Как я восстанавливал аудиозапись Adobe Audition 1.5 из временного файла
Звуковым редактором Adobe Audition версии 1.5 пользовались многие пользователи старых ПК. Некоторые пользуются им до сих пор из-за его простоты и удобства, несмотря на наличие более свежих версий или другого подобного современного софта. В своих предыдущих статьях я неоднократно прибегал к использованию данной программы, в основном не по её прямому назначению. В данной статье я расскажу, как когда-то давно, не имея большого опыта в программировании, мне приходилось восстанавливать потерянную аудиозапись телефонного разговора, сделанную моим знакомым в Adobe Audition 1.5.
Многим известно, что после установки Adobe Audition и при первом её запуске выскакивает диалоговое окно с предложением согласиться с выбором временной папки «Temp» в директории по умолчанию. Данной директорией служит корневой раздел наиболее свободного локального диска. Многим пользователям, как я помню, этот момент не очень нравился, чего не было в предшественнике «Cool Edit Pro».
 Рис. 1. Предложение Adobe Audition выбрать временную папку.
Рис. 1. Предложение Adobe Audition выбрать временную папку.
На этапе аудиозаписи Adobe Audition в данную папку записывает свои какие-то файлы неизвестного расширения. Самый весомый файл в этой папке по размеру приблизительно равен объёму записываемых PCM данных. После окончания записи её можно сохранить в звуковой файл того или иного формата. Если сохранять в wav, то размер такого файла будет также приблизительно равен размеру основного файла во временной папке. После сохранения аудиозаписи временные файлы удаляются. Если на этапе аудиозаписи внезапно произойдёт перезагрузка системы, или компьютер потеряет питание, то после очередной перезагрузки и запуска Adobe Audition высветится окно с предложением восстановить и продолжить запись. Восстановление происходит из той самой временной папки. Заведомо известно, что это работает не всегда. Если объём информации во временной папке небольшой (записи было сделано мало), то восстановление работает, однако зачастую оно не происходит. Более того, после такого неудачного восстановления стираются те самые временные файлы.
 Рис. 2. Предложение Adobe Audition восстановить и продолжить прерванную запись.
Рис. 2. Предложение Adobe Audition восстановить и продолжить прерванную запись.
Как раз, произошёл описанный выше сценарий: компьютер во время записи потерял питание, и запись была прервана. Зная вышеописанные особенности, перед запуском Adobe Audition была сделана резервная копия содержимого временной папки (на всякий случай). После запуска Adobe Audition, разумеется, восстановление провалилось, и временные файлы стёрлись.
Меня попросили помочь каким-либо образом восстановить из временного файла аудиозапись. На тот момент я уже работал с RAW форматом и, естественно, попытался открыть в Adobe Audition самый весомый временный файл как RAW-данные. И — о, чудо! Запись открылась без проблем, судя по волновому виду. Но оказалось, что не всё так было просто, иначе писать данную статью было бы слишком банально. При прослушивании аудиозаписи я выявил, что она воспроизводится некорректно: наблюдаются рывки, короткие пропуски или, наоборот, лишние вставки. То есть, стало быть, данный временный файл как бы состоит из частично перетасованных сегментов небольшой длины. Стало быть, таким хитрым образом Adobe Audition компонует свои данные во временный файл. Возникла идея собрать аудиозапись как мозаику из этих кусочков, которые заключены во временном файле.
Экспериментальным образом я установил, что данные кусочки имеют размер 65536 байт (очень круглое число), что для формата »16 бит Стерео», в котором велась запись, соответствует 16384 семплам. Целиковые длинные куски между «лишними» вставками по длине кратны 16384 семплам, то есть состоят из целого числа кусочков (сегментов). С помощью Total Commander я порезал данный временный файл на куски по 65536 байт, предварительно подогнав начало файла к началу целого сегмента. Получилось 7665 кусков. Из-за большого объёма данных я сначала разбил файл на равные фрагменты по 65536×512=33554432 байт (512 — для удобства). Получилось 14 целых фрагментов и 15-ый — остаток. Фрагментам я дал имена 1…15. Каждый фрагмент в свою очередь я разбил на 512 сегментов по 65536 байт. В 15-ом неполном фрагменте получилось 496 сегментов и 497-ой — остаток в 7320 байт. Сегменты проименовал как 1.001…1.512, 2.001……15.497.
Предварительно оценив алгоритм разбивки на сегменты, начал думать о написании программы пересортировки. Я увидел периодичность длинной в 27 сегментов: через каждые 27 сегментов вставляется сегмент, отстоящий на 27 сегментов назад, а текущий вставляется через 27 сегментов вперёд. Но, посмотрев внимательнее, я понял, что алгоритм намного сложнее и постоянная тенденция способов разбивки и сортировки отсутствует. Я принял решение восстанавливать запись вручную в мультитрековом режиме Adobe Audition, собирая её по сегментам, как мозаику. Для удобства я решил использовать одну мультисессию на один фрагмент, а затем результаты соединить. Итого — 15 мультисессий. Работа оказалась кропотливой. Во время сборки я заметил присутствие второго периода цикла разбивки длинной примерно в 27×9=243 сегмента: каждые 9 вышеуказанных частых периода происходит перестановка соседних сегментов. Это меня разочаровало ещё больше. Надежда написать программу восстановления была утрачена. А восстанавливать вручную мне было лень, поэтому пришлось сообщить, что восстановить запись не получится. На рисунке 3 показан вид мультисессии восстановления 2-ого фрагмента по кусочкам (16 дорожек — для удобства).
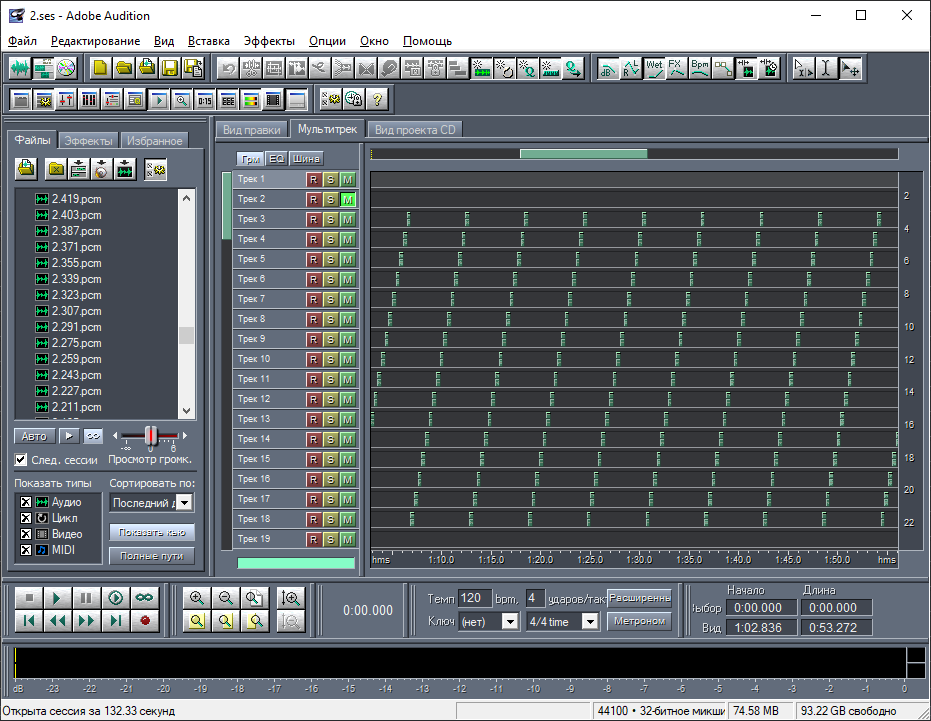 Рис. 3. Восстановление второго фрагмента вручную.
Рис. 3. Восстановление второго фрагмента вручную.
Спустя пару лет, когда я набрался опыта в работе в Excel, я решил вернуться к процедуре восстановления, имея к этому процессу собственный интерес. Казалось бы, а причём здесь Excel и восстановление аудио? А идея возникла следующая. В программе MS Excel создать с помощью формул столбец с перестановкой имён сегментов, затем в Total Commander выполнить групповое переименование сегментов по новому списку из данного столбца и дальнейшую склейку. При этом на этапе построения этого столбца следовать тому алгоритму сортировки, который я выявил (и описал выше) на основе уже сделанных вручную четырёх мультисессий. При этом я не был намерен применять скрипты VBA, с которыми я на тот момент ещё не работал. Все процедуры решил делать только с помощью функции автозаполнения и формул в ячейках. Формулы должны опираться на те или иные ключи, которые автозаполнением расставляются в нужных местах в зависимости от какой-либо операции сортировки сегментов того временного файла.
Я начал осуществлять расстановку ключей напротив каждого сегмента на листе 1 (рис. 4). Это целые числа, значение которых описано на листе 2 (рис. 5). Там же изображена гистограмма, визуализирующая частоту применения ключей. Также на листе 1 имеются столбцы промежуточных расчётов. Была замечена та самая периодичность из двух циклов, отличающихся между собой примерно в 9 раз. Но, кроме этого, в начале, в первой мультисессии на первых 512 сегментах была замечена ещё одна нигде больше пока не встречающаяся хитрая последовательность перестановки. Я решил, что это разовая перестановка и не стал вокруг неё заморачиваться, продолжая следовать уже выявленным периодам. Определившись с началом цикла, я начал отсчёт от сегмента 2.005. Всё, что находится до него, я решил потом просто прицепить слева, ибо это уже мной было восстановлено вручную. Также встречались небольшие отклонения от периодичности. Скорее всего, это были мои ошибки при ручной сортировке (в тех местах аудио, где преобладает тишина, сложно правильно сортировать сегменты).
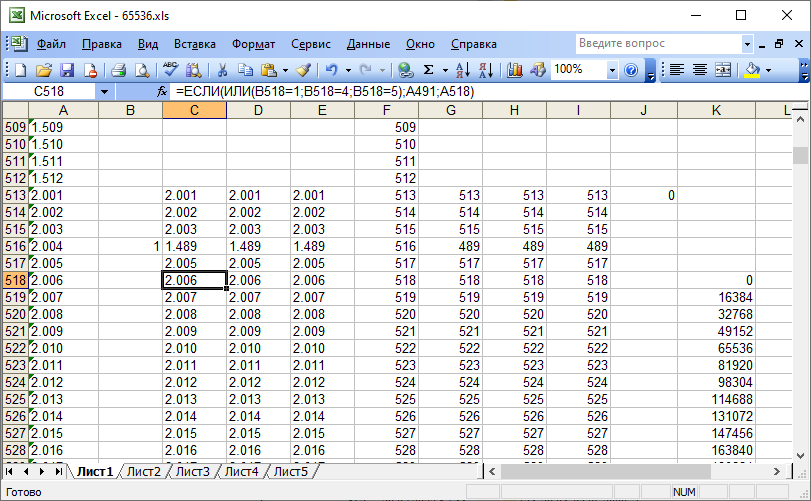 Рис. 4. Восстановление порядка сегментов при помощи Excel.
Рис. 4. Восстановление порядка сегментов при помощи Excel. Рис. 5. Значения ключей и гистограмма частоты их применения.
Рис. 5. Значения ключей и гистограмма частоты их применения.
В итоге с помощью хитрых методов Excel был получен список имён файлов в новом порядке. Данный список я сохранил в текстовый файл, после чего в Total Commander переименовал все сегменты по списку из данного файла. Там же я выполнил склейку всех файлов в единый файл. Склейку производил в 2 этапа, так как Total Commander не умеет склеивать более 999 файлов. Некоторые процессы я автоматизировал с помощью bat-файлов со сценариями, которые подготовил всё в том же Excel на листе 4.
Радоваться было нечему, ибо при прослушивании, начиная с сегмента 6.464, была замечена очередная рассортировка. Это могло быть вызвано не только нарушением периодичности, но и моей ошибкой при проделывании всех сложных операций. Одна была радость, что не пришлось собирать вручную почти два фрагмента (5 и 6). Всё, что до 6.464, я сохранил отдельно. К счастью оказалось, что 7-ой, 8-ой, 9-ый и частично 10-ый (до 10.122) фрагменты были правильно восстановлены и не испорчены. Начиная с 10.122, снова началась перетасовка сегментов. С этого момента я продолжил восстанавливать 10-ый фрагмент вручную, как я это делал изначально. При этом в Excel я фиксировал закономерности перестановок сегментов. После того, как я уловил периодичность рассортировки, снова выполнил процедуру преобразования и склеивания по описанному выше принципу. При прослушивании результата был замечен очередной сбой порядка, начиная с сегмента 14.118. Мне показалось, что опять сменился алгоритм рассортировки сегментов. К этому моменту мне уже всё это надоело, и я восстановил оставшиеся полтора фрагмента вручную. Все полученные большие фрагменты соединил в единый готовый файл.
Вот так я и завершил восстановление аудиоматериала. В дальнейшем мы решили избегать такие звуковые редакторы, как Adobe Audition, если требуется только функционал аудиозаписи. С одной стороны Adobe Audition красиво прорисовывает волновой вид, чем можно более точно контролировать уровень записи. С другой стороны — запись не упаковывается в реальном времени в окончательный файл, а используются временные файлы. Существует множество простых программ аудиорекордеров, лишённых данного недостатка.
В дальнейшем я постоянно задавался вопросом:, а почему Adobe Audition так сложно форматирует временный файл? Навряд ли это сделано специально, чтобы кого-то запутать. Видимо, это какая-то техническая особенность захвата звука через тот или иной драйвер или оборудование. Относительно недавно я интересовался вопросами принципа работы драйверов звуковых карт и интерфейса Windows DirectSound. Как раз там я и нашёл ответы на свои вопросы (но это не точно). Особо глубоко не вникая, помню, что там было сказано про особенности чтения из буферов при захвате аудио и про разновидности буферов. Данные особенности, которые мне с первого раза были непонятны, как раз и напомнили нечто похожие алгоритмы моих действий по исследованию временного файла и восстановлению аудио, чем я занимался более 10 лет назад. И ещё. Восстановление аудио велось на основе только одного, самого весомого временного файла, при этом не рассматривались вспомогательные временные файлы. Вполне возможно, что в этих файлах содержатся индексы, являющиеся указателями на сегменты в правильном порядке.
