевод, которому лучше соответствовать. Например, «Нельзя так просто войти в Мордор».
Единственный способ машине постоянно адаптироваться к изменяющимся условиям и учитывать контекст — это учиться на большом количестве актуальных текстов и самостоятельно выявлять закономерности и правила. В этом и заключается статистический подход к машинному переводу. Идеи эти известны с середины 20 века, но особого распространения они не получили: машинный перевод, основанный на правилах, работал лучше в условиях отсутствия больших вычислительных мощностей и обучающих баз.
Грубая сила компьютеров — это не наука
Новая волна развития статистического подхода началась в 80–90-х годах прошлого века. Компания IBM Research получила доступ к большому количеству документов канадского парламента и использовала их для работы над системой проверки правописания. И для этого они применили достаточно интересный подход, известный под названием noisy channel model. Смысл его в том, что текст А рассматривается как текст Б, но с ошибками. И задача машины — устранить их. Обучалась модель на тысячах уже набранных документах. Подробнее о noisy channel можно почитать в других постах на Хабре, здесь же важно сказать, что этот подход хорошо показал себя для проверки правописания, и группа сотрудников IBM решила попробовать его и для перевода. В Канаде два официальных языка (английский и французский), поэтому с помощью переводчика они надеялись уволить половину операторов сократить объем вводимого вручную текста. А вот со временем были проблемы, поэтому им пришлось дождаться того момента, когда руководитель ушел в отпуск, и появилась возможность творчески отнестись к дедлайнам и заняться исследованием.
Результаты их работы были опубликованы, но впечатлили они не всех. Организаторы конференции по компьютерной лингвистике COLING написали разгромный отзыв:

Результат оказался хуже, чем у лучших на тот момент систем, основанных на правилах, но сам подход, предполагавший сокращение ручного труда, заинтересовал исследователей со всего мира. И главная проблема, которая стояла перед ними, заключалась в отсутствии достаточного количества примеров переводов для обучения машины. В ход шли любые материалы, которые удавалось найти: базы международных документов ООН, документации, справочники, Библия и Коран (которые переведены практически на все языки мира). Но для качественной работы нужно было больше.
Поиск
В интернете каждый день появляются сотни тысяч новых страниц, многие из которых переводятся на другие языки. Этот ресурс можно использовать для обучения машины, но добыть его сложно. Таким опытом обладают организации, которые индексируют интернет и собирают данные о миллиардах веб-страниц. Среди них, например, поисковые системы.
Яндекс вот уже пять лет работает над собственной системой машинного перевода, которая обучается на данных из интернета. Ее результаты используются в Переводчике, Поиске, Браузере, Почте, Дзене и во многих других сервисах. Обучается она следующим образом. Изначально система находит параллельные тексты по адресам документов — чаще всего такие адреса различаются только параметрами, например, «en» для английской версии и «ru» для русской. Для каждого изученного текста система строит список уникальных признаков. Это могут быть редко используемые слова, числа, специальные знаки, находящиеся в тексте в определённой последовательности. Когда система набирает достаточное количество текстов с признаками, она начинает искать параллельные тексты ещё и с их помощью — сравнивая признаки новых текстов и уже изученных.
Чтобы переводчик соответствовал современным стандартам качества, система должна изучить миллионы фраз на обоих языках. Поисковые технологии могут найти их, но только для наиболее популярных направлений перевода. Для всех остальных можно пытаться по старинке обучаться только на Википедии или Библии, но качество перевода откатывается на десятилетия назад. Можно подключить краудсорсинг (Яндекс.Толока или Amazon Mechanical Turk) и усилиями большого количества людей из разных стран собрать примеры переводов. Но это долго, дорого и не всегда эффективно. Хотя мы и стараемся использовать краудсорсинг там, где это возможно, нам удалось найти альтернативное решение.
Язык как совокупность моделей
В основе статистического перевода долгое время лежали исключительно лексические модели, т.е. такие модели, который не учитывают родственные связи между различными словами и другие лингвистические характеристики. Проще говоря, слова «мама» и «маме» — это два совершенно разных слова с точки зрения модели, и качество перевода определялось только наличием подходящего примера.
Несколько лет назад в индустрии появилось понимание, что качество статистического машинного перевода можно улучшить, если дополнить сугубо лексическую модель еще и моделями морфологии (словоизменение и словообразование) и синтаксиса (построение предложений). Может показаться, что речь идет о шаге назад в сторону ручных правил лингвистов, но это не так. В отличие от систем, основанных на ручных правилах, модели морфологии и синтаксиса можно формировать автоматически на основе все той же статистики. Простой пример со словом «мама». Если скормить нейронной сети тысячи текстов, содержащих это слово в различных формах, то сеть «поймет» принципы словообразования и научится предсказывать правильную форму в зависимости от контекста.
Переход от простой модели языка к комплексной хорошо отразился на общем качестве, но для ее работы по-прежнему нужны миллионы примеров, которые трудно найти для небольших языков. Но именно здесь мы вспомнили о том, что многие языки связаны между собой. И этот факт можно использовать.
Родственные связи
Мы начали с того, что отошли от традиционного восприятия каждого языка как независимой системы и стали учитывать родственные связи между ними. На практике это означает вот что. Если у нас есть язык, для которого нужно построить перевод, но данных для этого недостаточно, то можно взять другие, более «крупные», но родственные языки. Их отдельные модели (морфология, синтаксис, лексика) можно использовать для заполнения пустот в моделях «малого» языка.
Может показаться, что речь идет о слепом копировании слов и правил между языками, но технология работает несколько умнее. Предлагаю рассмотреть ее сразу на реальном примере одного очень популярного в крайне узких кругах языка.
Папьяменто
Папьяменто — это родной язык населения Арубы, Кюрасао и Бонэйр, на котором говорят около 300 тыс. человек. В том числе один из наших коллег, который родился на Арубе. Он и предложил нам стать первыми, кто поддержит папьяменто. Про эти острова мы знали лишь по Википедии, но такое предложение упустить не могли. И вот почему.

Когда людям приходится разговаривать на языке, который ни для кого из них не является родным, появляются новые языки, которые называются пиджинами. Чаще всего пиджины возникали на островах, которые захватывали европейцы. Колонизаторы свозили туда рабочую силу с других территорий, и этим людям, не знавшим языков друг друга, приходилось как-то общаться. Единственным их общим языком был язык колонизаторов, усваиваемый обычно в очень упрощенном виде. Так возникло множество пиджинов на основе английского, французского, испанского и других языков. Потом люди передавали этот язык своим детям, и для тех он становился уже родным. Пиджины, которые стали для кого-то родными, называются креольскими языками.
Папьяменто — креольский язык, который возник, по-видимому, в XVI веке. Большая часть его лексики имеет испанское или португальское происхождение, но есть слова и из английского, голландского, итальянского, а также из местных языков. А поскольку ранее мы еще не испытывали нашу технологию на креольском языке, то ухватились за этот шанс.
Моделирование любого нового языка всегда начинается с построения его ядра. Каким бы «малым» ни был язык, у него всегда есть уникальные особенности, которые отличают его от любого другого. Иначе бы его просто нельзя было отнести к самостоятельному языку. Это могут быть свои уникальные слова или какие-то правила словообразования, которые не повторяются в родственных языках. Эти особенности и составляют то ядро, которое в любом случае нужно моделировать. И для этого вполне хватает малого количества примеров перевода. В случае с папьяменто в нашем распоряжении был перевод Библии на английский, испанский, голландский, португальский и, собственно, папьяменто. Плюс небольшое количество документов из сети с их переводом на один из европейский языков.
Начальный этап работы над папьяменто ничем не отличался от создания переводчика для любого большого языка. Загружаем в машину все доступные нам материалы и запускаем процесс. Она проходит по параллельным текстам, написанным на разных языках, и строит распределение вероятностей перевода для каждого найденного слова. Кстати, сейчас модно говорить о применении нейронных сетей в этом процессе, и мы тоже умеем это делать, но зачастую более простых инструментов вполне хватает. Например, для эльфийского языка (о нем мы поговорим чуть позже) мы изначально построили модель с применением нейронной сети, но в конечном счете запустились без нее. Потому что более простой статистический инструмент показал результат не хуже, а усилий потребовал меньше. Но мы отвлеклись.
Система, глядя на параллельные тексты, пополняет свой словарный запас и запоминает переводы. Для больших языков, где примеров миллионы, больше ничего делать и не надо — система найдет не только все возможны слова, их формы и запомнит их переводы, но и учтет разные случаи их применения в зависимости от контекста. С небольшим языком сложнее. Ядро мы смоделировали, но примеров недостаточно для полного покрытия всех слов, учета словообразования. Поэтому технология, которая лежит в основе нашего подхода, работает несколько глубже с уже имеющимися примерами и использует знания о других языках.
Например, согласно морфологии испанского языка, множественное число образуется с помощью окончаний -s/-es. Машина, встречаясь с множественным числом в испанском переводе, делает для себя вывод, что это же слово в переводе на папьяменто, скорее всего, написано во множественном числе. Благодаря этой особенности, автоматический переводчик вывел для себя правило, что слова в папьяменто с окончанием -nan обозначают множественное число, и если его перевода не найдено, то стоит отбросить окончание и попробовать найти перевод для единственного числа. Аналогично для многих других правил словоизменения.

С морфологией стало понятнее, но что делать, если даже начальная форма слова машине еще не известна? Мы помним, что большинство всех слов папьяменто произошло от европейских аналогов. Допустим, что наш автоматический переводчик сталкивается с неизвестным словом «largu» в папьяменто и хочет найти перевод на английский. Машина замечает, что это слово очень похоже на слово «largo» как из испанского, так и из португальского языков. Вот только значения этих слов не совпадают («длинный» и «широкий» соответственно). И на какой язык ориентироваться? Система машинного перевода решает эту проблему следующим образом. Она строит оба варианта перевода, а затем, опираясь на миллионы изученных английских документов, делает вывод, какой из вариантов больше похож на естественный текст. Например, «long tail queries» (длинный хвост запросов) больше похож на правду, чем «wide tail queries» (широкий хвост запросов). Так она запоминает, что в данном конкретном случае слово «largu» произошло из испанского, а не из португальского. И так для большинства неизвестных слов — машина автоматически выучит их без готовых примеров и ручного вмешательства.
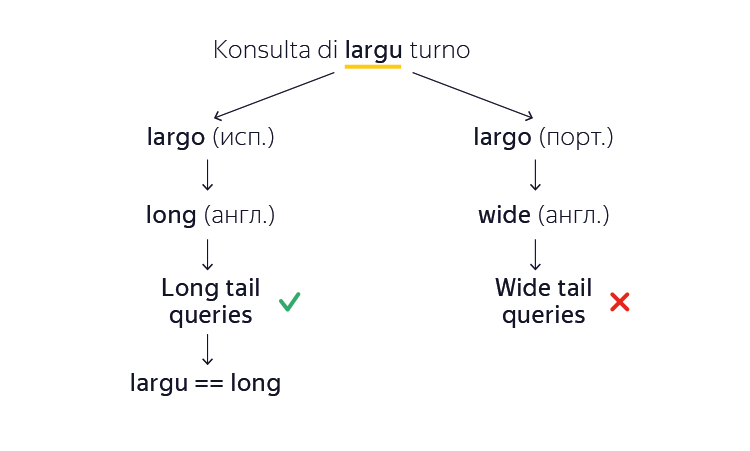
В результате, благодаря заимствованиям из более крупных языков, нам удалось построить перевода с/на папьяменто на таком объеме примеров, на которым классический статистический машинный перевод просто не справился бы.
Горномарийский
Другой пример. Мы регулярно добавляем поддержку языков народов России и в какой-то момент дошли до марийского, в котором с самого появления письменности (в XIX веке) различались два литературных варианта: луговой (восточный) и горный (западный). Они отличаются лексически. Тем не менее языки очень похожи и взаимопонимаемы. Первый печатный текст на марийском языке — «Евангелие» 1821 года — был горномарийским. Однако из-за того, что луговых марийцев намного больше, марийским языком «по умолчанию» обычно считается луговой. По этой же причине текстов на луговом марийском гораздо больше, и у нас не возникло проблем с классическим подходом. А вот для горного мы применили нашу технологию с заимствованиями. За основу мы взяли уже готовый луговой вариант, а словарный запас корректировали с помощью существующих словарей. Причем пригодился и русский язык, который за многие годы достаточно сильно повлиял на марийский.
Идиш
Идиш возник в X-XIV веках на основе верхненемецких диалектов — тех же, которые легли в основу современного немецкого языка. Поэтому очень многие слова в идише и немецком одинаковы или очень похожи. Это позволило нам использовать вспомогательные модели лексики и морфологии, собранные по данным для немецкого языка. При этом письменность в идише основана на еврейском алфавите, поэтому для ее моделирования использовался иврит. По нашим оценкам, перевод с/на идиш, дополненный заимствованиями из иврита и немецкого, отличается более высоким качеством в сравнении с классическим подходом.
Эльфийский
В нашей команде любят произведения писателя Толкина, поэтому перевод синдарина (один из языков эльфов Средиземья) был лишь вопросом времени. Как вы понимаете, язык редкий, и его носителей встретить не так уж и легко. Поэтому пришлось обратиться к лингвистическим исследованиям творчества писателя. Сочиняя синдарин, автор основывался на валлийском языке, и в нем есть характерные чередования начальных согласных. Например, «руна» будет «certh», а если перед ним идет определенный артикль, то получится «i gerth». Многие слова при этом заимствовались из ирландского, шотландского и валийского. К счастью, в свое время автор составил не только подробный словарь, но и правила транслитерации слов из существующих языков в синдарин. Всего этого оказалось вполне достаточно для создания переводчика.
Примеры языков, где мы использовали новый подход, можно было бы продолжать. К текущему моменту мы успели успешно применить технологию еще и в башкирском, узбекском, маратхи и непальском. Многие из этих языков даже формально нельзя назвать «малыми», но особенность нашего подхода именно в том и заключается — использовать его можно везде, где явно прослеживаются родственные связи. Для небольших языков он, в принципе, позволяет создать переводчик, для других — поднять планку качества. И это ровно то, чем мы и планируем заниматься в ближайшем будущем.
