Как я визуальную новеллу препарировал
Привет, Хабр!
На днях я захотел достать ресурсы одной визуальной новеллы, созданной с помощью Ren’Py (Да, да, того самого «Бесконечного Лета»). Опытным путем было установлено, что все они хранятся в файле archive.rpa. Я нашел готовые скрипты для распаковки на Github, но решил достать их сам, Haskell в помощь…
archive.rpa
Во-первых, давайте разберемся с чем конкретно мы имеем дело, то есть как ресурсы хранятся в нашем «архиве». Откроем его в dhex или в аналогичной программе:
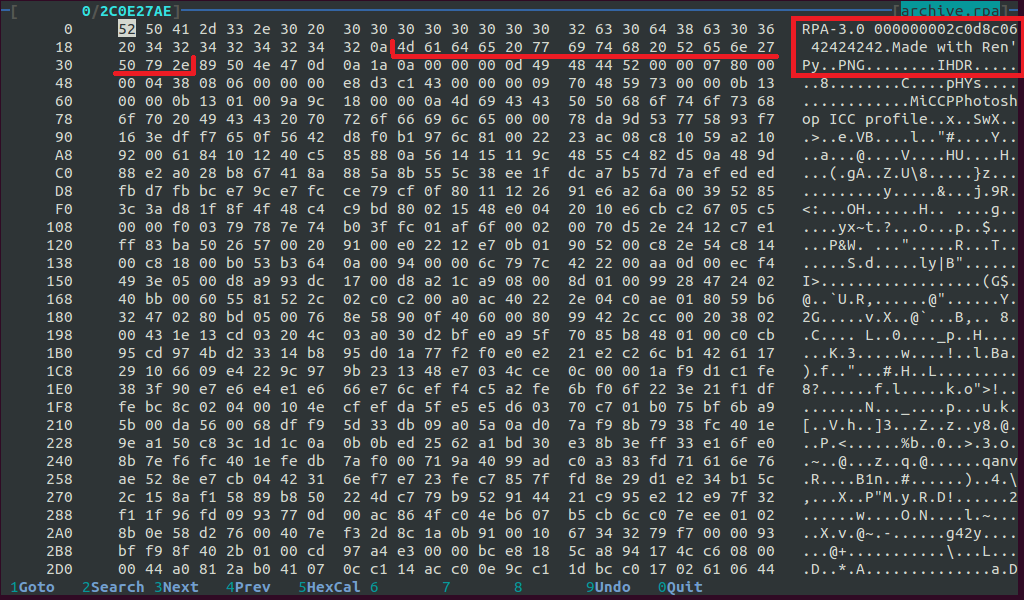
Что мы видим? Сначала данные о Ren’Py, потом еще что-то, а потом — начало PNG файла! Вот оно!
Долистаем до конца PNG:
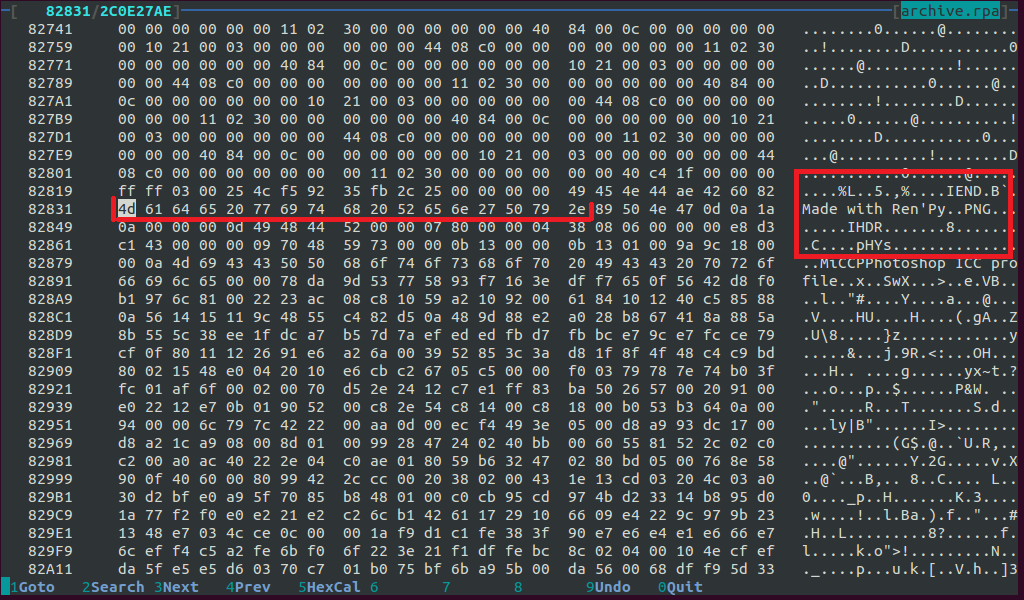
Тип бинарного файла можно определить по его первым байтам (т. н. «магическому числу»). У PNG «магические» байты таковы: 89 50 4e 47 0d 0a 1a 0a. Конец же PNG файла тоже всегда одинаков: 49 45 4e 44 ae 42 60 82
Список «магических чисел» других форматов можно найти здесь
Ага! PNG кончился, после него байты 4d 61 64 65 20 77 69 74 68 20 52 65 6e 27 50 79 2e (в ASCII: «Made with Ren’Py.»), после чего — начало нового PNG. Вывод: данные ресурсов в .rpa архивах разделяются этой последовательностью байтов. Время подумать о программе.
Пишем код
Итак, что же конкретно должна делать программа? Вот это:
- Считать файл
- Разбить его на файлы ресурсов
- Записать файлы ресурсов в папку, определенную пользователем
- Приделать каждому файлу соответствующее расширение
Разбиваем на части
Начнем, пожалуй, с функции разбиения на файлы:
Extractor.hs:
module Extractor where
import qualified Data.ByteString.Lazy as B
import Data.List.Split
extractRes :: B.ByteString -> [B.ByteString]
extractRes bs = map B.pack $ splitOn magicSep $ B.unpack bs
magicSep = [0x4d, 0x61, 0x64, 0x65,
0x20, 0x77, 0x69, 0x74,
0x68, 0x20, 0x52, 0x65,
0x6e, 0x27, 0x50, 0x79,
0x2e]Здесь magicSep — это те самые «магические» байты, разделяющие файлы ресурсов. Функция extractRes берет строку байтов, преобразует ее в список, разбивает его на списки байтов файлов, и каждый из этих списков преобразуется обратно в строку байтов. Остается один вопрос: зачем я использовал ленивую разновидность строк байтов? Ответ на него мы вскоре получим.
Устанавливаем расширение
ExtensionId.hs:
module ExtensionId where
import qualified Data.ByteString.Lazy as B
import Data.List (isPrefixOf)
import System.Directory
type FileType = String
readExtension :: FilePath -> IO (Maybe FileType)
readExtension path = B.readFile path >>= (return . getExtension)
writeExtension :: FilePath -> Maybe FileType -> IO ()
writeExtension _ Nothing = return ()
writeExtension path (Just ext) = renameFile path $ path ++ ext
getExtension :: B.ByteString -> Maybe FileType
getExtension = magicLookup magicMap
magicLookup :: [(B.ByteString, FileType)] -> B.ByteString -> Maybe FileType
magicLookup [] _ = Nothing
magicLookup ((magic, fileType) : rest) bytes
| (B.unpack magic) `isPrefixOf` (B.unpack bytes) = Just fileType
| otherwise = magicLookup rest bytes
magicMap = [(pngMagic, ".png"),
(jpgMagic, ".jpg"),
(oggMagic, ".ogg")]
pngMagic = B.pack [0x89, 0x50, 0x4e, 0x47]
jpgMagic = B.pack [0xff, 0xd8, 0xff]
oggMagic = B.pack [0x4f, 0x67, 0x67, 0x53]Здесь мы видим две главные функции: readExtension и writeExtension. Несложно догадаться, что одна считывает первые байты файла и на их основе устанавливает расширение, а вторая — переименовывает файл в соответствии с ним. Всю грязную работу по определению расширения на себя берет функция magicLookup, которая просто проходит по списку известных «магических чисел» и сравнивает их с началом файла. magicMap представляет из себя список соответствий байтов и расширений, pngMagic, jpgMagic и oggMagic — «магические числа» форматов файлов. Их список может быть расширен читателем, но я точно знал, что кроме этих форматов в архиве ничего не встретится.
Уффф…
Остался наш дорогой Main.hs:
module Main where
import qualified Data.ByteString.Lazy as B
import System.Environment
import System.Directory
import System.FilePath
import System.IO
import ExtensionId
import Extractor
main :: IO ()
main = do
args <- getArgs
if (length args) /= 2
then usage
else extractToFolder (args !! 0) (args !! 1)
extractToFolder :: FilePath -> FilePath -> IO ()
extractToFolder input output = do
b <- doesFileExist input
if b
then do
b <- doesDirectoryExist output
if b
then do
c <- confirm $ "Folder " ++ output ++ " already exists, overwrite it? (y/n): "
if c
then do
removeDirectoryRecursive output
createDirectory output
extractToFolder' input output
else return ()
else extractToFolder' input output
else putStrLn $ "Input file " ++ input ++ " does not exist"
extractToFolder' :: FilePath -> FilePath -> IO ()
extractToFolder' input output = do
bytes <- B.readFile input
let bs = extractRes bytes
doNastyWork bs 0
where doNastyWork [] _ = putStrLn "Done."
doNastyWork (bs : rest) n = do
let path = output ("extraction_" ++ (show n))
B.writeFile path bs
ext <- readExtension path
writeExtension path ext
putStrLn $ (show $ n + 1) ++ " files processed..."
doNastyWork rest (n + 1)
confirm :: String -> IO Bool
confirm q = do
putStr q
hFlush stdout
line <- getLine
case head line of
'y' -> return True
'n' -> return False
_ -> confirm q
usage :: IO ()
usage = putStrLn "Usage: extractrpa [ARCHIVE] [OUTPUT FOLDER]"Что же здесь? Функция main просто проверяет количество аргументов, и если их два, то делегирует грязную работу (тоже не шибко чистой) функции extractToFolder, в противном случае посылает нас курить мануал читать usage.
В extractToFolder творится примерно то же самое: проверка корректности ввода (защита от дурака), и если папка, в которую надо выводить, не существует или пользователь дал согласие на уничтожение ее содержимого, обращается за помощью к extractToFolder'
В других языках способ обработки данных примерно такой: читаем все данные, после чего разбиваем их на части, после чего каждую записываем в файл и даем расширение. Haskell же предлагает несколько другой подход: обрабатывать данные по мере их поступления. Это возможно благодаря ленивым вычислениям (вот почему я использовал ленивые строки байтов). Такой подход позволяет пользователю лучше видеть процесс обработки, что уже неплохо. extractToFolder' — своеобразный конвейер, на котором и происходит обработка архива: читаем файл, разбиваем его на части, пока части не кончатся записываем их в файлы с уникальными именами.
Ну вот и все, набираем в терминале заветные команды:
$ ghc --make Main.hs -o extractrpa
...
$ extractrpa archive.rpa archive
...
Done.И наслаждаемся ловко стыренным искусно добытым контентом!
Вопросы, жалобы, предложения — прошу в комментарии!
